十六、C++字元串(一) 1、原生字元串實現將兩個字元串拼接 //原生字元串實現將兩個字元串拼接 #include <iostream> #include <locale> int main() { char strA[0x10] = "123"; //定義字元串 char strB[0x10] = ...
2 命名的藝術
本章包括
- 命名
- 命名空間
"電腦科學中只有兩件難事:緩存失效和命名。"這句話出自菲爾-卡爾頓(Phil Karlton)之口,他是網景公司(Netscape)的程式員。
2.1 命名
命名是你和Python共用某物身份的一種方式。通常,這意味著您要唯一地標識一個事物,使其與程式中所有其他被命名的事物區分開來。例如,美國的社會安全號是給人們的,這樣他們就可以在美國的使用環境中唯一地識別自己。這串唯一的號碼可以幫助人們就業、納稅、購買保險,以及從事其他各種需要全國唯一標識符的活動。
這是否意味著社會保障號是唯一事物的好名字?其實不然。除非你能進入使用該號碼的系統,否則它是完全不透明的。它沒有傳遞任何關於所標識事物的信息。
讓我們把唯一名稱的概念提升到另一個層次。有一種標準化的標識符被稱為通用唯一標識符(UUID)。UUID是一串字元,就所有實際目的而言,在全世界都是唯一的。UUID示例如下
f566d4a9-6c93-4ee6-b3b3-3a1ffa95d2ae
您可以使用Python內置的UUID模塊,根據UUID值創建有效的變數名:
>>> import uuid
>>> f"v_{uuid.uuid4().hex}"
'v_02f9c8953e2d4fb8ba83b65f1237f82f'
您可以用這種方法創建變數名,以便唯一標識應用程式中的所有內容。這些變數名在整個應用程式中和已知世界中都是唯一的。
以這種方式命名變數也是一種完全不可用的命名約定。變數名完全沒有傳遞任何關於所標識事物的信息。這樣的變數名輸入起來也非常長,不可能記住,使用起來也不方便。
2.1.1 命名事物
創建有用的變數名需要花費精力,但作為開發人員,這是值得的。隨著時間的推移,你會發現變數名很難更改。這是因為隨著應用程式的開發和使用,對現有變數的依賴性會增加。選擇好的變數名可以避免在使用過程中更改變數名。
變數名的長度也與編寫代碼的工作量有關。編程確實涉及到大量的鍵入,這意味著意義和簡短之間的平衡非常重要。
你突然發現,整個語言都是你尋找命名單詞和短語的地方。您的目標是找到既能附加元信息,又足夠簡短,不會妨礙編寫或閱讀一行程式代碼的詞語。這就限制了你在命名時可以或應該做的事情。就像畫家在有限的調色板上創作一樣,你可以選擇沮喪,也可以在這種限制下發揮想象力,創作出具有藝術性和創造力的作品。
你要編寫的許多程式都會包括對事物集合的迴圈、計數和相加。下麵是一個二維表格的迭代代碼示例:
t = [[12, 11, 4], [3, 22, 105], [0, 47, 31]]
for i, r in enumerate(t):
for j, it in enumerate(r):
process_item(i, j, it)
這段代碼功能完善。t 變數由一個 Python 列表組成,代表一個二維表格。process_item() 函數需要知道項目--it 變數--在表中的行和列位置,才能正確處理它。變數 t、i、j、r 和 it 完全可以使用,但卻沒有告訴讀者它們的意圖。
修改後:
table = [[12, 11, 4], [3, 22, 105], [0, 47, 31]]
for row_index, row in enumerate(table):
for column_index, item in enumerate(row):
process_item(row_index, column_index, item)
開發過程中的另一個常見操作是計數和創建總數。下麵是一些簡單的示例:
total_employees = len(employees)
total_parttime_employees = len([
employee for employee in employees if employee.part_time
])
total_managers = sum([
employee for employee in employees if employee.manager
])
在前面的示例中,我們可以看到幾個非常好的命名規則。employees 這個名字賦予了變數意義。複數 employees的使用表明這是可迭代的集合。它還表明該集合內部有一個或多個代表雇員的事物。列表理解中的變數employee表明它是雇員集合中的單個項目。
變數total_employees、total_parttime_employees和total_ managers的名稱中使用了total,說明瞭它們所指的是什麼。每一個變數都是一個總計數。每個變數名的第二部分表示被計算的事物。
除了數值計算,你還經常會遇到一些已經有名字的事物,比如公司、社區或小組中的人。當你收集用戶輸入或通過名字搜索某人時,有一個有用的變數名會讓你更容易想到代碼中要表示的事物:
full_name = "John George Smith"
根據您編寫代碼的目的,這可能是一個完全可以接受的變數名,用來表示姓名。通常情況下,在處理人名時,您需要更細化的變數名,並希望用部分變數名來表示人名:
