
一般我們對緩存讀操作的時候有這麼一個固定的套路: 如果我們的數據在緩存裡邊有,那麼就直接取緩存的。 如果緩存里沒有我們想要的數據,我們會先去查詢資料庫,然後將資料庫查出來的數據寫到緩存中。 最後將數據返回給請求 代碼例子: 1 @Override 2 public R selectOrderById ...
一般我們對緩存讀操作的時候有這麼一個固定的套路:
- 如果我們的數據在緩存裡邊有,那麼就直接取緩存的。
- 如果緩存里沒有我們想要的數據,我們會先去查詢資料庫,然後將資料庫查出來的數據寫到緩存中。
- 最後將數據返回給請求
代碼例子:
1 @Override 2 public R selectOrderById(Integer id) { 3 //查詢緩存 4 Object redisObj = valueOperations.get(String.valueOf(id)); 5 6 //命中緩存 7 if(redisObj != null) { 8 //正常返回數據 9 return new R().setCode(200).setData(redisObj).setMsg("OK"); 10 } 11 Order order = orderMapper.selectOrderById(id); 12 if (order != null) { 13 valueOperations.set(String.valueOf(id), order); //加入緩存 14 return new R().setCode(200).setData(order).setMsg("OK"); 15 } 16 return new R().setCode(500).setData(new NullValueResultDO()).setMsg("查詢無果"); 17 }
但這樣寫的代碼是不行的,這代碼里就有我們緩存的三大問題的兩大問題.穿透,擊穿.
一,緩存雪崩
1.1什麼是緩存雪崩?
第一種情況:Redis掛掉了,請求全部走資料庫.
第二種情況:緩存數據設置的過期時間是相同的,然後剛好這些數據刪除了,全部失效了,這個時候全部請求會到資料庫
緩存雪崩如果發生了,很有可能會把我們的資料庫搞垮,導致整個伺服器癱瘓.
1.2如何解決緩存雪崩?
對於第二種情況,非常好解決:
在存緩存的時候給過期時間加上一個隨機值,這樣大幅度的減少緩存同時過期.
第一種情況:
事發前:實現Redis的高可用(主從架構+Sentinel 或者Redis Cluster),儘量避免Redis掛掉這種情況發生。
事發中:萬一Redis真的掛了,我們可以設置本地緩存(ehcache)+限流(hystrix),儘量避免我們的資料庫被幹掉(起碼能保證我們的服務還是能正常工作的)
事發後:redis持久化,重啟後自動從磁碟上載入數據,快速恢復緩存數據。
二,緩存穿透
2.1什麼是緩存穿透?
比如你搶了你同事的女神,你同事很氣,想搞你,在你的項目里,每次請求的ID為負數.這個時候緩存肯定是沒有的,緩存就沒用了,請求就會全部找資料庫,但資料庫也沒用這個值.所以每次返回空出去.
緩存穿透是指查詢一個一定不存在的數據。由於緩存不命中,並且出於容錯考慮,如果從資料庫查不到數據則不寫入緩存,這將導致這個不存在的數據每次請求都要到資料庫去查詢,失去了緩存的意義。
這就是緩存穿透:
請求的數據在緩存大量不命中,導致請求走資料庫。
緩存穿透如果發生了,也可能把我們的資料庫搞垮,導致整個服務癱瘓!
2.2如何解決緩存穿透?
解決緩存穿透也有兩種方案:
- 由於請求的參數是不合法的(每次都請求不存在的參數),於是我們可以使用布隆過濾器(BloomFilter)或者壓縮filter提前攔截,不合法就不讓這個請求到資料庫層!
