
Hadoop 3個核心組件: 分散式文件系統:Hdfs——實現將文件分散式存儲在很多的伺服器上(hdfs是一個基於Linux本地文件系統上的文件系統) 分散式運算編程框架:Mapreduce——實現在很多機器上分散式並行運算 分散式資源調度平臺:Yarn——幫用戶調度大量的mapreduce程式,並 ...
Hadoop 3個核心組件:
分散式文件系統:Hdfs——實現將文件分散式存儲在很多的伺服器上(hdfs是一個基於Linux本地文件系統上的文件系統)
分散式運算編程框架:Mapreduce——實現在很多機器上分散式並行運算
分散式資源調度平臺:Yarn——幫用戶調度大量的mapreduce程式,併合理分配運算資源
HDFS的設計特點是:
1、大數據文件,非常適合上T級別的大文件或者一堆大數據文件的存儲,如果文件只有幾個G甚至更小就沒啥意思了。
2、文件分塊存儲,HDFS會將一個完整的大文件平均分塊存儲到不同計算器上,它的意義在於讀取文件時可以同時從多個主機取不同區塊的文件,多主機讀取比單主機讀取效率要高得多得都。
3、流式數據訪問,一次寫入多次讀寫,這種模式跟傳統文件不同,它不支持動態改變文件內容,而是要求讓文件一次寫入就不做變化,要變化也只能在文件末添加內容。
4、廉價硬體,HDFS可以應用在普通PC機上,這種機制能夠讓給一些公司用幾十臺廉價的電腦就可以撐起一個大數據集群。
5、硬體故障,HDFS認為所有電腦都可能會出問題,為了防止某個主機失效讀取不到該主機的塊文件,它將同一個文件塊副本分配到其它某幾個主機上,如果其中一臺主機失效,可以迅速找另一塊副本取文件。
HDFS的關鍵元素:
1、Block:將一個文件進行分塊,通常是64M。
2、NameNode:保存整個文件系統的目錄信息、文件信息及分塊信息,這是由唯一 一臺主機專門保存,當然這台主機如果出錯,NameNode就失效了。在 Hadoop2.* 開始支持 activity-standy 模式----如果主 NameNode 失效,啟動備用主機運行 NameNode。
3、DataNode:分佈在廉價的電腦上,用於存儲Block塊文件。
如果你想瞭解大數據的學習路線,想學習大數據知識以及需要免費的學習資料可以加群:784789432.歡迎你的加入。每天下午三點開直播分享基礎知識,晚上20:00都會開直播給大家分享大數據項目實戰。