first_name = "John"
middle_name = "George"
last_name = "Smith"
這些變數名也能很好地發揮作用,而且與full_name一樣,這些變數名賦予了變數所代表的含義。下麵是另一種變體
fname = "John"
mname = "George"
lname = "Smith"
這個版本採用了變數命名的慣例。這樣的約定意味著你選擇了一種模式來創建人的變數名。使用約定意味著讀者必須知道並理解所使用的約定。上例中的折衷方法是減少鍵入,但變數名的含義仍然清晰。此外,由於變數名以單行編輯字體垂直排列,因此視覺效果可能更好。
採用約定是在變數命名限制條件下提高工作效率的一種技巧。如果速記命名約定在視覺上對你更有吸引力,那麼在可視化解析代碼時,你就能識別模式並找出錯別字。
建立約定俗成的習慣有助於減輕開發人員的認知負擔。你可以更多地考慮要解決的問題,而不是考慮如何命名。
2.1.2 命名實驗
你可能不記得了,早期的個人電腦只有很小的硬碟驅動器。早期的操作系統也沒有目錄或子目錄的概念;硬碟上的所有文件都存在於一個全局目錄中。此外,文件名僅限於8個字元、點(.)和 3 個字元的擴展名,擴展名通常用來表示文件包含的內容。
正因為如此,人們發明瞭奇異而複雜的文件命名約定,以保持唯一性並防止文件名衝突。這些命名約定是以犧牲有邏輯意義的文件名為代價的。例如1995年10月創建的簡歷文件可能是這樣的
res1095.doc
解決這個問題的辦法是在操作系統中增加對命名子目錄的支持,並取消文件名字元長度限制。現在,每個人都對此非常熟悉,因為你可以創建幾乎無限深的目錄和子目錄結構。
下麵是一個要求你滿足的規範:你工作的會計部門要求所有費用報告的文件名都必須相同:expense.xlsx。你需要創建一個目錄結構,讓所有expenses.xlsx文件都能存在,並且不會相互碰撞或覆蓋,以保存和跟蹤這些費用文件。
約束條件是要求所有支出報告文件都有一個固定的文件名。隱含的限制條件是,無論你設計什麼樣的目錄結構,都必須適用於你的工作所產生的儘可能多的費用報告。創建子目錄的功能就是幫助你解決這個問題並將費用報告文件分開的工具。
任何解決方案都取決於你在工作中創建了多少份開支報告。如果你的工作是初級軟體開發人員,你可能一年只出差幾次。在這種情況下,你只需提供粗粒度的支出.xlsx文件,就可以將其分開。這種簡單的結構將所有支出報告集中在一個名為expenses的根目錄下。每份費用報告都存在於一個目錄中,該目錄以創建費用報告的完整日期命名。使用YYYY-MM-DD的日期格式會使目錄在許多操作系統上顯示時按有用的時間順序排序。
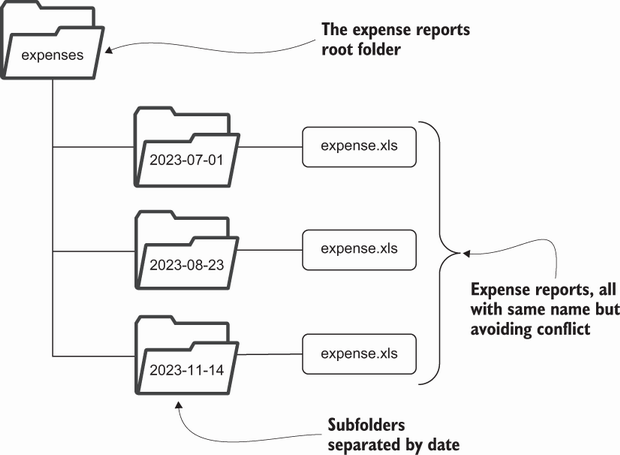
但是,如果你是一名銷售工程師,你很可能經常出差,可能每天要會見多個客戶。這就改變了你處理約束的方式,要求你的目錄結構支持更多的粒度,以便將所有expenses.xlsx文件分開。對於銷售工程師來說,一個可行的解決方案是使用年、月、日和客戶名稱值作為子目錄。這樣,即使每天拜訪多個客戶,也能保持expenses.xlsx文件的獨立性。這樣就形成了一種慣例,即特定expenses.xlsx文件路徑的每一部分都有意義和價值。
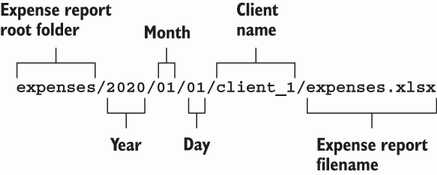
從前面的實驗中我們可能看不出什麼,但我們創建的變數名是有意義和約定俗成的。請看特定支出報告的目錄路徑。你創建了命名空間,每個命名空間都縮小了所包含內容的範圍。從左到右閱讀路徑,你會發現路徑的每一段都由 / 字元分隔,在前一段的上下文中創建了一個新的、範圍更小的命名空間。
假設你是會計師,規定了費用報告的文件命名規則。作為會計,你必須保存員工提交的所有費用報告。你將受到與生成費用報告的員工相同的限制,但要保持所有員工的費用報告彼此不同並相互分離,這就增加了複雜性。

創建一個目錄結構來處理增加的複雜性,可以包括更高級別的部門和員工抽象。創建一個提供這種粒度的目錄結構來跟蹤和保存所有員工費用報告是可行的。考慮到如何創建該結構,會計部門顯然應該重新考慮文件命名要求和限制,並設計一個更好的系統。
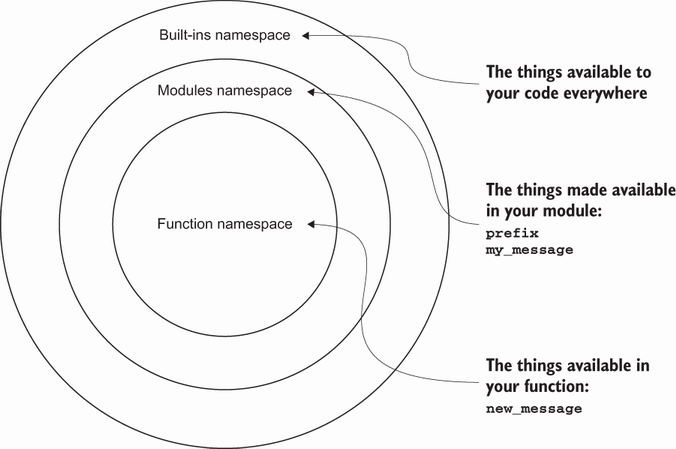
2.2 命名空間
Python編程語言提供了創建名稱空間的能力。在處理命名變數的約束、賦予它們意義、保持它們相對較短並避免衝突時,命名空間為您提供了很大的能力和控制。可以通過在命名空間放置變數名來實現這一點。在開始創建自己的命名空間之前,讓我們先看看該語言提供的名稱空間。
2.2.1內置級
當Python開始運行應用程式時,它會創建一個builtins命名空間,其中builtins是Python中最外層的命名空間,包含您可以隨時訪問的所有函數。例如,print()和open()函數存在於內置命名空間中。
你可以通過在Python交互提示符下輸入以下命令來查看內置命名空間中的內容:
>>> dir(__builtins__)
