
消息系統 消息系統被用於各種場景,如解耦數據生產者,緩存未處理的消息。Kafka 可作為傳統的消息系統的替代者,與傳統消息系統相比,kafka有更好的吞吐量、更好的可用性,這有利於處理大規模的消息。 根據經驗,通常消息傳遞對吞吐量要求較低,但可能要求較低的端到端延遲,並經常依賴kafka可靠的dur ...
消息系統
消息系統被用於各種場景,如解耦數據生產者,緩存未處理的消息。Kafka 可作為傳統的消息系統的替代者,與傳統消息系統相比,kafka有更好的吞吐量、更好的可用性,這有利於處理大規模的消息。
根據經驗,通常消息傳遞對吞吐量要求較低,但可能要求較低的端到端延遲,並經常依賴kafka可靠的durable機制。
在這方面,Kafka可以與傳統的消息傳遞系統(ActiveMQ 和RabbitMQ)相媲美。
存儲系統
寫入到kafka中的數據是落地到了磁碟上,並且有冗餘備份,kafka允許producer等待確認,通過配置,可實現直到所有的replication完成複製才算寫入成功,這樣可保證數據的可用性。
Kafka認真對待存儲,並允許client自行控制讀取位置,你可以認為kafka是-種特殊的文件系統,它能夠提供高性能、低延遲、高可用的日誌提交存儲。
日誌聚合
日誌系統一般需要如下功能:日誌的收集、清洗、聚合、存儲、展示。Kafka常用來替代其他日誌聚合解決方案。
和Scribe、Flume相比,Kafka提供同樣好的性能、更健壯的堆積保障、更低的端到端延遲。
日誌會落地,導致kafka做日誌聚合更昂貴。
kafka可實現日誌的:
- 清洗(需編碼)
- 聚合(可靠但昂貴,因需落地磁碟)
- 存儲
ELK是現在比較流行的日誌系統。在kafka的配合 下才是更成熟的方案,kafka在ELK技術棧中,主要起到buffer的作用,必要時可進行日誌的匯流。
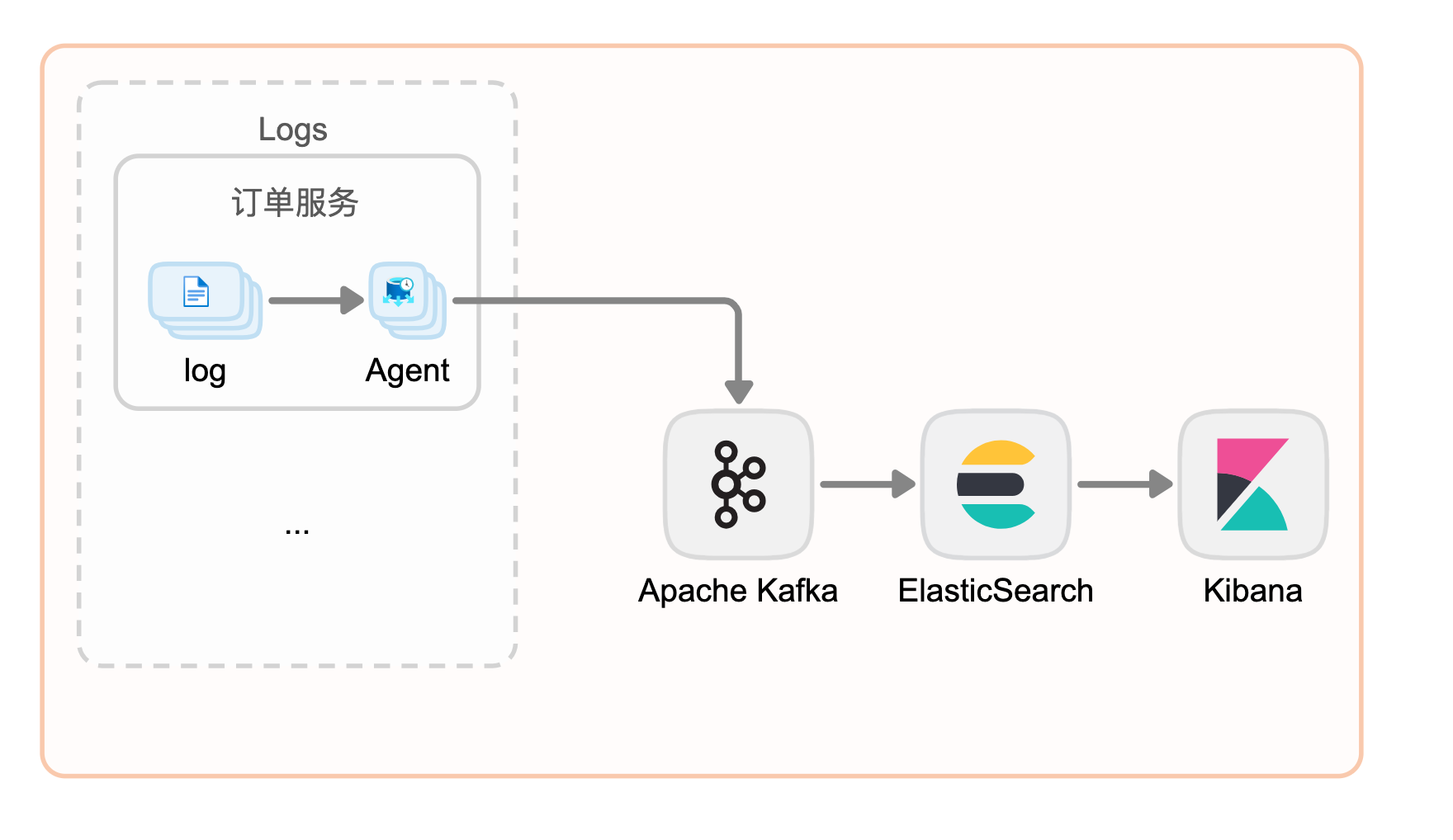
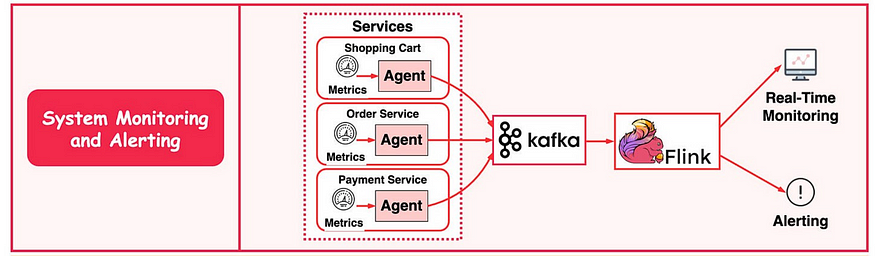
