第一章 電腦系統概述 “較簡單,不做過多贅述,後面會詳細學到” 第一節 電腦系統層次結構 1.電腦系統的基本組成:硬體+軟體 2.電腦硬體的基本組成:運算器+存儲器+控制器+輸入設備+輸出設備 3.系統軟體和應用軟體 系統軟體 操作系統、資料庫管理系統、語言處理程式、分散式軟體系統、網路軟體 ...
第一章 電腦系統概述
“較簡單,不做過多贅述,後面會詳細學到”
第一節 電腦系統層次結構
1.電腦系統的基本組成:硬體+軟體
2.電腦硬體的基本組成:運算器+存儲器+控制器+輸入設備+輸出設備
3.系統軟體和應用軟體
| 系統軟體 | 操作系統、資料庫管理系統、語言處理程式、分散式軟體系統、網路軟體系統、標準庫語言、服務性程式 |
|---|---|
| 應用軟體 | 科學計算類程式、工程設計類程式、數據統計與處理程式 |
4.(易考)翻譯程式:
| 彙編程式(彙編器) | 將彙編語言程式翻譯成機器語言程式 |
|---|---|
| 解釋程式(解釋器) | 將源程式翻譯成機器指令並立即執行 |
| 編譯程式(編譯器) | 將高級語言翻譯城機器語言或彙編語言 |
第二節 電腦性能指標
- 吞吐量:表徵一臺電腦在某一時間間隔內能夠處理信息量。
- 響應時間:表徵從輸入有效到系統產生響應之間的時間度量,用時間單位來度量的。
- 利用率:在給定的時間間隔系統被實際使用的時間所占的比率,用百分比表示的。
- 處理機字長:指處理機運算器中一次能夠完成二進位數運算的位數,如 32 位、64 位。
- 匯流排寬度:一般指 CPU 中運算器與存儲器之間進行互連的內部匯流排二進位位數。
- 存儲器容量:存儲器中所有存儲單元的總數目,通常用 KB、MB、GB、TB 來表示。公式一般是:位數×個數
(MAR×MDR)
- 存儲器帶寬:單位時間內從存儲器讀出的二進位數信息量,一般用位元組數/秒錶示。
- 主頻/時鐘周期:CPU 的工作節拍受主時鐘控制,主時鐘不斷產生固定頻率的時鐘度量單位是 MHz、GHz
主頻的倒數稱為 CPU 時鐘周期(T),T=1/f,度量單位是 μs、ns。
K= 103 ,M= 106 ,G= 109
易錯:時鐘頻率的提高,不能保證CPU執行速度又同倍速的提高,有時候還會減慢。
- CPU 執行時間:表示 CPU 執行一般程式所占用的 CPU 時間,可用下式計算:
CPU 執行時間 = CPU 時鐘周期數 * CPU 時鐘周期
- CPI:執行一條指令所需的平均時鐘周期數。用下式計算:
CPI = 執行某段程式所需的 CPU 時鐘周期數 / 程式包含的指令條數
- MIPS:(Million Instructions Per Second)的縮寫,表示平均每秒執行多少百萬條定點指令數,用下式計算:
MIPS = 指令數 / (程式執行時間 * 10^6)
- FLOPS:(Floating-point Operations Per Second)的縮寫,表示每秒執行浮點操作的次數,用來衡量機器浮點操作的性能。用下式計算:FLOPS = 程式中的浮點操作次數 / 程式執行時間(s)
題目總結:
①對於高級語言程式員來說,浮點數格式、乘法指令、數據如何在運算器中運算時透明的。對於彙編語言程式員,指令格式,機器構造,數據格式則不是透明的。
②在CPU中,IR、MAR、MDR對各類程式員都是透明。
③機器字長,指令字長,存儲字長
機器字長也稱字長——是電腦直接處理二進位數據的位數,機器字長一半等於內部寄存器的大小,它決定了電腦的運算精度。
指令字長——一個指令中包含的二進位代碼的位數。
存儲字長——一個存儲單元中二進位代碼的長度。
指令字長一般是存儲字長的整數倍,若指令字長等於存儲字長的2倍,則需要2次訪存來取出一條指令,因此取值周期為機器周期的2倍;若指令字長等於存儲字長,則取值周期等於機器周期的。
分享一本谷歌大佬撰寫的演算法手冊,整整 300 道 LeetCode 題目,並且都是最優解,非常強!這本手冊幫助不少朋友加入大廠,大家加油!


第二章 數據的表示和運算
一、無符號整數的表示和運算
Ⅰ、無符號整數的加法:從最低位開始,按位相加,並往更高位進位。
Ⅱ、”被減數“不變,”減數“全部按位取反,末位+1,減法變加法。
二、帶符號整數的表示和運算
帶符號的整數表示:原碼、補碼、反碼
※帶符號的整數運算可以用原碼嗎?
用原碼的話符號位不能參與運算,需要設計複雜的硬體電路才能處理,貴。
這時候就可以利用補碼來進行帶符號的整數運算。
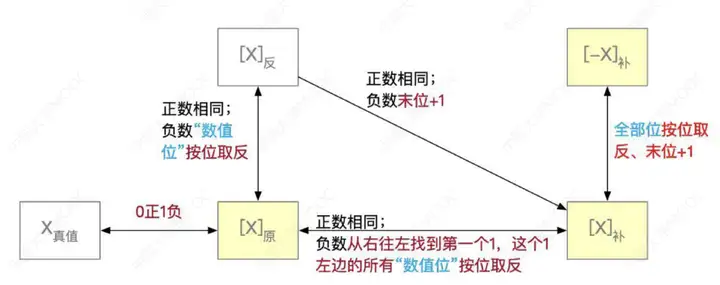
①涉及原碼和補碼的轉化。
正數:原碼->補碼,不變
負數:原碼->補碼,除符號位外,各位取反,末位+1
Ⅰ、補碼的加法
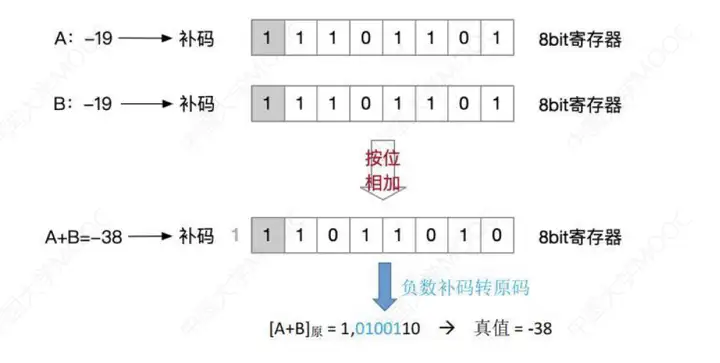
從最低位開始,然後按位相加,並往高位進位。算出來的結果,轉回原碼,就可以得到正值。
補充:補碼->原碼:類似,除符號位外,各位取反,末位+1
Ⅱ、補碼的減法
※加法電路造價便宜,減法電路造價昂貴,若將減法變為加法,更加economize。
- 那我們知道了”減數“的補碼,那如何求得”減數“負值的補碼呢?
補碼全部位取反,末位+1(易錯這裡是全部位取反,而帶符號位的負數,是除符號位外,各位取反)
其實啊,這裡的運算的邏輯結構和無符號的減法運算是一樣的,通用一套電路,省錢!
三、原碼、反碼和補碼的特性對比
| 8bit | 合法的表示範圍 | 最大的數 | 最小的數 | 真值0的表示 |
|---|---|---|---|---|
| 帶符號原碼 | -127~127 | 127 | -127 | +0=00000000 -0=10000000 |
| 帶符號反碼 | -127~127 | 127 | -127 | +0=00000000 -0=11111111 |
| 帶符號補碼 | -128~127 | 127 | -128 | -/+0=00000000 只有這一種 |
| 無符號整數 | 0~255 | 255 | 0 | 00000000 |
| 帶符號移碼 | -128~127 | 127 | -128 | 0=10000000 只有這一種 |
原碼和反碼的合法表示範圍完全相同,而且都有兩種表示真值0的方法。
補碼的合法表示範圍多一個負數,原因就是只有一種0的表示方法,因為-0的補碼就是00000000
四、移碼,定點小數
移碼:在補碼的基礎上符號位取反。且移碼只能表示整數。表示範圍和補碼相同。
移碼的作用:移碼的作用就是方便電腦比較兩個數數值的大小。
定點小數的編碼表示:原碼、反碼、補碼。
運算規則和整數的運算規則一模一樣。
五、電路的基本原理和加法器設計
Ⅰ、補碼/無符號整數加減法運算器
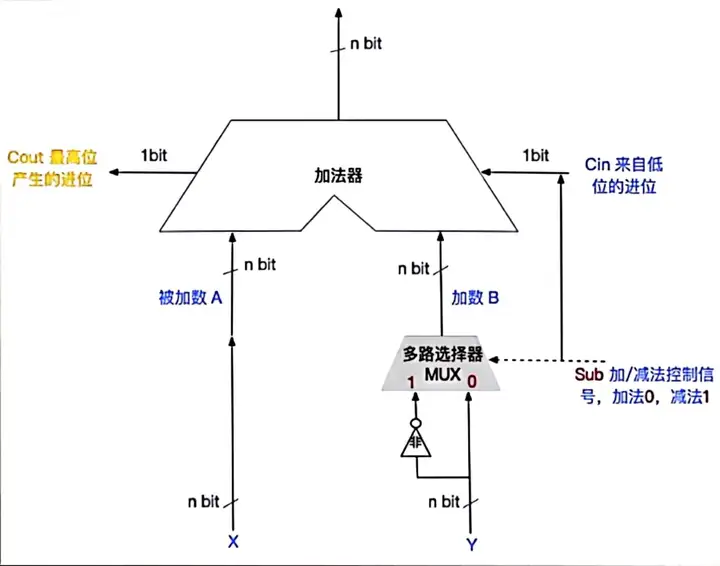
減法運算過程:
①首先Sub信號置為1;
②多路選擇器的值為1,Y(減數)經過非門,都取反;
③cin來自低位加1;
Ⅱ、標誌位生成
①進位標誌CF (Carry Flag)只對無符號運算有意義
當運算結果的最高有效位有進位(加法)或借位(減法)時,進位標誌置1,
即CF = 1;否則CF= 0。
49H + 6DH=B6H, 沒有進位:CF = 0
BBH + 6AH=(1)25H,有進位:CF = 1
②零標誌ZF (Zero Flag)
若運算結果為0,則ZF = 1;否則ZF = 0
49H + 6DH=B6H,結果不是零:ZF = 0
75H + 8BH=(1)00H,結果是零:ZF = 1
③符號標誌SF (Sign Flag)只對有符號運算有意義
運算結果最高位為1,則SF = 1;否則SF = 0
49H + 6DH=B6H=10110110B,SF=1
④溢出標誌OF (Overflow Flag)只對有符號運算有意義
若算術運算的結果有溢出,則OF=1;否則 OF=0
49H + 6DH =B6H,產生溢出:OF = 1
75H + 8BH =(1)26H,沒有溢出:OF = 0
進位CF和溢出OF位有什麼區別呢?
