
0 大綱 [Apache Flink]2017年12月發佈的1.4.0版本開始,為流計算引入里程碑特性:TwoPhaseCommitSinkFunction。它提取了兩階段提交協議的通用邏輯,使得通過Flink來構建端到端的Exactly-Once程式成為可能。同時支持: 數據源(source) 和 ...
0 大綱
[Apache Flink]2017年12月發佈的1.4.0版本開始,為流計算引入里程碑特性:TwoPhaseCommitSinkFunction。它提取了兩階段提交協議的通用邏輯,使得通過Flink來構建端到端的Exactly-Once程式成為可能。同時支持:
- 數據源(source)
- 和輸出端(sink)
包括Apache Kafka 0.11及更高版本。它提供抽象層,用戶只需實現少數方法就能實現端到端Exactly-Once語義。
新功能及Flink實現邏輯:
- 描述Flink checkpoint機制如何保證Flink程式結果的Exactly-Once的
- 顯示Flink如何通過兩階段提交協議與數據源和數據輸出端交互,以提供端到端的Exactly-Once保證
- 通過一個簡單的示例,瞭解如何使用TwoPhaseCommitSinkFunction實現Exactly-Once的文件輸出
1 Flink應用中的Exactly-Once語義
Exactly-Once,指每個輸入的事件隻影響最終結果一次。即使機器或軟體故障,既沒有重覆數據,也不會丟數據。
Flink很久就提供Exactly-Once,checkpoint機制是Flink有能力提供Exactly-Once語義的核心。
一次checkpoint是以下內容的一致性快照:
- 應用程式的當前狀態
- 輸入流的位置
Flink可配置一個固定時間點,定期產生checkpoint,將checkpoint的數據寫入持久存儲系統,如S3或HDFS。將checkpoint數據寫入持久存儲是非同步,即Flink應用程式在checkpoint過程中可以繼續處理數據。
如果發生機器或軟體故障,重新啟動後,Flink應用程式將從最新的checkpoint點恢復處理; Flink會恢復應用程式狀態,將輸入流回滾到上次checkpoint保存的位置,然後重新開始運行。這意味著Flink可以像從未發生過故障一樣計算結果。
Flink 1.4.0前,Exactly-Once語義僅限Flink應用程式內部,沒有擴展到Flink數據處理完後發送的大多數外部系統。Flink應用程式與各種數據輸出端進行交互,開發人員自己維護組件上下文保證Exactly-Once語義。
