
新建表T: mysql> create table T ( ID int primary key, k int NOT NULL DEFAULT 0, s varchar(16) NOT NULL DEFAULT '', index k(k)) engine=InnoDB; insert into ...
新建表T:
mysql> create table T ( ID int primary key, k int NOT NULL DEFAULT 0, s varchar(16) NOT NULL DEFAULT '', index k(k)) engine=InnoDB; insert into T values(100,1, 'aa'),(200,2,'bb'),(300,3,'cc'),(500,5,'ee'),(600,6,'ff'),(700,7,'gg');
執行語句:
select * from T where k between 3 and 5
執行過程:
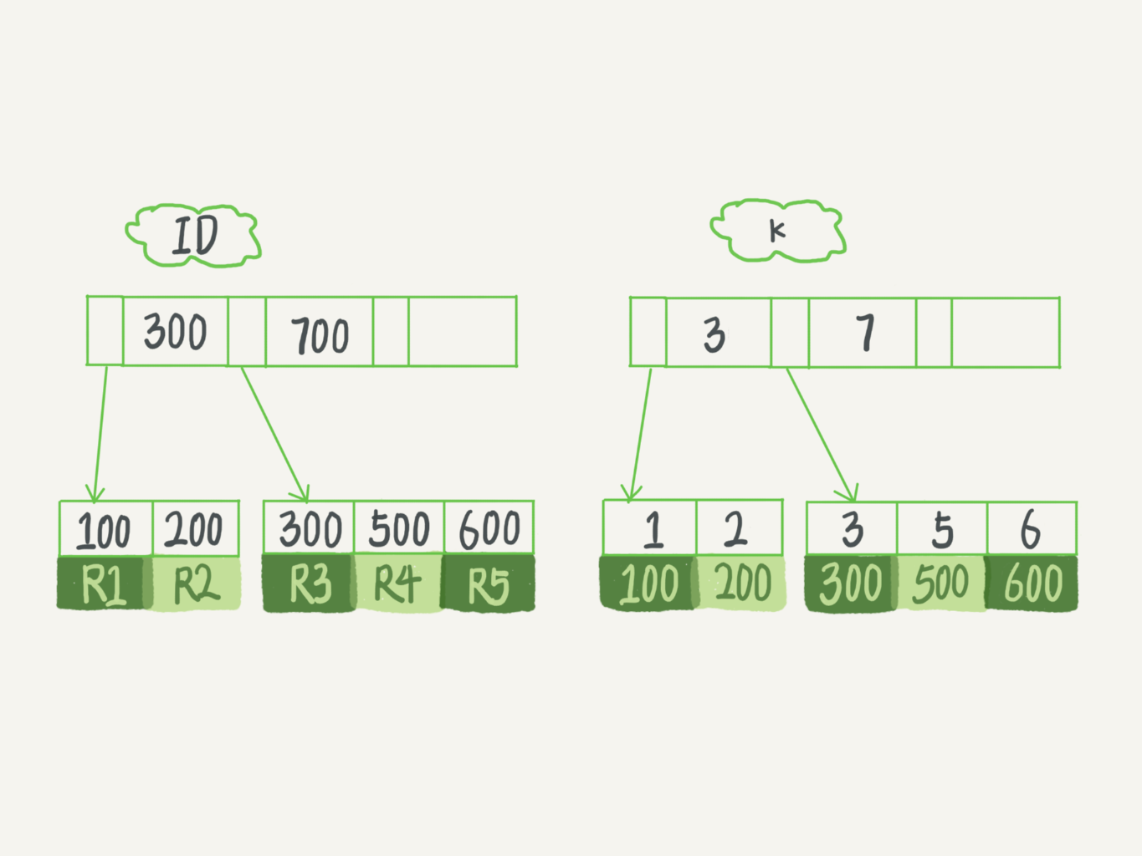
①在 k 索引樹上找到 k=3 的記錄,取得 ID = 300
②再到 ID 索引樹查到 ID=300 對應的 R3
③在 k 索引樹取下一個值 k=5,取得 ID=500
④再回到 ID 索引樹查到 ID=500 對應的 R4
⑤在 k 索引樹取下一個值 k=6,不滿足條件,迴圈結束
在這個過程中,回到主鍵索引樹搜索的過程,稱為回表(此查詢回表兩次,步驟2,4)
優化索引,避免回表:
覆蓋索引:
在這個查詢裡面,索引 k 已經“覆蓋了”我們的查詢需求,我們稱為覆蓋索引。
執行語句:
select ID from T where k between 3 and 5
直接查詢欄位ID的值,而ID的值在k索引的樹上,不需要回表。
最左首碼原則:
不可能為每一個查詢都設置一個索引,但是單獨為一個不頻繁的請求創建一個索引又有點浪費。
B+ 樹這種索引結構,可以利用索引的“最左首碼”,來定位記錄。
可以設置N個欄位
這就需要考慮到一個問題,在建立聯合索引的時候,如何安排索引內的欄位順序?
