
同步容器 同步容器是指那些對所有的操作都進行加鎖(synchronize)的容器。比如Vector、HashTable和Collections.synchronizedXXX返回系列對象: 可以看到,它的絕大部分方法都被加了同步(帶個小時鐘圖標)。 雖然Vector這麼勞神費力地搞了這麼多同步方法, ...
同步容器
同步容器是指那些對所有的操作都進行加鎖(synchronize)的容器。比如Vector、HashTable和Collections.synchronizedXXX返回系列對象:
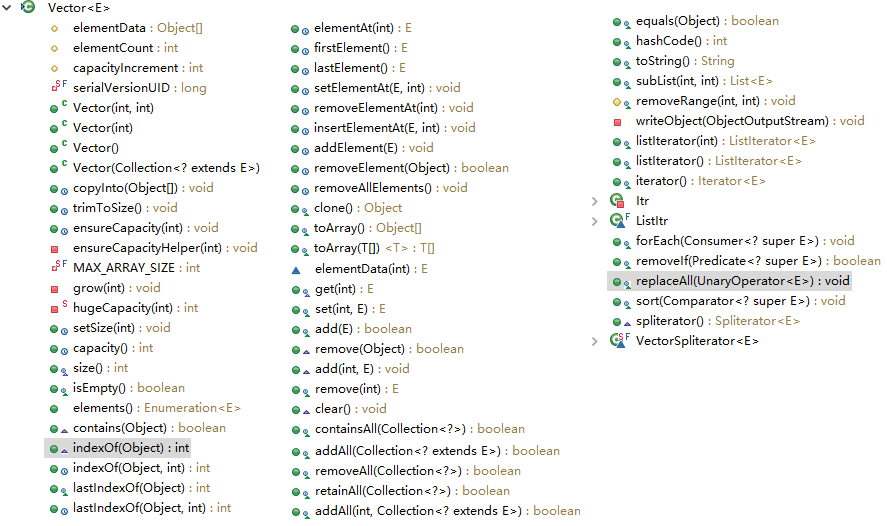
可以看到,它的絕大部分方法都被加了同步(帶個小時鐘圖標)。
雖然Vector這麼勞神費力地搞了這麼多同步方法,但在最終使用的時候它並不一定真的“安全”。
同步容器的複合操作不安全
雖然Vector的方法增加了同步,但是像下麵這種“先檢查再操作”複合操作其實是不安全的:
//兩個同步的原子操作合在一起就不再具有原子性了 public void getLast(Vector vector) { int size = vector.size(); vector.get(size); }
啊?不是說Vector和HashTable是線程安全的嗎?所以,以後再聽說某個類是線程安全的,不能就覺得萬事大吉了,應該留個心想想其安全的真正含義。
Vector和HashTable這些類的線程安全指的是它所提供的單個方法具有原子性,一個線程訪問的時候其他線程不能訪問。在進行覆核操作時還需要咱們自己去保證線程安全:
public void getLast(Vector vector) { //客戶端顯式鎖保證符合操作的同步 synchronized (vector) { int size = vector.size(); vector.get(size); } }
這種不安全的問題在遍歷集合的時候仍然存在。Vector能做的就是在出現多線程訪問導致集合內容衝突時給一個異常提醒:
final void checkForComodification() { if (modCount != expectedModCount) throw new ConcurrentModificationException(); }
一定要明白,ConcurrentModificationException異常的真正目的其實是在提醒咱的系統中存在多線程安全問題,需要我們去解決。不解決程式也能跑,但是指不定那天就見鬼了,這要靠運氣。
書中還指出,像Vector這樣把鎖隱藏在代碼端的設計,會導致客戶端經常忘記去同步。即“狀態與保護它的代碼越遠,程式員越容易忘記在訪問狀態時使用正確的同步”。這裡的狀態就是指的容器的數據元素。
即使同步容器在單方法的上能夠做到“安全”,但是它會使CPU的吞吐量下降、降低系統的伸縮性,因此才有了下麵的併發容器。
併發容器
針對於每一種同步容器,都設計了一個對應的併發容器:
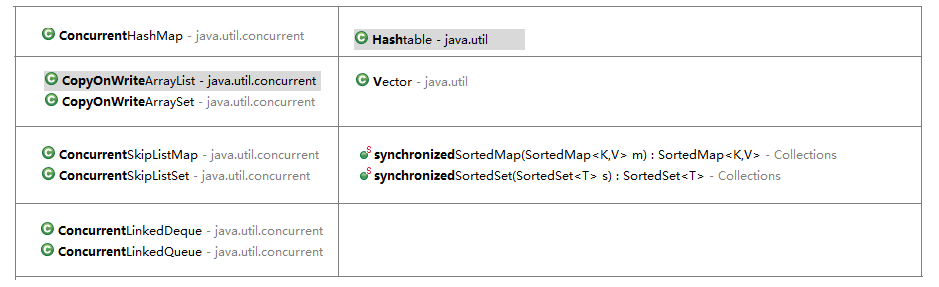
隊列(Queue)和雙向隊列(Deque)是新增的集合類型。
ConcurrentHashMap使用分段鎖運行多個線程併發訪問
為瞭解決同步訪問時的低吞吐量問題,ConcurrentHashMap使用了分段鎖的方式,允許多個線程併發訪問。
同步鎖的機制是,使用16把鎖,每一把鎖負責1/16的散列桶的同步訪問。你可能猜到了,如果存儲的數據採用了一個糟糕的散列函數,那麼ConcurrentHashMap的效果HashTable一樣了。
