
基本概念 數據:描述事物的符號稱為數據,是存儲在資料庫中的基本對象。 資料庫:資料庫是長期存儲在電腦上內的有組織、可共用的數據集合。 資料庫管理系統:用戶和操作系統之間的一層數據管理軟體。主要功能包括如下幾個方面: >1 數據定義功能:通過數據定義語言DDL(Data Definition Lan... ...
- 基本概念
- 數據:描述事物的符號稱為數據,是存儲在資料庫中的基本對象。
- 資料庫:資料庫是長期存儲在電腦上內的有組織、可共用的數據集合。
- 資料庫管理系統:用戶和操作系統之間的一層數據管理軟體。主要功能包括如下幾個方面:
>1 數據定義功能:通過數據定義語言DDL(Data Definition Language)實現數據對象的定義
>2 數據組織、存儲和管理
>3 數據操縱:通過數據操縱語言DML(Data Manipulation Language),用戶可以使用DML操縱數據,實現對資料庫的的增、刪、改、查等基本操作
>4 資料庫的事務管理和運行管理
>5 資料庫的建立和維護功能
4、資料庫系統:電腦系統中引入資料庫後的系統,一般由資料庫、資料庫管理系統、應用系統、資料庫管理員組成。
5、數據模型:對現實世界數據特征的抽象,用來描述數據、組織數據和對數據進行操作的。是資料庫系統的基礎和核心。
按照應用目的的不同,可以將其分為兩類:概念模型、第二類邏輯模型和物理模型。
概念模型,又稱信息模型,按照用戶的觀點來對數據和信息建模,主要用於資料庫設計。
概念模型中的基本概念:
實體:客觀存在並可相互區別的事物稱為實體
屬性:實體所具有的某一特性稱為屬性
碼:唯一標識實體的屬性集稱為碼,例如學生實體的學號就是學生實體的碼
域:一組具有數據類型的值的集合。例如學生成績的域為整數
實體型:實體名及其屬性名集合來抽象刻畫同類實體,稱為實體型。
實體集:同一類型實體集合稱為實體集,例如全體學生
聯繫:分為實體內部(實體的各個屬性之間的聯繫)的聯繫和實體間的聯繫(不同實體集之間的聯繫)
邏輯模型是按照電腦系統的觀點對數據進行建模,主要用於DBMS的實現
主要包括層次模型、網狀模型、關係模型、對象關係模型、面向對象模型。
物理模型:是對數據最底層的抽象,描述數據在系統內部的表示方式和存取方法,是面對電腦系統的。
數據模型一般由數據結構、數據操作、完整性約束組成
數據結構:描述資料庫的組成對象以及各對象之間的聯繫,是刻畫資料庫性質最重要的部分,是對系統的靜態描述。
數據操作:對資料庫中的各種對象的實例允許執行的操作的集合,包括操作及有關的操作規則,資料庫主要有查詢和更新(增、刪、改)兩大類操作,是對系統的動態描述
數據的完整性描述:給定的數據模型中的數據及其聯繫所具有的制約和運存規則,用以限定符合數據模型的數據模型的資料庫狀態以及狀態的變化,以保證數據的正確,有效,相容性。
6、實體之間的聯繫
兩個實體模型之間的聯繫可以分為三種:
①一對一聯繫
對於實體集A中的每個實體,實體集B中至多有一個(也可以沒有)實體與之聯繫。
②一對多聯繫
對於實體集A中的每個實體,在實體集B中有n個實體與之聯繫
③多對多聯繫
對於實體集A中的每個實體,實體集B中有n個實體與之聯繫,反之,對於實體集B中的每個實體,實體集A中也有n個實體與之聯繫。
7、實體-聯繫圖(E-R圖)
實體型:用矩形表示,矩形框內些實體名
屬性:用橢圓表示,並用無向邊將其與相應的實體型連接起來
