
一、OSD模塊簡介 1.1 消息封裝:在OSD上發送和接收信息。 cluster_messenger -與其它OSDs和monitors溝通 client_messenger -與客戶端溝通 1.2 消息調度: Dispatcher類,主要負責消息分類 1.3 工作隊列: 1.3.1 OpWQ: 處 ...
一、OSD模塊簡介
1.1 消息封裝:在OSD上發送和接收信息。
cluster_messenger -與其它OSDs和monitors溝通
client_messenger -與客戶端溝通
1.2 消息調度:
Dispatcher類,主要負責消息分類
1.3 工作隊列:
1.3.1 OpWQ: 處理ops(從客戶端)和sub ops(從其他的OSD)。運行在op_tp線程池。
1.3.2 PeeringWQ: 處理peering任務,運行在op_tp線程池。
1.3.3 CommandWQ:處理cmd命令,運行在command_tp。
1.3.4 RecoveryWQ: 數據修複,運行在recovery_tp。
1.3.5 SnapTrimWQ: 快照相關,運行在disk_tp。
1.3.6 ScrubWQ: scrub,運行在disk_tp。
1.3.7 ScrubFinalizeWQ: scrub,運行在disk_tp。
1.3.8 RepScrubWQ: scrub,運行在disk_tp。
1.3.9 RemoveWQ: 刪除舊的pg目錄。運行在disk_tp。
1.4 線程池:
有4種OSD線程池:
1.4.1 op_tp: 處理ops和sub ops
1.4.2 recovery_tp:處理修複任務
1.4.3 disk_tp: 處理磁碟密集型任務
1.4.4 command_tp: 處理命令
1.5 主要對象:
ObjectStore *store;
OSDSuperblock superblock; 主要是版本號等信息
OSDMapRef osdmap;
1.6 主要操作流程: 參考文章
1.6.1 客戶端發起請求過程
1.6.2 op_tp線程處理數據讀取
1.6.3 對象操作的處理過程
1.6.4 修改操作的處理
1.6.5 日誌的寫入
1.6.6 寫操作處理
1.6.7 事務的sync過程
1.6.8 日誌恢復
1.7 整體處理過程圖