進位標誌表示無符號數運算結果是否超出範圍,運算結果仍然正確,對有符號位加減法無意義。
溢出標誌表示有符號數運算結果是否超出範圍,運算結果已經不正確,對無符號加減無意義。
溢出的判斷判斷運算結果是否溢出有一個簡單的規則:
只有當兩個相同符號數相加(包括不同符號數相減),而運算結果的符號與原數據符號相反時,產生溢出;因為,此時的運算結果顯然不正確其他情況下,則不會產生溢出
1.當兩個符號相同的數相加,結果的符號與之相反,則OF=1,否則OF=0.
2.當兩個符號不同的數相減,結果的符號與減數相同,則OF=1,否則OF=0.
六、定點數的移位運算
- 左移1位相當於×2,右移1位相當於÷2
- 原碼:符號位不參與移位。左移,右移都補0
- 反碼:符號位不參與移位。若反碼是負數補1;若反碼是正數補0
- 補碼:符號位不參與移位。若補碼是負數左移低位補0,右移高位補1;若補碼是正數,左移右移都補0
七、原碼補碼的乘法除法運算
Ⅰ、原碼的一位乘法
符號位通過異或確定;數值部分通過被乘數和乘數絕對值的n輪加法、移位完成,根據當前乘數中參與運算的位確定(ACC)加什麼。若當運算位=1,則(ACC)+[|x|],若為0,則(ACC)+1。每輪加法完成後,ACC,MQ的內容統一邏輯右移。
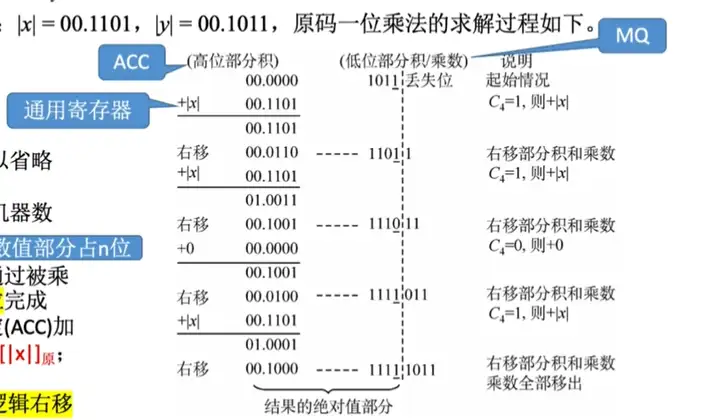
先ACC初始化。x置於通用寄存器中,y置於MQ。
Ⅱ、補碼的一位乘法
原碼一位乘法和補碼一位乘法的不同點
| 原碼一位乘法 | 補碼一位乘法 |
|---|---|
| 進行n輪的加法、移位 | 進行n輪加法,移位,最後再多來一次加法 |
| 每次加法相加,只有兩種情況+0或加x | 每次加法加有三種情況,0或+x或+[-x] |
| 每次移位都是邏輯右移,補1 | 每次都是補碼的右移,正數右移補0,負數右移補1 |
| 符號位不參與運算 | 符號位參與運算 |
- 會添加一位輔助位
- 輔助位-MQ中“最低位”=1時,(ACC)+[X)]補
- 輔助位-MQ中“最低位”=0時,(ACC)+0
- 輔助位-MQ中“最低位”=-1時,(ACC)+[-X]補

八、C語言類型轉換和數據存儲排列
- C語言中定點整數是用”補碼“存儲的。
- 無符號數轉為有符號數:不改變數據內容,改變解釋方式。
- 長整數變為短整數:高位截斷,保留低位。
- 短整數變長整數:若為有符號數,在符號位和數值位添1,若為無符號,直接在高位添0。
- 大小端模式:大端方式便於人類閱讀;小段方式便於機器處理,因為機器最先讀入的就是最應被處理的數據。
- 邊界對齊:假設存儲字長為32位,則1個字=32bit,半字=16bit。每次訪存只能讀/寫1個字。若採用邊界對齊的方式,則訪問一個字/半字都需要一次訪存,雖然會造成一點點的空間浪費。採用不對齊的方式,對空間利用率高,但是可能會涉及到兩次訪存時間大大增加。
九、浮點數的表示和運算
Ⅰ、概念:之前我們學習了定點數,其中「定點」指的是約定小數點位置固定不變。那浮點數的「浮點」就是指,其小數點的位置是可以是漂浮不定的。
Ⅱ、表示:階符表示的是階碼正負,尾數的數符表示的是尾數正負。
階碼:常用補碼或移碼表示的定點整數,反映表示範圍。
尾數:常用原碼或補碼表示的定點小數,反映精度。
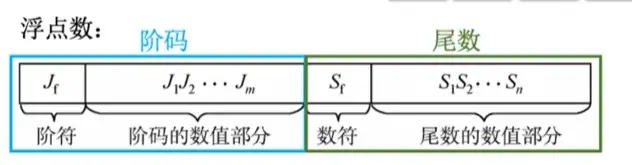
Ⅲ、規格化:規定尾數的最高位必須是有效位。
①”有效位“又分兩種情況。分為尾數是補碼表示還是原碼表示
原碼表示的尾數視格化:尾數的最高數值位必須是1
補碼表示的尾數規格化:尾數最高數值位必須和尾數符號位相反
②左規:當浮點數運算的結果為非規格化時要進行規格化處理,將尾數算數左移一位,階碼減1。
b= 22×(+0.01001)=21×(+0.10010) #尾數最高位為0,左規
右規:當浮點數運算的結果尾數出現溢出(雙符號位為01或10)時,將尾數算數右移一位,階碼加1。

採用雙符號位,當發生溢出時(雙符號位為01或10),可以採用右規,更高位的符號位是正確的符號位。
③雖然浮點數的範圍和精度也有限,但其範圍和精度都已非常之大,所以在電腦中,對於小數的表示我們通常會使用浮點數來存儲。

十、IEEE 754
背景:在浮點數提出的早期,各個電腦廠商各自製定自己的浮點數規則,導致不同廠商對於同一個數字的浮點數表示各不相同,在計算時還需要先進行轉換才能進行計算。後來 IEEE 組織提出了浮點數的標準,統一了浮點數的格式,並規定了單精度浮點數 float 和雙精度浮點數 double,從此以後各個電腦廠商統一了浮點數的格式,一直延續至今。


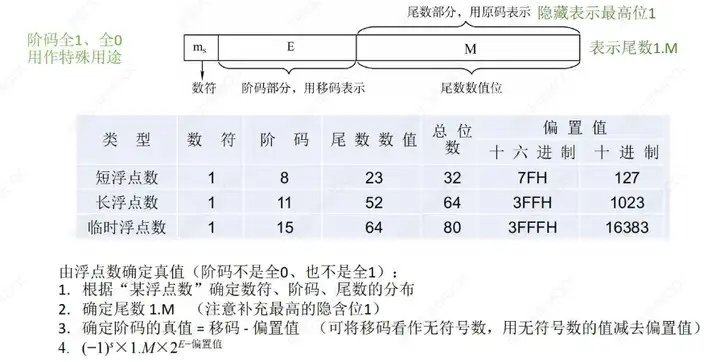
十一、浮點數運算(重點)
現代電腦表示數的方法通常都是浮點數了,所以這節很重要。
①對階:小階向大階靠齊,方便電腦對尾數進行處理。
②尾數加減:尾數常規加減。
③規格化:如果尾數加減出現類似0.0099517× 1012 時,需要“左規”;
如果尾數加減出現類似99.517107× 1012 時,需要“右規”。
④舍入:尾數位數有限,若規定只能保留6位有效尾數,則9.9517107× 1012 →9.95171× 1012 (多餘的直接砍掉)或者,9.9517107× 1012 →9.95172× 1012 (若砍掉分非0,則入1)或者,也可以採用四捨五入的原則,當捨棄位≥5時,高位入1。
⑤判溢出:若規定階碼不能超過兩位,則運算後階碼超出範圍,則溢出。
如:9.85211× 1099 +9.96007× 1099 =19.81218× 1099 規格化並用四捨五入的原則保留6位尾數,得1.98122× 10100 ,階碼超過兩位,溢出。

強制類型轉化:
無損:char->int->long->double
float->double
有損:int->float,可能會損失精度
float->int,可能會溢出,也可能會損失精度
第三章 存儲系統
第一節 存儲器概述
一、存儲器的層次結構
寄存器->Cache->主存->輔存->外存
Cache-主存:解決了主存與CPU速度不匹配的問題。
主存-輔存:實現虛擬存儲系統,解決了主存容量不夠的問題。
※輔存中的數據要調入到主存才能被CPU訪問
二、存儲器的分類
Ⅰ、按照存取方式:分為隨機存取存儲器(RAM),如記憶體;順序存取存儲器(SAM),如磁帶;直接存取存儲器(DAM),如磁碟;相聯存儲器(可按內容訪問的存儲器,CAM),如快表。
Ⅱ、按信息是否可改:分為讀/寫存儲器和只讀存儲器(ROM)