聯繫:用菱形表示,菱形框內寫明聯繫名,並用無向邊分別於相應的實體型連接起來同時在無向邊旁標上聯繫的類型(一對一、一對多等)
8、關係數據模型的數據結構
關係模型中的一些術語:
關係:一個關係對應資料庫中的一張二維表
元組:表中的一行即為一個元組
屬性:表中的一列即為屬性,列名即屬性名
分量:元組中的一個屬性值
9、資料庫系統模式
模式:資料庫中全體數據的邏輯結構和特征的描述
>9.1 資料庫的三級模式結構
模式(三級模式結構中的一級,非上述的模式):也稱邏輯模式,是資料庫中全體數據的邏輯結構和特征的描述,是資料庫數據在邏輯級上的視圖,一個資料庫只能有一個模式
外模式:又稱子模式或用戶模式,它是資料庫用戶(包括程式開發人員和最終用戶)能夠看見的一部分數據的邏輯結構和特征的描述,是資料庫用戶的數據視圖,是於某一應用有關的數據的邏輯顯示。
一個資料庫可以有多個外模式,同一外模式可以為某一用戶的多個應用系統所使用,但一個應用程式只能使用一個外模式。
內模式:也稱存儲模式,一個資料庫只有一個內模式,他是數據物理結構和存儲方式的描述,是數據在資料庫內部的表示方式。
>9.2 資料庫的二級影像功能與數據獨立性
為了在系統內部實現著3個抽象層次的聯繫和轉換,資料庫管理系統在這三級模式之間提供了兩層影像:
外模式/模式影像:定義外模式於模式之間的對應關係
模式/內模式影像 :定義數據全局邏輯結構和存儲結構間的對應關係
>9.3 資料庫的邏輯獨立性
當模式改變時(如增加新的關係、新的屬性、改變屬性的數據類型等),由資料庫管理員對各個外模式/模式的影像做相應的改變,可以使外模式保持不變。(應用程式是根據外模式編寫的)從而使應用程式不用改變),保證數據與應用程式的邏輯獨立性。
>9.4 資料庫的物理獨立性
當資料庫的存儲結構改變時,有資料庫管理員對模式/內模式做相應的改變,可以使模式保持不變,從而使應用程式保持不變,保證了數據與應用程式間的獨立性。
10、關係模型中的基本概念
(1)關係:D1xD2xD3……Dn的子集叫做在於D1、D2…Dn上的關係,表示為R(D1,D2,D3….Dn),其中n為關係的目或度,當n=1時,稱為一元關係
(2)關係模式:關係的描述稱為關係模式,可以形象的概括為?R(U,D,DOM,F)
R為關係名,U為組成該關係的屬性名的集合,D為屬性組U中屬性所來自的域,DOM為屬性向域的影像的集合,F為屬性間數據的依賴關係集合。
10.1 關係的三類完整性約束
實體完整性約束:若屬性(指一個或一組屬性)A是基本關係R的主屬性,則A不能為空
參照完整性:若屬性(或屬性組)F是基本關係R的外碼,它與基本關係S的主碼Ks相對應(基本關係R和S不一定是不同的關係),則對於R中的每個元組在F上的值必須為:
- 或者取空值
- 或者等於S中某個元組的主碼值
註:什麼叫外鍵?
設F是基本關係R的一個或一組屬性,但不是R的碼,Ks是基本關係S的主碼。如果F與Ks相對應,則稱F是R的外鍵。並稱關係R為參照關係,基本關係S為被參照關係。
- 用戶自定義的完整性
針對某一具體關係資料庫的約束條件。它反映某一具體應用所涉及的數據必須滿足的語義條件。
- Check 約束
Check約束可以和列關聯,也可以和表關聯,可以檢查一列值相對於同一表中另一列的值,也可以檢查某一列的值是否符合某個標準
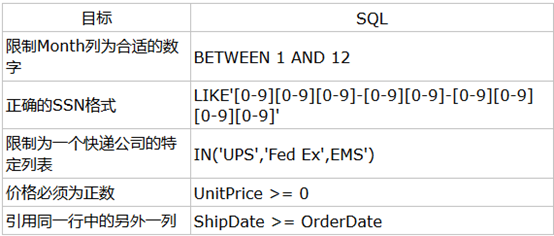
Eg:

