
詞法分析器 一、 目標和要求 首先本次實驗分為三個小題分別為:C語言詞法分析器、四則運算文法、解釋器。因此以下一 ~ 九部分是C語言詞法分析器的實驗內容,十 ~ 十三部分是四則運算及其解釋器的實驗內容。 1.第一小題: 明確目標: 按照已經掌握的C語言的詞法規範,編寫能夠按照C語言規範識別每個詞法符 ...
詞法分析器
一、 目標和要求
首先本次實驗分為三個小題分別為:C語言詞法分析器、四則運算文法、解釋器。因此以下一 ~ 九部分是C語言詞法分析器的實驗內容,十 ~ 十三部分是四則運算及其解釋器的實驗內容。
1.第一小題:
明確目標:
按照已經掌握的C語言的詞法規範,編寫能夠按照C語言規範識別每個詞法符號的分析器。從一個文本文件(典型地,就是C語言的源程式文件)中讀入字元流,經過識別之後逐個輸出詞法符號(只需原樣輸出識別到的詞法符號,無需考慮語法屬性)。
幾個要求:
(1)假定該語言有:
預處理指令:以#開頭。
字元常量:單撇號作為界標;
字元串常量:雙撇號作為界標;
數值型常量:數字開頭,如016、0x8b、1.0f、3L都是,這裡只選擇整數;
標識符:非數字開頭的下劃線字母數字串(包括保留字);
運算符:有單字元的,也有多字元的如++、+=、&&=、sizeof等。
分隔符:逗號,分號,括弧,花括弧,冒號(定義標號時使用);
(2)至少要有一個空白符將相鄰的標識符、數值型常量和關鍵字隔開,但不能用空白符將符號中的相鄰字元分開。
(3)註釋是以符號/*開始,並以*/的第一次出現作為結束,或者以//開頭。
(4)需要在輸出結果前說明該符號的詞法屬性。例如:預定義:#include<stdio.h>
2.第二小題:
明確目標:
構造一個能夠實現四則運算的文法。
幾個要求:
對文法的符號、規則、特性以及語言給出準確解釋。
3.第三小題:
明確目標:
根據四則運算文法構造編譯器。
幾個要求:
能夠按照文法規則,逐行解釋執行輸入內容。
二、數據模型
|
單詞符號 |
類型編碼 |
助記符 |
單詞符號 |
類型編碼 |
助記符 |
|
標識符 |
1 |
$SYMBOL |
字元常量 |
2 |
$CHARA |
|
字元串常量 |
3 |
$STRING |
數值型常量 |
4 |
$NUMER
|
|
Int |
5 |
$INT |
If |
6 |
$IF |
|
Else |
7 |
$ELSE |
While |
8 |
$WHILE |
|
For |
9 |
$FOR |
Read |
10 |
$READ |
|
Write |
11 |
$WRITE |
+ |
12 |
$ADD |
|
- |
13 |
$SUB |
* |
14 |
$MUL |
|
/ |
15 |
$DIV |
< |
16 |
$L |
|
++ |
17 |
$INC |
-- |
18 |
$DEC |
|
<= |
19 |
$LE |
> |
20 |
$G |
|
>= |
21 |
$GE |
!= |
22 |
#NE |
|
== |
23 |
#E |
= |
24 |
#ASSIGN |
|
( |
25 |
#LPAR |
) |
26 |