系統監控與報警
與日誌分析系統類似,我們需要收集系統指標以進行監控和故障排除。
區別在於指標是結構化數據,而日誌是非結構化文本。指標數據發送到 Kafka 併在 Flink 中聚合。聚合數據由實時監控儀錶板和警報系統(例如 PagerDuty)使用。
Commit Log
Kafka 可充當分散式系統的一種外部提交日誌。日誌有助於在節點之間複製數據,並充當故障節點恢複數據的重新同步機制。
Kafka 中的日誌壓縮功能有助於支持這種用法。
跟蹤網站活動 - 推薦系統
kafka的最初始作用就是,將用戶行為跟蹤管道重構為一組實時發佈-訂閱源。
把網站活動(瀏覽網頁、搜索或其他的用戶操作)發佈到中心topics中,每種活動類型對應一個topic。基於這些訂閱源,能夠實現一系列用例,如實時處理、實時監視、批量地將Kafka的數據載入到Hadoop或離線數倉系統,進行離線數據處理並生成報告。
每個用戶瀏覽網頁時都生成了許多活動信息,因此活動跟蹤的數據量通常非常大。(Kafka實際應用)
像亞馬遜這樣的電子商務網站使用過去的行為和相似的用戶來計算產品推薦。
下圖展示了推薦系統的工作原理。 Kafka 傳輸原始點擊流數據,Flink 對其進行處理,模型訓練則使用來自數據湖的聚合數據。
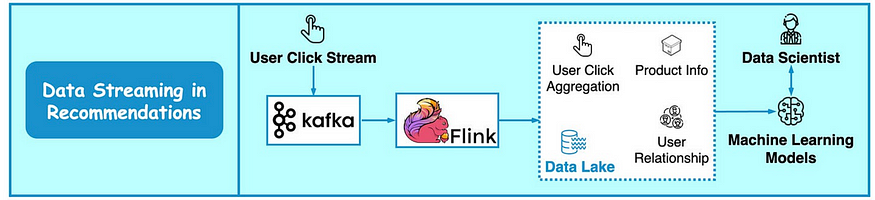 這使得能夠持續改進每個用戶的推薦的相關性。 Kafka 的另一個重要用例是實時點擊流分析。
這使得能夠持續改進每個用戶的推薦的相關性。 Kafka 的另一個重要用例是實時點擊流分析。
流處理 - kafka stream API
Kafka社區認為僅僅提供數據生產、消費機制是不夠的,他們還要提供流數據實時處理機制
從0.10.0.0開始, Kafka通過提供Strearms API來提供輕量,但功能強大的流處理。實際上就是Streams API幫助解決流引用中一些棘手的問題,比如:
- 處理無序的數據
- 代碼變化後再次處理數據