二、客戶端寫入數據大致流程及保存形式
2.1 讀寫框架



2.2 客戶端寫入流程
在客戶端使用 rbd 時一般有兩種方法:
- 第一種 是 Kernel rbd。就是創建了rbd設備後,把rbd設備map到內核中,形成一個虛擬的塊設備,這時這個塊設備同其他通用塊設備一樣,一般的設備文件為/dev/rbd0,後續直接使用這個塊設備文件就可以了,可以把 /dev/rbd0 格式化後 mount 到某個目錄,也可以直接作為裸設備使用。這時對rbd設備的操作都通過kernel rbd操作方法進行的。
- 第二種是 librbd 方式。就是創建了rbd設備後,這時可以使用librbd、librados庫進行訪問管理塊設備。這種方式不會map到內核,直接調用librbd提供的介面,可以實現對rbd設備的訪問和管理,但是不會在客戶端產生塊設備文件。
應用寫入rbd塊設備的過程:
- 應用調用 librbd 介面或者對linux 內核虛擬塊設備寫入二進位塊。下麵以 librbd 為例。
- librbd 對二進位塊進行分塊,預設塊大小為 4M,每一塊都有名字,成為一個對象
- librbd 調用 librados 將對象寫入 Ceph 集群
- librados 向主 OSD 寫入分好塊的二進位數據塊 (先建立TCP/IP連接,然後發送消息給 OSD,OSD 接收後寫入其磁碟)
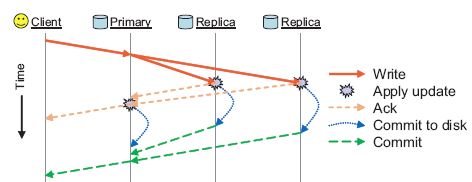
- 主 OSD 負責同時向一個或者多個次 OSD 寫入副本。註意這裡是寫到日誌(Journal)就返回,因此,使用SSD作為Journal的話,可以提高響應速度,做到伺服器端對客戶端的快速同步返回寫結果(ack)。
- 當主次OSD都寫入完成後,主 OSD 向客戶端返回寫入成功。
- 當一段時間(也許得幾秒鐘)後Journal 中的數據向磁碟寫入成功後,Ceph通過事件通知客戶端數據寫入磁碟成功(commit),此時,客戶端可以將寫緩存中的數據徹底清除掉了。
- 預設地,Ceph 客戶端會緩存寫入的數據直到收到集群的commit通知。如果此階段內(在寫方法返回到收到commit通知之間)OSD 出故障導致數據寫入文件系統失敗,Ceph 將會允許客戶端重做尚未提交的操作(replay)。因此,PG 有個狀態叫 replay:“The placement group is waiting for clients to replay operations after an OSD crashed.”。
也就是,文件系統負責文件處理,librbd 負責塊處理,librados 負責對象處理,OSD 負責將數據寫入在Journal和磁碟中。
2.3 RBD保存形式
如下圖所示,Ceph 系統中不同層次的組件/用戶所看到的數據的形式是不一樣的:
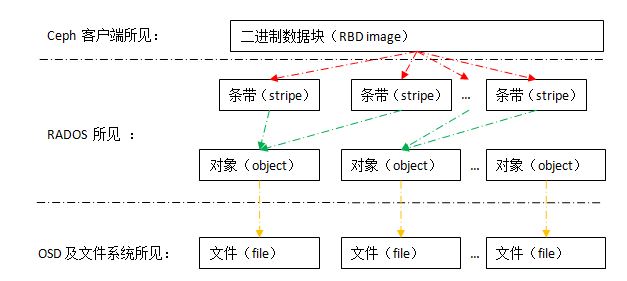
- Ceph 客戶端所見的是一個完整的連續的二進位數據塊,其大小為創建 RBD image 是設置的大小或者 resize 的大小,客戶端可以從頭或者從某個位置開始寫入二進位數據。
- librados 負責在 RADOS 中創建對象(object),其大小為 pool 的 order 決定,預設情況下 order = 22 此時 object 大小為 4MB;以及負責將客戶端傳入的二進位塊條帶化為若幹個條帶(stripe)。
- librados 控制哪個條帶由哪個 OSD 寫入(條帶 ---寫入哪個----> object ----位於哪個 ----> OSD)
- OSD 負責創建在文件系統中創建文件,並將 librados 傳入的數據寫入數據。
Ceph client 向一個 RBD image 寫入二進位數據(假設 pool 的拷貝份數為 3):
(1)Ceph client 調用 librados 創建一個 RBD image,這時候不會做存儲空間分配,而是創建若幹元數據對象來保存元數據信息。
(2)Ceph client 調用 librados 開始寫數據。librados 計算條帶、object 等,然後開始寫第一個 stripe 到特定的目標 object。
(3)librados 根據 CRUSH 演算法,計算出 object 所對應的主 OSD ID,並將二進位數據發給它。
(4)主 OSD 負責調用文件系統介面將二進位數據寫入磁碟上的文件(每個 object 對應一個 file,file 的內容是一個或者多個 stripe)。
(5)主 ODS 完成數據寫入後,它使用 CRUSH 算啊計算出第二個OSD(secondary OSD)和第三個OSD(tertiary OSD)的位置,然後向這兩個 OSD 拷貝對象。都完成後,它向 ceph client 反饋該 object 保存完畢。