Ⅲ、斷電後是否消失:分為易失性存儲器,如記憶體、Cache;非易失性存儲器,如磁碟、光碟
三、存儲器的性能指標
1.存儲容量:存儲字數×字長
2.單位成本:每位價格=總成本/總容量
3.存儲速度:數據傳輸率=數據的寬頻/存儲周期
存儲周期=存取時間+恢復時間
第二節 主存儲器
一、SRAM和DRAM
一個靜態RAM,一個動態RAM。動態的用於主存,靜態的用於Cache
SRAM和DRAM的差別
| 類型特點 | SRAM | DRAM |
|---|---|---|
| 存儲信息 | 觸發器 | 電容 |
| 破壞性讀出 | 非 | 是 |
| 讀出後是否需要重寫 | 不用 | 需要 |
| 運行速度 | 快 | 慢 |
| 集成度 | 低 | 高 |
| 發熱量 | 大 | 小 |
| 存儲成本 | 高 | 低 |
| 是否易失 | 易失 | 易失 |
| 是否需要刷新 | 不需要 | 需要 |
| 作用 | 常用作Cache | 常用作主存 |
二、ROM只讀存儲器
RAM晶元——易失性,斷電後數據消失
ROM晶元——非易失性,斷電後數據不會消失
①MROM——掩模式只讀存儲器:任何人都不可重寫
②PROM——可編程只讀存儲器:寫一次後就不可更改
③EPROM——可擦除可編程只讀存儲器:可進行多次重寫,寫入時間很長
④Flash Memory——閃速存儲器:可進行多次快速擦除重寫,但寫的速度比讀的速度慢
⑤SSD——固態硬碟:可進行多次快速擦除重寫,目前個人電腦大都市這種。速度快,功耗低,價格高。
第三節 主存儲器與CPU的連接
一、單塊存儲器與CPU連接
Ⅰ、連接原理:主存器通過數據匯流排,地址匯流排和控制匯流排與CPU連接。
地址匯流排的位數決定了可定址的最大記憶體空間。
控制匯流排指出匯流排周期類型和本次輸入輸出操作完成的時刻。
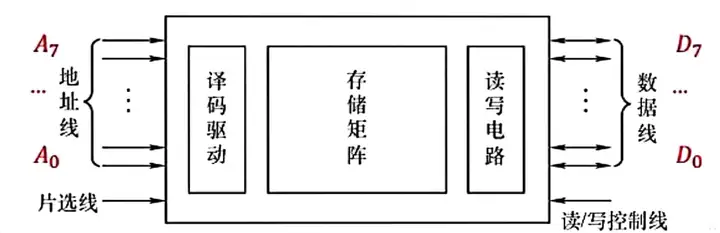
主存儲器的線路
二、多塊存儲器與CPU連接
Ⅰ、位擴展法
原理:CPU的數據線與存儲晶元的數據位數不相等,此時必須使用多個存儲器件對字長進行擴位。每個存儲器的數據線都並行連接在CPU的數據匯流排上,而地址位數是串列相連。那CPU傳一個地址過來,怎麼知道是使用哪個存儲晶元呢,此時就要WE來控制使用哪個存儲晶元。
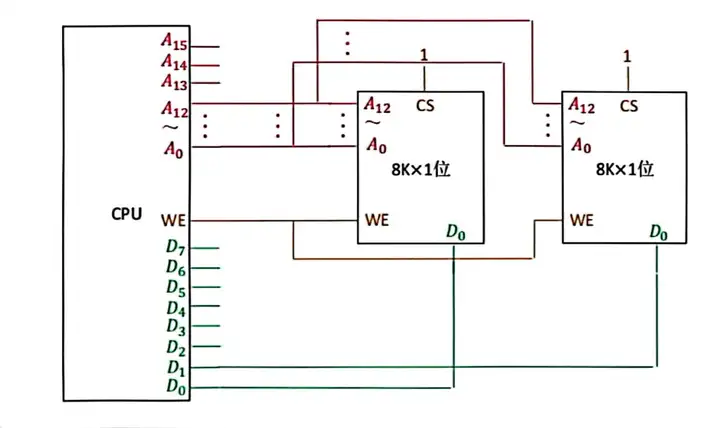
Ⅱ、字擴展法
原理:當主存儲器位數不足,字數足夠時,我們會通過位擴展的方法來擴展主存儲器,將多個字數相同的存儲晶元並聯起來,增加位數,並且存儲空間是連續的。裡面還會涉及解碼器,主要功能就是增加控制存儲器的個數,如有兩位地址線連接了解碼器,那麼解碼器可以控制 22 個存儲器。
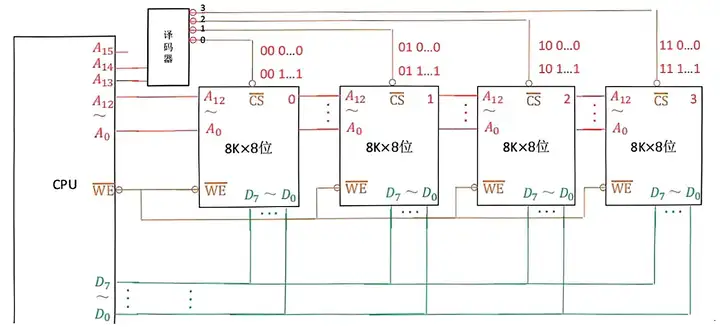
| 線選法 | 解碼片選法 |
|---|---|
| n條線n個片選信號 | n條線2的n次方個片選信號 |
| 電路簡單 | 電路複雜 |
| 地址不連續(兩位舉例,00和11的地址用不到) | 地址連續(00和11的地址也都用到了) |
Ⅲ、字位同時擴展
原理:而當字數和位數都不足時,我們會通過字位同時擴展的方法來擴展存儲器,將多個字數和位數都相同的存儲晶元連接起來,同時增加字數和位數。
Ⅳ、三者比較
字擴展方法只能增加主存儲器的容量,存取速度沒有提升。而位擴展方法不光可以增加主存儲器的容量,同時還可以讓多個存儲晶元同時工作,同時做讀寫操作,增加了存取速度。字位同時擴展的方法又可以增加主存儲器的容量,又可以讓多個存儲晶元同時工作,那麼是不是只用字位同時擴展這一種方法就可以了呢?任何事情都是有利弊兩面性的,在能力增強的同時,他的成本,功耗和體積都會增加,所以我們還是要根據實際的系統需求來判斷具體使用的主存儲器擴展方法。
Ⅴ、題目總結
【2018統考真題】假定DRAM晶元中存儲陣列的行數為r、列數為c,對於一個2K×1位的DRAM晶元,為保證其地址引腳數最少,並儘量減少刷新開銷,則r、c的取值分別是()。
解:r是行,c是列,為了保證地址引腳數最少,就要求,行列相差小,並且減少刷新開銷,則要求行數越小越好。故最終行數位32,列數位64。
三、多模塊存儲器
背景:隨著CPU的功能不斷增強,I/O設備數量不斷增多,這也導致了主存的存取速度已成為電腦系統的發展瓶頸。為瞭解決此問題,除了尋找更高速的原件和採用存儲器層次結構外,調整主存的結構也可以提高訪存速度,這就涉及到了多模塊存儲器。
由於取值周期=存取時間+恢復時間。DRAM晶元恢復時間較短,有可能是存取時間的幾倍。那怎麼半,不能讓設備停著吧。那太浪費資源了。
Ⅰ、雙埠RAM
顧名思義,就是利用兩個埠實現多核CPU存儲,需要有兩組完全獨立的數據線,地址線,控制線。支持兩個CPU同時訪問。
兩個埠可以同時對不同單元的地址中取數據,也可以對同一地址單元中讀出數據,但是不行同時對同一單元中寫入數據,也不能對同一單元一邊讀一邊寫入數據。
解決辦法:發出”busy“信號,其中一個CPU的訪問埠暫時關閉。
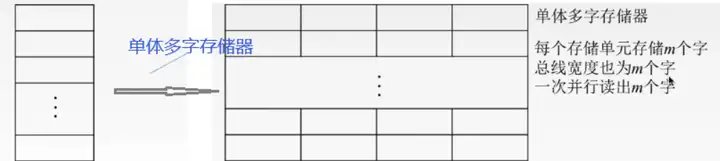
Ⅱ、單體多字存儲器
原理:原來每行只存放一個存儲字,變為每行存放多個存儲字,這樣原來一次只能讀取一個存儲字,變為一次能讀取多個存儲字,這需要數據匯流排根數變大。
限制:指令和數據在主存必須是連續存放的。
Ⅲ、多體並行存儲器(重點)
原理:每個模塊都有相同的容量和存取速度,各模塊都有獨立的讀寫控制電路,地址寄存器,和數據寄存器,既能並行工作,又能交叉工作(一個模塊進入恢復時間,另一個模塊進行存取)。
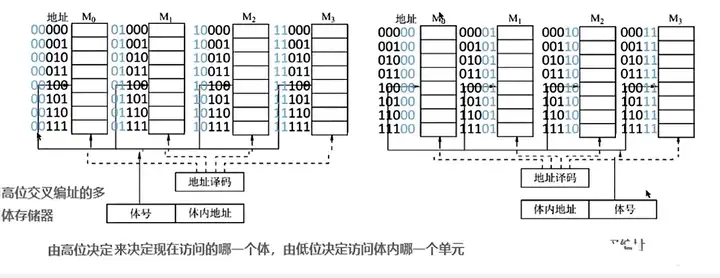
區別:在高位交叉中,由於下一個訪問的地址還是在這個存儲體上,所以必須等到恢復時間結束後才能繼續訪問,故不能並行訪問。效果也僅僅是擴容。而在低位交叉編製中,下一個訪問地址不在同一個存儲體上,所以可以交叉訪問,不僅擴容還加快了訪問速度。當塊數m ≥ T/r時,能達到最佳存儲效率。T為存取周期,r為存取時間。

第四節 外部存儲器
一、磁碟存儲器
優點:存儲容量大,價格低,長期保存而不丟失。
缺點:存取速度慢,機械結構複雜,對環境要求高。
磁碟最小的讀寫單位是一個扇區。
二、固態存儲器SSD(新增考點)
優點:讀寫速度快。若要寫的頁有數據,則不能寫入,需要將塊內其他頁全部複製到一個新的塊中,再寫入新的頁。
缺點:價格高,一個塊被寫入多次可能會壞掉(採用平均磨損,對我們來說仍然很耐用)而磁碟不會。
第五節 高速緩衝存儲器(重點)
一、什麼是Cache,為什麼要引入Cache?
