
Java使用jdbc連接Hive比較簡單,但是Hive的計算能力相對於其它資料庫的SQL而言較弱,要完成非常規的計算需要將數據取出後用Java進一步計算,編程比較麻煩。使用集算器配合Java編程,可以減少Java使用Hive時要進行複雜計算工作量。下麵我們通過例子來看一下具體作法:Hive中的or....
Java使用jdbc連接Hive比較簡單,但是Hive的計算能力相對於其它資料庫的SQL而言較弱,要完成非常規的計算需要將數據取出後用Java進一步計算,編程比較麻煩。
使用集算器配合Java編程,可以減少Java使用Hive時要進行複雜計算工作量。下麵我們通過例子來看一下具體作法:Hive中的orders表中保存了訂單的明細數據,需要計算同期比和比上期。數據如下:
ORDERID CLIENT SELLERID AMOUNT ORDERDATE
1 UJRNP 17 392 2008/11/2 15:28
2 SJCH 6 4802 2008/11/9 15:28
3 UJRNP 16 13500 2008/11/5 15:28
4 PWQ 9 26100 2008/11/8 15:28
5 PWQ 11 4410 2008/11/12 15:28
6 HANAR 18 6174 2008/11/7 15:28
7 EGU 2 17800 2008/11/6 15:28
8 VILJX 7 2156 2008/11/9 15:28
9 JAYB 14 17400 2008/11/12 15:28
10 JAXE 19 19200 2008/11/12 15:28
11 SJCH 7 13700 2008/11/10 15:28
12 QUICK 11 21200 2008/11/13 15:28
13 HL 12 21400 2008/11/21 15:28
14 JAYB 1 7644 2008/11/16 15:28
15 MIP 16 3234 2008/11/19 15:28
…
比上期是指用當期數據和上期數據進行比較,以月作為時間間隔,比如用4月份的銷售額除以3月份的銷售額,這稱為4月份的比上期。同期比是指用當期數據和上一周期的同期數據進行比較,比如2014年4月份的銷售額除以2013年4月份的銷售額。因為Hive沒有視窗函數,所以難以完成這個計算需求,必須編寫嵌套的SQL子查詢,而Hive對子查詢的支持也不夠完備,這個計算目標經常需要放在外部實現。集算器esProc則可以比較容易的實現,具體代碼如下:
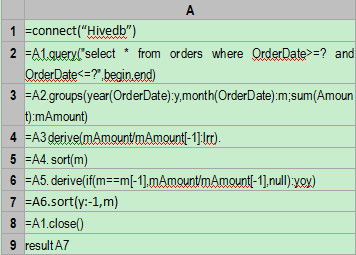
A1:使用定義好的Hive數據源,通過jdbc連接資料庫。
A2:按時間段從資料庫查詢數據,begin和end是外部參數,比如begin=”2011-01-01 00:00:00″,end=”2014-07-08 00:00:00″(即當天日期,可用now()函數獲取)。
A3:對訂單按照年份和月份進行分組,並彙總求得每月的銷售額。
A4:增加一個新的欄位lrr,即按月比上期,其表達式為mAmount/mAmount[-1]。代碼中mAmount代表當期銷售額,mAmount[-1]代表上期銷售額。需要註意的是,初始月份的比上期值為空(即2011年1月)。
A5:將A4按照月、年排序,以便計算同期比。完整的代碼應當是:=A4.sort(m,y),由於A4本來就是按年排序的,因此只需按月排序就可以達到目的,即A4.sort(m),這樣性能也高。A6: 增加一個新的欄位yoy,即月銷售額的同期比,其表達式為if(m==m[-1],mAmount/mAmount[-1],null),這表示月份相同時才進行同期比計算。需要註意的是,初始年份(即2011年)各月份的同期比為空。
A7:將A6按照年逆序月正序進行排序。需要註意的是,數據只到2014年7月為止。結果如下:

A8:關閉Hive資料庫連接。
A9:返回結果。
在Java程式中使用esProc JDBC調用這段程式獲得結果的代碼如下:(將上述esProc程式保存為test.dfx):
//建立esProc jdbc連接
Class.forName(“com.esproc.jdbc.InternalDriver”);
con= DriverManager.getConnection(“jdbc:esproc:local://”);
//調用esProc 程式(存儲過程),其中test是dfx的文件名
st =(com.esproc.jdbc.InternalCStatement)con.prepareCall(“call test(?,?)”);
//設置參數
st.setObject(1,”2011-01-01 00:00:00″);//begin
st.setObject(1,”2014-07-08 00:00:00″);//end
//執行esProc存儲過程
st.execute();
//獲取結果集
ResultSet set = st.getResultSet();
集算器訪問Hive和訪問普通資料庫一樣,配好Hive的JDBC即可,這裡不再贅述。