索引的復用能力:因為已經有(a,b)聯合索引,所以不需要在a上單獨建索引,so第一原則就是:如果可以通過調整順序少維護一個索引,那麼調整順序是需要優先考慮採用的。
空間原則: 如果查詢條件里只有b,同時a欄位比b欄位大,那麼就需要創建一個(a,b)聯合索引和b單欄位索引。
索引下推:
事例語句:
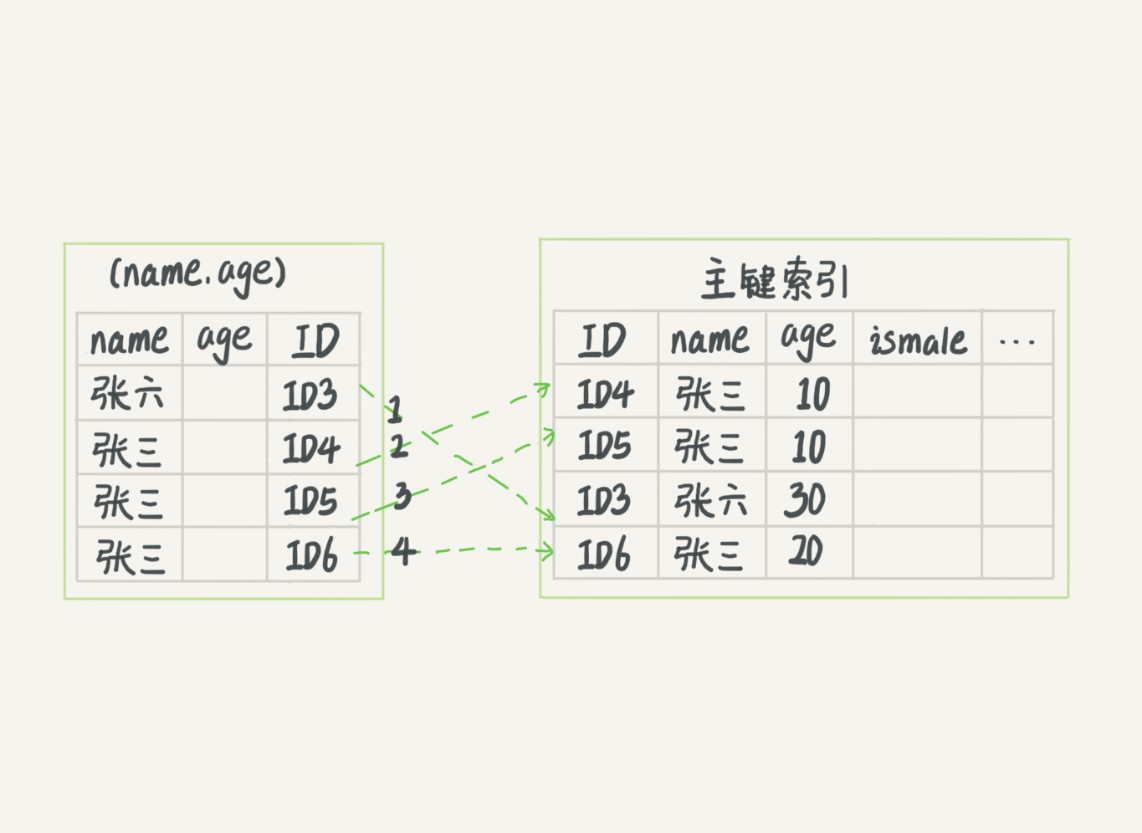
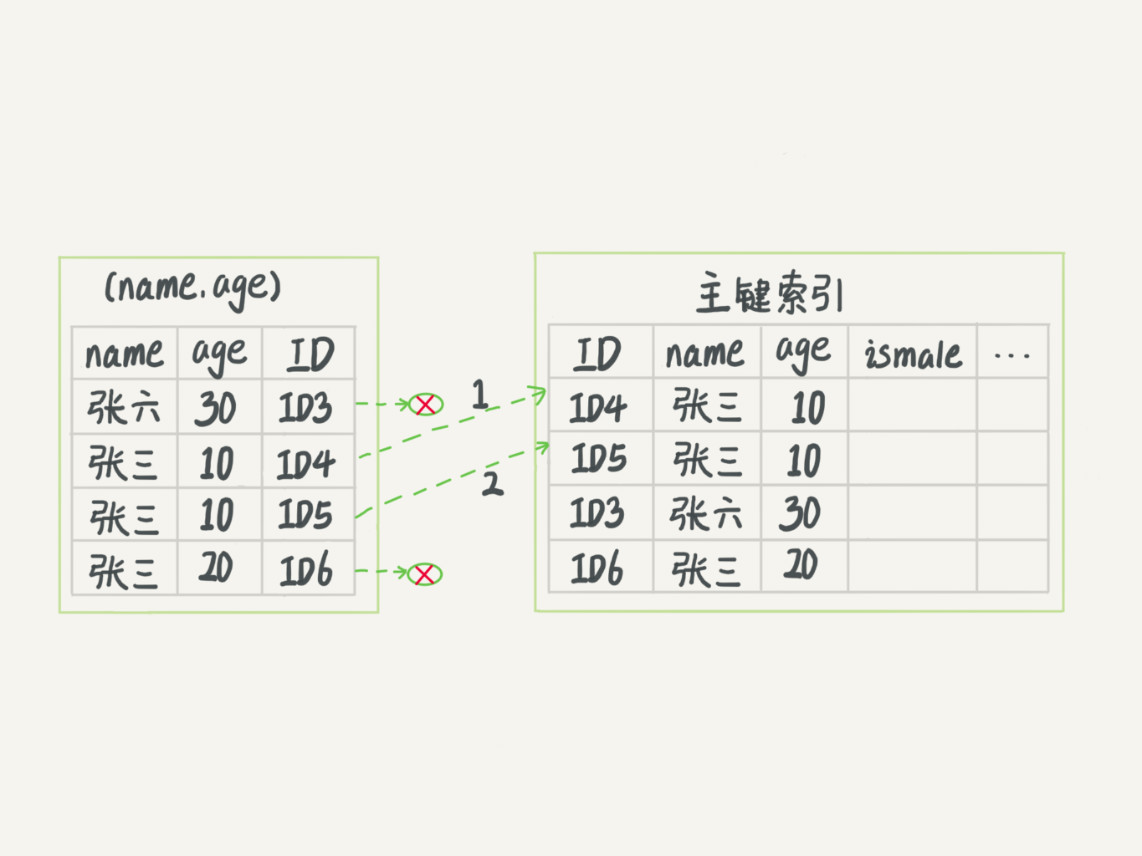
select * from tuser where name like '張%' and age=10 and ismale=1;
以首碼規則來執行(過程):
搜索索引樹--》用 ‘張’ 找到第一個滿足條件的記錄(ID3)--》在MySQL5.6之前(沒有索引下推):從ID3開始一個一個回表,到主鍵索引上找出數據行,對比欄位值
在MySQL5.6之後(優化了索引下推):在索引遍歷的過程中對包含的欄位做優先判斷,過濾掉不符合要求的值,減少回表次數
【虛線代表回表次數】
沒有索引下推: 索引下推:
【個人理解】
索引越多,維護成本越大
覆蓋索引:查詢結果是索引欄位或主鍵
優--不用回表操作
最左首碼:聯合索引最左邊的N個欄位或字元串索引的最左N個欄位
優--減少索引數量,降低維護成本
聯合索引:兩個欄位創建的索引,例如:(a,b)查詢a或a,b時使用索引,單查b不會使用索引
索引下推:先過濾掉不符合條件的數據再進行回表查詢

