
本文要點剛要: (一)讀文本文件格式的數據函數:read_csv,read_table 1.讀不同分隔符的文本文件,用參數sep 2.讀無欄位名(表頭)的文本文件 ,用參數names 3.為文本文件制定索引,用index_col 4.跳行讀取文本文件,用skiprows 5.數據太大時需要逐塊讀取文 ...
本文要點剛要:
(一)讀文本文件格式的數據函數:read_csv,read_table
1.讀不同分隔符的文本文件,用參數sep
2.讀無欄位名(表頭)的文本文件 ,用參數names
3.為文本文件制定索引,用index_col
4.跳行讀取文本文件,用skiprows
5.數據太大時需要逐塊讀取文本數據用chunksize進行分塊。
(二)將數據寫成文本文件格式函數:to_csv
範例如下:
(一)讀取文本文件格式的數據集
1.read_csv和read_table的區別:
#read_csv預設讀取用逗號分隔符的文件,不需要用sep來指定分隔符
import pandas as pd
pd.read_csv('C:\\Users\\xiaoxiaodexiao\\pythonlianxi\\test0424\\data.csv')
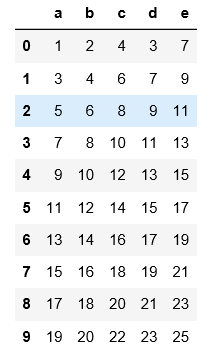
#read_csv如果讀的是用非逗號分隔符的文件,必須要用sep指定分割符,不然讀出來的是原文件的樣子,數據沒被分割開
import pandas as pd
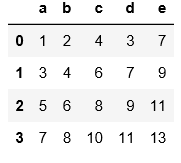
pd.read_csv('C:\\Users\\xiaoxiaodexiao\\pythonlianxi\\test0424\\data.txt')

#與上面的例子可以對比一下區別
import pandas as pd
pd.read_csv('C:\\Users\\xiaoxiaodexiao\\pythonlianxi\\test0424\\data.txt',sep='|')
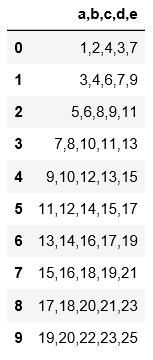
#read_table讀取文件時必須要用sep來指定分隔符,否則讀出來的數據是原始文件,沒有分割開。
import pandas as pd
pd.read_table('C:\\Users\\xiaoxiaodexiao\\pythonlianxi\\test0424\\data.csv')
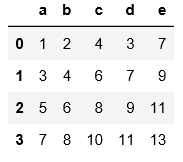
#read_table讀取數據必須指定分隔符
import pandas as pd
pd.read_table('C:\\Users\\xiaoxiaodexiao\\pythonlianxi\\test0424\\data.txt',sep='|')
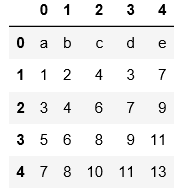
2.讀取文本文件時不用header和names指定表頭時,預設第一行為表頭
#用header=None表示數據集沒有表頭,會預設用阿拉伯數字填充表頭和索引
pd.read_table('C:\\Users\\xiaoxiaodexiao\\pythonlianxi\\test0424\\data.txt',sep='|',header=None)
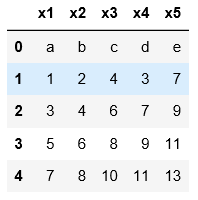
#用names可以自定義表頭
pd.read_table('C:\\Users\\xiaoxiaodexiao\\pythonlianxi\\test0424\\data.txt',sep='|',
names=['x1','x2','x3','x4','x5'])
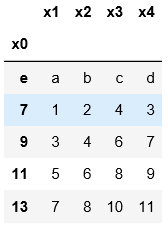
3.預設用阿拉伯數字指定索引;用index_col指定某一列作為索引
names=['x1','x2','x3','x4','x0']
pd.read_table('C:\\Users\\xiaoxiaodexiao\\pythonlianxi\\test0424\\data.txt',sep='|',
names=names,index_col='x0')
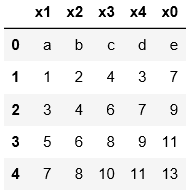
4.以下示例是用skiprows將hello對應的行跳過後讀取其他行數據,不管首行是否作為表頭,都是將表頭作為第0行開始數
可以對比一下三個例子的區別進行理解
pd.read_csv('C:\\Users\\xiaoxiaodexiao\\pythonlianxi\\test0424\\data1.txt')

names=['x1','x2','x3','x4','x0']
pd.read_csv('C:\\Users\\xiaoxiaodexiao\\pythonlianxi\\test0424\\data1.txt',names=names,
skiprows=[0,3,6])
pd.read_csv('C:\\Users\\xiaoxiaodexiao\\pythonlianxi\\test0424\\data1.txt',
skiprows=[0,3,6])
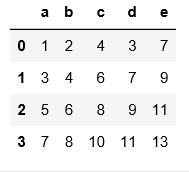
pd.read_csv('C:\\Users\\xiaoxiaodexiao\\pythonlianxi\\test0424\\data1.txt',header=None,
skiprows=[0,3,6])
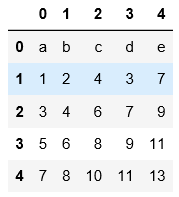
5.分塊讀取,data1.txt中總共8行數據,按照每塊3行來分,會讀3次,第一次3行,第二次3行,第三次1行數據進行讀取。
註意這裡在分塊的時候跟跳行讀取不同的是,表頭沒作為第一行進行分塊讀取,可通過一下兩個例子對比進行理解。
chunker = pd.read_csv('C:\\Users\\xiaoxiaodexiao\\pythonlianxi\\test0424\\data1.txt',chunksize=3)
for m in chunker:
print(len(m))
print m

chunker = pd.read_csv('C:\\Users\\xiaoxiaodexiao\\pythonlianxi\\test0424\\data1.txt',header=None,
chunksize=3)
for m in chunker:
print(len(m))
print m

(二)將數據寫入文本格式用to_csv
以data.txt為例,註意寫出文件時,將索引也寫入了
data=pd.read_table('C:\\Users\\xiaoxiaodexiao\\pythonlianxi\\test0424\\data.txt',sep='|')
print data

#可以用index=False禁止索引的寫入。
data=pd.read_table('C:\\Users\\xiaoxiaodexiao\\pythonlianxi\\test0424\\data.txt',sep='|')
data.to_csv('C:\\Users\\xiaoxiaodexiao\\pythonlianxi\\test0424\\outdata.txt',sep='!',index=False)

#可以用columns指定寫入的列
data=pd.read_table('C:\\Users\\xiaoxiaodexiao\\pythonlianxi\\test0424\\data.txt',sep='|')
data.to_csv('C:\\Users\\xiaoxiaodexiao\\pythonlianxi\\test0424\\outdata2.txt',sep=',',index=False,
columns=['a','c','d'])