為提供端到端的Exactly-Once語義 – 即除了Flink應用程式內部,Flink寫入的外部系統也需要能滿足Exactly-Once語義 – 這些外部系統必須提供提交或回滾的方法,然後通過Flink的checkpoint機制協調。
分散式系統中,協調提交和回滾的常用方法是2pc協議。討論Flink的TwoPhaseCommitSinkFunction如何利用2pc提供端到端的Exactly-Once語義。
2 Flink應用程式端到端的Exactly-Once語義
Kafka經常與Flink使用。Kafka 0.11版本添加事務支持。這意味著現在通過Flink讀寫Kafaka,並提供端到端的Exactly-Once語義有了必要支持。
Flink對端到端的Exactly-Once語義的支持不僅局限Kafka,可將它與任何一個提供必要的協調機制的源/輸出端一起使用。如Pravega,來自DELL/EMC的開源流媒體存儲系統,通過Flink的TwoPhaseCommitSinkFunction也能支持端到端的Exactly-Once語義。
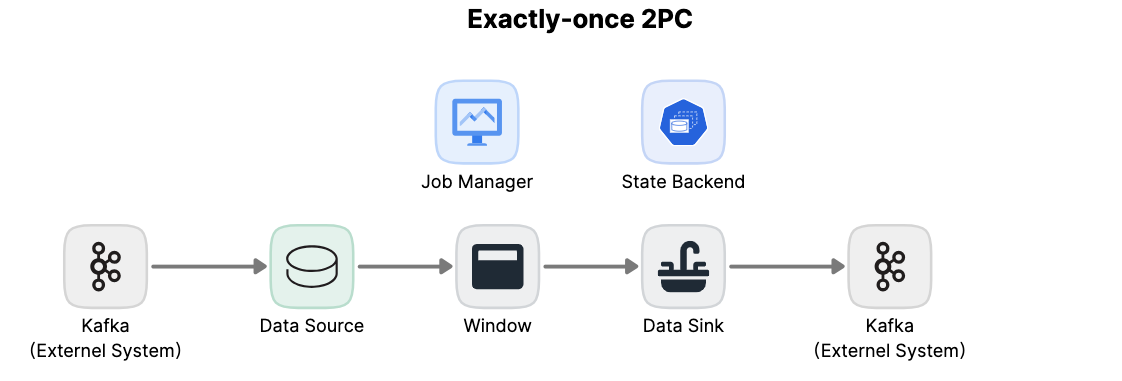
示常式序有:
- 從Kafka讀取的數據源(Flink內置的KafkaConsumer)
- 視窗聚合
- 將數據寫回Kafka的數據輸出端(Flink內置的KafkaProducer)
要使數據輸出端提供Exactly-Once保證,須將所有數據通過一個事務提交給Kafka。提交捆綁了兩個checkpoint之間的所有要寫數據。這確保在故障時,能回滾寫入的數據。但分散式系統中,通常有多個併發運行的寫入任務,所有組件須在提交或回滾時“一致”才能確保一致結果。Flink使用2PC及預提交階段解決這問題。
pre-commit
checkpoint開始時,即2PC的“預提交”階段。當checkpoint開始時,Flink的JobManager會將checkpoint barrier(將數據流中的記錄分為進入當前checkpoint與進入下一個checkpoint)註入數據流。
brarrier在operator之間傳遞。對每個operator,它觸發operator的狀態快照寫入state backend。
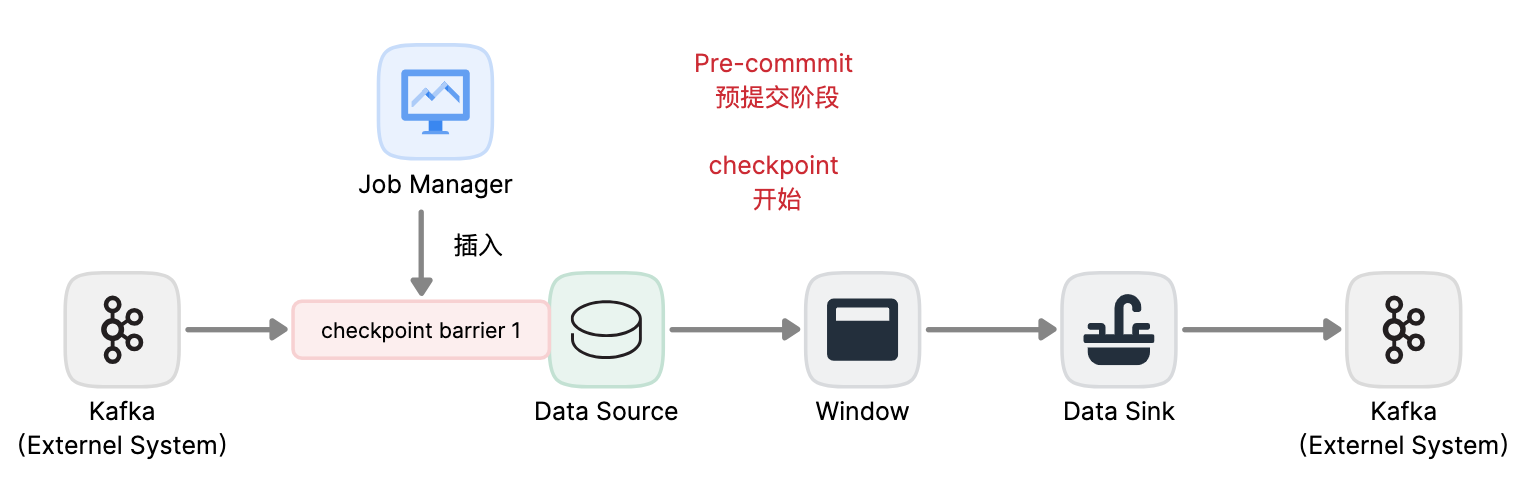