['ArithmeticError', 'AssertionError', 'AttributeError', 'BaseException', 'BlockingIOError', 'BrokenPipeError', 'BufferError', 'BytesWarning', 'ChildProcessError', 'ConnectionAbortedError', 'ConnectionError', 'ConnectionRefusedError', 'ConnectionResetError', 'DeprecationWarning', 'EOFError', 'Ellipsis', 'EncodingWarning', 'EnvironmentError', 'Exception', 'False', 'FileExistsError', 'FileNotFoundError', 'FloatingPointError', 'FutureWarning', 'GeneratorExit', 'IOError', 'ImportError', 'ImportWarning', 'IndentationError', 'IndexError', 'InterruptedError', 'IsADirectoryError', 'KeyError', 'KeyboardInterrupt', 'LookupError', 'MemoryError', 'ModuleNotFoundError', 'NameError', 'None', 'NotADirectoryError', 'NotImplemented', 'NotImplementedError', 'OSError', 'OverflowError', 'PendingDeprecationWarning', 'PermissionError', 'ProcessLookupError', 'RecursionError', 'ReferenceError', 'ResourceWarning', 'RuntimeError', 'RuntimeWarning', 'StopAsyncIteration', 'StopIteration', 'SyntaxError', 'SyntaxWarning', 'SystemError', 'SystemExit', 'TabError', 'TimeoutError', 'True', 'TypeError', 'UnboundLocalError', 'UnicodeDecodeError', 'UnicodeEncodeError', 'UnicodeError', 'UnicodeTranslateError', 'UnicodeWarning', 'UserWarning', 'ValueError', 'Warning', 'WindowsError', 'ZeroDivisionError', '__build_class__', '__debug__', '__doc__', '__import__', '__loader__', '__name__', '__package__', '__spec__', 'abs', 'aiter', 'all', 'anext', 'any', 'ascii', 'bin', 'bool', 'breakpoint', 'bytearray', 'bytes', 'callable', 'chr', 'classmethod', 'compile', 'complex', 'copyright', 'credits', 'delattr', 'dict', 'dir', 'divmod', 'enumerate', 'eval', 'exec', 'exit', 'filter', 'float', 'format', 'frozenset', 'getattr', 'globals', 'hasattr', 'hash', 'help', 'hex', 'id', 'input', 'int', 'isinstance', 'issubclass', 'iter', 'len', 'license', 'list', 'locals', 'map', 'max', 'memoryview', 'min', 'next', 'object', 'oct', 'open', 'ord', 'pow', 'print', 'property', 'quit', 'range', 'repr', 'reversed', 'round', 'set', 'setattr', 'slice', 'sorted', 'staticmethod', 'str', 'sum', 'super', 'tuple', 'type', 'vars', 'zip']
該命令在__builtins__對象上運行dir (directory)。
在使用內置命名空間時,完全有可能用您自己的命名空間覆蓋名稱空間中的對象。例如,你可以這樣定義一個函數:
def open(...):
# run some code here
這個函數遮蔽了已經在內置命名空間中定義的open()函數。你可以通過創建如下的函數來處理這個問題:
def my_own_open(...):
# run some code here
參考資料
- 軟體測試精品書籍文檔下載持續更新 https://github.com/china-testing/python-testing-examples 請點贊,謝謝!
