
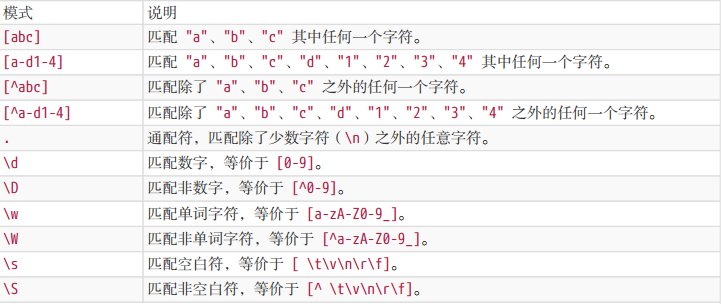
前言 此內容由學習《JavaScript正則表達式迷你書(1.1版)》整理而來(於2020年3月30日看完)。此外還參考了MDN上關於Regex和String的相關內容,還有ECMAScript 6中關於正則的擴展內容,但不多。在文章末尾,會放上所有的鏈接。 迷你書共七章,我都做了相應的標號。不過我 ...
前言
此內容由學習《JavaScript正則表達式迷你書(1.1版)》整理而來(於2020年3月30日看完)。此外還參考了MDN上關於Regex和String的相關內容,還有ECMAScript 6中關於正則的擴展內容,但不多。在文章末尾,會放上所有的鏈接。
迷你書共七章,我都做了相應的標號。不過我將【7】7種方法放在了前面,討論了具體情境下怎麼正確使用函數的問題(其實是我自己一直被這個問題困擾,書上的例子為什麼用這個方法,為什麼這個方法這裡返回這樣,那裡卻不是這樣,把我搞崩潰了),也建議大家先搞懂這個吧。
本文重點
-
正則的 2 種創建
-
正則的 6 個修飾符(i、g、m、u、y、s)
-
【7】.用到正則的 7 種方法(RegExp(exec、test),String(search、match、matchAll、replace、split))
-
正則表達式中的6種結構(字元字面量、字元組、量詞、錨、分組、分支)
-
【1】.字元匹配:字面量、字元組、量詞。重點還有貪婪匹配與惰性匹配
-
【2】.位置匹配:^ 、$ 、 \b 、\B 、(?=abc) 、 (?!abc) 的使用
-
【3】.括弧的作用:分組和分支結構。知識點有:分組引用($1的使用)、反向引用(\1的使用)、括弧嵌套、括弧結合量詞
-
-
【4】
.回溯原理(本文大多介紹的是實踐中用的基礎知識,後期對此可能會單獨寫篇,先占個坑) -
【5】.正則的拆分:重點是操作符的優先順序
-
【6】.
正則表達式的構建(本章寫了些提高正則準確性和效率的內容,也先占個坑) -
簡單實用的正則測試器
2種創建
語法:/pattern/flags
var regexp = /\w+/g;
var regexp = new RegExp('\\w+','g');
6個修飾符

重點介紹全局與非全局:
全局就是說在字元串中查找所有與正則式匹配的內容,因此會有>=1個結果。
而為了得到這個所謂的所有匹配內容的過程,後面介紹的函數還有一次執行和多次執行之別。
如果正則表達式中存在分組,該模式下各個函數返回的結果也不一樣。
非全局就簡單了,它表示匹配到了一個就不會再繼續往後匹配了,因此都是一次就得結果。
7種方法
以下圖在我學習的過程中,修改了很多遍,才得出了這個最簡潔明瞭的版本。


【補充1】全局模式對 exec 和 test 的影響
正則實例有個 lastIndex 屬性,表示嘗試匹配時,從字元串的 lastIndex 位開始去匹配。
全局匹配下,字元串的四個方法,每次匹配時,都是從 0 開始的,即 lastIndex 屬性始終不變。
而正則實例的兩個方法 exec、test,當正則是全局匹配時,每一次匹配完成後,都會修改 lastIndex。(詳見下麵示例)
如果是非全局匹配,自然都是從字元串第 0 個字元處開始嘗試匹配:
exec()在全局狀態下,需要一次次執行直到末尾才能得到所有匹配項,這裡只是手動模擬下。當然最好是用迴圈實現,while ((match = regexp.exec(str)) !== null) {//輸出}
var regexp = /a/g;
console.log( regexp.exec("a"), regexp.lastIndex );// [ 'a', index: 0, input: 'a', groups: undefined ] 1
console.log( regexp.exec("aba"), regexp.lastIndex );// [ 'a', index: 2, input: 'aba', groups: undefined ] 3
console.log( regexp.exec("ababc"), regexp.lastIndex );// null 0
註意:該部分將的所有正則表達式不知道的都先不要急,慢慢來。
【補充2】全局下match、exec、matchAll示例
match()和exec()示例:
//全局模式下,匹配所有能匹配到的
var regexp1 = /t(e)(st(\d?))/g;
var str1 = 'test1test2';
console.log(str1.match(regexp1)); //match返回所有匹配項組成的數組[ 'test1', 'test2' ]
console.log(regexp1.exec(str1))// exec第一次執行返回第一個匹配項和它的分組['test1', 'e','st1','1',index:0,input:'test1test2',groups:undefined]
console.log(regexp1.exec(str1))//exec第二次執行返回第二個匹配項和它的分組['test2', 'e','st2','2',index:5,input:'test1test2',groups:undefined]
console.log(regexp1.exec(str1))//exec第二次執行已經到末尾了,因此第三次結果為null
//非全局模式下,只匹配到第一項就停止
var regexp2 = /t(e)(st(\d?))/;
var str2 = 'test1test2';
console.log(str2.match(regexp2)); //match['test1', 'e','st1','1',index:0,input:'test1test2',groups:undefined]
console.log(regexp2.exec(str2)) //exec['test1', 'e','st1','1',index:0,input:'test1test2',groups:undefined]
matchAll()示例:
matchAll()是es6的用法,記住它返回的就是一個迭代器。可以用for...of迴圈取出,也可以用...迭代器運算符或者Array.from(迭代器)將它轉為數組。
var array1 = [...str1.matchAll(regexp1)];
console.log(array1)
//['test1','e','st1','1',index: 0,input: 'test1test2',groups: undefined]
//['test2','e','st2','2',index: 5,input: 'test1test2',groups: undefined]
var array2 = [...str2.matchAll(regexp2)];
console.log(array2)
//['test1','e','st1','1',index: 0,input: 'test1test2',groups: undefined]