- 進行有狀態的流式計算
Streams API的流處理包含多個階段,從input topics消費數據,做各種處理,將結果寫入到目標topic, Streans API基於kafka提供的核心原語構建,它使用kafka consumer、 producer來輸入、輸出,用Kfka來做狀態存儲。
流處理框架: flink、spark streaming、Storm本是正統流處理框架,Kafka在流處理更多扮演流存儲角色。
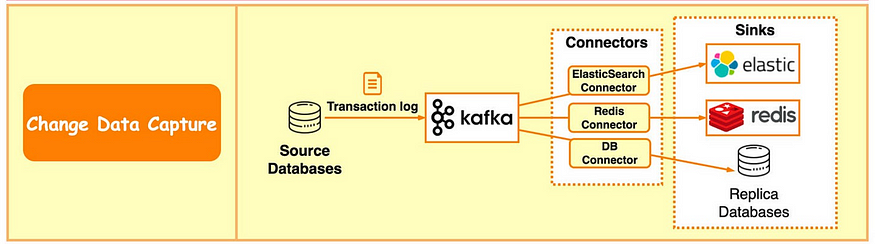
CDC( Change data capture,變更數據捕獲)
- CDC將資料庫變化流式傳輸到其他系統,以進行複製或緩存/索引更新
- Kafka 還是構建data pipeline的絕佳工具,使用它從各種來源獲取數據、應用處理規則並將數據存儲在倉庫、數據湖或數據網格中
- 如下,事務日誌發送到 Kafka 並由 ElasticSearch、Redis 和輔助資料庫攝取。
系統遷移
升級遺留服務具有挑戰性:
- 舊語言
- 複雜邏輯
- 缺乏測試
可利用MQ降低風險。
為升級訂單服務,更新舊的訂單服務以消費來自 Kafka 的輸入並將結果寫入 ORDER topic。新訂單服務使用相同的輸入並將結果寫入 ORDERNEW topic:
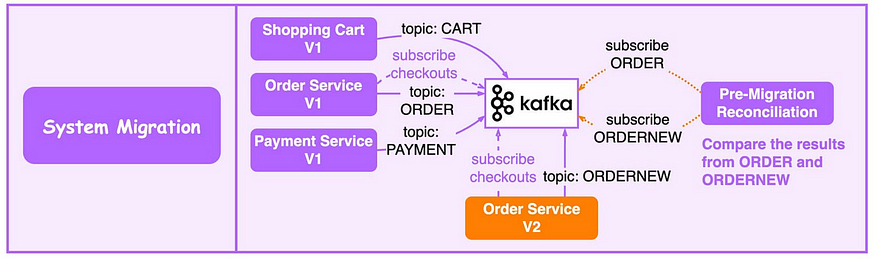
Reconciliation調節服務比較 ORDER 和 ORDERNEW。如果它們相同,則新服務通過測試。
事件溯源
如果將事件作為系統中的一等公民(即事實來源),那存儲應用程式的狀態就是一系列事件,系統中的其他所有內容都可根據這些持久且不可變的事件重新計算。
事件溯源就是捕獲一系列事件中狀態的變化。通常使用 Kafka 作為主要事件存儲。如果發生任何故障、回滾或需要重建狀態,可隨時重新應用 Kafka 中的事件。
本文由博客一文多發平臺 OpenWrite 發佈!