數據源保存了消費Kafka的偏移量(offset),之後將checkpoint barrier傳遞給下一operator。
這種方式僅適用於operator具有『內部』狀態。
內部狀態
指Flink state backend保存和管理的。如第二個operator中window聚合算出來的sum值。當一個進程有它的內部狀態時,除了在checkpoint前需將數據變更寫入state backend,無需在pre-commit階段執行其他操作。
Flink負責在checkpoint成功時正確提交這些寫入或故障時中止這些寫入。
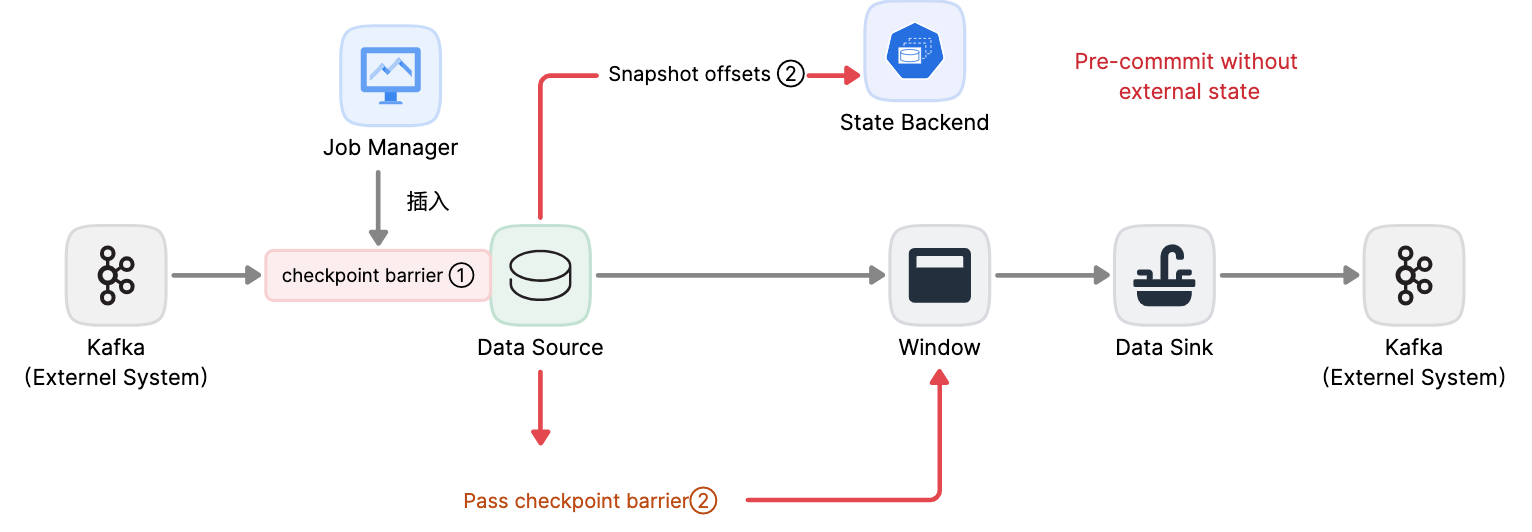
3 Flink應用啟動pre-commit階段
當進程具有『外部』狀態,需額外處理。外部狀態通常以寫入外部系統(如Kafka)的形式出現。此時,為提供Exactly-Once保證,外部系統須【支持事務】,才能和兩階段提交協議集成。
示例數據需寫入Kafka,因此數據輸出端(Data Sink)有外部狀態。此時,在預提交階段:
- 除了將其狀態寫入state backend
- 數據輸出端還必須預先提交其外部事務

當checkpoint barrier在所有operator都傳遞了一遍,並且觸發的checkpoint回調成功完成時,預提交階段結束。所有觸發的狀態快照都被視為該checkpoint的一部分。checkpoint是整個應用程式狀態的快照,包括預先提交的外部狀態。若故障,可回滾到上次成功完成快照的時間點。
下一步是通知所有operator,checkpoint已經成功了。這是2PC的提交階段,JobManager為應用程式中的每個operator發出checkpoint已完成的回調。
數據源和 widnow operator沒有外部狀態,因此在提交階段,這些operator不必執行任何操作。但是,數據輸出端(Data Sink)擁有外部狀態,此時應該提交外部事務。
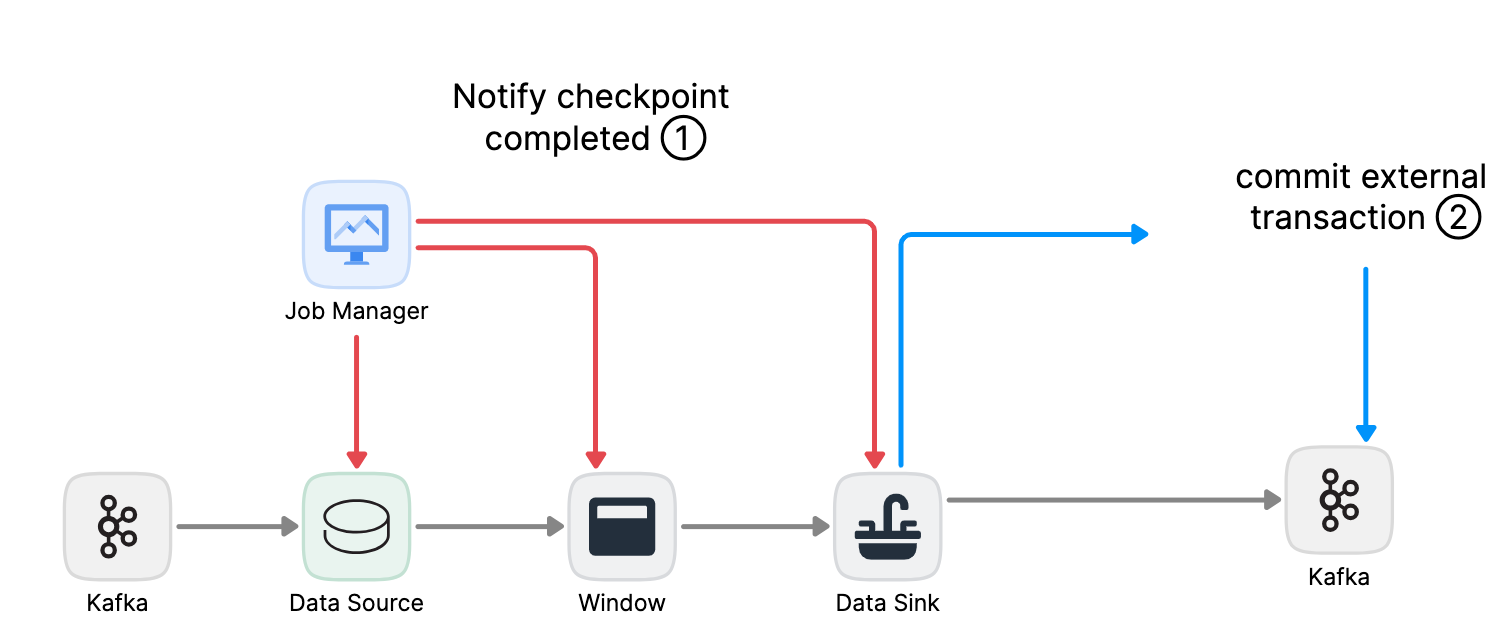
總結
- 一旦所有operator完成預提交,就提交一個commit。
- 如果至少有一個預提交失敗,則所有其他提交都將中止,我們將回滾到上一個成功完成的checkpoint。
- 在預提交成功之後,提交的commit需要保證最終成功 – operator和外部系統都需要保障這點。如果commit失敗(例如,由於間歇性網路問題),整個Flink應用程式將失敗,應用程式將根據用戶的重啟策略重新啟動,還會嘗試再提交。這個過程至關重要,因為如果commit最終沒有成功,將會導致數據丟失。