到目前為止,我們應該積攢了很多問號了。我學的過程中有以下兩個問題:
1./t(e)(st(\d?))/g和/t(e)(st(\d?))/的區別我知道了,但t(e)(st(\d?))這是什麼意思呢?
2.上文所謂的“與正則表達式匹配的內容”和“匹配項中分組捕獲的內容”怎麼理解?
那就帶著問題看後面的內容吧。
7種結構 -字元匹配
字面量

字元組
需要強調的是,雖叫字元組(字元類),但只是其中一個字元。
如果字元組裡的字元特別多,可用連字元 - 來省略和簡寫(見表格示例)。
示例:全局匹配,使用match()方法返回字元串中與表達式匹配的所有內容。[123]表示這個位置的字元可以是1、2、3中的任意一個

量詞
有了一個字元,那我我們就會考慮到需要它出現幾次,那麼量詞來了。
示例:全局匹配,使用match()方法返回字元串中與表達式匹配的所有內容。b{2,5}表示字元b出現2到5次。


貪婪匹配與惰性匹配

貪婪匹配/\d{2,5}/ 表示數字連續出現 2 到 5 次,會儘可能多的匹配。你如果有 6 個連續的數字,那我就要我的上限 5 個;你如果只有 3 個連續數字,那我就要3個。想要我只取 2 個,除非你只有兩個。
惰性匹配/\d{2,5}?/ 表示雖然 2 到 5 次都行,當 2 個就夠的時候,我也不貪,我就取兩個。
對惰性匹配的記憶方式是:量詞後面加個問號,問一問你知足了嗎,你很貪婪嗎?註意是 量詞後面 量詞後面 量詞後面,重要的事說三遍。還是來個例子吧,?與??:
'testtest1test2'.match(/t(e)(st(\d?))/g)的結果就是[ 'test', 'test1', 'test2' ]
'testtest1test2'.match(/t(e)(st(\d??))/g)的結果就是[ 'test', 'test', 'test' ]
7種結構 -位置匹配
位置理解
位置特性
1.對於位置的理解,我們可以理解成空字元 ""。
因此,把 /^hello$/ 寫成 /^^hello$$$/,是沒有任何問題的。甚至 /(?=he)^^he(?=\w)llo$\b\b$/;
2.整體匹配時,自然就需要使用 ^ 和 $

7種結構 - 括弧的作用
分組和分支結構
到目前為止,我們對於 match(/t(e)(st(\d?))/g)應該完全理解了(包括 match()的使用,全局修飾符g,表示字元組的\d和表示量詞的?,且也知道了這是貪婪匹配)。那麼,裡面的括弧又表示什麼意思呢?這就涉及到分組捕獲了。
以日期為例,假設要匹配的格式是 yyyy-mm-dd 的:
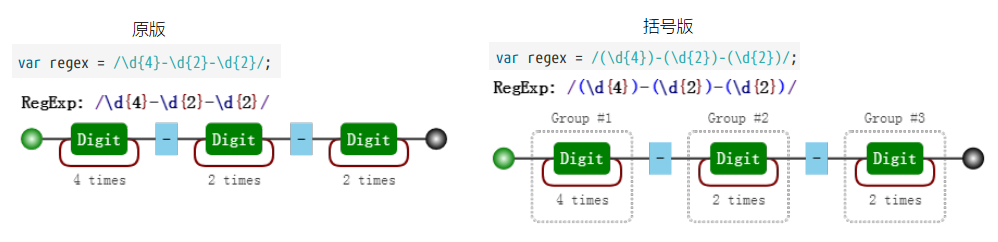
對比這兩個可視化圖片,我們發現,與前者相比,後者多了分組編號,如 Group #1,這樣正則就能在匹配表達式的同時,還能得到我們想要從匹配項中捕獲的分組內容。即用 () 括起來的內容。到此為止,t(e)(st(\d?))涉及到的分組捕獲知識點也就結束了。
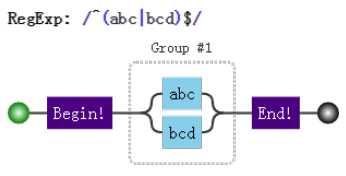
再介紹下分支結構,由於操作符 | 的優先順序最低,因此需要將其放於括弧中:
分支結構形如(regex1|regex2),字面意思,即這裡可以匹配 regex1或者 regex2之一,捕獲分組的時候也是二者之一 ,例子:
引用分組
使用相應 API 來引用分組。
提取數據