#RPAR |
|
, |
27 |
#COM |
; |
28 |
#SEM |
表1 數據模型圖
三、描述輸出
對於程式段 for(k=0; k<=100; ++k)將產生下麵的結果。
|
步驟 |
輸出 |
含義 |
|
1 |
9, ’for’ |
標識符for |
|
2 |
25, ‘(‘ |
分隔符( |
|
3 |
1, ’k’ |
標識符k |
|
4 |
24, ’=’ |
運算符= |
|
5 |
4, ‘0’ |
數值型常量 |
|
6 |
28, ’;’ |
分隔符; |
|
7 |
1, ’k’ |
標識符k |
|
8 |
19, ’<=’ |
運算符<= |
|
9 |
4, ‘100’ |
數值型常量 |
|
10 |
28, ’;’ |
分隔符; |
|
11 |
17, ’++’ |
運算符++ |
|
12 |
1, ’k’ |
標識符k |
|
13 |
26, ‘)’ |
分隔符) |
表2 輸出描述
四、演算法
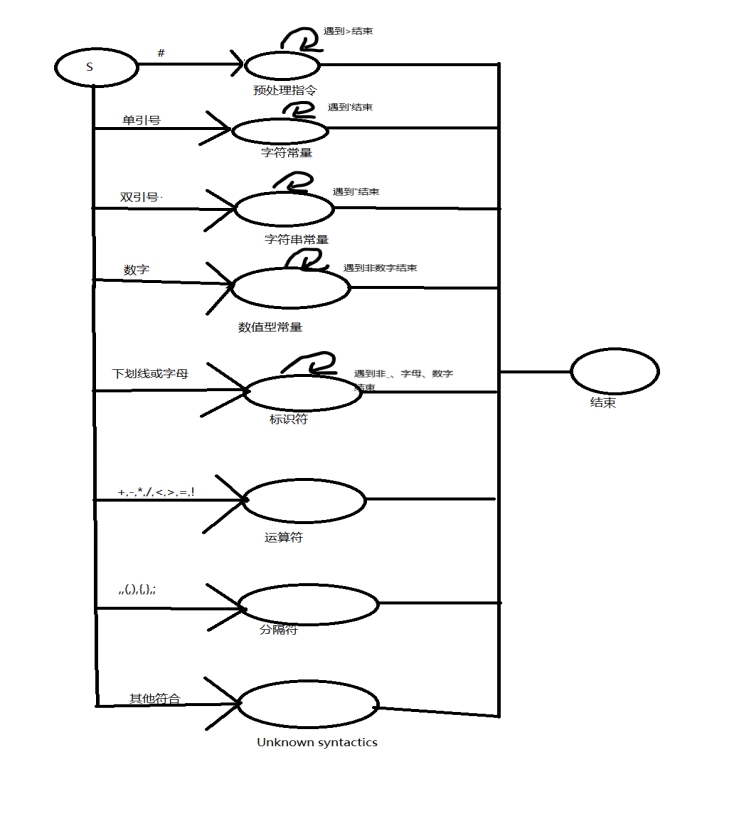
圖1 狀態轉換圖
五、演算法細化
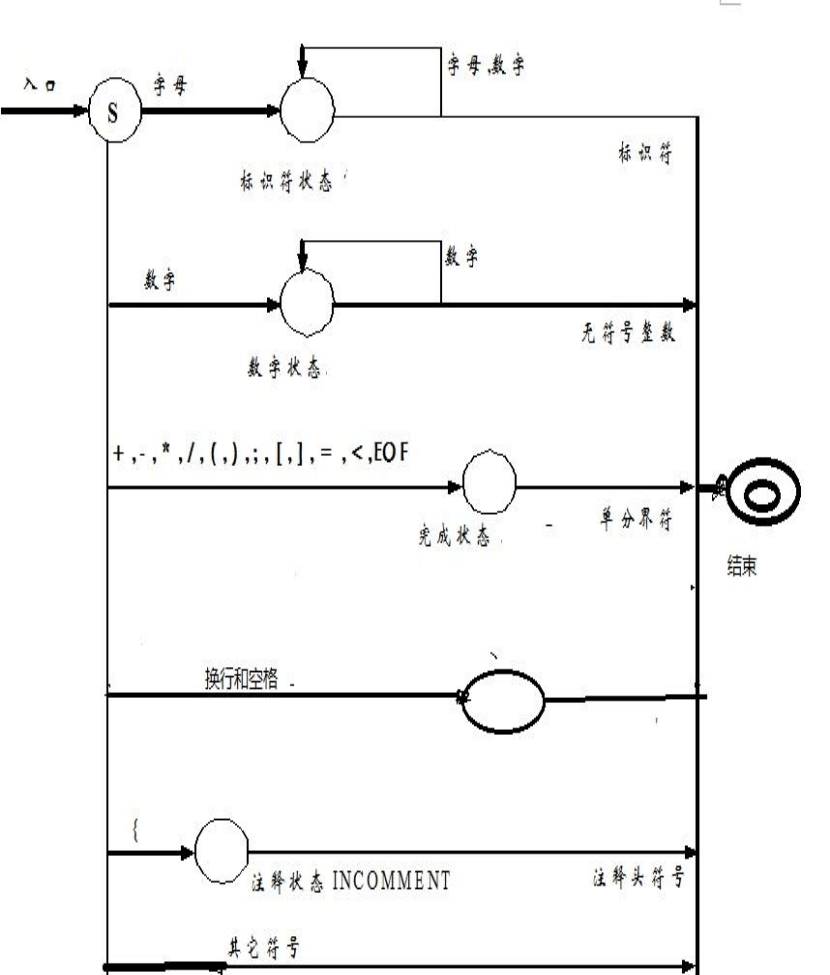
圖2 狀態轉換圖細化
六、流程圖、偽代碼
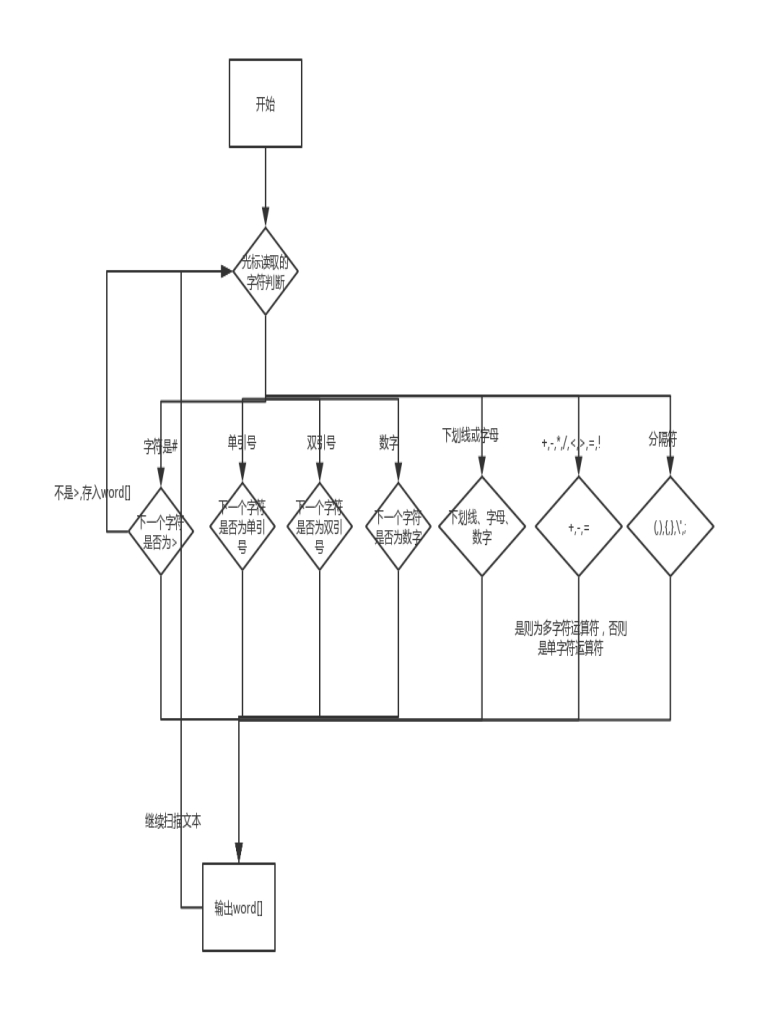
圖3 流程圖
七、編程
1、預定義與頭文件
#include<stdio.h>
#include<ctype.h> //包含isspace函數 ,isalnum()是否字母或數字,isalpha()是否字母
//預處理是以>作為結束,字元是以'作為結束,字元串是以"作為結束,
//數值型常量只能根據當前字元的下一個字元是不是數字判斷是否結束,標識符也是根據下一個字元判斷。所以要記錄下一個字元。
2、全局變數
int current_ch, next_ch,k=0;
int flag = 0;
char word[1024];
FILE *fp;
3、函數原型
//讀下一個字元
void read_next_char();
//預處理指令:
void get_preprocessing_line();
//提取字元型常量:\'
void get_char_const();
//提取字元串常量
void get_string_const();
//提取數值型常量,讀取文本只有整數:
void get_num_const();
//提取標識符:
void get_identifier();
//提取運算符
void get_operator();
//提取分隔符
void get_seperator();
//詞法分析部分的基本流程
int lexical_analyzer(FILE * input_file)
int main()
{
fp = fopen("test.txt","r");
if(fp == NULL)
{
printf("無法找到文件\n");
return 0;
}
current_ch = fgetc(fp);//當前字元
lexical_analyzer(fp);