- 本文涉及的python測試開發庫 謝謝點贊! https://github.com/china-testing/python_cn_resouce
- python精品書籍下載 https://github.com/china-testing/python_cn_resouce/blob/main/python_good_books.md
- Linux精品書籍下載 https://www.cnblogs.com/testing-/p/17438558.html
2.2.2模塊級別
將程式代碼分解為包含邏輯分組功能的多個文件是一種有用的慣例。這樣做有以下好處:
- 將相似的功能放在一起
- 防止程式文件變得太長
- 創建命名空間
utility.py:
def add(a, b):
return f"{a} {b}"
main.py
import utility
def add(a, b):
return a + b
print(add(12, 12))
print(utility.add(12, 12))
utility.py文件將兩個add()函數定義分開。在main.py文件中,import utility語句告訴Python將utility.py文件中的所有對象拉到utility的新名稱空間中。
在導入文件時使用from
通過利用文件系統目錄結構,您可以創建名稱空間層次結構。就像前面的目錄結構命名實驗一樣,這為您提供了更多的工具來為您創建的層次結構創建意義和範圍。
在main.py文件所在的文件夾中創建utilities的新目錄。將utility.py文件移動到utilities目錄,並將其重命名為strings.py。
在創建包含功能的目錄層次結構時,需要記住的一件事是需要創建一個__init__.py文件。該文件必須存在於每個目錄中,以讓Python知道該目錄包含功能或它的路徑。當__init__.py文件存在於目錄中時,該目錄就是Python包。
通常__init__.py文件是空的,但它不必是空的。只要包含該文件的路徑是import語句的一部分,該文件中的任何代碼都將執行。
在此基礎上,在實用程式目錄中創建一個空的__init__.py文件。完成後,像這樣修改main.py文件:
from utilities import strings
def add(a, b):
return a + b
print(add(12, 12))
print(strings.add(12, 12))
如果您使用過任何Python的標準模塊,如sys,您可能會註意到這些標準模塊不存在於您的程式的工作目錄中,例如您之前創建的strings.py模塊。Python通過路徑列表搜索你想要導入的模塊,首先是工作目錄。
>>> import sys
>>> sys.path
['', 'D:\\anaconda\\python310.zip', 'D:\\anaconda\\DLLs', 'D:\\anaconda\\lib', 'D:\\anaconda', 'C:\\Users\\徐榮中\\AppData\\Roaming\\Python\\Python310\\site-packages', 'D:\\anaconda\\lib\\site-packages', 'D:\\anaconda\\lib\\site-packages\\win32', 'D:\\anaconda\\lib\\site-packages\\win32\\lib', 'D:\\anaconda\\lib\\site-packages\\Pythonwin']
列表中的第一個元素是一個空字元串。Python將在當前工作目錄中查找模塊。這就是它找到utilities包和該包中string模塊的方式。
這也意味著,如果你創建了一個模塊,並將其命名為Python系統模塊,Python將首先找到你的包並使用它,而忽略系統包。在命名包和模塊時,請記住這一點。
在我們的簡短示例中,import sys語句導致Python搜索前面提到的路徑列表。因為工作目錄中不存在sys模塊,所以它會在其他路徑中查找標準模塊。
路徑列表在使用pip命令安裝包或模塊時使用。pip命令將在列表中的一個路徑中安裝包。如前所述,建議使用Python虛擬環境來防止pip安裝到您的電腦系統的Python版本中。