Cache存儲器也被稱為高速緩衝存儲器,位於CPU和主存儲器之間。之所以在CPU和主存之間要加cache是因為現代的CPU頻率大大提高,記憶體的發展已經跟不上CPU訪存的速度。在2001 – 2005年間,處理器時鐘頻率以每年55%的速度增長,而主存的增長速度只是7%。在現在的系統中,處理器需要上百個時鐘周期才能從主存中取到數據。如果沒有cache,處理器在等待數據的大部分時間內將會停滯不動。
二、原理
採用了程式訪問的時間局部性原理和空間局部性原理
時間局部性:如果一個數據現在被訪問了,那麼以後很有可能也會被訪問
空間局部性:如果一個數據現在被訪問了,那麼它周圍的數據在以後可能也會被訪問
三、多級Cache的由來?
cache分為L1,L2,L3甚至L4等多級。為什麼不能把L1的容量做大,不要其它的cache了?原因在於性能/功耗/面積(PPA)權衡考慮。L1 cache一般工作在CPU的時鐘頻率,要求的就是夠快,可以在2-4時鐘周期內取到數據。L2 cache相對來說是為提供更大的容量而優化的。雖然L1和L2往往都是SRAM,但構成存儲單元的晶體管並不一樣。L1是為了更快的速度訪問而優化過的,它用了更多/更複雜/更大的晶體管,從而更加昂貴和更加耗電;L2相對來說是為提供更大的容量優化的,用了更少/更簡單的晶體管,從而相對便宜和省電。在有一些CPU設計中,會用DRAM實現大容量的L3 cache。
四、如何區分Cache和主存的數據塊對應關係?
每次被訪問的主存塊,一定會被立即調入Cache,而且是以塊為單位進行調入。
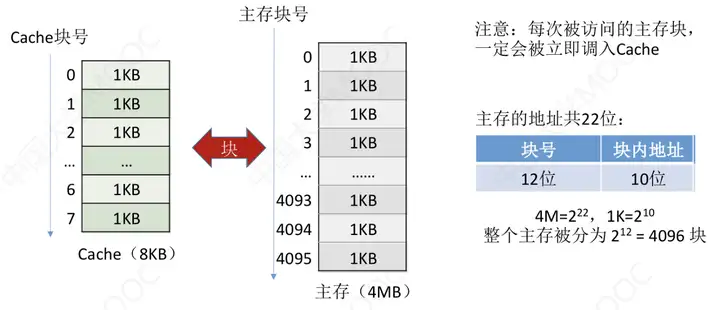
那是採用什麼方式將主存塊號調入到Cache呢?有三種方式
①全相聯映射——主存塊可以放在Cache的任意位置。
那它是如何來訪問主存的呢?
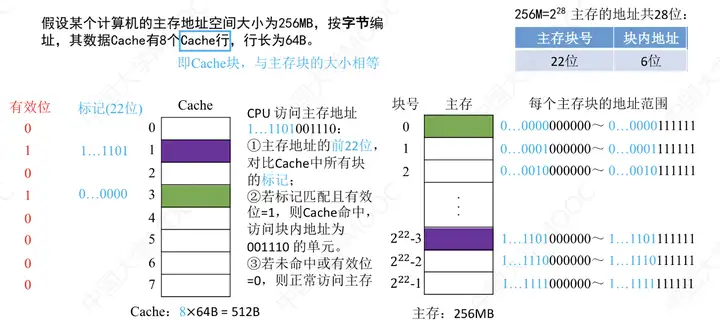
對以上圖只要能看懂,對於全相聯映射就沒什麼問題了。做幾點說明,CPU在訪問主存時,會先對比Cache所有塊中的標記Tag,Tag就是在主存中的主存塊號,占22位。
②直接映射——每個主存塊只能放在一個特定的位置。Cache塊號=主存塊號%Cache塊總數
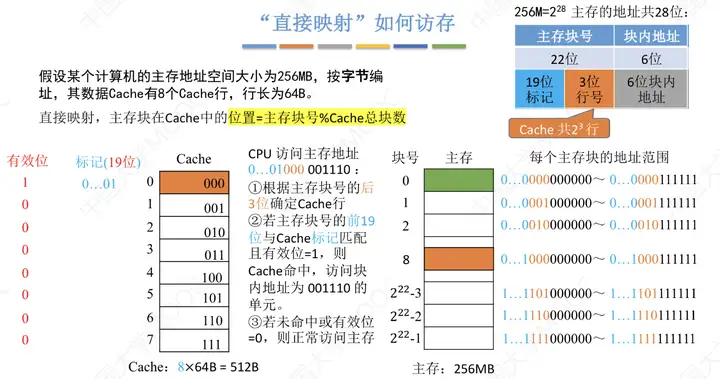
做以下幾點說明
- 相對於全相聯映射,直接映射對Tag進行了優化,因為主存塊號最後三位地址就是Cache中的位置,所以將主存塊號其餘位作為標記即可。
- 若Cache總塊數= 2� ,則主存塊號末尾n位直接反映它在Cache的位置,所以將主存塊號其餘位作為標誌位即可。
③組相聯映射——Cache塊分為若幹組,每個主存塊可以放到特定分組中的任意一個位置。組號=主存塊號%分組數
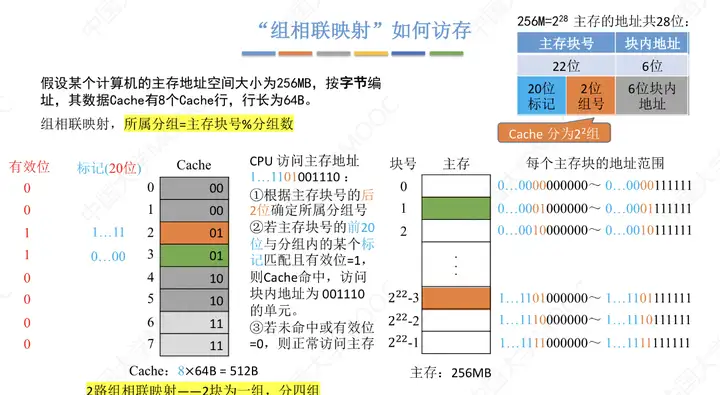
做以下幾點說明
- 相對於全相聯映射,直接映射對Tag進行了優化,因為主存塊號最後兩位地址就是Cache中的位置,所以將主存塊號其餘位作為標記即可。
- 一個組內有幾個Cache塊就成為幾路相聯映射
④三種映射方法對比總結
| 全相聯 | 直接 | 組相聯 | |
|---|---|---|---|
| 特點 | 任意位置 | 特定位置 | 分組中的任意位置 |
| 主存地址結構 | 標記+塊內地址 | 標記+行號+塊內地址 | 標記+組號+塊內地址 |
| 優點 | Cache存儲空間利用充分 | 對任意地址,執行對比一個Tag,速度快 | 折中辦法 |
| 缺點 | 可以會對比所有行的標記,速度慢 | Cache空間利用不充分 | / |
五、Cache很小,而主存很大,如果Cache滿了,是利用了什麼替換演算法?
替換條件:對於全相聯映射,需要在全局中選擇替換哪一塊,對於直接映射,若非空,則直接替換,對於組相聯,組內滿了,則在組內選擇替換哪一塊。
Ⅰ、隨機演算法(RAND)
隨機,隨便,隨意,換哪一個都行。實現簡單,但完全沒有考慮局部性原理,命中率低,實際效果很不穩定。
可能會導致,換出的塊,下一次又需要訪問。就會多次訪問記憶體塊。導致抖動現象。
Ⅱ、先進先出演算法(FIFO)
替換最先進入的塊。同樣實現簡單,但仍然沒有考慮到局部性原理,最先被調入Cache塊可能是被訪問最頻繁的。
Ⅲ、近期最少使用(LRU)
為每個Cache塊設置一個”計數器“,用於記錄每個Cache塊多久沒有被訪問了。然後替換”計數器“值最大的。
- 計數器的位數=Cache塊的總數= 2� ,只需要n位,且Cache裝滿後所有計數器的值一定不重覆。
- 基於局部性原理,近期被訪問的主存塊,未來可能仍會被使用,LRU演算法實際運行效果優秀。
- 若頻繁訪問的主存塊數量>Cache行的數量,則有可能發生”抖動“
Ⅳ、最近不經常使用(LFU)
為每個Cache設置一個”計數器“,用於記錄Cache被訪問過幾次,然後替換”計數器“值最小的(訪問次數最少的)
曾經被經常訪問的主存塊不一定在未來會被用到。並沒有很好的遵循局部性原理,因此實際運行效果不如LRU。
六、Cache寫策略——CPU修改了Cache中的數據副本,如何確保主存中數據母本一致性?