因此,我們可以確定所有operator都同意checkpoint的最終結果:所有operator都同意數據已提交,或提交被中止並回滾。
4 在Flink中實現兩階段提交Operator
完整的實現兩階段提交協議可能有點複雜,這就是為什麼Flink將它的通用邏輯提取到抽象類TwoPhaseCommitSinkFunction中的原因。
接下來基於輸出到文件的簡單示例,說明如何使用TwoPhaseCommitSinkFunction。用戶只需要實現四個函數,就能為數據輸出端實現Exactly-Once語義:
- beginTransaction – 在事務開始前,我們在目標文件系統的臨時目錄中創建一個臨時文件。隨後,我們可以在處理數據時將數據寫入此文件。
- preCommit – 在預提交階段,我們刷新文件到存儲,關閉文件,不再重新寫入。我們還將為屬於下一個checkpoint的任何後續文件寫入啟動一個新的事務。
- commit – 在提交階段,我們將預提交階段的文件原子地移動到真正的目標目錄。需要註意的是,這會增加輸出數據可見性的延遲。
- abort – 在中止階段,我們刪除臨時文件。
我們知道,如果發生任何故障,Flink會將應用程式的狀態恢復到最新的一次checkpoint點。一種極端的情況是,預提交成功了,但在這次commit的通知到達operator之前發生了故障。在這種情況下,Flink會將operator的狀態恢復到已經預提交,但尚未真正提交的狀態。
我們需要在預提交階段保存足夠多的信息到checkpoint狀態中,以便在重啟後能正確的中止或提交事務。在這個例子中,這些信息是臨時文件和目標目錄的路徑。
TwoPhaseCommitSinkFunction已經把這種情況考慮在內了,並且在從checkpoint點恢復狀態時,會優先發出一個commit。我們需要以冪等方式實現提交,一般來說,這並不難。在這個示例中,我們可以識別出這樣的情況:臨時文件不在臨時目錄中,但已經移動到目標目錄了。
在TwoPhaseCommitSinkFunction中,還有一些其他邊界情況也會考慮在內,請參考Flink文檔瞭解更多信息。
FAQ
flink sink在如果過來一個checkpoint barrier,會去存儲state,這個動作會和普通的write並行嗎?還是串列?
