
字元流按字元個數輸入、輸出數據。 1.Reader類和FileReader類 Reader類是字元輸入流的超類,FileReader類是讀取字元的便捷類,此處的便捷是相對於其父類(另一個字元輸入流)InputStreamReader而言的。 read()每單字元讀取: read(char[] c)讀 ...
字元流按字元個數輸入、輸出數據。
1.Reader類和FileReader類
Reader類是字元輸入流的超類,FileReader類是讀取字元的便捷類,此處的便捷是相對於其父類(另一個字元輸入流)InputStreamReader而言的。
read()每單字元讀取:
import java.io.*;
public class FileR {
public static void main(String[] args) throws IOException {
FileReader fr = new FileReader("D:/temp/hello.txt");
int ch = 0;
while((ch=fr.read())!=-1) {
System.out.println((char)ch);
}
fr.close();
}
}
read(char[] c)讀取字元緩衝到字元數組:
import java.io.*;
public class FileR {
public static void main(String[] args) throws IOException {
FileReader fr = new FileReader("D:/temp/hello.txt");
int len = 0;
char[] buf = new char[1024];
while ((len=fr.read(buf))!=-1) {
System.out.println(new String(buf,0,len)); //字元數組轉換為字元串輸出
}
fr.close();
}
}
2.Writer類和FileWriter類
Writer類是字元輸出流的超類,FileWriter類是輸出字元的便捷類,此處的便捷是相對於其父類(另一個字元輸出流)InputStreamWriter而言的。
import java.io.*;
public class FileW {
public static void main(String[] args) throws IOException {
FileWriter fw = new FileWriter("d:/temp/hellow.txt");
fw.write("a你好,謝謝,再見!");
fw.flush(); //儘量每write一次就flush一次
fw.close();
}
}
flush()和close()的註意點:
(1).close()自帶flush(),它在關閉流之前會自動先flush()一次。
(2).flush()後流還能繼續使用,而close()後流就被關閉不可再被使用。
(3).為了防止數據丟失,應儘量每write一次就flush一次。但最後一次可不用flush(),因為close()自帶flush()。
3.InputStreamReader類和OutputStreamWriter類
FileReader和FileWriter分別是InputStreamReader和OutputStreamWriter的便捷類,便捷類的意思是前兩個類可以簡化後兩個類,同時又能達到相同的目的。實際上,FileReader和FileWriter是InputStreamReader和OutputStreamWriter的子類,等價於它們的預設形式。
InputStreamReader、OutputStreamWriter可以看作是位元組流和字元流之間的橋梁。前者將字元按照字元集轉換為位元組(二進位格式)並讀取字元,這稱為編碼(例如:a->97(01100001));後者將位元組(二進位格式)按照字元集轉換為字元並寫入字元,這稱為解碼(例如:97(01100001)->a)。
InputStreamReader、OutputStreamWriter的預設字元集採用的是操作系統的字元集,對於簡體中文的Windows系統,預設採用的是GBK字元集。
以下是OutputStreamWriter以utf-8編碼格式寫入字元的示例:
import java.io.*;
public class OutputStreamW {
public static void main(String[] args) throws IOException {
WriteCN();
}
public static void WriteCN() throws IOException {
OutputStreamWriter osw =
new OutputStreamWriter(new FileOutputStream("d:/temp/hellow.txt"),"utf-8");
//new OutputStreamWriter(new FileOutputStream("d:/temp/hellow.txt"));//採用預設gbk字元集寫入