Ⅰ、寫命中——寫入的時候,在Cache中
①回寫法:當CPU對Cache寫命中時,只修改Cache的內容,而不立即寫入主存,只有當次塊被換出時才寫回主存。減少了訪存次數,但存在數據不一致的隱患。
被換出時,看”臟位“是否知道是否被修改。
②全寫法:當CPU對Cache寫命中時,必須把數據同時寫入Cache和主存,一般使用寫緩衝。訪存次數增加,速度變慢,但是能保證數據的一致性。無臟位。
Ⅱ、寫不命中——寫入的時候,不在Cache中
①寫分配法——當CPU對Cache不命中時,把主存中的塊調入Cache,在Cache中修改。通常搭配回寫法使用,改完後要被換出,才在主存中修改。
②非寫分配法——當CPU對Cache寫不命中時,只寫入主存,不調入Cache,搭配全寫法使用。
第六節 虛擬存儲器
虛擬存儲器:在操作系統的管理下,只把當前需要的部分數據調入主存,暫不需要的部分留在輔存中。在用戶看來,似乎獲得了一個超大的主存。(虛擬性)
一、頁式虛擬存儲器
背景:CPU執行的機器指令中,使用的是”邏輯地址“,因此需要通過”頁表“將邏輯地址轉為物理地址。
一個程式在邏輯上被分為若幹個大小相等的”頁面“,”頁面“大小與”塊“的大小相同。每個頁面可以離散的存放在不同主存塊中。
頁表的作用:記錄了每個邏輯頁面存放在哪個主存塊中。
無快表:
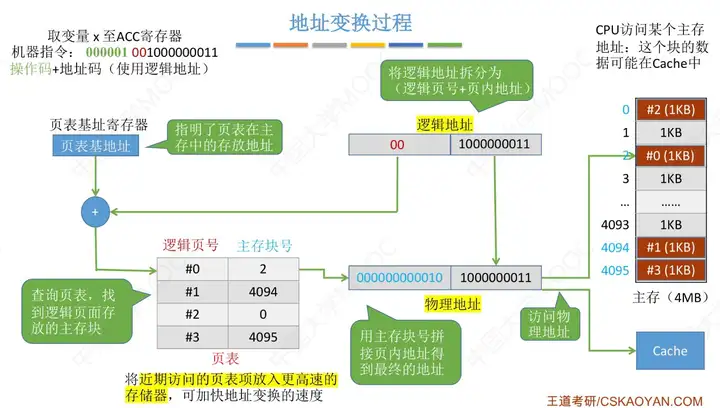
- 邏輯地址=邏輯頁號+頁內地址
- 物理地址=主存塊號+頁內地址
增加快表(存放在Cache中,先訪問快表,若未命中,則去訪問主存中的慢表)
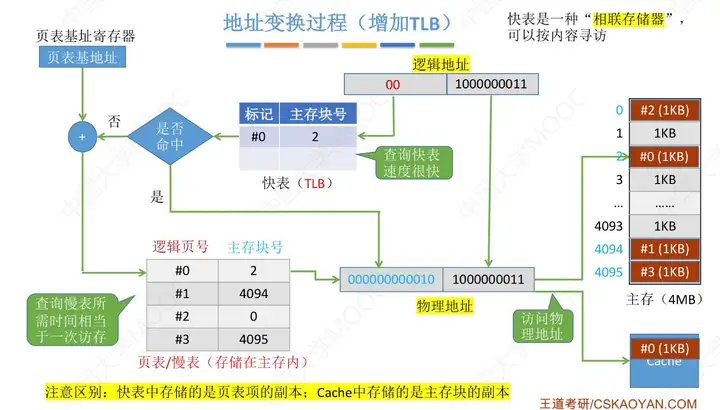
- 快表查詢速度很快,若快表中無,則會去慢表中查找,會把相應的內容存入快表中
清楚整個查找流程
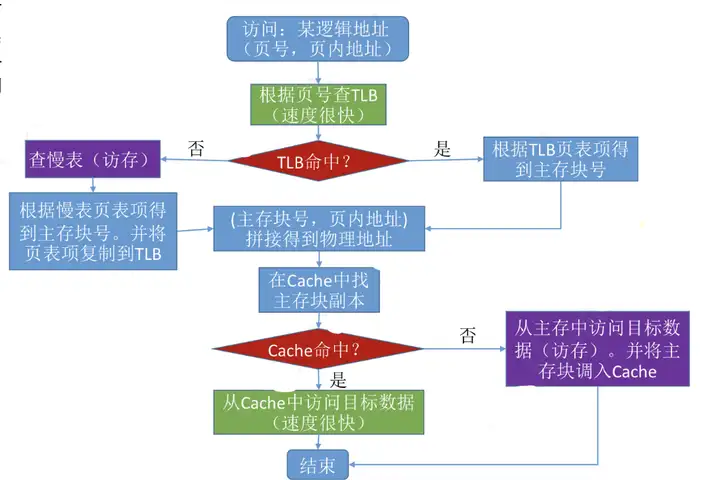
二、段式虛擬存儲(按功能拆分成大小不同的模塊)
按照功能模塊拆分不同的模塊大小。
虛擬地址:段號+段內地址
優點:段的分界與程式的自然分界相對應,因而具有邏輯獨立性,使得它易於編譯、管理、修改和保護。
缺點:段的長度可變,分配空間不便,容易留下碎片,不好利用,造成浪費。
三、段頁式虛擬存儲
把程式按邏輯結構分段,每段在分固定大小的頁,主存空間也劃分為大小相等的頁,每個程式對應一個段表,每段對應一個頁表。
虛擬地址:段號+段內地址+頁內地址
優點是兼具段式和頁式的優點缺點是需要查兩次表,系統開銷較大。
四、虛擬存儲器與Cache的比較
| Cache | 虛擬存儲器 |
|---|---|
| 解決CPU與主存速度不匹配的問題 | 解決主存容量的問題 |
| 全由硬體組成,對所有程式員透明 | 由OS和硬體組成,邏輯上存儲器對系統程式員不透明 |
| 不命中影響小 | 不命中影響大 |
| 不命中時,主存直接與CPU通信 | 不命中時,不能直接和CPU通信,要先硬碟調入主存 |
題目總結:
【2015統考真題】假定主存地址為32位,按位元組編址,主存和Cache之間採用直接映射方式,主存塊大小為4個字,每字32位,採用回寫方式,則能存放4K字數據的Cache的總容量的位數至少是()
- Cache的容量分為兩個部分一個是數據存儲容量+標記陣列容量
- 標記陣列中一定包含有效位和標記位,若為回寫法,則還存在一位的”臟位“,若為LRU、LFU替換演算法,則還存在替換演算法位(計數器)位數為 ���2� ,n為Cache的個數。
- 本題按照位元組編址,則塊內地址占4位,採用直接映射方法中的標誌位為32-4-10=18,Tag=18。
- 採用回寫法,有一位臟位,故最終標記項有18+1+1=20
- 標記陣列容量為 210 ×20=20K,數據儲存容量為4K×32=128K,故總的為148K。
第四章 指令系統
第一節 指令格式
指令概念:又稱機器指令,是指示電腦執行某種操作的命令,是電腦運行的最小功能單位。
一條指令就是機器語言的一個語句,一條指令通常要包括操作碼和地址碼兩部分:操作碼主要指明用戶乾什麼,地址碼主要指明對誰操作。
一、指令分類
按操作數個數分:
Ⅰ、零地址指令:不需要操作數,如空操作、停機、關中斷等指令
Ⅱ、一地址指令:只需要單個操作數,如自增,自減,取反,求補,需要兩個操作數,但其中一個隱含在某個寄存器中
Ⅲ、二地址指令:常用於兩個操作數的算術運算、邏輯運算相關指令。
完成一條指令需要訪存四次,分別為取值,讀第一個操作數,讀第二個操作數,寫回第一個操作數。
Ⅳ、三地址指令:常用於兩個操作數的計算,結果放在第三個地址中。
完成一條指令需要訪存四次,分別為取值,讀讀一個操作數,讀第二個操作數,寫到第三個操作數。
※若指令長度不變,地址碼數量越多,定址能力就越差
按指令長度是機器指令的多少倍分:
Ⅰ、半長指令:是機器指令長度一半
Ⅱ、單字長指令:與機器指令長度一樣
Ⅲ、雙字長指令:是機器指令長度兩倍
二、擴展操作碼指令格式(考點:會設計指令系統)
概念:指令是定長的,但是操作碼的長度可變。
通常情況下,使用頻率高的指令使用短的操作碼,減少指令解碼和分析的時間。而使用頻率低的指令使用長的操作碼
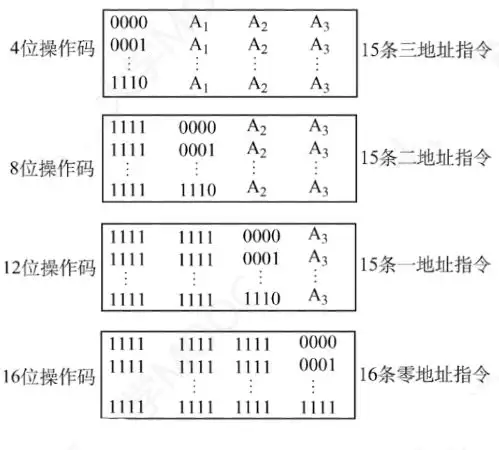
定長指令和擴展操作碼的比較
| 定長操作碼 | 擴展操作碼 | |
|---|---|---|
| 優點 | 硬體設計簡單,識別速度快 | 在指令長度限制下仍有豐富指令 |
| 缺點 | 指令難以增加,不靈活 | 增加指令解碼和分析難度,速度慢 |
【2017統考真題】某電腦按位元組編址,指令字長固定且只有兩種指令格式,其中三地址指令29條、二地址指令107條,每個地址欄位為6位,則指令字長至少應該是()。
解答:三地址29條需要的位數是5位,多出3位,而107條需要6位。故總共5+6+12=23,因為按照位元組編址,所以最少需要24位。
第二節 定址方式(重點)
一、指令定址(由PC指出)
Ⅰ、順序定址
PC+”1“,這裡的1指指令字長,每次取值結束後PC會+1
Ⅱ、跳躍定址