在Flink的checkpoint機制中,當一個Checkpoint Barrier過來時,sink會觸發對狀態的snapshot,這個snapshot動作預設是和普通的write操作並行進行的。
具體來說:
-
Flink的checkpoint機制是通過在datastream中註入Checkpoint Barrier來實現的。
-
當source接收到Checkpoint Barrier時,會將其傳遞給下游的transformation和sink。
-
當sink接收到Checkpoint Barrier時,會啟動一個新的線程來執行state snapshot(狀態保存)。
-
這個狀態snapshot線程會從狀態後端Snapshot State,並存儲檢查點。
-
而sink的主線程在接收到Checkpoint Barrier時,會繼續處理正常的write。
-
這樣,狀態snapshot和正常的write操作就是並行進行的。
但是也可以通過Sink的配置來設置snapshot和write的執行策略,主要有兩種模式:
-
並行模式(預設):snapshot和write同時進行
-
串列模式:snapshot完成後再進行write
綜上,Flink sink在預設的並行checkpoint模式下,狀態snapshot和普通的write操作是並行執行的。可以通過配置來改變其行為。這樣可以根據實際需要進行平衡。
總結
- Flink的checkpoint機制是支持兩階段提交協議並提供端到端的Exactly-Once語義的基礎。
- 這個方案的優點是: Flink不像其他一些系統那樣,通過網路傳輸存儲數據 – 不需要像大多數批處理程式那樣將計算的每個階段寫入磁碟。
- Flink的TwoPhaseCommitSinkFunction提取了兩階段提交協議的通用邏輯,基於此將Flink和支持事務的外部系統結合,構建端到端的Exactly-Once成為可能。
- 從Flink 1.4.0開始,Pravega和Kafka 0.11 producer都提供了Exactly-Once語義;Kafka在0.11版本首次引入了事務,為在Flink程式中使用Kafka producer提供Exactly-Once語義提供了可能性。
- Kafaka 0.11 producer的事務是在TwoPhaseCommitSinkFunction基礎上實現的,和at-least-once producer相比只增加了非常低的開銷。
本文由博客一文多發平臺 OpenWrite 發佈!


