
視頻課程:李興華 Oracle從入門到精通 視頻課程學習者:陽光羅諾 視頻來源:51CTO學院 整體內容: 統計函數 在之前我們就學習過一個COUNT()函數,這個函數的主要作用是統計一張表之中的數據量的個數。和它功能與之類似的常用函數有五個: 統計個數COUNT():根據表中的實際數據量返回結果。 ...
視頻課程:李興華 Oracle從入門到精通
視頻課程學習者:陽光羅諾
視頻來源:51CTO學院
整體內容:
- 統計函數的使用
- 分組統計查詢的實現
- 對分組的數據過濾
統計函數
在之前我們就學習過一個COUNT()函數,這個函數的主要作用是統計一張表之中的數據量的個數。和它功能與之類似的常用函數有五個:
- 統計個數COUNT():根據表中的實際數據量返回結果。
- 求和SUM():是針對於數字的統計
- 平均值AVG():是針對數字的統計
- 最小值MIN():各種數據類型都支持。
- 最大值MAX():各種數據類型都支持。
範例:驗證各個函數。
代碼示例:
1 SELECT COUNT(*) 人數, AVG(sal)員工平均工資,SUM(sal)每月總支出,MAX(sal) 最高工資, MIN(sal)最低工資
2
3 FROM emp;

但是這些函數是允許和其他的函數嵌套的。
範例:統計出公司的平均雇佣年限。
代碼示例:
1 SELECT AVG(MONTHS_BETWEEN(SYSDATE,hiredate)/12)
2 FROM emp;

範例:求出最早和最晚的雇佣日期(找到公司最早雇佣的雇員,以及公司最近雇佣的雇員日期)
代碼示例:
1 SELECT MAX(hiredate) 最晚,MIN(hiredate) 最早 FROM emp;

以上的幾個操作函數,在表中沒有數據的時候,只有COUNT()函數會返回結果,其他的都是null。
範例:統計Bonus表
代碼示例:
1 SELECT COUNT(*) 人數, AVG(sal)員工平均工資,SUM(sal)每月總支出,MAX(sal) 最高工資, MIN(sal)最低工資
2
3 FROM bonus;