2) 唯一性約束
限制某一列的值在整張表中必須是唯一的

3)Default約束
和所有約束一樣,DEFAULT約束也是表定義的一個組成部分,它定義了當插入的新行對於定義了預設約束的列未提供相應數據時該怎麼辦。可以定義它為一個字面值(例如,設置預設薪水為0,或者設置字元串列為"UNKNOWN"),或者某個系統值(getdate())。
對於DEFAULT約束,要瞭解以下幾個特性:
1、預設值只在insert語句中使用-在update語句和delete語句中被忽略。
2、如果在insert語句中提供了任意值,那就不使用預設值。
3、如果沒有提供值,那麼總是使用預設值。

註意:如果使用預設值,則在插入數據是不能省略表名後的列名
11、關係模型中的關係操作
關係模型中常用的關係操作有查詢和插入、刪除、修改,關係操作的對象和結果都是集合。
12、關係模型中的關係運算
- 選擇:在關係R中選擇滿足條件的諸元組
- 投影:從R中選擇出若幹屬性列組成新的關係
- 連接:從兩個關係的笛卡爾積中選取屬性間滿足一定條件的元組
- 基本SQL語句
- 定義模式
Create Schema <模式名> AUTHORZATION <用戶名>
Eg: Create Schema "S-T" AUTHORZATION Test
如果沒有指明模式名,則模式名預設為用戶名
- 刪除模式
Drop Schema <模式名> <CASCADE>|RESTRICT>
CASCADE:級聯模式,刪除模式時將該模式下的所有資料庫對象一起刪除
RESTRICT:限制模式,只有在要刪除的模式下沒有任何對象屬性時才能執行的刪除。
在執行刪除模式時,這兩個必須選其一
- 定義基本表
Create table 表名(列名,數據類型 [列級完整性約束])
Eg:create table test(
Id int primary key identity(1,1),//設置表主鍵 identity(表示為自增主鍵,identity(標識種子,標識增量))
UserName nvarchar(20) not null,
foreign key CardId varchar(20) References Test(id)//設置外鍵,References設置外鍵表及外鍵列
)
- 定義模式
- 註:創建表時設置多列主鍵

- 將表中以存在的列設置為外鍵

2.1 修改基本表
Alter table 表名
Add <列名> <數據類型> [列級完整性約束] /*新增一列*/
註意:不管原來表中是否有數據,新增列的值均為Null
Alter column <列名> <數據類型> /*修改現有列*/
Drop <完整性約束名> /*去除約束*/
2.1 刪除基本表
命令基本格式:Drop table <表名>
表的級聯刪除:
假設現有Student 和 Gender兩張表,Student 表有外鍵Gender,現欲在刪除Gender中的項時將Student中有之關聯的項也刪除
- 給Student 表設置外鍵時指定級聯刪除

- 給Gender表設置觸發器

2.2 表數據更新
2.2.1 插入數據
Insert into <表名[<屬性列1>…]>
values(<常量1>,<常量2>……),()……..
2.2.2 清空表數據
- Delete from <表名>
- Truncate table <表名>
2.2.3 修改數據
Update <表名>
Set <屬性名1> = value1,<屬性名2> = value2…….
Where 更新條件
2.3 數據查詢
2.3.1 選出表中的若幹列
Select <列名1>,<列名2>…
From <表名>
2.3.2 查詢全部列
Select * from <表名>
2.3.3 取消重覆行(通過關鍵字distinct)
Select distinct Sno from Student
若果沒有指明 distinct關鍵字,則預設為all,即顯示全部結果
2.3.4 根據指定條件查詢
Select <列名1>,<列名2>
From 表名
Where 查詢條件
常用查詢條件
比較 >< =、=>、!=、<>、!>(不大於)
確定範圍 between and/not between and
空值判斷 is null /is not null
多重條件 and/or/not
確定集合 in/not in
字元匹配(通過Like關鍵字實現) % :匹配任意多個字元
_: 任意單個字元
Eg: where name like '%明' 查詢名字中含有'明'字的
註意:如果用戶查詢的字元串本身含有通配符%或_時,需要使用Escape'換碼字元',對通配符進行轉義
Where currency like '\_明' escape '\'
這樣'\'後面的'_'將不再具有通配符的語義,而僅僅表示普通的字元
- order by 和group by
3.1 order by
Order by 列名 [ASC(升序,預設值)|DESC(降序)]
Eg :

註意:對於空值排序時不同的資料庫系統可能有不同的實現
3.2 group by
Select <列名1>,<列名2>…. From <表名>
Group by <列名>
Having 聚合函數
註意:select 後面跟的列名必須出現在Group by字句或聚合函數中
聚合函數(即對排序或分組後的集合進行處理):
Count([Distinct|ALL]*) 統計元組個數
Count([Distinct|All<列名>]) 統計一列中值的個數
SUM([Distinct|ALL]<列名>) 統計一列中值的總和
AVG([Distinct|ALL] <列名>) 統計一列值的平均值
Max([Distinct|ALL])/Min([Distinct|ALL]) 求一列中的最大值/最小值
4.嵌套查詢
4.1 帶有In謂詞的子查詢
Eg :

4.2 帶有比較運算符的子查詢

4.3 帶有any 或all謂詞的子查詢
Eg:找出所有學生中年齡最大的學生(年齡大於等於集合中最大的元素)

找出其它部門學生中比IS部門任何人年齡都小的學生

4.4 帶有Exitsts謂詞的子查詢
Exitsts代表存在量詞,不返回任何數據,只產生邏輯真或假
Eg:

判斷Student表中是否有Tom,如果存在則將其Sdept,Sno,Sname信息顯示出來
註:存在Exists的子查詢,只有Exists字句返回true時,外層查詢才執行
- 集合操作
Select語句查詢的結果是元組的集合,多個集合可以進行結合操作,集合的操作包括並操作(Union)、交操作(INTERSECT)、差操作(EXCEPT)
並操作 :

找出 IS部門和MA部門中所有年齡大於20歲的人員信息
交操作:

找出選修了2號和4號課的學生學號
差操作:

找出所有的女生信息
- 視圖
視圖:視圖是從一個或多個基本表(或視圖)導出的表。但它與基本表不同,資料庫中值存放視圖的定義,而不存放視圖對應的數據,這些數據仍存放在原來的表中。
視圖的作用:
- 視圖機制使用戶可以將註意力集中在所關心的數據上。如果這些數據不是直接來自基本表,則可以通過定義視圖,使得資料庫看起來結構簡單、清晰,並且可以簡化用戶的數據查詢操作。
- 視圖可以使用戶以多種角度看待同一數據
- 視圖對重構資料庫提供了一定程度的邏輯獨立性
- 因為隱藏了底層的表結構,所以大大加強了安全性,用戶只能看到視圖提供的數據
- 使用視圖,方便了許可權管理,讓用戶對視圖有許可權而不是對底層表有許可權進一步加強了安全性
行列子集視圖:若一個視圖是從單個基本表導出,並且只是去除了基本表的某些列,但保留了主碼,則稱這類視圖為行列子集視圖。
帶表達式的視圖:帶有虛擬列(基本表中並未定義而是由其他列計算出來的列)的視圖稱為帶表達式的視圖
5.1 建立視圖
Create View <視圖名> [<列名1>,[列名2]。。。]//屬性列名要麼全指定,要麼全部指定,第二種情況下,視圖的屬性列名由子查詢中select字句中目標列中的諸欄位組成
As 子查詢//任意的select語句,
[with check option]//指定該語句,則對視圖進行操作的行要滿足視圖中定義的謂詞條件()即子查詢中的表達式
關於 With check option的理解:
通過視圖進行的修改,必須也能通過該視圖看到修改後的結果。比如你insert,那麼加的這條記錄在刷新視圖後必須可以看到;如果修改,修改完的結果也必須能通過該視圖看到;如果刪除,當然只能刪除視圖裡有顯示的記錄。
5.2 刪除視圖
Drop view 視圖名 [Cascade]
如果該視圖上還導出了其它視圖,則指明CASCADE刪除,則刪除該視圖時,會一併刪除所有導出的視圖
5.3 查詢視圖(與表查詢類似)
5.4 更新視圖(與更新表類似)
並非所有的視圖都是可更新的,行列子集視圖一般是可更新的
- 索引的建立與刪除
索引的作用:建立索引是加快查詢速度的有效手段
6.1 建立索引
Create index[Unique|CLUSER] index <索引名>
On <表名>(<列名>[次序])
Unique表示索引中的每一個索引值只對應唯一的數據記錄。
Cluster 表示要建立的索引是聚簇索引。
聚簇索引:索引項的順序與表中記錄的物理順序一致的索引組織
用戶可以在經常查詢的列上建立聚簇索引以提高查詢效率。顯然在一個基本表上最多只能建立一個聚簇索引。
註意:建立局促索引後,更新該索引列上的數據時,往往會導致表中記錄的物理順序的變更,代價較大,因此對於經常更新的列不宜創建聚簇索引
6.2 索引的刪除
Drop index <索引名>//刪除索引時,系統同時會從數據字典中刪去該索引的描述
- 存儲過程
7.1 創建存儲過程
Create proc <存儲過程名> 參數名 參數類型…..
As
[begin]
<PL/SQL>//其中包括聲明部分和可執行部分
[end]
Eg:MS sql server

7.2 存儲過程的執行
Call/perform procdure 存儲過程名(參數列表)
- 註意:在MS sql 中使用 exec 存儲過程名 參數列表形式來調用存儲過程,
- 在存儲過程中亦可以調用其它的存儲過程
7.3 刪除存儲過程
Drop procdure <存儲過程名>
存儲過程詳解:http://www.cnblogs.com/knowledgesea/archive/2013/01/02/2841588.html
- PL/SQL
8.1 變數和常量的定義
變數名 數據類型 [not null] :=初值表達式
變數名 數據類型 [not null ] 初值表達式
常量名 數據類型 [not null] :=初始化表達式
8.2 條件控制語句
- If condition Then
語句序列(條件為真時執行)
End If
- If condition Then
語句序列(條件為真時執行)
Else
語句序列(條件為假或null時執行)
End If
8.3 迴圈語句
- Loop
語句序列
End Loop
- While condition Loop
語句序列
End Loop
- For count IN [Reverse] bound1…bound2 Loop
語句序列
End Loop
Count:迴圈的下界bound1,檢查它是否小於上界bound2,當指定Reverse時,count為迴圈的上界,檢查它是否大於下界bound1,如果越界,則執行跳出迴圈,然後按照步長更新,count,重新判斷條件。