osw.write("a你好,謝謝,再見!!!");
osw.flush();
osw.close();
}
}
以下是InputStreamReader讀取上述文件d:\temp\hellow.txt中字元的示例,因為hellow.txt中的字元編碼為UTF-8,因此讀取時必須也也utf-8讀取。假如以預設的gbk字元集讀取,由於每次讀取2個位元組,將會把utf-8字元(中文字元占用3個位元組)切分開導致亂碼:
import java.io.*;
public class InputStreamR {
public static void main(String[] args) throws IOException {
ReadCN();
}
public static void ReadCN() throws IOException {
InputStreamReader isr =
new InputStreamReader(new FileInputStream("d:/temp/hellow.txt"),"utf-8");
// new InputStreamReader(new FileInputStream("d:/temp/hellow.txt"));//預設字元集,亂碼
/* int ch = 0;
while ((ch=isr.read())!=-1) {
System.out.println((char)ch);
} */
int len = 0;
char[] buf = new char[1024];
while ((len=isr.read(buf))!=-1) {
System.out.println(new String(buf,0,len));
}
isr.close();
}
}
4.位元組流、字元流的關係(編碼、解碼、編碼表(字元集))
首先說明編碼、解碼和編碼表(字元集)的關係。
編碼:將字元根據編碼表轉換為二進位的0/1數字。
解碼:將二進位根據編碼表轉換為字元。
編碼表:
1.ascii碼表:使用一個位元組中的7位二進位就能表示字母、數字、英文標點等字元。
2.iso8859-1碼表:(也即latin-1),使用一個位元組中的8位二進位,其內包含了ascii碼表中的字元,此外還擴展了歐洲一些語言的字元。
3.GB2312:中國自編的編碼表,2個位元組,兩個位元組都是負數,收錄了6700多個漢字。相容ascii。
GBK:K代表擴展的意思,是GB2312的擴展,占用2位元組,大部分兩個位元組都是負數,但少數幾個字元的第二個位元組是正數,其內包含了GB2312的碼表,收錄了2萬多個漢字。
GB18030:新的編碼表,變長(可能1、2、4位元組),其內包含了GB2312和GBK的碼表,收錄了7萬多個漢字。
4.Unicode:收錄了全世界幾乎所有的字元,但無論什麼字元都占用2個位元組,不足兩個位元組的0占位。
5.UTF-8:解決了unicode的缺點,它使用變長1-4位元組來表示一個字元(空間能省則省),其中ascii部分仍占用1個位元組(仍相容ascii)。和Unicode不同的是,UTF-8中的中文字元占用3個位元組。
因此,需要知道的是:
- (1)所有字元集都相容ascii碼表;
- (2)一般考慮字元集時,需要考慮的碼表大致分:ascii、latin-1、GBK、utf-8。
- (3)不同碼表之間,因為編碼、解碼規則不一樣,會導致文本亂碼問題。
- (4)GBK不會和ascii衝突。因為GBK即使有正數的位元組,也一定是在第二個位元組。因為解碼時,如果讀取的第一個位元組為正數,則一定是ascii字元,如果讀取的第一個位元組為負數,則一定是中文字元,此時會繼續讀取下一個位元組。
- (5)以上都是文本的編碼、解碼。除了文本,還有媒體類數據,它們都有各自的編碼、解碼規則。實際使用過程中,採用什麼方式編碼、解碼,取決於打開文件的程式,例如不能用記事本類程式打開媒體類(圖片、音頻、視頻等)文件,不能用視頻播放器打開文本文件。
再來說明字元流和位元組流的關係,也就是實現字元流的原理。
對於字元串"abcde",使用位元組流能夠很輕鬆地讀取、寫入,但對於字元串"a你好,謝謝,再見!"這樣的中文字元(假設它們是gbk編碼的),無論是採用位元組流的單位元組讀取還是以位元組數組讀取多個位元組的方式都很難實現讀取、寫入。例如,一次讀取2個位元組,則第一次讀取的兩個位元組為a和"你"的前一個位元組,a的ascii碼為97,"你"的前一個位元組也是一個數值,假如為196,gbk對196也有對應的編碼,假設對應的字元為"浣",於是第一次的兩個位元組經過解碼,得到"a浣",而非"a你",這已經亂碼了。而且很多時候,編碼表中有某些數值並沒有對應的字元,這時看到的就是亂七八糟的符號。
如果採用字元流讀取、寫入字元,則會先將其轉換為位元組數組,再對位元組數組中的位元組進行編碼、解碼。也就是說,字元流的底層還是位元組流。而且根據不同的編碼表(字元集),轉換為位元組存儲到位元組數組中時,數值和占用位元組數也是不一樣的。
以InputStreamReader和OutputStreamWriter這兩個字元流按照utf-8字元集解析"你好"兩個字元為例。