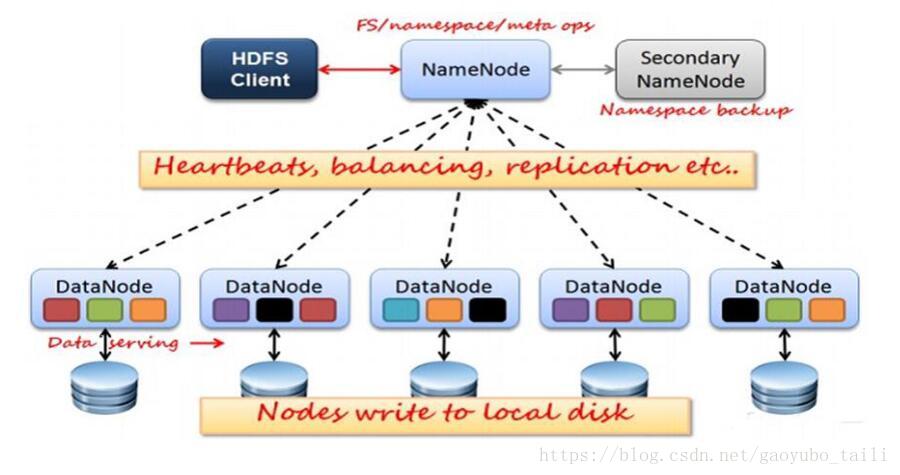
一、HDFS運行原理
1、NameNode和DataNode節點初始化完成後,採用RPC進行信息交換,採用的機制是心跳機制,即DataNode節點定時向NameNode反饋狀態信息,反饋信息如:是否正常、磁碟空間大小、資源消耗情況等信息,以確保NameNode知道DataNode的情況;
2、NameNode會將子節點的相關元數據信息緩存在記憶體中,對於文件與Block塊的信息會通過fsImage和edits文件方式持久化在磁碟上,以確保NameNode知道文件各個塊的相關信息;
3、NameNode負責存儲fsImage和edits元數據信息,但fsImage和edits元數據文件需要定期進行合併,這時則由SecondNameNode進程對fsImage和edits文件進行定期合併,合併好的文件再交給NameNode存儲。
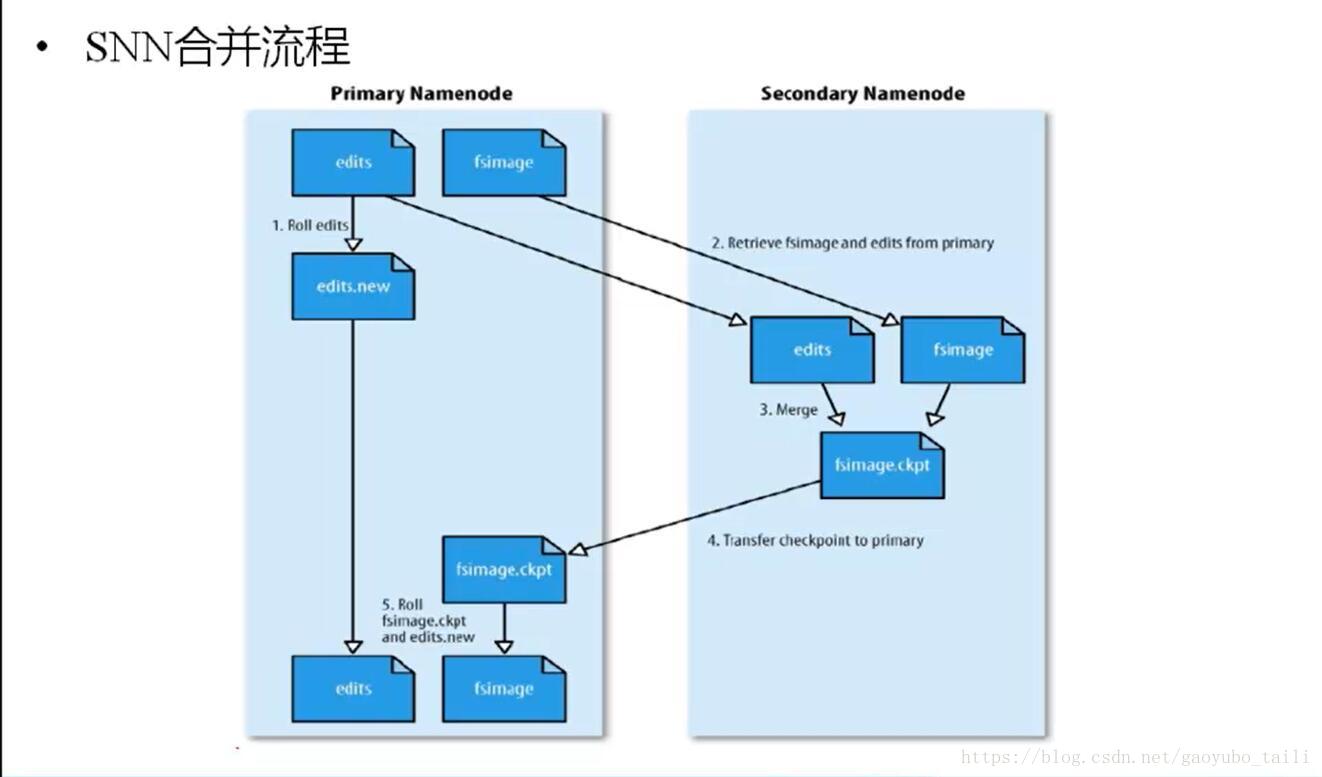
二、HDFS數據合併原理
1、NameNode初始化時會產生一個edits文件和一個fsimage文件,edits文件用於記錄操作日誌,比如文件的刪除或添加等操作信息,fsImage用於存儲文件與目錄對應的信息以及edits合併進來的信息,即相當於fsimage文件在這裡是一個總的元數據文件,記錄著所有的信息;
2、隨著edits文件不斷增大,當達到設定的一個閥值的時候,這時SecondaryNameNode會將edits文件和fsImage文件通過採用http的方式進行複製到SecondaryNameNode下(在這裡考慮到網路傳輸,所以一般將NameNode和SecondaryNameNode放在相同的節點上,這樣就無需走網路帶寬了,以提高運行效率),同時NameNode會產生一個新的edits文件替換掉舊的edits文件,這樣以保證數據不會出現冗餘;
3、SecondaryNameNode拿到這兩個文件後,會在記憶體中進行合併成一個fsImage.ckpt的文件,合併完成後,再通過http的方式將合併後的文件fsImage.ckpt複製到NameNode下,NameNode文件拿到fsImage.ckpt文件後,會將舊的fsimage文件替換掉,並且改名成fsimage文件。