return 0;
}
完整代碼見附錄。
八、測試
集成測試:測試過程中出現了很多問題,最主要的一個就是對next_ch定義不明確。比如預處理指令判斷是否current_ch=’>’結束,字元是判斷current_ch是否等於單引號和雙引號結束。而數值型常量不同,必須判斷next_ch是否為數字,標識符也是同樣的判斷next_ch。所以我添加了一個flag進行判斷。

圖4 測試文件
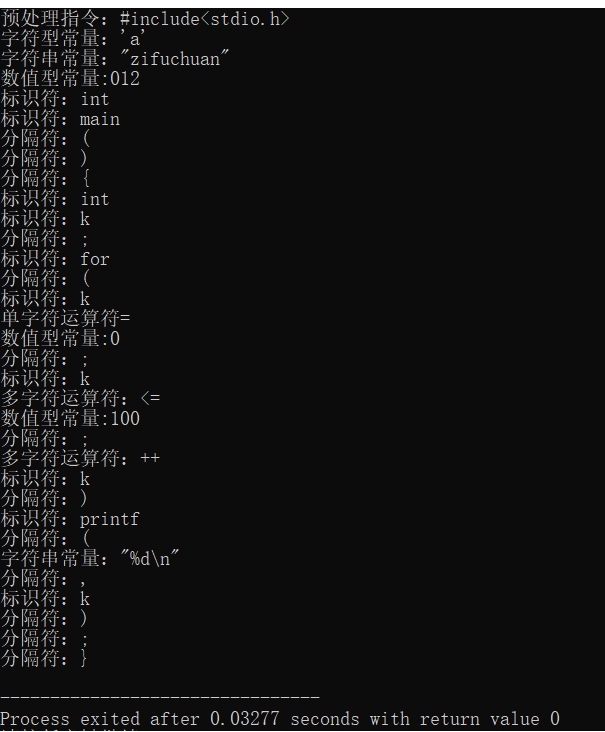
圖5 輸出示例
九、總結
整體來說,本次實驗的難度不大,實驗過程並不涉及語法分析,只是對C語言簡單的詞法分析。題目一給出自然想到的就是使用多個判斷條件,判斷出究竟是保留字、變數、常量、運算符、分隔符、頭文件和預定義還是註釋。其次就是對輸入流字元的處理,我們使用一個字元型數組word來保存。使用flag來判斷current_ch是字元型還是數值型。我們使用C語言面向過程的編程方式進行模塊化的編程,結構比較清晰。
經過參與這次詞法分析的實驗,我們對C語言的詞法有了更進一步的理解。以及對編程語言的此法構成有了進一步的瞭解。知道了一些編譯器的基本工作方式。相信在接下來的學習中我們會對電腦編譯原理有更深層次的理解。
四則運算
十、四則運算文法
四則運算屬於2型文法,所以制定以下文法規則:
運算符→+-*/
整數→[1-9][0-9]* | 0
浮點數→整數.[0-9]*
數→整數 | 浮點數
算式→數 | 算式 運算符 數
用相應符號表示:
算式:S,運算符:P,整數:N,浮點數:F,數:D
P→+-*/
N→[1-9][0-9]* | 0
F→N.[0-9]*
D→N | F
S→D | S P D
十一、解釋器
解釋器的製作需要藉助lex和Yacc兩個工具來完成,在DEV C++環境下運行。
(1)先使用lex和Yacc的編程規則編寫好兩個文件:

圖6 生成詞法和語法解釋器的兩個文件
(2)然後進入兩個文件的所在目錄命令行視窗按順序輸入以下命令:
$env:Path += ";C:\usr\local\wbin"
flex gr1.txt
bison -y -d gr2.txt
(3)最後將生成的兩個.c文件添加到同一項目中運行即可。
詞法文件編碼:

圖7詞法分析
文法文件編碼:

圖8 語法分析
十二、測試
四則運算可以正常執行:

圖9 運算測試
以下為一些極端測試:
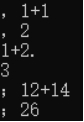
![]()
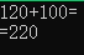

圖10 極端測試
根據以上一些極端測試,可以看出,大部分輸入錯誤該程式都可以進行適當的處理。一些特出錯誤,程式識別不出來的數據,會直接結束運行。對於大數相乘程式會用浮點數的形式給出結果,並不能算出精確值,最大可精確到小數點後5位。所以可以看出功能還是比較局限的。
十三、總結
在這次試驗中我感到lex和Yacc這兩個工具的強大,它們可以幫助我們快速生成非常全面解釋器,使我們的工作轉移到詞法和語法分析上。相信在接下來的學習中我們會對電腦編譯原理有更深層次的理解。