ConcurrentHashMap也有它的問題,既然允許多個線程同時訪問了,那麼size()和isEmpty()方法的結果就不准確了。書中說這是一種權衡,認為多線程狀態下size和isEmpty方法沒有那麼重要了。但是在使用ConcurrentHashMap是我們應該知道確實有這樣的問題。
電腦世界里經常出現這樣的權衡問題。是的,沒有免費午餐,得到一些好處的同時就需要付出另外一些代價。典型的例子就是分散式系統中的CAP原則,即一致性、可用性和分區容錯性三者不可兼得。
CopyOnWriteArrayList應用於讀遠大於寫的場景
顧名思義,添加或修改時直接複製一個新的底層數組來存儲數據。因為要複製,所以比較適合應用於寫遠小於讀的場景。比如事件通知系統,註冊和註銷(寫)的操作就遠大於接收事件的操作。
阻塞隊列應用於生產者-消費者模式
隊列嘛就是一個存儲單元,數據可以按序存入然後按序取出。關鍵在於阻塞。在生產者-消費者模式中。生成者可以往隊列里存數據,消費者負責從隊列里獲取數據。阻塞的含義是當隊列里沒有數據時,消費者在take數據時會被阻塞,直到有生產者往隊列里put了一個數據。相反,如果隊列里的數據已經滿了,那麼生產者也只能等到消費者take走了一個數據之後才能put數據。
阻塞隊列的兩個好處:
1,使生產者和消費者解耦,他們之間不需要額外的直接對話通信;
2,阻塞隊列可以協調生產者和消費者的速度,讓較快的一方等待較慢的一方,不至於使未處理的消息累積過大;
阻塞方法與中斷方法
個人總結:catch到InterruptException時要麼繼續往上拋,實在不能拋了就要標記當期線程為interrupt。
Thread.currentThread().interrupt();
切忌try-catch完了之後什麼都不做,直接給和諧了。
同步工具類
CountDownLatch(計數器)-等待多個結果
當需要等待多個條件都滿足時才執行下一步,就可以用Latch來做計數器:
public class CountDownLatchTest { public static void main(String[] args) throws InterruptedException { final Random r = new Random(); final CountDownLatch latch = new CountDownLatch(5); for(int i = 0; i < 5; i++) { new Thread(new Runnable() { @Override public void run() { try { Thread.sleep(r.nextInt(5) * 1000); } catch (InterruptedException e) { Thread.currentThread().interrupt(); } System.out.println(Thread.currentThread().getName() + " execute complated!"); latch.countDown(); } }).start(); } System.out.println("Wait for sub thread execute..."); latch.await(); System.out.println("All Thread execute complated!"); } }
測試結果:
Wait for sub thread execute... Thread-4 execute complated! Thread-1 execute complated! Thread-0 execute complated! Thread-3 execute complated! Thread-2 execute complated! All Thread execute complated!