通過以上幾步則完成了edits和fsimage文件的合併,依此不斷迴圈,從而到達保證元數據的正確性。
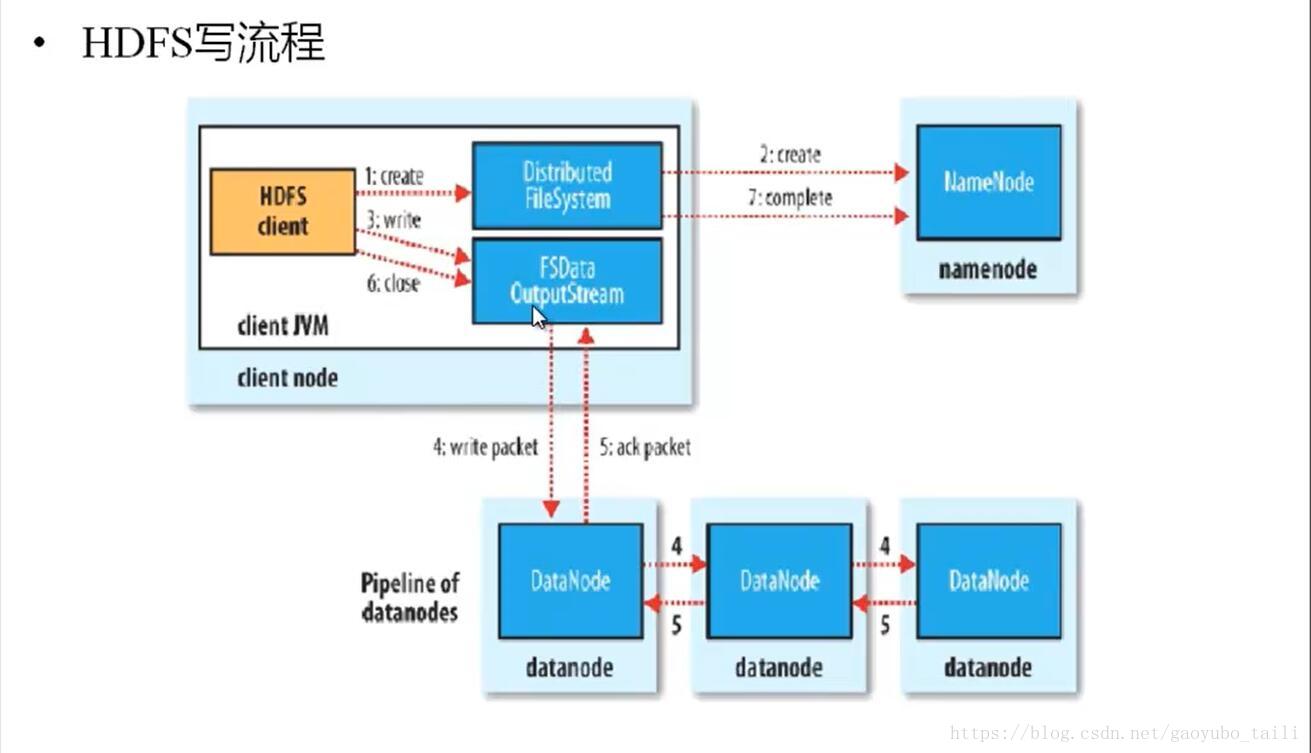
三、HDFS寫原理
1、HDFS客戶端提交寫操作到NameNode上,NameNode收到客戶端提交的請求後,會先判斷此客戶端在此目錄下是否有寫許可權,如果有,然後進行查看,看哪幾個DataNode適合存放,再給客戶端返回存放數據塊的節點信息,即告訴客戶端可以把文件存放到相關的DataNode節點下;
2、客戶端拿到數據存放節點位置信息後,會和對應的DataNode節點進行直接交互,進行數據寫入,由於數據塊具有副本replication,在數據寫入時採用的方式是先寫第一個副本,寫完後再從第一個副本的節點將數據拷貝到其它節點,依次類推,直到所有副本都寫完了,才算數據成功寫入到HDFS上,副本寫入採用的是串列,每個副本寫的過程中都會逐級向上反饋寫進度,以保證實時知道副本的寫入情況;
3、隨著所有副本寫完後,客戶端會收到數據節點反饋回來的一個成功狀態,成功結束後,關閉與數據節點交互的通道,並反饋狀態給NameNode,告訴NameNode文件已成功寫入到對應的DataNode。
代碼實現
- /*
- * 測試HDFS寫入數據
- */
- public void Test1() throws IOException {
- // 載入配置文件
- Configuration conf = new Configuration();
- FileSystem fs = FileSystem.get(conf);
- Path path = new Path("/gyb/student.txt");
- // 產生IO流
- FSDataOutputStream fsio = fs.create(path);
- // 包裝輸出IO流
- BufferedWriter bw = new BufferedWriter(new OutputStreamWriter(fsio));
- // 包裝輸入IO流
- BufferedReader br = new BufferedReader(
- new InputStreamReader(new FileInputStream("student.txt")));
- String line = null;