執行轉移類指令導致的PC值改變
二、數據定址(由本條指令的地址碼指明真實地址)
非偏移指令
| 定址方式 | 有效地址 | 優點 | 缺點 | 訪存次數(指令執行期間) |
|---|---|---|---|---|
| 直接定址 | 操作數的真實地址 | 簡單 | 限制定址範圍 | 1 |
| 間接定址 | 操作數地址的地址 | 可擴大定址範圍 | 指令在執行階段要多次訪存 | 最少2次 |
| 寄存器定址 | 寄存器的地址 | 不訪問主存,速度快 | 寄存器昂貴 | 0 |
| 寄存器間接定址 | 寄存器地址,內部是操作數主存地址 | 與一般的間址快 | 但執行仍然會訪存 | 1 |
| 隱含定址 | 指令中隱含操作數地址 | 有利於縮短指令字長 | 需要增加存儲操作數的硬體 | 0 |
| 立即定址 | 就是操作數本身 | 最快 | 限制操作數範圍 | 0 |
偏移定址(重中之重)
指令執行過程中,都會在將運算結果放入主存中,涉及一次訪存。
Ⅰ、基址定址
將CPU中基址寄存器(BR)/通用寄存器的內容加上指令格式中的形式地址A,而形成操作數的有效地址,即EA=(BR)+A
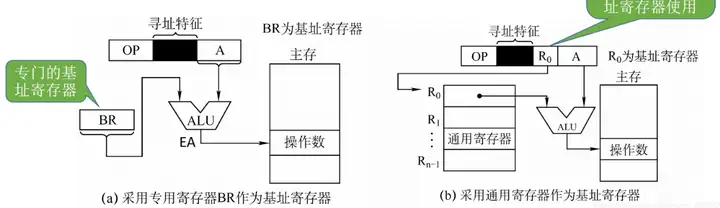
※採用通用寄存器作為基址寄存器 �0 的位數,根據通用寄存器的總數判斷,程式運行前,CPU將BR的值修改為該程式的起始地址。
- 基址寄存器是面向操作系統的,其內容由操作系統或管理程式確定。用戶無法修改,在程式執行過程中,基址寄存器的內容不變(作為基地址),形式地址可變(作為偏移量)。
- 當採用通用寄存器作為基址寄存器時,可由用戶決定哪個寄存器作為基址寄存器,但其內容仍由操作系統確定。
- 優點:可擴大定址範圍(基址寄存器的位數大於形式地址A的位數)
Ⅱ、變址定址
有效地址EA等於指令字中的形式地址A與變址寄存器IX的內容相加之和,即EA= (IX)+A,其中IX可為變址寄存器(專用),也可用通用寄存器作為變址寄存器 。
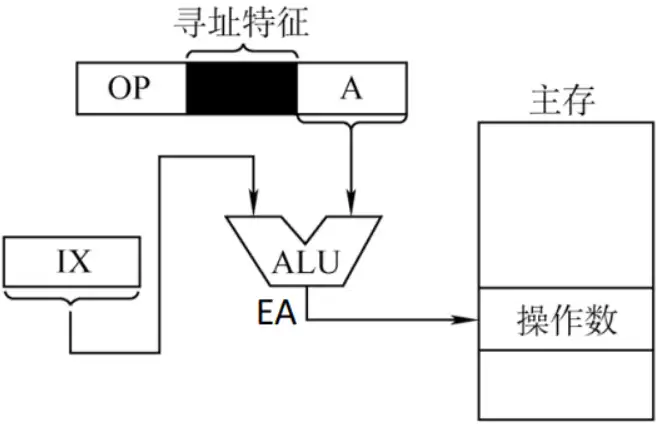
- 變址寄存器是面向用戶的,在執行過程中,變址寄存器的內容可由用戶改變(IX作為偏移量),形式地址A不變(作為基地址)。剛好與基址定址相反。
- 在針對數組處理過程中,不斷改變IX的值,便很容易形成數組中任一數據的地址,特別適合編製迴圈程式。
- 基址變址複合執行。EA=(IX)+(BR)+A。
Ⅲ、相對定址
相對定址:把程式計數器PC的內容加上指令格式中的形式地址A而形成操作數的有效地址,即EA=(PC)+A,其中A是相對於PC所指地址的位移量,可正可負,補碼表示 。
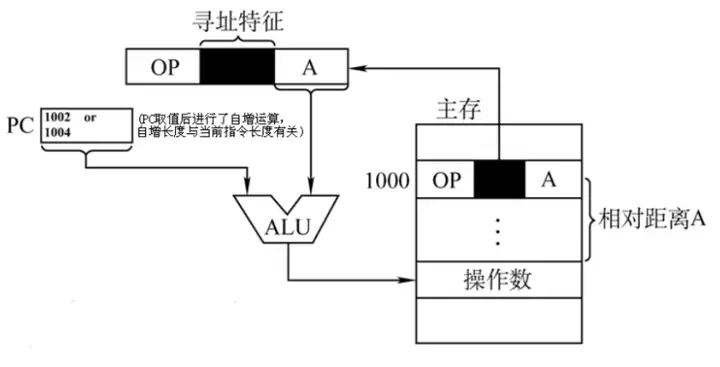
- 優點:這段代碼在程式內浮動時不用更改跳轉指令的地址碼
- 相對定址廣泛應用於轉移指令
- 註意:對於JMP A轉移指令,當從CPU中取出一位元組時,會自動執行PC+1。若指令的地址為X,且占2B,在取出該指令後,會自定跳轉到X+2+A。
堆棧定址
操作數存放在堆棧中,隱含使用堆棧指針作為操作數地址。
- 硬堆棧是將寄存器作為棧,成本很高;軟堆棧是將主存作為棧,成本低。
- 硬堆棧不訪存,軟堆棧訪存一次
第三節 高級語言程式與機器級代碼之間的對應
一、基本概念
- 對操作數的操作地址只涉及三種:寄存器到寄存器,主存到寄存器,立即數到寄存器。
- dword 32bit ;word 16bit ;byte 8bit
- 通用寄存器 eax ebx ecx edx 變址寄存器 esi edi 堆棧寄存器 ebp esp。
二、選擇結構語句的機器級表示
| je | jump when equal, |
|---|---|
| jne | jump when not equal, |
| jg | jump when greater, |
| jge | jump when greater or equal |
| jl | jump when less |
| jle | jump when less or equal |
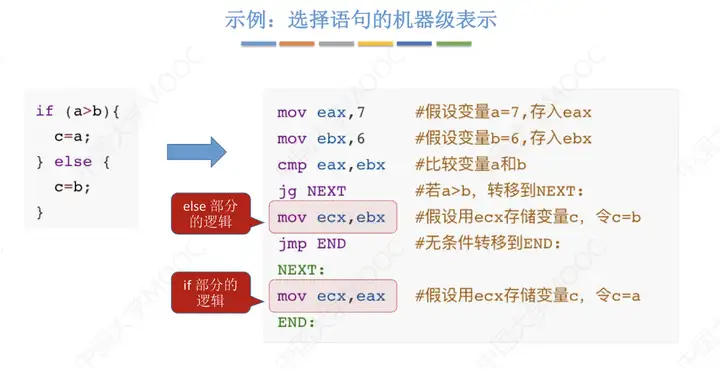
例如
cmp eax ,ebx #比較寄存器eax和ebx里的值
jg NEXT #若eax>ebx,則跳轉到NEXT
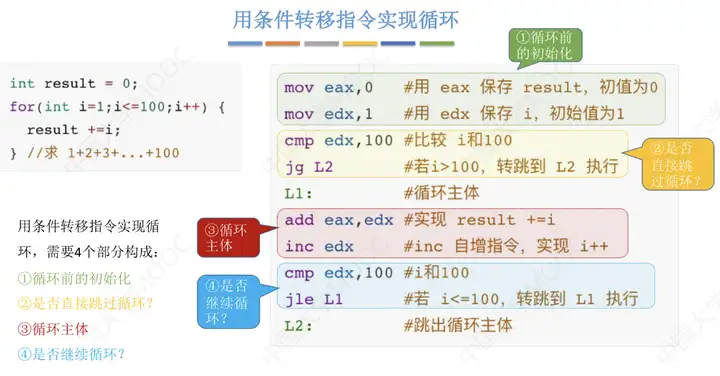
三、迴圈結構語句的機器級表示
用條件指令實現迴圈
用loop指令實現迴圈
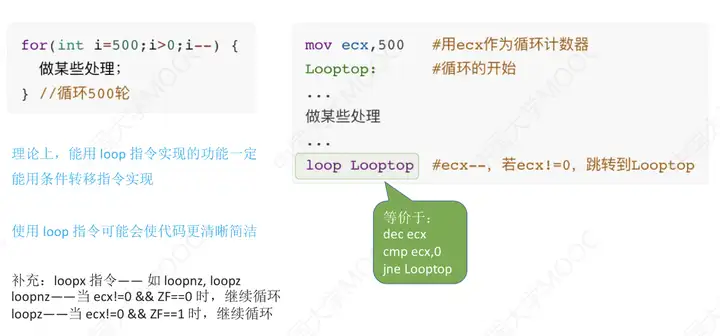
就是將”某些處理“封裝到了Looptop內,使得代碼更加簡潔。
四、CISC和RISC
| 對比項目 | CISC | RISC |
|---|---|---|
| 指令系統 | 複雜,龐大 | 簡單,精簡 |
| 指令數目 | 一般大於200條 | 一般小於100條 |
| 指令字長 | 不固定 | 定長 |
| 可訪存指令 | 沒有限制 | 只有Load/Store指令 |
| 各種指令執行時間 | 相差較大 | 絕大多數在一個周期內完成 |
| 各指令使用頻率 | 有的常用,有點不常用 | 一般都常用 |
| 通用寄存器的數量 | 較少 | 多 |
| 控制方式 | 絕大多數為微程式控制 | 絕大多數為組合邏輯控制 |
| 指令流水線 | 可以通過一定方式實現 | 必須實現 |
第五章 中央處理器
第一節 CPU
一、CPU的結構
CPU由運算器和控制器組成。
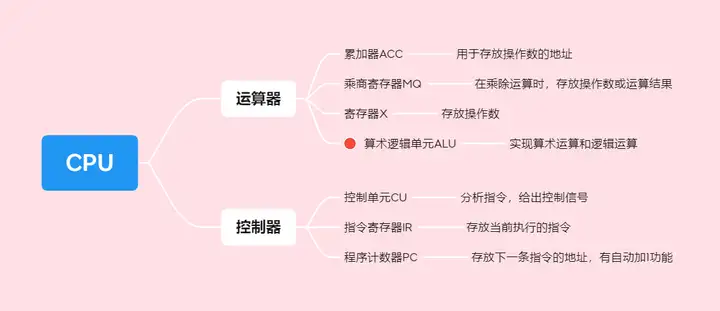
二、CPU的功能
指令控制、操作控制、時間控制、數據加工、中斷處理。
運算器的功能:對數據加工
控制器的功能:取指令、分析指令、執行指令
第二節 指令執行過程
在指令周期中,包含了:取指周期,在取指周期後需要判斷是否有間址周期,如果沒有就進入到執行周期,在執行周期後又需要判斷是否有中斷程式,如果有就響應中斷並保存斷點生成中斷服務程式入口;如果沒有就進入下一個取指周期。