替換replace

當第二個參數是字元串時,如下的字元有特殊的含義。其中,第二個是 $&:

反向引用分組
除了使用相應 API 來引用分組,也可以在正則本身里引用分組。但只能引用之前出現的分組,即反向引用。
以前面的日期為例,假設我們想要求分割符前後一致怎麼辦?即杜絕 2016-06/12這樣中間分割符不一致的情況,此時需要使用反向引用:
註意裡面的 \1,表示的引用之前的那個分組 (-|\/|\.)。不管它匹配到什麼(比如 -),\1 都匹配那個同樣的具體某個字元。
我們知道了 \1 的含義後,那麼 \2 和 \3 的概念也就理解了,即分別指代第二個和第三個分組。需要註意:
-
\10表示第十個分組,如果真要匹配\1和0的話,使用(?:\1)0或者\1(?:0)。 -
反向引用引用不存在的分組時候,匹配
反向引用的字元本身。例如\2,就匹配"\2"。

分組括弧嵌套
針對 "1231231233".match(/^((\d)(\d(\d)))\1\2\3\4$/) 的可視化形式如下,一目瞭然:
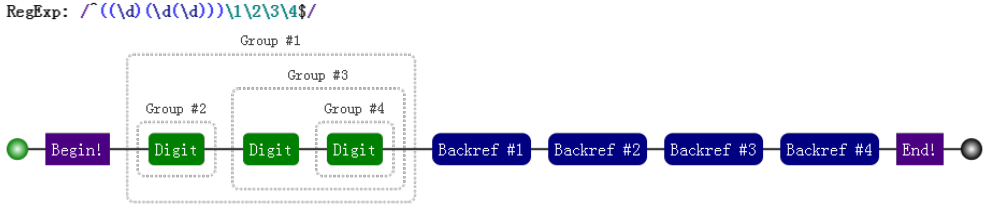
分組括弧結合量詞
分組後面有量詞的話,分組最終捕獲到的數據是最後一次的匹配。分組引用與反向引用都是這樣例子:

非捕獲括弧
如果只想要括弧最原始的功能,但不會引用它,即,既不在 API 里引用,也不在正則里反向引用。
可以使用非捕獲括弧 (?:p) 和 (?:p1|p2|p3),如下代碼,執行matchAll(),雖然有括弧,但不會得到捕獲的分組內容。

正則的拆分
不僅要求自己能解決問題,還要看懂別人的解決方案。代碼是這樣,正則表達式也是這樣。如何能正確地把一大串正則拆分成一塊一塊的,成為了破解“天書”的關鍵。
這裡,我們來分析一個正則 /ab?(c|de*)+|fg/:

思考下:
/^abc|bcd$/和/^(abc|bcd)$/。
/^[abc]{3}+$/和/^([abc]{3})+$/
操作符優先順序

操作符轉義
所有操作符都需要轉義
^、$、.、*、+、?、|、\、/、(、)、[、]、{、}、=、!、:、- ,

到這裡,對正則表達式也算是入了個小門了,即對正則的一些基本操作也有了瞭解,也能看懂別人的正則表達式,就算是copy也能靈活的改動了。
簡單實用的正則測試器
效果圖:
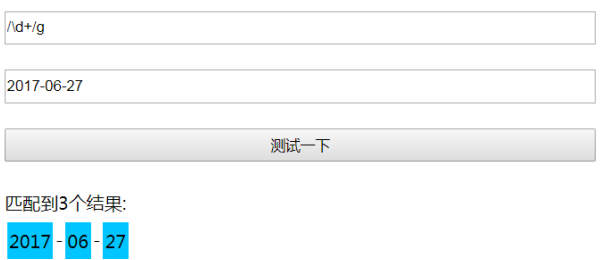
源代碼:git
相關鏈接
老姚 《JavaScript 正則表達式迷你書》下載
阮一峰《ECMAScript 6 入門 - 正則的擴展》
MDN RegExp.prototype.exec()
MDN RegExp.prototype.test()
MDN String.prototype.search()
MDN String.prototype.match()
MDN String.prototype.matchAll()
MDN String.prototype.replace()
MDN String.prototype.split()