- 當我們從資料庫找不到的時候,我們也將這個空對象設置到緩存裡邊去。下次再請求的時候,就可以從緩存裡邊獲取了。這種情況我們一般會將空對象設置一個較短的過期時間。
緩存空對象代碼例子:
1 public R selectOrderById(Integer id) { 2 return cacheTemplate.redisFindCache(String.valueOf(id), 10, TimeUnit.MINUTES, new CacheLoadble<Order>() { 3 @Override 4 public Order load() { 5 return orderMapper.selectOrderById(id); 6 } 7 },false); 8 }
1 public R redisFindCache(String key, long expire, TimeUnit unit, CacheLoadble<T> cacheLoadble, boolean b) { 2 //查詢緩存 3 Object redisObj = valueOperations.get(String.valueOf(key)); 4 //命中緩存 5 if (redisObj != null) { 6 if(redisObj instanceof NullValueResultDO){ 7 return new R().setCode(500).setData(new NullValueResultDO()).setMsg("查詢無果"); 8 } 9 //正常返回數據 10 return new R().setCode(200).setData(redisObj).setMsg("OK"); 11 } 12 try { 13 T load = cacheLoadble.load();//查詢資料庫 14 if (load != null) { 15 valueOperations.set(key, load, expire, unit); //加入緩存 16 return new R().setCode(200).setData(load).setMsg("OK"); 17 }else{ 18 valueOperations.set(key,new NullValueResultDO(),expire,unit); 19 } 20 21 } finally { 22 23 } 24 return new R().setCode(500).setData(new NullValueResultDO()).setMsg("查詢無果"); 25 }
這裡封裝了一個模板redisFindCache,不然每一個方法都要寫這個流程.註意在命中緩存時,要判斷數據是否是空對象.
空對象:
1 @Getter 2 @Setter 3 @ToString 4 public class NullValueResultDO{ 5 6 }
緩存空對象的缺點:有大量的空數據占用redis的記憶體.治標不治本.
布隆過濾器:
有谷歌的guava,但是是單機版的,不支持分散式.
也可以用redis的位數組bit手寫一個分散式布隆過濾器,代碼就不寫了.過程就是先把id(比如你是用id為key的)存進布隆過濾器(會經過特定的演算法),當我們請求介面的時候先讓它查詢布隆過濾器,判斷數據是否存在.
上面的代碼還有個緩存擊穿(緩存當中沒有,資料庫中有)問題,就是併發的時候.比如99個人同時請求,還是會列印99條sql語句,還是會找資料庫.
這裡的代碼是用的分散式鎖(互斥鎖)
1 public R redisFindCache(String key, long expire, TimeUnit unit, CacheLoadble<T> cacheLoadble,boolean b){ 2 //判斷是否走過濾器 3 if(b){ 4 //先走過濾器 5 boolean bloomExist = bloomFilter.isExist(String.valueOf(key)); 6 if(!bloomExist){ 7 return new R().setCode(600).setData(null).setMsg("查詢無果"); 8 } 9 } 10 //查詢緩存 11 Object redisObj = valueOperations.get(String.valueOf(key)); 12 //命中緩存 13 if(redisObj != null) { 14 //正常返回數據 15 return new R().setCode(200).setData(redisObj).setMsg("OK"); 16 } 17 // RLock lock0 = redisson.getLock("{taibai0}:" + key); 18 // RLock lock1 = redisson.getLock("{taibai1}:" + key); 19 // RLock lock2 = redisson.getLock("{taibai2}:" + key); 20 // RedissonMultiLock lock = new RedissonMultiLock(lock0,lock1, lock2); 21 try { 22 redisLock.lock(key);//上鎖 23 // lock.lock(); 24 //查詢緩存 25 redisObj = valueOperations.get(String.valueOf(key)); 26 //命中緩存 27 if(redisObj != null) { 28 //正常返回數據 29 return new R().setCode(200).setData(redisObj).setMsg("OK"); 30 } 31 T load = cacheLoadble.load();//查詢資料庫 32 if (load != null) { 33 valueOperations.set(key, load,expire, unit); //加入緩存 34 return new R().setCode(200).setData(load).setMsg("OK"); 35 } 36 return new R().setCode(500).setData(new NullValueResultDO()).setMsg("查詢無果"); 37 }finally { 38 redisLock.unlock(key);//解鎖 39 // lock.unlock(); 40 } 41 }
三,緩存與資料庫雙寫一致
3.1什麼是緩存與資料庫雙寫一致問題?
