
該文章是圖說Java系列文章中的一篇 substring(int beginIndex, int endIndex)方法在jdk 6和jdk 7中的實現是不同的。瞭解他們的區別可以幫助你更好的使用他。為簡單起見,後文中用substring()代表substring(int beginIndex, i ...
該文章是圖說Java系列文章中的一篇
substring(int beginIndex, int endIndex)方法在jdk 6和jdk 7中的實現是不同的。瞭解他們的區別可以幫助你更好的使用他。為簡單起見,後文中用substring()代表substring(int beginIndex, int endIndex)方法。
substring() 的作用
substring(int beginIndex, int endIndex)方法截取字元串並返回其[beginIndex,endIndex-1]範圍內的內容。
String x ="abcdef";
x = x.substring(1,3);System.out.println(x);輸出內容:
bc調用substring()時發生了什麼?
你可能知道,因為x是不可變的,當使用x.substring(1,3)對x賦值的時候,它會指向一個全新的字元串:
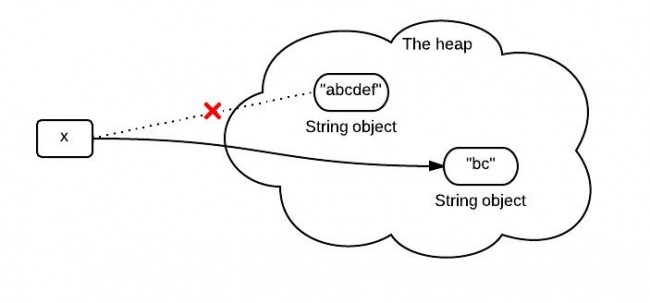
然而,這個圖不是完全正確的表示堆中發生的事情。因為在jdk6 和 jdk7中調用substring時發生的事情並不一樣。
JDK 6中的substring
String是通過字元數組實現的。在jdk 6 中,String類包含三個成員變數:char value[], int offset,int count。他們分別用來存儲真正的字元數組,數組的第一個位置索引以及字元串中包含的字元個數。
當調用substring方法的時候,會創建一個新的string對象,但是這個string的值仍然指向堆中的同一個字元數組。這兩個對象中只有count和offset 的值是不同的。
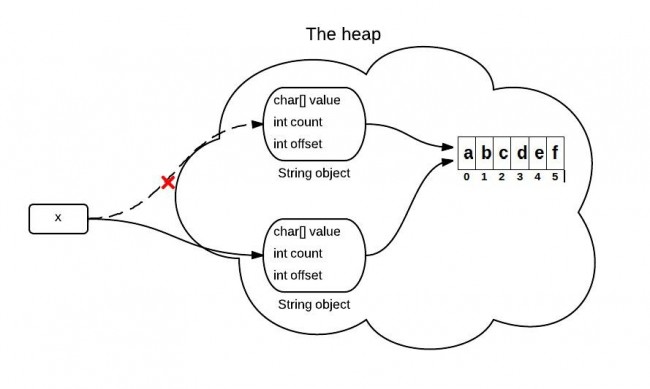
下麵是證明上說觀點的Java源碼中的關鍵代碼:
//JDK 6String(int offset,int count,char value[]){this.value = value;this.offset = offset;this.count = count;}publicString substring(int beginIndex,int endIndex){//check boundaryreturnnewString(offset + beginIndex, endIndex - beginIndex, value);}JDK 6中的substring導致的問題
如果你有一個很長很長的字元串,但是當你使用substring進行切割的時候你只需要很短的一段。這可能導致性能問題,因為你需要的只是一小段字元序列,但是你卻引用了整個字元串(因為這個非常長的字元數組一直在被引用,所以無法被回收,就可能導致記憶體泄露)。在JDK 6中,一般用以下方式來解決該問題,原理其實就是生成一個新的字元串並引用他。
x = x.substring(x, y)+""JDK 7 中的substring
上面提到的問題,在jdk 7中得到解決。在jdk 7 中,substring方法會在堆記憶體中創建一個新的數組。
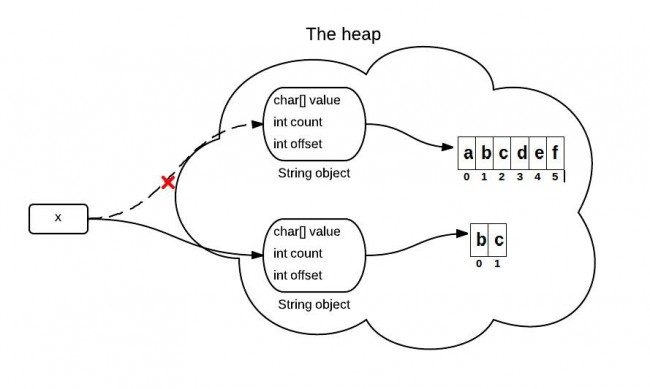
Java源碼中關於這部分的主要代碼如下:
//JDK 7publicString(char value[],int offset,int count){//check boundarythis.value =Arrays.copyOfRange(value, offset, offset + count);}publicString substring(int beginIndex,int endIndex){//check boundaryint subLen = endIndex - beginIndex;returnnewString(value, beginIndex, subLen);}(全文完)
 歡迎關註HollisChuang微信公眾賬號
歡迎關註HollisChuang微信公眾賬號轉載:HollisChuang's Blog » 三張圖徹底瞭解JDK 6和JDK 7中substring的原理及區別