附錄
#include<stdio.h>
#include<ctype.h> //包含isspace函數 ,isalnum()是否字母或數字,isalpha()是否字母
//預處理是以>作為結束,字元是以'作為結束,字元串是以"作為結束,
//數值型常量只能根據當前字元的下一個字元是不是數字判斷是否結束,標識符也是根據下一個字元判斷。所以要記錄下一個字元。
int current_ch, next_ch,k=0;
int flag = 0;
char word[1024];
FILE *fp;
//讀下一個字元
void read_next_char()
{
current_ch = fgetc(fp);
}
//預處理指令:
void get_preprocessing_line()
{
k = 1;
while(1)
{
word[k++]=fgetc(fp);
if(word[k-1] == '>') //碰到>跳出迴圈
{
printf("預處理指令:");
break;
}
}
}
//提取字元型常量:\'
void get_char_const()
{
k = 1;
while(1)
{
word[k++]=fgetc(fp);
if(word[k-1] == '\'') //碰到'跳出迴圈
{
printf("字元型常量:");
break;
}
}
}
//提取字元串常量
void get_string_const()
{
k = 1;
while(1)
{
word[k++]=fgetc(fp);
if(word[k-1] == '\"') //碰到"跳出迴圈
{
printf("字元串常量:");
break;
}
}
}
//提取數值型常量,讀取文本只有整數:
void get_num_const()
{
k = 1;
while(1)
{
word[k++]=fgetc(fp);
if(word[k-1] - '0' < 0 || word[k-1] - '0' > 9) //碰到非數字跳出迴圈 ,要把char型word轉為int型數字
{
next_ch = word[k-1]; //記錄最後的字元
word[k-1] = '\0';
printf("數值型常量:");
break;
}
}
}
//提取標識符:
void get_identifier()
{
k = 1;
while(1)
{
word[k++]=fgetc(fp);
if(!(isalnum(word[k-1]) || word[k-1] == '_')) //碰到非字母或數字或下劃線跳出迴圈
{
next_ch = word[k-1]; //記錄最後的字元
word[k-1] = '\0';
printf("標識符:");
break;
}
}
}
//提取運算符
void get_operator()
{
word[1] = next_ch;
printf("多字元運算符:");
}
//提取分隔符
void get_seperator()
{
printf("分隔符:");
}
//詞法分析部分的基本流程