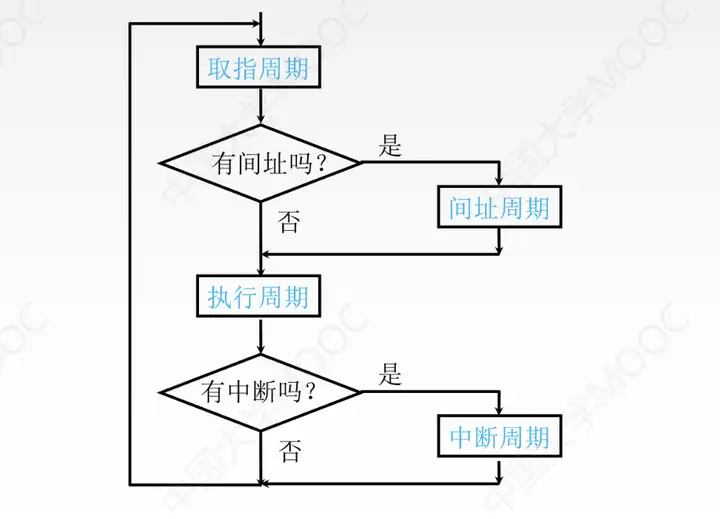
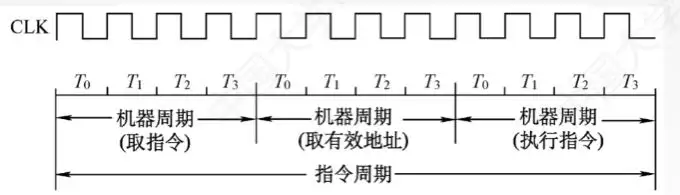
四個周期都有CPU訪存操作,只是訪存目的不同。取值周期是取指令;間址周期是取有效地址;執行周期是為了取操作數;中斷周期是為了保存程式斷點。
指令周期常常有若幹個機器周期,機器周期裡面又包含若幹個時鐘周期。每個指令周期內的機器周期可以不同,機器周期內的時鐘周期也可以不同。時鐘周期是CPU操作的最基本單位。
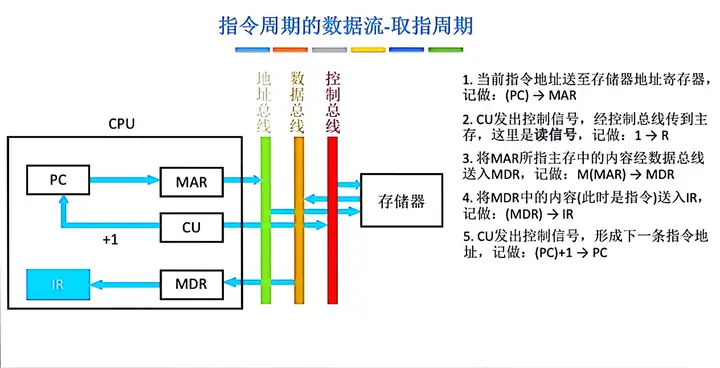
一、取值周期
取指周期:取指周期的任務是根據PC中的內容從主存中取出指令代碼並存放在IR中。而PC中存放的是指令的地址,根據這個地址從記憶體單元取出的是指令,並放在指令寄存器IR中,取指令的同時,PC加1。
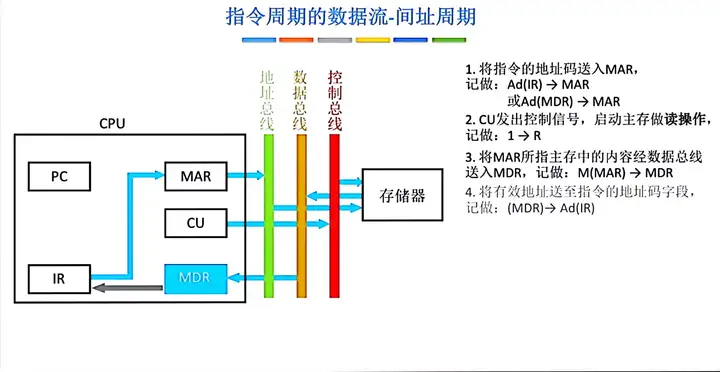
二、間址周期
間址周期:間址周期的任務是取操作數有效地址,以一次間址為例,將指令中的地址碼送到MAR並送至地址匯流排,此後CU向存儲器發讀命令,以獲取有效地址並存至MDR。
三、執行周期
執行周期:執行周期的任務是根據IR中的指令字的操作碼和操作數通過ALU操作產生執行結果。不同指令的執行周期操作不同,因此沒有統一的數據流向。
指令執行方案:
| 單指令周期 | 所有指令選用相同的執行時間(取決於最長指令執行時間),指令間串列,但原本只需要很短時間完成指令也分配了很長時間,降低整個系統運行速度 |
|---|---|
| 多指令周期 | 對不同指令選用不同的執行時間,需要更複雜的硬體設計,指令間是串列 |
| 流水線 | 在每個時鐘周期讓多個指令同時運行,指令間是並行 |
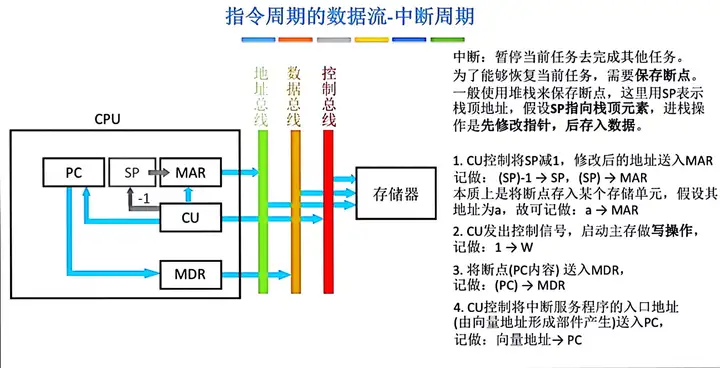
四、中斷周期
中斷周期:中斷周期的任務是處理中斷請求。假設程式斷點存入堆棧中,並用SP指示棧頂地址,而且進棧操作是先修改棧頂指針,後存入數據。
第三節 數據通路的功能和基本結構
一、數據通路的基本結構
Ⅰ:CPU內部單匯流排方式。將所有寄存器的輸入端和輸出端都連接在一條公共通路上。易發生衝突。
Ⅱ:雙匯流排/多匯流排方式。多個匯流排上傳不同的數據,提高效率。
Ⅲ:專用數據通路方式。專門給某些部件設計通路。性能很高但是硬體量大。
說明:
①對於單匯流排的連接方式來說,ALU只能有一端與匯流排相連,因為兩端相連就必會發生衝突。所以另一段要設計一個暫存器,先把數據放入暫存器,暫存器再與匯流排相連。
②單周期就是指令在一個周期內完成,這是需要與多匯流排結構配合。才能使各個部件的數據傳遞。因為單匯流排一個周期內只能傳遞一個數據,所以指令不可能在一個周期內完成。
| 內部匯流排 | 是指同一部件,如CPU內部連接各個寄存器及運算部件之間的匯流排 |
|---|---|
| 系統匯流排 | 指同一臺電腦的各部件,如CPU,主存,I/O之間連接的匯流排 |
第四節 控制器的功能和工作原理
一、硬佈線控制器
多提一嘴,一定要看看王道視頻是如何設計出組合邏輯圖的,我保證看完一定會有顛覆性的收穫。
根據指令操作碼、目前的機器周期、節拍信號、機器狀態條件,即可確定現在這個節拍應該發出哪些”微命令“
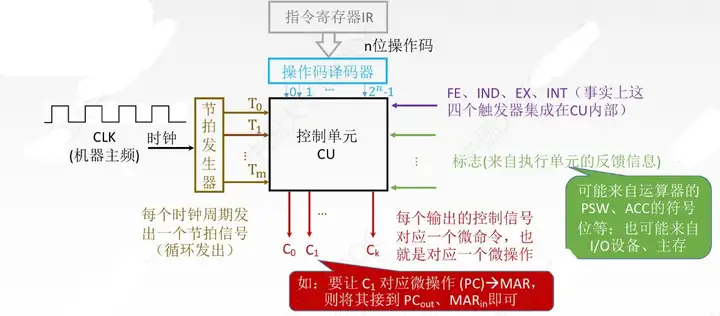
硬佈線控制器的特點:
- 指令越多,設計和實現就越複雜(邏輯圖很複雜),因此一般使用RISC。
- 如果擴充一條新的指令,則控制器的設計就需要大改,因此擴充指令較為困難。
- 由於使用存純硬體實現控制,因此執行速度很快。
二、微程式控制器(重難點)
要求:會基本概念微命令與微操作,微指令與微周期,主存儲器與控制存儲器,程式與微程式,MAR與CMAR,IR與CMDR。還會一些基本結構,比如為地址形成部件,微地址寄存器CMAR,微指令寄存器CMDR,控制存儲器CM。
- 微命令:控制器部件向執行部件發出的控制命令,是構成控制序列的最小單位,例如打開或者關閉控制門的電位信號。是各部件完成某個基本微操作的命令
- 微操作:執行部件接受微命令後所進行的操作,和微操作是一一對應的。 (實際上,微命令是微操作的控制信號,微操作是微命令的執行過程,微操作是執行部件中最基本的操作)
- 微指令:若幹微命令的集合,存放在一個控制存儲器中,而存放微指令的控制存儲器的單元成為微地址。在同一CPU周期內,並行執行的一組微命令,存儲在控制存儲器上面,稱為一條微指令。
- 微周期:從讀取一條微指令,到執行執行完畢所需要的時間稱為微周期。
- 控制存儲器:主存儲器,主要用來存放程式和數據,位於CPU的外部,使用的是RAM。而控制存儲器,則主要用於存儲微程式,位於CPU內部,採用的是ROM。
- 微程式:實現一條機器指令功能的微指令序列。
- 程式與微程式:程式由機器指令構成,編寫好以後放到主存中運行,可以改寫。而微程式由微指令構成,事先編寫好在CM(控制存儲器)中,一般是不可改寫的。微程式的作用就是實現一條對應的機器指令。
- 微程式>微指令>微命令=微操作是微命令的執行過程。
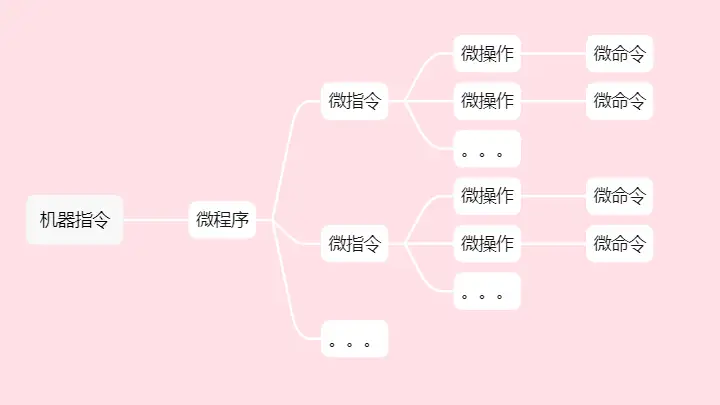
秒懂哦
- 一臺電腦可以分為控制部件和執行部件。其中控制部件有指令寄存器,程式計數器,操作控制器,執行部件有運算器,存儲器,外圍設備,狀態條件寄存器。
- 彙編程式員可見的寄存器有基址寄存器和狀態/標誌寄存器,程式計數器PC及通用寄存器。而MAR,MDR,IR,是CPU內部寄存器,彙編程式員不可見,微指令相關的彙編程式員也不可見。
水平型微指令的編碼方式(重點會考)
①欄位直接編碼對於直接編碼的方式最大的好處就是能夠並行微操作,縮短了微命令的欄位長度。有個題能很好的解釋這其中的原因。某電腦的控制器採用微程式控制方式,微指令中的操作控制欄位採用欄位直接編碼方式,共有33歌微命令,構成5個互斥類,分別包含7,3,12,5和6個微命令,則操作控制欄位至少有幾位?