在圖中我們可以清楚的發現,此時只有COUNT()函數會返回最終的結果,即使沒有數據也會返回0,而其他的統計函數結果都是null。
實際上針對於COUNT()函數有三種使用形式:【面試題】
- COUNT(*):可以準確的返回表中的全部記錄數。
- COUNT(欄位):統計不為null的所有數據量。
- COUNT(DISTINCT 欄位):消除重覆數據之後的結果。
範例:統計查詢一
代碼示例:
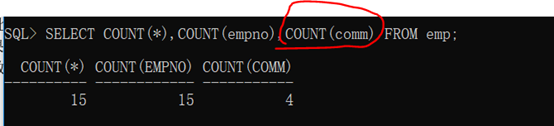
1 SELECT COUNT(*),COUNT(empno),COUNT(comm) FROM emp;
範例:查詢二
代碼示例:
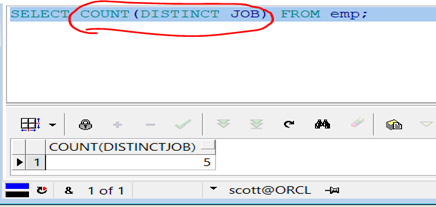
1 SELECT COUNT(DISTINCT JOB) FROM emp;
分組統計
分組的前提是存在有重覆,1但是允許單獨一行記錄進行分組。
如果要進行分組應該使用GROUP BY子句來完成,那麼此時的語法結構形式如下:
語法結構:
|
【④選出所需要的數據列】SELECT [DISTINCT] * 分組列[別名],分組列[別名],分組列[別名]······ 【①確定數據來源(行和列的集合)】FROM 表名稱 [別名],表名稱 [別名],······ 【②篩選數據行】[WHERE 限定條件] 此時的條件可以是多個語法結構。 【③針對於篩選的行分組】[GROUP BY 分組欄位,分組欄位,······] 【⑤數據排序】[ORDER BY 排序欄位 [ASC|DESC] 可以設置多個] |
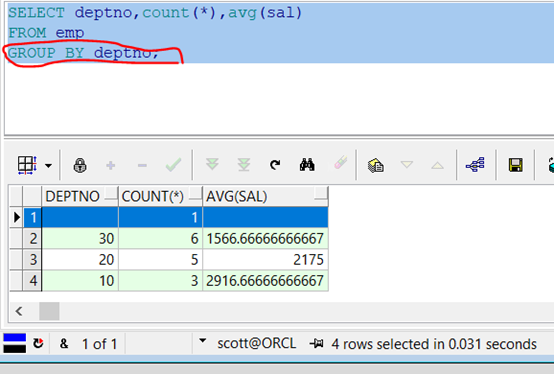
範例:根據部門編號分組,查詢出每一個部門的編號、人數、平均工資。
代碼示例:
1 SELECT deptno,count(*),avg(sal)
2
3 FROM emp
4
5 GROUP BY deptno;
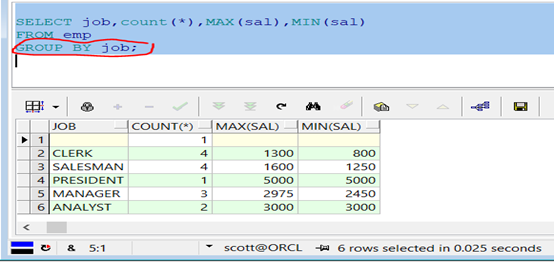
範例:根據職位分組,統計出每一個職位的人數,最低工資與最高工資。
代碼示例:
1 SELECT job,count(*),MAX(sal),MIN(sal)
2
3 FROM emp
4
5 GROUP BY job;
查詢結果如圖:
在GROUP BY 子句中,之所以使用麻煩,是因為分組的時候有一些約定條件。
- 如果查詢不適用GROUP BY子句,那麼在SELECT子句中只允許出現統計函數,其他任何欄位不允許出現。
|
錯誤代碼: |
正確代碼: |
|
SELECT empno,COUNT(*) FROM emp; 錯誤提示: 第 1 行出現錯誤: ORA-00937: 不是單組分組函數 |
SELECT COUNT(*) FROM emp; |
- 如果查詢中使用了額GROUP BY子句,那麼SELECT子句中只允許出現分組欄位、統計函數,其他任何欄位都不允許出現。
|
錯誤代碼: |
正確代碼: |
|
SELECT ename,job,COUNT(*) FROM emp GROUP BY job; 錯誤提示: 第 1 行出現錯誤: ORA-00979: 不是 GROUP BY 表達式 |
SELECT job,COUNT(*) FROM emp GROUP BY job; |
- 統計函數允許嵌套,但是嵌套之後的SELECT子句裡面只允許出現嵌套函數,而不允許任何欄位,包括分組欄位。
|
錯誤代碼: |
正確代碼: |
|
SELECT deptno,MAX(AVG(sal)) FROM emp GROUP BY deptno; 錯誤提示: 第 1 行出現錯誤: ORA-00937: 不是單組分組函數 |
SELECT MAX(AVG(sal)) FROM emp GROUP BY deptno; |
多表查詢與分析統計(重點)
對於GROUP BY子句而言,是在WHERE子句之後執行的,所以在使用時可以進行限定查詢,也可以進行多表查詢。
範例:查詢出每個部門的名稱、部門人數、平均工資。
- 確定要使用的數據表
-
- dept表:部門名稱
- emp表:統計數據
-
- 確定已知的關聯欄位。
-
- 雇員與部門:emp.deptno = dept.deptno;
-
第一步:查詢出每一個部門的名稱、雇員編號(COUNT(empno))、基本工資(AVG(sal))。
代碼示例:
1 SELECT d.dname,e.empno,e.sal
2
3 FROM emp e,dept d
4
5 WHERE e.deptno=d.deptno;
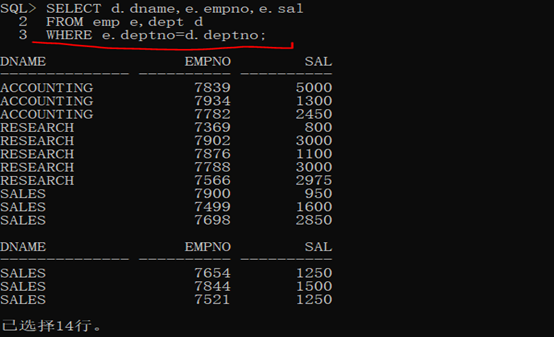
第二步:此時的查詢結果中對於部門名稱部分出現了重覆的內容,按照分組來講,只要是出現了數據的重覆,那麼就可以進行分組,只不過此時的分組是針對於臨時表(查詢結果),既然確定了dname上存在有重覆記錄,那麼就直接針對於dname分組即可。
代碼示例:
1 SELECT d.dname,COUNT(e.empno),AVG(e.sal)
2
3 FROM emp e,dept d
4
5 WHERE e.deptno=d.deptno
6
7 GROUP BY d.dname;
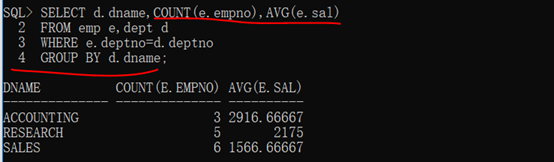
第三步:在dept表中存在有四個部門信息,而此時的要求也是統計所有的部門名稱,如果發現數據不完整,立刻使用外連接。
代碼示例:
1 SELECT d.dname,COUNT(e.empno),AVG(e.sal)
2
3 FROM emp e,dept d
4
5 WHERE e.deptno=d.deptno(+)
6
7 GROUP BY d.dname;