Semaphore(信號量)控制資源併發訪問數量

Semaphore可以實現資源訪問控制,在初始化時可以指定一個數量,這個數量表示可以同時訪問資源的線程數。
也可以理解成許可證。訪問資源前問Semaphore獲取(acquire)訪問許可,如果還有剩餘的許可就能正常獲取到,否則就會等待,知道有其他線程歸還(release)許可了。
public static void main(String[] args) { Semaphore s = new Semaphore(3); for(int i = 0;i<10;i++) { new Thread(new Runnable() { @Override public void run() { try { System.out.println(System.currentTimeMillis() +":"+ Thread.currentThread().getName() + " waiting for Permit..."); s.acquire(); System.out.println(System.currentTimeMillis() +":"+ Thread.currentThread().getName() + " doing his job..."); Thread.sleep(5000); s.release(); } catch (InterruptedException e) { Thread.currentThread().interrupt(); } } }).start(); } }
測試結果如下,可以看到每次同時執行的線程數永遠只有3個:
1514272606904:Thread-0 waiting for Permit... 1514272606904:Thread-3 waiting for Permit... 1514272606904:Thread-0 doing his job... 1514272606904:Thread-1 waiting for Permit... 1514272606905:Thread-5 waiting for Permit... 1514272606904:Thread-3 doing his job... 1514272606905:Thread-1 doing his job... 1514272606905:Thread-4 waiting for Permit... 1514272606905:Thread-6 waiting for Permit... 1514272606905:Thread-2 waiting for Permit... 1514272606905:Thread-7 waiting for Permit... 1514272606905:Thread-8 waiting for Permit... 1514272606905:Thread-9 waiting for Permit... 1514272611905:Thread-5 doing his job... 1514272611905:Thread-6 doing his job... 1514272611905:Thread-4 doing his job... 1514272616905:Thread-7 doing his job... 1514272616905:Thread-2 doing his job... 1514272616905:Thread-8 doing his job... 1514272621906:Thread-9 doing his job...
當把Semaphore的許可數量設置為1時,Semaphore就變成了一個互斥鎖。
Barrier(柵欄)實現並行計算
柵欄有著和計數器一樣的功能,他們都可以等待一些線程執行完畢後再近些某項操作。
不同之處在於柵欄可以重置,它可以讓多個線程同時到達某個狀態或結果之後再繼續往下一個目標出發。
並行計算時,各個子線程計算的速度可能不一樣,需要等待每個線程計算完成之後再繼續執行下一步計算:
垂直線表示計算狀態,水平箭頭的長度表示計算時間的差異。
public class BarrierTest { static int hours = 0; static boolean stopAll = false; public static void main(String[] args) { CyclicBarrier barrier = new CyclicBarrier(3, new Runnable() { @Override public void run() { System.out.println("every on stop,wait for a minute."); hours++; if(hours>8) { System.out.println("times up,Go off work!"); stopAll = true; } } }); Random r = new Random(); //barrier. for(int i = 0;i<3;i++) { new Thread(new Runnable() { @Override public void run() { while(!stopAll) { System.out.println(Thread.currentThread().getName() + " is working..."); try { Thread.sleep(r.nextInt(2) * 1000); barrier.await(); } catch (InterruptedException e) { Thread.currentThread().interrupt(); } catch (BrokenBarrierException e) { e.printStackTrace(); } } } }).start(); } } }
測試結果:
... ... every on stop,wait for a minute. Thread-1 is working... Thread-2 is working... Thread-0 is working... every on stop,wait for a minute. Thread-1 is working... Thread-0 is working... Thread-2 is working... every on stop,wait for a minute. Thread-0 is working... Thread-1 is working... Thread-2 is working... every on stop,wait for a minute. times up,Go off work!