每個互斥類要留1個狀態位不操作,故為8,4,13,6,7個微命令。則需要3,2,4,3,3位共15位控制欄位,而直接控製法要33位。很明顯的縮減操作欄位位數。
優點明顯,缺點也明顯啊。增加了解碼,執行時間會增長,而卻增大成本。
②直接編碼就是每個控制欄位位,就代表一個微命令,優點就是快,電力嘎嘎簡單。但是若微命令要是多達幾百條。那不是要幾百位了。因此指令位數太長。
③某帶有中斷的指令系統有101中操作,採用微程式控制方式,存儲器中相應最少有103個微程式。
要加上取值操作和終端操作,若有n條操作,則有n+2個微程式
④下一條微指令的形成方法常考的:斷定法(根據當前執行的微指令尋找到下一條微指令)和計數器法(類似PC)
第五節 異常和中斷機制
這節會在後面第七章一起講
第六節 指令流水線
講在前面,為什麼要引入指令流水線。相信都聽說過華強北的流水線運作方式吧。最明顯的優點就是相較於順序執行的吞吐量更大(單位時間內)運行相同數量的指令也更快。效率也更高。
這裡就可以知道指令流水線的概念:把指令執行過程劃分為不同的階段,占用不同的資源,就能使多條指令同時執行。
①在流水執行的過程中,會經常遇到衝突,包括結構衝突,數據衝突,控制衝突。
| 結構相關/衝突/冒險 | 數據相關/衝突/冒險 | 控制相關/衝突/冒險 | |
|---|---|---|---|
| 概念 | 多條指令在同一時刻爭用同一資源 | 下一條指令會用到當前指令計算的結果 | 遇到執行轉移、調用、返回導致PC中斷 |
| 處理辦法 | 1.單獨設置數據存儲器和指令存儲器,使取數和取值操作在不同的存儲器中進行 2.暫停時鐘周期 | 1.暫停時鐘周期 2.數據旁路技術 3.編譯優化 | 1.早判斷,早生成 2.預取轉移成功和不成功兩個控制流方向的目標指令 3.加快和提前形成條件碼 4.提高轉移方向的猜準率 |
②五段式指令流水線(超重要)
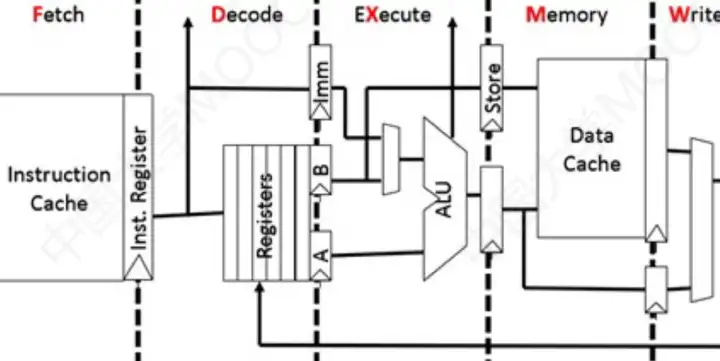
顧名思義,五段分為IF(取值),ID(解碼&取數),EX(執行),M(訪存),WB(寫回寄存器)
只有上一條指令進入ID段後,下一條指令才能開始IF段,否則會覆蓋IF段鎖存器的內容
考試中常見的五類指令:
Ⅰ、運算類指令的執行過程
IF:根據PC從指令Cache取指令至IF段的鎖存器
ID:取出操作數至ID段的鎖存器
EX:運算,將結果存入EX段鎖存器
M:空段
WB:將運算結果寫回指定的寄存器
Ⅱ、LOAD指令執行過程
作用:load指令可以完成將數據從存儲器中複製到目的寄存器中,會訪存
IF:根據PC從指令Cache取指令至IF段的鎖存器
ID:將基址寄存器的值放到鎖存器A,將偏移量的值放到lmm
EX:運算,得到有效地址
M:從數據Cache中取數並放入鎖存器
WB:將運算結果寫回指定的寄存器
Ⅲ、STORE指令執行過程
作用:將數據從寄存器中,複製到存儲器中,會訪存
IF:根據PC從指令Cache取指令至IF段的鎖存器
ID:將基址寄存器的值放到鎖存器A,將偏移量的值放到lmm。將要存的數放到B
EX:運算,得到有效地址。並將鎖存器B的內容放到鎖存器Store
M:寫入數據Cache
WB:空段
Ⅳ、條件轉移指令執行過程
IF:根據PC從指令Cache取指令至IF段的鎖存器
ID:進行比較的兩個數放入鎖存器A,B;偏移量放入lmm
EX:運算,比較兩個數
M:將目標PC值寫回PC
WB:空段
Ⅴ、無條件轉移指令的執行過程
IF:根據PC從指令Cache取指令至IF段的鎖存器
ID:偏移量放入lmm
EX:將目標PC值寫回PC
M:空段
WB:空段
針對條件轉移指令和無條件轉移指令做以下說明:寫入PC的好事比EX更短,可以安排在EX段時間內完成。越早完成就越能避免控制衝突。當然也有在WB段修改PC值的
題目總結:
①流水CPU是由一系列叫做“段”的處理線路組成的。一個m段流水線穩定時的CPU的吞吐能力,與m個並行部件的CPU的吞吐能力相比具有相同的吞吐能力
原因是當流水線穩定後,說明已經進行了一條指令,往後每多一個時鐘周期就多一條指令執行成功。
m個並行平均下來也是一個時針周期就多條指令
故具有相同的吞吐能力,但是流水線的方式,結構實現較為簡單。
第七節 多處理器的基本概念(選擇題)
這節的要求就是明白基本概念
①SISD(單指令流單數據流)
特點:只能併發,不能並行,每條指令處理一個指令
不是數據級並行技術
| SISD(單指令流單數據流) | SIMD(單指令多數據流) | MIMD(多指令多數據流) | 多處理器系統 | 多電腦系統 | |
|---|---|---|---|---|---|
| 特點 | 不是數據級並行技術 | 是一種數據級並行技術 | 是一種線程級並行技術 | 多個處理器共用單一物理地址空間 | 每台電腦擁有私有存儲器,相互獨立 |
| 特征 | 一條指令處理一個數據 | 一條指令處理多個數據 | 多條指令處理多個數據 | 多個處理器+一個主存儲器 | 多個處理器+多個主存儲器 |
- 併發(concurrency):把任務在不同的時間點交給處理器進行處理。在同一時間點,任務並不會同時運行。
- 並行(parallelism):把每一個任務分配給每一個處理器獨立完成。在同一時間點,任務一定是同時運行。
併發不是並行。並行是讓不同的代碼片段同時在不同的物理處理器上執行。並行的關鍵是同時做很多事情,而併發是指同時管理很多事情,這些事情可能只做了一半就被暫停去做別的事情了。(你學廢了嗎?)
第六章 匯流排
第一節 匯流排的概述
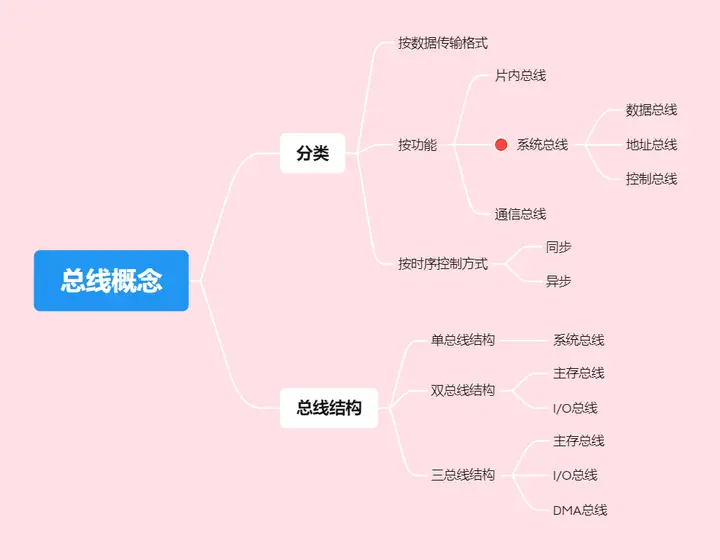
- 片內匯流排:晶元內部的匯流排,是CPU晶元內部寄存器與寄存器之間,寄存器與ALU之間的公共連接線
- 系統匯流排:電腦系統內部功能部件(CPU、主存、I/O介面)之間相互連接的匯流排,可分為三類,數據匯流排,地址匯流排,控制匯流排
- 通信匯流排:電腦系統之間或電腦系統與其它系統之間的信息傳送的匯流排
| 數據匯流排 | 地址匯流排 | 控制匯流排 | |
|---|---|---|---|
| 功能 | 傳輸數據信息 | 傳輸地址信息 | 傳輸控制信息 |
| 大小與什麼有關 | 機器字長、存儲字長 | 主存地址空間大小 | 傳輸一個信號 |
| 方向 | 雙向 | 單向 | 既有雙向也有單向 |
| 匯流排結構 | 單
  更多相關文章
一周排行
 所有分類
|
|---|