如果僅僅查詢的話,緩存的數據和資料庫的數據是沒問題的。但是,當我們要更新時候呢?各種情況很可能就造成資料庫和緩存的數據不一致了。
- 這裡不一致指的是:資料庫的數據跟緩存的數據不一致
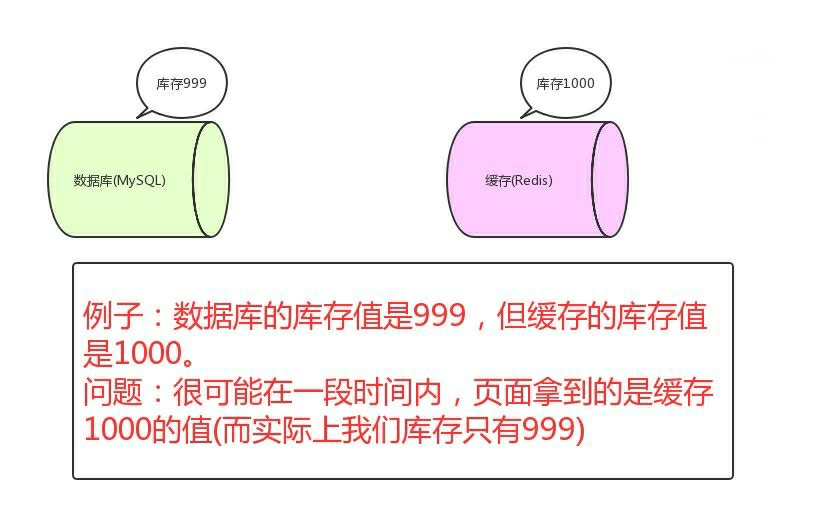
從理論上說,只要我們設置了鍵的過期時間,我們就能保證緩存和資料庫的數據最終是一致的。因為只要緩存數據過期了,就會被刪除。隨後讀的時候,因為緩存里沒有,就可以查資料庫的數據,然後將資料庫查出來的數據寫入到緩存中。
除了設置過期時間,我們還需要做更多的措施來儘量避免資料庫與緩存處於不一致的情況發生。
3.2對於更新操作
一般來說,執行更新操作時,我們會有兩種選擇:
- 先操作資料庫,再操作緩存
- 先操作緩存,再操作資料庫
首先,要明確的是,無論我們選擇哪個,我們都希望這兩個操作要麼同時成功,要麼同時失敗。所以,這會演變成一個分散式事務的問題。
所以,如果原子性被破壞了,可能會有以下的情況:
- 操作資料庫成功了,操作緩存失敗了。
- 操作緩存成功了,操作資料庫失敗了。
如果第一步已經失敗了,我們直接返回Exception出去就好了,第二步根本不會執行。
下麵我們具體來分析一下吧。
3.2.1操作緩存
操作緩存也有兩種方案:
- 更新緩存
- 刪除緩存
一般我們都是採取刪除緩存緩存策略的,原因如下:
- 高併發環境下,無論是先操作資料庫還是後操作資料庫而言,如果加上更新緩存,那就更加容易導致資料庫與緩存數據不一致問題。(刪除緩存直接和簡單很多)
- 如果每次更新了資料庫,都要更新緩存【這裡指的是頻繁更新的場景,這會耗費一定的性能】,倒不如直接刪除掉。等再次讀取時,緩存里沒有,那我到資料庫找,在資料庫找到再寫到緩存裡邊(體現懶載入)
基於這兩點,對於緩存在更新時而言,都是建議執行刪除操作!