範例:查詢每個部門的編號、名稱、位置、部門人數、平均工資。
第一步:查詢每一個部門的編號、名稱、位置、雇員編號(COUNT())、工資(AVG(sal)).
代碼示例:
1 SELECT d.deptno,d.dname,d.loc,e.empno,e.sal
2
3 FROM emp e,dept d
4
5 WHERE e.deptno(+)=d.deptno;
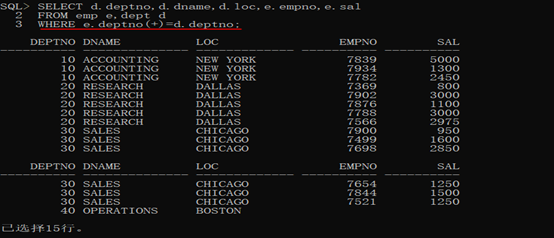
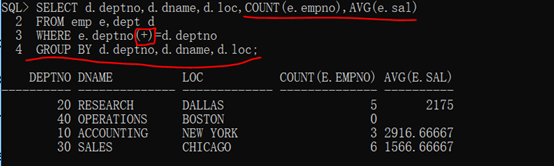
第二步:此時發現三個列(dept列)同時發生著重覆,那麼就可以進行多欄位分組。
代碼示例:
1 SELECT d.deptno,d.dname,d.loc,COUNT(e.empno),AVG(e.sal)
2
3 FROM emp e,dept d
4
5 WHERE e.deptno(+)=d.deptno
6
7 GROUP BY d.deptno,d.dname,d.loc;
HAVING子句
現在要求查詢出每個職位的名稱,職位的平均工資,但是要求顯示的職位的平均工資高於2000.
即:按照職位先進行分組,同時統計出每個職位的平均工資。隨後要求只顯示那些平均工資高於2000的職位信息,那麼既然現在要針對於顯示的數據進行篩選,自然就會首先想到WHERE子句,於是有瞭如下的代碼:
範例:代碼示例:
|
錯誤代碼: |
|
SELECT job,AVG(sal) FROM emp WHERE AVG(sal) GROUP BY job; |
|
錯誤提示: 第 3 行出現錯誤: ORA-00934: 此處不允許使用分組函數 |
此時直接告訴用戶,WHERE子句中不允許出現統計函數(分組函數)。因為GROUP BY子句在WHERE子句之後執行的。那麼此時執行WHERE子句時還沒有進行分組,那麼就自然無法進行統計。此時我們就可以使用HAVING子句來完成。
SQL語法結構:
【⑤選出所需要的數據列】SELECT [DISTINCT] * 分組列[別名],分組列[別名],分組列[別名]······
【①確定數據來源(行和列的集合)】FROM 表名稱 [別名],表名稱 [別名],······
【②篩選數據行】[WHERE 限定條件] 此時的條件可以是多個語法結構。
【③針對於篩選的行分組】[GROUP BY 分組欄位,分組欄位,······]
【③針對於篩選的行分組】[HAVING 分組過濾]
【⑥數據排序】[ORDER BY 排序欄位 [ASC|DESC] 可以設置多個]
範例:使用HAVING子句
代碼示例:
1 SELECT job,AVG(sal)
2
3 FROM emp
4
5 GROUP BY job
6
7 HAVING AVG(sal)>2000;