(6)然後寫第二個條帶,直到全部寫入完成。全部完成後,librados 還應該會做元數據更新,比如寫入新的 size 等。
完整的過程(來源):
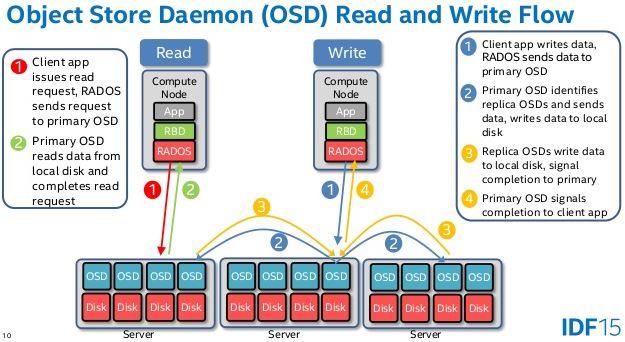
該過程具有強一致性的特點:
- Ceph 的讀寫操作採用 Primary-Replica 模型,Client 只向 Object 所對應 OSD set 的 Primary 發起讀寫請求,這保證了數據的強一致性。
- 由於每個 Object 都只有一個 Primary OSD,因此對 Object 的更新都是順序的,不存在同步問題。
- 當 Primary 收到 Object 的寫請求時,它負責把數據發送給其他 Replicas,只要這個數據被保存在所有的OSD上時,Primary 才應答Object的寫請求,這保證了副本的一致性。這也帶來一些副作用。相比那些只實現了最終一致性的存儲系統比如 Swift,Ceph 只有三份拷貝都寫入完成後才算寫入完成,這在出現磁碟損壞時會出現寫延遲增加。
- 在 OSD 上,在收到數據存放指令後,它會產生2~3個磁碟seek操作:
- 把寫操作記錄到 OSD 的 Journal 文件上(Journal是為了保證寫操作的原子性)。
- 把寫操作更新到 Object 對應的文件上。
- 把寫操作記錄到 PG Log 文件上。
三、客戶端請求流程(轉的一隻小江的博文,寫的挺好的)
RADOS讀對象流程

RADOS寫對象操作流程

例子:
#!/usr/bin/env python
import sys,rados,rbd
def connectceph():
cluster = rados.Rados(conffile = '/root/xuyanjiangtest/ceph-0.94.3/src/ceph.conf')
cluster.connect()
ioctx = cluster.open_ioctx('mypool')
rbd_inst = rbd.RBD()
size = 4*1024**3 #4 GiB
rbd_inst.create(ioctx,'myimage',size)
image = rbd.Image(ioctx,'myimage')
data = 'foo'* 200
image.write(data,0)
image.close()
ioctx.close()
cluster.shutdown()
if __name__ == "__main__":
connectceph()
1. 首先cluster = rados.Rados(conffile = 'ceph.conf'),用當前的這個ceph的配置文件去創建一個rados,這裡主要是解析ceph.conf中中的集群配置參數。然後將這些參數的值保存在rados中。
2. cluster.connect() ,這裡將會創建一個radosclient的結構,這裡會把這個結構主要包含了幾個功能模塊:消息管理模塊Messager,數據處理模塊Objector,finisher線程模塊。
3. ioctx = cluster.open_ioctx('mypool'),為一個名字叫做mypool的存儲池創建一個ioctx ,ioctx中會指明radosclient與Objector模塊,同時也會記錄mypool的信息,包括pool的參數等。
4. rbd_inst.create(ioctx,'myimage',size) ,創建一個名字為myimage的rbd設備,之後就是將數據寫入這個設備。
5. image = rbd.Image(ioctx,'myimage'),創建image結構,這裡該結構將myimage與ioctx 聯繫起來,後面可以通過image結構直接找到ioctx。這裡會將ioctx複製兩份,分為為data_ioctx和md_ctx。見明知意,一個用來處理rbd的存儲數據,一個用來處理rbd的管理數據。
流程圖:

1. image.write(data,0),通過image開始了一個寫請求的生命的開始。這裡指明瞭request的兩個基本要素 buffer=data 和 offset=0。由這裡開始進入了ceph的世界,也是c++的世界。
由image.write(data,0) 轉化為librbd.cc 文件中的Image::write() 函數,來看看這個函數的主要實現
ssize_t Image::write(uint64_t ofs, size_t len, bufferlist& bl)
{ ImageCtx *ictx = (ImageCtx *)ctx; int r = librbd::write(ictx, ofs, len, bl.c_str(), 0); return r; }2. 該函數中直接進行分發給了librbd::wrte的函數了。跟隨下來看看librbd::write中的實現。該函數的具體實現在internal.cc文件中。
ssize_t write(ImageCtx *ictx, uint64_t off, size_t len, const char *buf, int op_flags)
{ Context *ctx = new C_SafeCond(&mylock, &cond, &done, &ret); //---a AioCompletion *c = aio_create_completion_internal(ctx, rbd_ctx_cb);//---b r = aio_write(ictx, off, mylen, buf, c, op_flags); //---c while (!done) cond.Wait(mylock); // ---d
}---a.這句要為這個操作申請一個回調操作,所謂的回調就是一些收尾的工作,信號喚醒處理。
---b。這句是要申請一個io完成時 要進行的操作,當io完成時,會調用rbd_ctx_cb函數,該函數會繼續調用ctx->complete()。
---c.該函數aio_write會繼續處理這個請求。
---d.當c句將這個io下發到osd的時候,osd還沒請求處理完成,則等待在d上,直到底層處理完請求,回調b申請的 AioCompletion, 繼續調用a中的ctx->complete(),喚醒這裡的等待信號,然後程式繼續向下執行。
3.再來看看aio_write 拿到了 請求的offset和buffer會做點什麼呢?
int aio_write(ImageCtx *ictx, uint64_t off, size_t len, const char *buf, AioCompletion *c, int op_flags)
{ //將請求按著object進行拆分 vector<ObjectExtent> extents; if (len > 0) { Striper::file_to_extents(ictx->cct, ictx->format_string, &ictx->layout, off, clip_len, 0, extents); //---a } //處理每一個object上的請求數據 for (vector<ObjectExtent>::iterator p = extents.begin(); p != extents.end(); ++p) { C_AioWrite *req_comp = new C_AioWrite(cct, c); //---b AioWrite *req = new AioWrite(ictx, p->oid.name, p->objectno, p- >offset,bl,….., req_comp); //---c r = req->send(); //---d }
}根據請求的大小需要將這個請求按著object進行劃分,由函數file_to_extents進行處理,處理完成後按著object進行保存在extents中。file_to_extents()存在很多同名函數註意區分。這些函數的主要內容做了一件事兒,那就對原始請求的拆分。
一個rbd設備是有很多的object組成,也就是將rbd設備進行切塊,每一個塊叫做object,每個object的大小預設為4M,也可以自己指定。file_to_extents函數將這個大的請求分別映射到object上去,拆成了很多小的請求如下圖。最後映射的結果保存在ObjectExtent中。