另外還有一種叫Exchanger的Barrier,它可以用來做線程間的數據交換。
構建高效可伸縮的結果緩存
簡單的用synchronize + HashMap實現結果緩存:
public class ComputeMemroyCache<T,V> { HashMap<T,V> cache = new HashMap<T,V>(); Computable<T,V> computable; public ComputeMemroyCache(Computable<T,V> computable) { this.computable = computable; } public synchronized V compute(T t) { V result = cache.get(t); if(result == null) { result = computable.compute(t); cache.put(t, result); } return result; } } public interface Computable<T,V> { public V compute(T t); }
這種緩存有時甚至比沒有緩存還要糟糕:
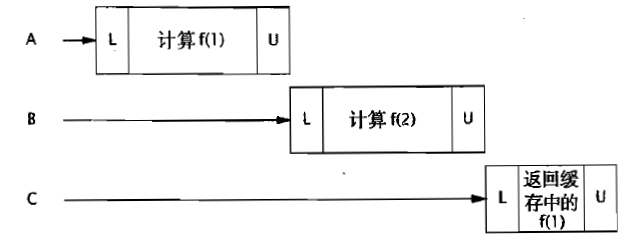
如果計算的對象不多,那麼系統僅僅是有個很長的熱身階段,否則的話,低命中率的緩存沒有起到實際的作用,糟糕的同步反而使程式的吞吐量急劇下降。
如果去掉同步,並且使用ConcurrentHashMap,結果會好一點兒,但是還是會出現重覆計算一個結果的情況。因為compute中有“先檢查後計算”的行為(非原子操作)。
這裡一個最嚴重的問題是,計算代碼和客戶度調用同步了,就是一定要計算到一個結果之後才往Map中緩存結果,如果計算時間過長,就會導致後面很多請求的堆積。下麵的改進中使用了FutureTask來講計算推遲到另外一個線程,從而可以立即將“正在計算”的動作存放都Map中:
public class FutureTaskComputeMemroyCache<T,V> { ConcurrentHashMap<T,FutureTask<V>> cache = new ConcurrentHashMap<T,FutureTask<V>>(); Computable<T,V> computable; public FutureTaskComputeMemroyCache(Computable<T,V> computable) { this.computable = computable; } public V compute(T t) throws InterruptedException, ExecutionException { FutureTask<V> result = cache.get(t); if(result == null) { result = new FutureTask<V>(new Callable<V>() { @Override public V call() throws Exception { return computable.compute(t); } }); cache.put(t, result); result.run(); } return result.get(); } }
還缺一點兒,上面的代碼還是會存在重覆計算的問題。還是因為“檢查並計算”的複合操作!真是夠煩人的。這裡要記住:既然都使用了ConcurrentHashMap,那麼在存取值的時候一定要記住是否還能簡單的get,一定要考慮複合操作是否需要避免的問題。因為ConcurrentHashMap已經我們準備好瞭解決複合操作的putIfAbsent方法。使用了ConcurrentHashMap而沒使用putIfAbsent那太可惜也太浪費。
public class FutureTaskComputeMemroyCache<T,V> { ConcurrentHashMap<T,FutureTask<V>> cache = new ConcurrentHashMap<T,FutureTask<V>>(); Computable<T,V> computable; public FutureTaskComputeMemroyCache(Computable<T,V> computable) { this.computable = computable; } public V compute(T t) throws InterruptedException, ExecutionException { FutureTask<V> result = cache.get(t); if(result == null) { result = new FutureTask<V>(new Callable<V>() { @Override public V call() throws Exception { return computable.compute(t); } }); FutureTask<V> existed = cache.putIfAbsent(t, result); if(existed==null) {//之前沒有啟動計算時這裡才需要啟動 result.run(); } } return result.get(); } }
待完善
1,如果FutureTask計算失敗,需要從緩存種移除;
2,緩存過期
這裡僅嘗試實現了緩存過期:
public class TimeoutFutureTaskComputeMemroyCache<T,V> { ConcurrentHashMap<T,ComputeFutureTask<V>> cache = new ConcurrentHashMap<T,ComputeFutureTask<V>>(); Computable<T,V> computable; public TimeoutFutureTaskComputeMemroyCache(Computable<T,V> computable) { this.computable = computable; } public V compute(T t) throws InterruptedException, ExecutionException { ComputeFutureTask<V> result = cache.get(t); if(result == null) { result = new ComputeFutureTask<V>(new Callable<V>() { @Override public V call() throws Exception { return computable.compute(t); } },1000 * 60);//一分鐘超時 ComputeFutureTask<V> existed = cache.putIfAbsent(t, result); if(existed==null) {//之前沒有啟動計算時這裡才需要啟動 result.run(); }else if(existed.timeout()) {//超時重新計算 cache.replace(t, existed, result); result.run(); } } return result.get(); } class ComputeFutureTask<X> extends FutureTask<X>{ long timestamp; long age; public ComputeFutureTask(Callable<X> callable,long age) { super(callable); timestamp = System.currentTimeMillis(); this.age =age; } public long getTimestamp() { return timestamp; } public void setTimestamp(long timestamp) { this.timestamp = timestamp; } public boolean timeout() { return System.currentTimeMillis() - timestamp > age; } } }