HAVING實在GROUP BY分組之後才進行的篩選,在HAVING裡面可以直接使用統計函數。
說明:關於WHERE與HAVING的區別?
- WHERE子句在GROUP BY分組之前進行篩選,指的是選出那些可以參與分組的數據。並且在WHERE子句中不允許使用統計函數
- HAVING子句是在WHERE分組之後執行的,那麼就可以使用統計函數。
分組案例:
範例:顯示所有銷售人員的工作名稱以及從事同一個工作的雇員的月工資的總和,並且要求滿足從事同一工作的月工資的合計大於5000,顯示的結果按照月工資合計的升序排列。
第一步:查詢所有非銷售人員的信息,WHERE子句即可實現限定查詢。
代碼示例:
1 SELECT * FROM emp WHERE job<>'SALESMAN';
查詢結果:
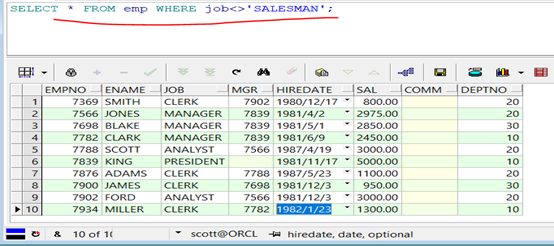
第二步:按照職位進行分組,而後求出月工資的總支出。
代碼示例:
1 SELECT job,SUM(sal)
2 FROM emp
3 WHERE job<>'SALESMAN'
4 GROUP BY job;
查詢結果:
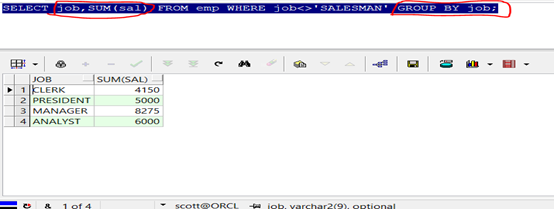
第三步:分組後的數據進行再次的篩選,使用HAVING子句。
代碼示例:
1 SELECT job,SUM(sal)
2 FROM emp
3 WHERE job<>'SALESMAN'
4 GROUP BY job
5 HAVING SUM(sal)>5000;
查詢結果:
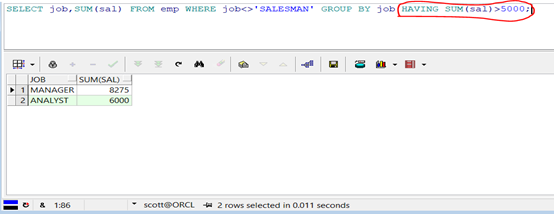
第四步:按照月工資的合計升序排列。使用ORDER BY子句。
代碼示例:
1 SELECT job,SUM(sal)
2
3 FROM emp
4
5 WHERE job<>'SALESMAN'
6
7 GROUP BY job
8
9 HAVING SUM(sal)>5000
10
11 ORDER BY SUM(sal);
查詢結果:

範例:統計所有領取佣金和布領取佣金的人數、平均工資。
代碼示例:
1 SELECT comm,AVG(sal)
2
3 FROM emp
4
5 GROUP BY comm;
查詢結果:

使用GROUP BY子句會把每一個種子值當作一個分組,所以此時不可能直接使用GROUP BY。
查詢出所有領取佣金的雇員的人數、平均工資。————直接使用WHERE子句。不需要使用GROUP BY子句
代碼示例:
1 SELECT '領取佣金' info,COUNT(*),AVG(sal) 2 FROM emp 3 WHERE comm IS NOT NULL;
查詢結果:

查詢出所有不領取佣金的雇員的人數、平均工資。————直接使用WHERE子句。不需要使用GROUP BY子句
代碼示例:
1 SELECT '不領取佣金' info,COUNT(*),AVG(sal)
2 FROM emp
3 WHERE comm IS NULL;
查詢結果:

既然此時兩個查詢結果返回的結構完全相同,那麼我們就直接連接即可。