原本的offset是指在rbd內的偏移量(寫入rbd的位置),經過file_to_extents後,轉化成了一個或者多個object的內部的偏移量offset0。這樣轉化後處理一批這個object內的請求。
4. 再回到 aio_write函數中,需要將拆分後的每一個object請求進行處理。
---b.為寫請求申請一個回調處理函數。
---c.根據object內部的請求,創建一個叫做AioWrite的結構。
---d.將這個AioWrite的req進行下發send().
5. 這裡AioWrite 是繼承自 AbstractWrite ,AbstractWrite 繼承自AioRequest類,在AbstractWrite 類中定義了send的方法,看下send的具體內容.
int AbstractWrite::send() { if (send_pre()) //---a
}
#進入send_pre()函數中
bool AbstractWrite::send_pre()
{ m_state = LIBRBD_AIO_WRITE_PRE; // ----a FunctionContext *ctx = //----b new FunctionContext( boost::bind(&AioRequest::complete, this, _1)); m_ictx->object_map.aio_update(ctx); //-----c
}---a.修改m_state 狀態為LIBRBD_AIO_WRITE_PRE。
---b.申請一個回調函數,實際調用AioRequest::complete()
---c.開始下發object_map.aio_update的請求,這是一個狀態更新的函數,不是很重要的環節,這裡不再多說,當更新的請求完成時會自動回調到b申請的回調函數。
6. 進入到AioRequest::complete() 函數中。
void AioRequest::complete(int r)
{ if (should_complete(r)) //---a
}---a.should_complete函數是一個純虛函數,需要在繼承類AbstractWrite中實現,來7. 看看AbstractWrite:: should_complete()
bool AbstractWrite::should_complete(int r)
{ switch (m_state) { case LIBRBD_AIO_WRITE_PRE: //----a { send_write(); //----b----a.在send_pre中已經設置m_state的狀態為LIBRBD_AIO_WRITE_PRE,所以會走這個分支。
----b. send_write()函數中,會繼續進行處理,
7.1.下麵來看這個send_write函數
void AbstractWrite::send_write()
{ m_state = LIBRBD_AIO_WRITE_FLAT; //----a add_write_ops(&m_write); // ----b int r = m_ictx->data_ctx.aio_operate(m_oid, rados_completion, &m_write);
}
---a.重新設置m_state的狀態為 LIBRBD_AIO_WRITE_FLAT。
---b.填充m_write,將請求轉化為m_write。
---c.下發m_write ,使用data_ctx.aio_operate 函數處理。繼續調用io_ctx_impl->aio_operate()函數,繼續調用objecter->mutate().
8. objecter->mutate()
ceph_tid_t mutate(……..) { Op *o = prepare_mutate_op(oid, oloc, op, snapc, mtime, flags, onack, oncommit, objver); //----d return op_submit(o);
}---d.將請求轉化為Op請求,繼續使用op_submit下發這個請求。在op_submit中繼續調用_op_submit_with_budget處理請求。繼續調用_op_submit處理。
8.1 _op_submit 的處理過程。這裡值得細看
ceph_tid_t Objecter::_op_submit(Op *op, RWLock::Context& lc)
{ check_for_latest_map = _calc_target(&op->target, &op->last_force_resend); //---a int r = _get_session(op->target.osd, &s, lc); //---b _session_op_assign(s, op); //----c _send_op(op, m); //----d}
----a. _calc_target,通過計算當前object的保存的osd,然後將主osd保存在target中,rbd寫數據都是先發送到主osd,主osd再將數據發送到其他的副本osd上。這裡對於怎麼來選取osd集合與主osd的關係就不再多說,在《ceph的數據存儲之路(3)》中已經講述這個過程的原理了,代碼部分不難理解。
----b. _get_session,該函數是用來與主osd建立通信的,建立通信後,可以通過該通道發送給主osd。再來看看這個函數是怎麼處理的
9. _get_session
int Objecter::_get_session(int osd, OSDSession **session, RWLock::Context& lc)
{ map<int,OSDSession*>::iterator p = osd_sessions.find(osd); //----a OSDSession *s = new OSDSession(cct, osd); //----b osd_sessions[osd] = s;//--c s->con = messenger->get_connection(osdmap->get_inst(osd));//-d
}
----a.首先在osd_sessions中查找是否已經存在一個連接可以直接使用,第一次通信是沒有的。
----b.重新申請一個OSDSession,並且使用osd等信息進行初始化。
---c. 將新申請的OSDSession添加到osd_sessions中保存,以備下次使用。
----d.調用messager的get_connection方法。在該方法中繼續想辦法與目標osd建立連接。
10. messager 是由子類simpleMessager實現的,下麵來看下SimpleMessager中get_connection的實現方法
ConnectionRef SimpleMessenger::get_connection(const entity_inst_t& dest)
{ Pipe *pipe = _lookup_pipe(dest.addr); //-----a if (pipe) { } else { pipe = connect_rank(dest.addr, dest.name.type(), NULL, NULL); //----b }
}
----a.首先要查找這個pipe,第一次通信,自然這個pipe是不存在的。
----b. connect_rank 會根據這個目標osd的addr進行創建。看下connect_rank做了什麼。
11. SimpleMessenger::connect_rank
Pipe *SimpleMessenger::connect_rank(const entity_addr_t& addr, int type, PipeConnection *con, Message *first)
{ Pipe *pipe = new Pipe(this, Pipe::STATE_CONNECTING, static_cast<PipeConnection*>(con)); //----a pipe->set_peer_type(type); //----b pipe->set_peer_addr(addr); //----c pipe->policy = get_policy(type); //----d pipe->start_writer(); //----e return pipe; //----f
}----a.首先需要創建這個pipe,並且pipe同pipecon進行關聯。
----b,----c,-----d。都是進行一些參數的設置。
----e.開始啟動pipe的寫線程,這裡pipe的寫線程的處理函數pipe->writer(),該函數中會嘗試連接osd。並且建立socket連接通道。
目前的資源統計一下,寫請求可以根據目標主osd,去查找或者建立一個OSDSession,這個OSDSession中會有一個管理數據通道的Pipe結構,然後這個結構中存在一個發送消息的處理線程writer,這個線程會保持與目標osd的socket通信。
12. 建立並且獲取到了這些資源,這時再回到_op_submit 函數中
ceph_tid_t Objecter::_op_submit(Op *op, RWLock::Context& lc)
{ check_for_latest_map = _calc_target(&op->target, &op->last_force_resend); //---a int r = _get_session(op->target.osd, &s, lc); //---b _session_op_assign(s, op); //----c MOSDOp *m = _prepare_osd_op(op); //-----d _send_op(op, m); //----e
}---c,將當前的op請求與這個session進行綁定,在後面發送請求的時候能知道使用哪一個session進行發送。
--d,將op轉化為MOSDop,後面會以MOSDOp為對象進行處理的。
---e,_send_op 會根據之前建立的通信通道,將這個MOSDOp發送出去。_send_op 中調用op->session->con->send_message(m),這個方法會調用SimpleMessager-> send_message(m), 再調用_send_message(),再調用submit_message().在submit_message會找到之前的pipe,然後調用pipe->send方法,最後通過pipe->writer的線程發送到目標osd。
自此,客戶就等待osd處理完成返回結果了。