- while ((line = br.readLine()) != null) {
- bw.write(line);
- bw.newLine();
- bw.flush();
- }
- bw.close();
- br.close();
- }
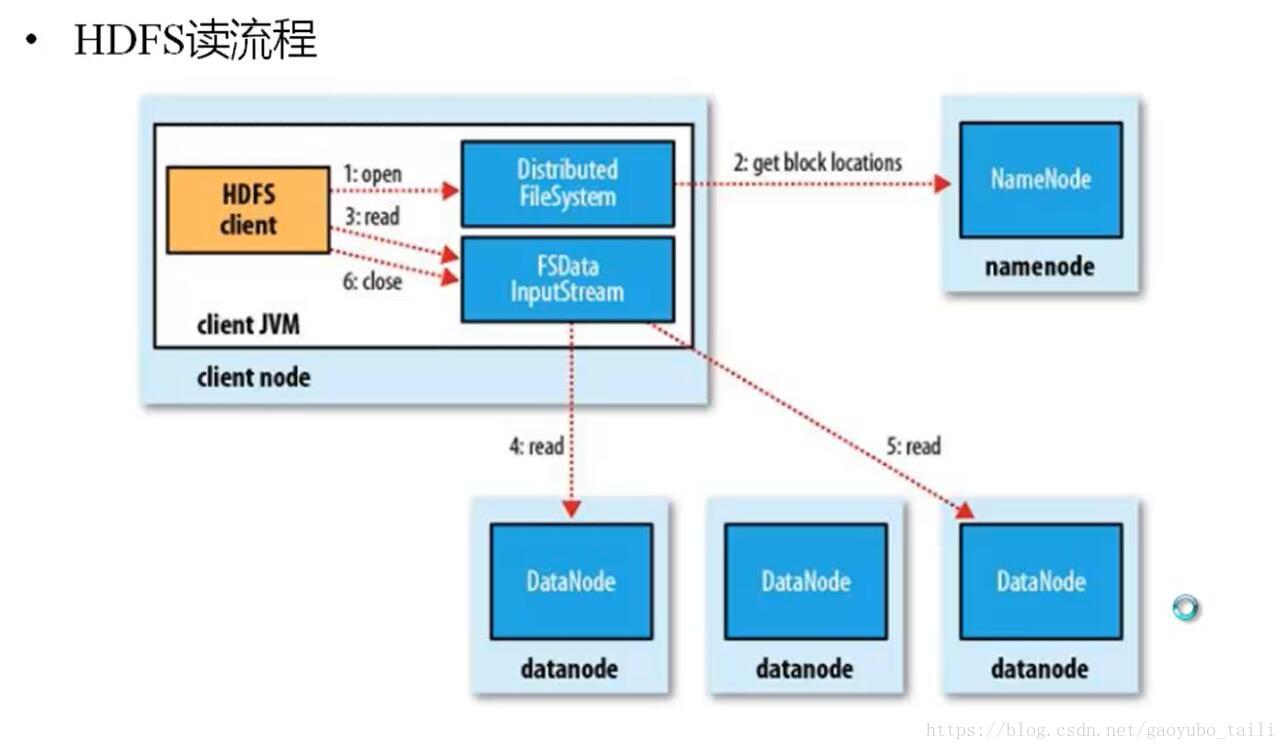
四、HDFS讀原理
1、HDFS客戶端提交讀操作到NameNode上,NameNode收到客戶端提交的請求後,會先判斷此客戶端在此目錄下是否有讀許可權,如果有,則給客戶端返回存放數據塊的節點信息,即告訴客戶端可以到相關的DataNode節點下去讀取數據塊;
2、客戶端拿到塊位置信息後,會去和相關的DataNode直接構建讀取通道,讀取數據塊,當所有數據塊都讀取完成後關閉通道,並給NameNode返回狀態信息,告訴NameNode已經讀取完畢。
代碼實現
- /*
- * 測試HDFS讀出的操作
- */
- public void Test3() throws IOException {
- // 載入配置類
- Configuration conf = new Configuration();
- FileSystem fs =FileSystem.newInstance(conf);
- Path path = new Path("/gyb/student.txt");
- FileStatus[] fileStatus = fs.listStatus(path);
- for (FileStatus fileStatus2 : fileStatus) {
- if(fileStatus2 != null && fileStatus2.isFile()) {
- //open方法只能傳文件
- FSDataInputStream fsi = fs.open(path);
- // 包裝IO流
- BufferedReader br = new BufferedReader(new InputStreamReader(fsi));
- while(br.ready()) {
- System.out.println(br.readLine());
- }
- }
- }
- System.out.println("--------over--------");
- }