int lexical_analyzer(FILE * input_file)
{
int i;
int ch;
while(isspace(current_ch)) read_next_char();//碰到空格,當前word結束
while((ch = current_ch) != EOF)
{
word[0] = ch;
if(ch == '#') get_preprocessing_line();//預處理指令:
else if(ch== '\'') get_char_const();//提取字元常量:\'
else if(ch=='"') get_string_const();//提取字元串常量
else if(ch>='0'&&ch<='9') {get_num_const();current_ch = next_ch;flag = 1;}//提取數值型常量:
else if(ch=='_' || isalpha(ch)) {get_identifier();current_ch = next_ch;flag = 1;}//提取標識符下劃線或字母開頭:isalpha()判斷字元變數c是否為字母
else if(ch == (int)'+' || ch == (int)'-' || ch == (int)'*' || ch == (int)'/' || ch == (int)'<' || ch == (int)'>' || ch == (int)'!' || ch == (int)'=') //提取運算符
{
next_ch = fgetc(fp);
if(next_ch != '+' && next_ch != '-' && next_ch != '=') //如果下一個字元不是+-=,那麼是單字元運算符,否則是多字元運算符
{printf("單字元運算符") ;current_ch = next_ch;flag = 1;}
else
{get_operator();}
}
else if(ch == (int)'(' || ch == (int)')' || ch == (int)',' || ch == (int)';' || ch == (int)'{' || ch == (int)'}') get_seperator();//提取分隔符
else { printf("Unknown syntactics:%c(0X%X)\n",ch,ch); return 1; }
printf("%s\n", word);
for(i = 0;i < k;i++) //word置空
{
word[i] = '\0';
}
do{
if(flag==0)
read_next_char();
flag=0;
}while(isspace(current_ch));
}
}
int main()
{
fp = fopen("test.txt","r");
if(fp == NULL)
{
printf("無法找到文件\n");
return 0;
}
current_ch = fgetc(fp);//當前字元
lexical_analyzer(fp);
return 0;
}