1.看左上角的rados結構,首先創建io環境,創建rados信息,將配置文件中的數據結構化到rados中。
2.根據rados創建一個radosclient的客戶端結構,該結構包括了三個重要的模塊,finiser 回調處理線程、Messager消息處理結構、Objector數據處理結構。最後的數據都是要封裝成消息 通過Messager發送給目標的osd。
3.根據pool的信息與radosclient進行創建一個ioctx,這裡麵包好了pool相關的信息,然後獲得這些信息後在數據處理時會用到。
4.緊接著會複製這個ioctx到imagectx中,變成data_ioctx與md_ioctx數據處理通道,最後將imagectx封裝到image結構當中。之後所有的寫操作都會通過這個image進行。順著image的結構可以找到前面創建並且可以使用的數據結構。
5.通過最右上角的image進行讀寫操作,當讀寫操作的對象為image時,這個image會開始處理請求,然後這個請求經過處理拆分成object對象的請求。拆分後會交給objector進行處理查找目標osd,當然這裡使用的就是crush演算法,找到目標osd的集合與主osd。
6.將請求op封裝成MOSDOp消息,然後交給SimpleMessager處理,SimpleMessager會嘗試在已有的osd_session中查找,如果沒有找到對應的session,則會重新創建一個OSDSession,並且為這個OSDSession創建一個數據通道pipe,把數據通道保存在SimpleMessager中,可以下次使用。
7.pipe 會與目標osd建立Socket通信通道,pipe會有專門的寫線程writer來負責socket通信。線上程writer中會先連接目標ip,建立通信。消息從SimpleMessager收到後會保存到pipe的outq隊列中,writer線程另外的一個用途就是監視這個outq隊列,當隊列中存在消息等待發送時,會就將消息寫入socket,發送給目標OSD。
8. 等待OSD將數據消息處理完成之後,就是進行回調,反饋執行結果,然後一步步的將結果告知調用者。
四、Ceph讀流程
OSD端讀消息分發流程

