
編譯打包 Spark支持Maven與SBT兩種編譯工具,這裡使用了Maven進行編譯打包; 在執行make distribution腳本時它會檢查本地是否已經存在Maven還有當前Spark所依賴的Scala版本,如果不存在它會自動幫你下載到build目錄中並解壓使用;Maven源最好...
編譯打包
Spark支持Maven與SBT兩種編譯工具,這裡使用了Maven進行編譯打包;
在執行make-distribution腳本時它會檢查本地是否已經存在Maven還有當前Spark所依賴的Scala版本,如果不存在它會自動幫你下載到build目錄中並解壓使用;Maven源最好配置成OSChina的中央庫,這下載依賴包比較快;
耐心等待,我編譯過多次所以沒有下載依賴包,大概半個小時左右編譯完成;註意:如果使用的是Java 1.8需要給JVM配置堆與非堆記憶體,如:export MAVEN_OPTS="-Xmx1.5g -XX:MaxPermSize=512M -XX:ReservedCodeCacheSize=512m";
進入Spark根目錄下,執行:
./make-distribution.sh --tgz
--tgz 參數是指編譯後生成tgz包
- PHadoop 支持Hadoop
-Pyarn :支持yarn
-Phive :支持hive
--with-tachyon:支持tachyon記憶體文件系統
-name:與--tgz一起用時,name代替Hadoop版本號
./make-distribution.sh --tgz --name 2.6.0 -Pyarn -Phadoop-2.6 -Phive 開始編譯檢查本地環境,如不存在合適的Scala與Maven就在後臺下載;
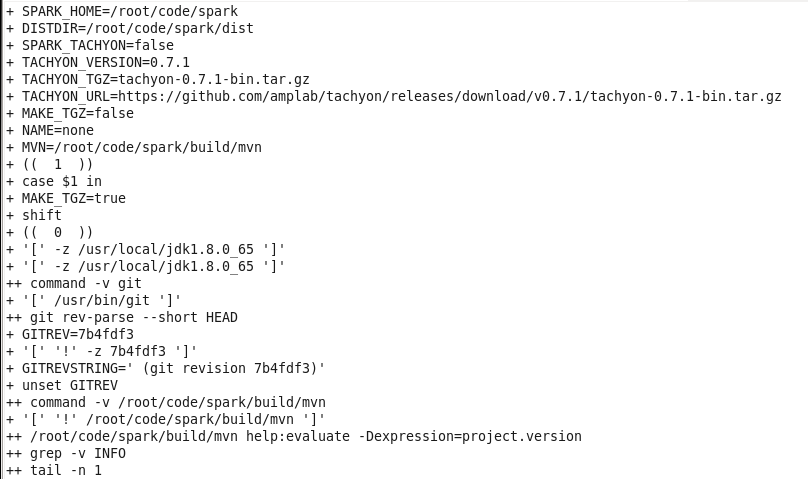
編譯中:
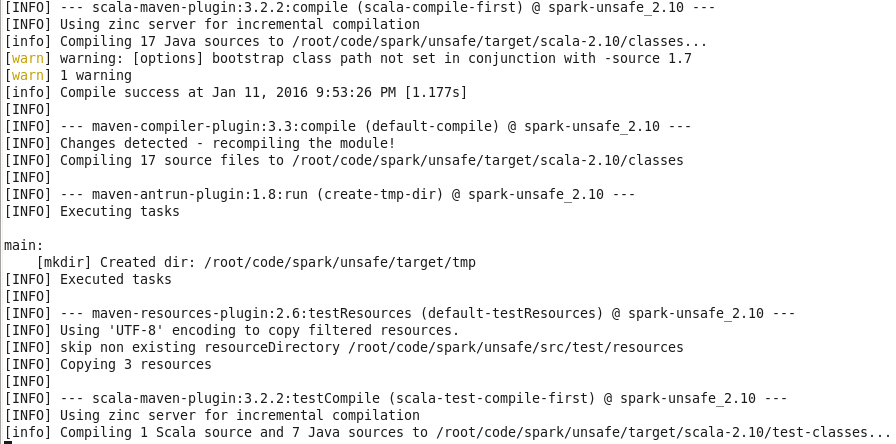
編譯完成並打包生成tgz:
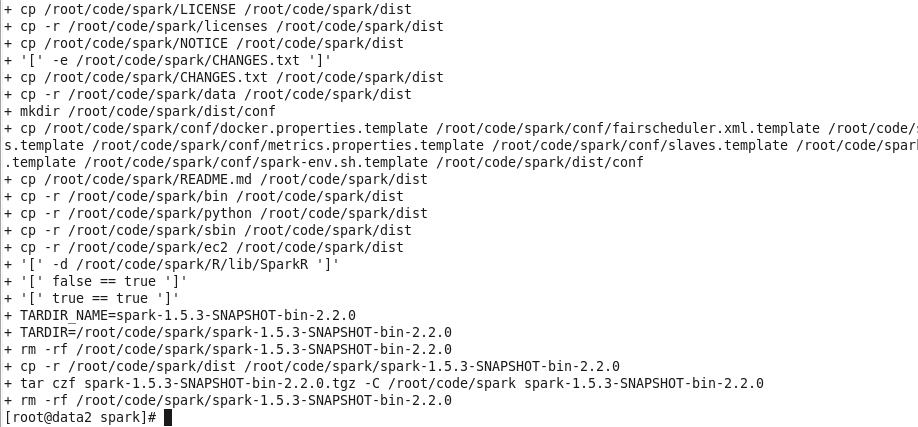
編譯完成後把生成的文件拷貝到當前Spark的dist目錄中並且打包生成spark-1.5.3-SNAPSHOT-bin-2.2.0.tgz文件;

文章首發地址:Solinx
http://www.solinx.co/archives/558