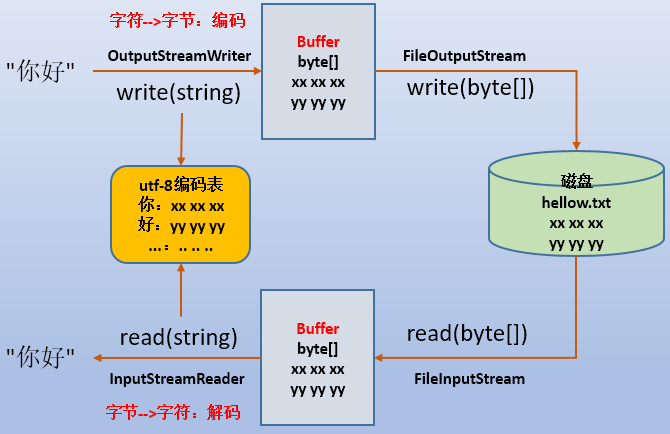
5.InputStreamReader/OutputStreamWriter和FileReader/FileWriter的區別
FileReader/FileWriter類是InputStreamReader/OutputStreamWriter類的子類,它們都能處理字元。區別是前者是後者的便捷類,是後者的預設形式。
也就是說,當InputStreamReader/OutputStreamWriter採用預設字元集時,它們和FileReader/FileWriter是等價的。即以下三條代碼是等價的。
InputStreamReader isr = new InputStreamReader(new FileInputStream("a.txt")); //預設字元集
InputStreamReader isr = new InputStreamReader(new FileInputStream("a.txt"),"gbk"); //指定為預設字元集
FileReader fr = new FileReader("a.txt"); //使用便捷類FileReader
所以,如果採用的是預設字元集,最佳方式是採用FileReader/FileWriter,但如果需要指定字元集,則必須使用InputStreamReader/OutputStreamWriter。
6.字元流複製文本類文件
import java.io.*;
public class CopyFileByChar {
public static void main(String[] args) throws IOException {
copy("d:/temp/big.log","d:/temp/big_bak.log");
}
public static void copy(String src,String dest) throws IOException {
//字元集必須設置正確
InputStreamReader isr = new InputStreamReader(new FileInputStream(src),"gbk");
OutputStreamWriter osw = new OutputStreamWriter(new FileOutputStream(dest),"gbk");
int len = 0;
char[] buf = new char[1024];
while((len=isr.read(buf))!=-1) {
osw.write(buf,0,len);
osw.flush();
}
osw.close();
isr.close();
}
}
7.操作行:BufferedReader類BufferedWriter類
它們是緩衝類字元流,分別用於創建帶有輸入、輸出緩衝區的輸入、輸出字元流。
其實和字元數組的作用差不多,只不過設計為緩衝類後可以使用類的一些方法,最常用的是操作行的方法:
- BufferedReader的readLine()方法:讀取一行數據。只要遇到換行符(\n)、回車符(\r)都認為一行結束。當讀取到流末尾時返回null。
- BufferedWriter的newLine()方法:寫入一個換行符。
例如,下麵是用這兩個類來複制文本文件d:\temp\big.log。
import java.io.*;
public class CopyByBuffer {
public static void main(String[] args) throws IOException {
copy("d:/temp/big.log","d:/temp/big_bak.log");
}
public static void copy(String src,String dest) throws IOException {
// src buffer & dest buffer
InputStreamReader isr = new InputStreamReader(new FileInputStream(src),"gbk");
BufferedReader bufr = new BufferedReader(isr);
OutputStreamWriter osw = new OutputStreamWriter(new FileOutputStream(dest),"gbk");
BufferedWriter bufw = new BufferedWriter(osw);
String line = null;
while((line=bufr.readLine())!=null) {
bufw.write(line);
bufw.newLine();
bufw.flush();
}
bufw.close();
bufr.close();
}
}
對於大文件來說,這BufferedReader類操作數據其實比字元數組的速度要慢,因為每次緩衝一行,一行才不到1k而已(除非行很長),而char[]通常都設置為好幾k,一次就能讀很多行。
註:若您覺得這篇文章還不錯請點擊右下角推薦,您的支持能激發作者更大的寫作熱情,非常感謝!