OSD端讀操作處理流程

總體流程圖:

int read(inodeno_t ino,
file_layout_t *layout,
snapid_t snap,
uint64_t offset,
uint64_t len,
bufferlist *bl, // ptr to data
int flags,
Context *onfinish,
int op_flags = 0) --------------------------------Filer.h
Striper::file_to_extents(cct, ino, layout, offset, len, truncate_size, extents);//將要讀取數據的長度和偏移轉化為要訪問的對象,extents沿用了brtfs文件系統的概念
objecter->sg_read_trunc(extents, snap, bl, flags, truncate_size, truncate_seq, onfinish, op_flags);//向osd發起請求
對於讀操作而言:
1.客戶端直接計算出存儲數據所屬於的主osd,直接給主osd上發送消息。
2.主osd收到消息後,可以調用Filestore直接讀取處在底層文件系統中的主pg裡面的內容然後返回給客戶端。具體調用函數在ReplicatedPG::do_osd_ops中實現。
CEPH_OSD_OP_MAPEXT||CEPH_OSD_OP_SPARSE_READ
r = osd->store->fiemap(coll, soid, op.extent.offset, op.extent.length, bl);
CEPH_OSD_OP_READ
r = pgbackend->objects_read_sync(soid, miter->first, miter->second, &tmpbl);
五、Ceph寫流程
OSD端寫操作處理流程

而對於寫操作而言,由於要保證數據寫入的同步性就會複雜很多:
1.首先客戶端會將數據發送給主osd,
2.主osd同樣要先進行寫操作預處理,完成後它要發送寫消息給其他的從osd,讓他們對副本pg進行更改,
3.從osd通過FileJournal完成寫操作到Journal中後發送消息告訴主osd說完成,進入5
4.當主osd收到所有的從osd完成寫操作的消息後,會通過FileJournal完成自身的寫操作到Journal中。完成後會通知客戶端,已經完成了寫操作。
5.主osd,從osd的線程開始工作調用Filestore將Journal中的數據寫入到底層文件系統中。
寫的邏輯流程圖如圖:

從圖中我們可以看到寫操作分為以下幾步:
1.OSD::op_tp線程從OSD::op_wq中拿出來操作如本文開始的圖上描述,具體代碼流是

ReplicatePG::apply_repop中創建回調類C_OSD_OpCommit和C_OSD_OpApplied
FileStore::queue_transactions中創建了回調類C_JournaledAhead
2.FileJournal::write_thread線程從FileJournal::writeq中拿出來操作,主要就是寫數據到具體的journal中,具體代碼流:

3.Journal::Finisher.finisher_thread線程從Journal::Finisher.finish_queue中拿出來操作,通過調用C_JournalAhead留下的回調函數FileStore:_journaled_ahead,該線程開始工作兩件事:首先入底層FileStore::op_wq通知開始寫,再入FileStore::ondisk_finisher.finisher_queue通知可以返回。具體代碼流:

4.FileStore::ondisk_finisher.finisher_thread線程從FileStore::ondisk_finisher.finisher_queue中拿出來操作,通過調用C_OSD_OpCommit留下來的回調函數ReplicatePG::op_commit,通知客戶端寫操作成功

5.FileStore::op_tp線程池從FileStore::op_wq中拿出操作(此處的OP_WQ繼承了父類ThreadPool::WorkQueue重寫了_process和_process_finish等函數,所以不同於OSD::op_wq,它有自己的工作流程),首先調用FileStore::_do_op,完成後調用FileStore::_finish_op。

6. FileStore::op_finisher.finisher_thread線程從FileStore::op_finisher.finisher_queue中拿出來操作,通過調用C_OSD_OpApplied留下來的回調函數ReplicatePG::op_applied,通知數據可讀。

具體OSD方面的源碼逐句解析可以參考一隻小江的博文
此文主要整理了參考資料里的ceph客戶端讀寫流程,OSD端讀寫流程等,使用了參考資料的內容,如果侵犯到參照資料作者的權益,請聯繫我,我會及時刪除相關內容。
參考資料:
http://blog.sina.com.cn/s/blog_c2e1a9c7010151xb.html
作者:ywy463726588 http://blog.csdn.net/ywy463726588/article/details/42676493
http://blog.csdn.net/ywy463726588/article/details/42679869
作者:劉世民(Sammy Liu)http://www.cnblogs.com/sammyliu/p/4836014.html
作者:一隻小江 http://my.oschina.net/u/2460844/blog/532755
http://my.oschina.net/u/2460844/blog/534390?fromerr=PnkKCbYU
感謝以上作者無私的分享!