3.2.2先更新資料庫,再刪除緩存
正常情況是這樣的:
- 先操作資料庫,成功
- 在刪除緩存,也成功
如果原子性被破壞了:
- 第一步成功(操作資料庫),第二步失敗(刪除緩存),會導致資料庫里是新數據,而緩存里是舊數據。
- 如果第一步(操作資料庫)就失敗了,我們可以直接返回錯誤(Exception),不會出現數據不一致。
如果在高併發的場景下,出現資料庫與緩存數據不一致的概率特別低,也不是沒有:
- 緩存剛好失效
- 線程A查詢資料庫,得一個舊值
- 線程B將新值寫入資料庫
- 線程B刪除緩存
- 線程A將查到的舊值寫入緩存
要達成上述情況,還是說一句概率特別低:
因為這個條件需要發生在讀緩存時緩存失效,而且併發著有一個寫操作。而實際上資料庫的寫操作會比讀操作慢得多,而且還要鎖表,而讀操作必需在寫操作前進入資料庫操作,而又要晚於寫操作更新緩存,所有的這些條件都具備的概率基本並不大。
對於這種策略,其實是一種設計模式:Cache Aside Pattern

刪除緩存失敗的解決思路:
- 將需要刪除的key發送到消息隊列中
- 自己消費消息,獲得需要刪除的key
- 不斷重試刪除操作,直到成功
3.2.3先刪除緩存,在更新資料庫
正常情況是這樣的:
- 先刪除緩存,成功;
- 再更新資料庫,也成功;
如果原子性被破壞了:
- 第一步成功(刪除緩存),第二步失敗(更新資料庫),資料庫和緩存的數據還是一致的。
- 如果第一步(刪除緩存)就失敗了,我們可以直接返回錯誤(Exception),資料庫和緩存的數據還是一致的。
看起來是很美好,但是我們在併發場景下分析一下,就知道還是有問題的了:
- 線程A刪除了緩存
- 線程B查詢,發現緩存已不存在
- 線程B去資料庫查詢得到舊值
- 線程B將舊值寫入緩存
- 線程A將新值寫入資料庫
所以也會導致資料庫和緩存不一致的問題。
併發下解決資料庫與緩存不一致的思路:
- 將刪除緩存、修改資料庫、讀取緩存等的操作積壓到隊列裡邊,實現串列化。
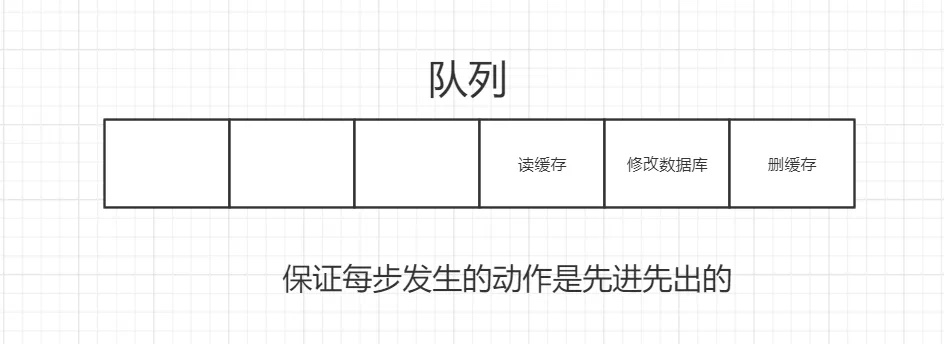
3.2.4對比著兩種策略
我們可以發現,兩種策略各自有優缺點:
- 先刪除緩存,再更新資料庫
在高併發下表現不如意,在原子性被破壞時表現優異
- 先更新資料庫,再刪除緩存(Cache Aside Pattern設計模式)
在高併發下表現優異,在原子性被破壞時表現不如意
3.2.5其他保障數據一致的方案與資料
可以用databus或者阿裡的canal監聽binlog進行更新。
參考資料:
- 緩存更新的套路
https://coolshell.cn/articles/17416.html
- 如何保證緩存與資料庫雙寫時的數據一致性?
https://github.com/doocs/advanced-java/blob/master/docs/high-concurrency/redis-consistence.md
- 分散式之資料庫和緩存雙寫一致性方案解析
https://zhuanlan.zhihu.com/p/48334686
- Cache Aside Pattern
https://blog.csdn.net/z50l2o08e2u4aftor9a/article/details/81008933

