
筆者最近遇到一則典型的因為sql中存在派生表造成的性能案例,通過改寫SQL改善了的性能,但當時並沒有弄清楚這其中的原因,派生表究竟是什麼原因會導致性能上的副作用。說來也巧,很快就無意中就看到下文中的提到的相關的派生表的介紹以及其特性之後,才發現個中緣由,本文基於此,用一個非常簡單的demo來演示該問 ...
筆者最近遇到一則典型的因為sql中存在派生表造成的性能案例,通過改寫SQL改善了的性能,但當時並沒有弄清楚這其中的原因,派生表究竟是什麼原因會導致性能上的副作用。
說來也巧,很快就無意中就看到下文中的提到的相關的派生表的介紹以及其特性之後,才發現個中緣由,本文基於此,用一個非常簡單的demo來演示該問題,同時警惕MySQL中派生表的使用。
什麼是派生表
關於派生表的定義,不贅述了,以下截圖來自於愛可生公司的公眾號中,說的非常清晰,連接地址為:https://mp.weixin.qq.com/s/CxagKla3Z6Q6RJ-x5kuUAA,侵刪,謝謝。
這裡我們主要關註它在與父查詢join時的一些限制,如果派生表中存在distinct,group by union /union all,having,關聯子查詢,limit offset等,也即父查詢的參數無法傳遞到派生表的查詢中,導致一些性能上的問題。
測試場景
假設是在MySQL的關係數據中,試想有這個一個查詢:一個訂單表以及對應的物流信息表,關係為1:N,查詢訂單和其最新的1條物流信息,這個查詢該怎麼寫(假設問題存在而不論證其是否合理)?
相信實現起來並不複雜,如果是查看單條訂單的物流信息,兩張表join 起來,按照時間倒序取第一條即可,如果要查詢多條訂單的信息,或者是某一段時間內所有的訂單的該信息呢?
如果是是商業資料庫或者是MySQL 8.0中有現成的分析函數可以用,如果是MySQL 5.7,沒有現成的分析函數,該怎麼寫呢?
簡單demo一下,說明問題即可:加入t1表示訂單表,t2表示物流信息表,c1為訂單號(關聯鍵),t1和t2中的數據為1對多。
CREATE TABLE t1 ( id INT AUTO_INCREMENT PRIMARY key, c1 INT, c2 VARCHAR(50), create_date datetime ); CREATE TABLE t2 ( id INT AUTO_INCREMENT PRIMARY key, c1 INT, c2 VARCHAR(50), create_date datetime ); CREATE INDEX idx_c1 ON t1(c1); CREATE INDEX idx_c1 ON t2(c1);
按照1:10的比例往兩張表中寫入測試數據,也就是說一條訂單存在10條物流信息,其訂單的物流信息的創建時間隨機分佈在一定的時間範圍。測試數據在百萬級就夠了。
CREATE DEFINER=`root`@`%` PROCEDURE `create_test_data`( IN `loop_count` INT ) BEGIN SET @p_loop = 0; while @p_loop<loop_count do SET @p_date = DATE_ADD(NOW(),INTERVAL -RAND()*100 DAY); INSERT INTO t1 (c1,c2,create_date) VALUES (@p_loop,UUID(),@p_date); INSERT INTO t2 (c1,c2,create_date) VALUES (@p_loop,UUID(),DATE_ADD(@p_date,INTERVAL RAND()*10000 MINUTE)); INSERT INTO t2 (c1,c2,create_date) VALUES (@p_loop,UUID(),DATE_ADD(@p_date,INTERVAL RAND()*10000 MINUTE)); INSERT INTO t2 (c1,c2,create_date) VALUES (@p_loop,UUID(),DATE_ADD(@p_date,INTERVAL RAND()*10000 MINUTE)); INSERT INTO t2 (c1,c2,create_date) VALUES (@p_loop,UUID(),DATE_ADD(@p_date,INTERVAL RAND()*10000 MINUTE)); INSERT INTO t2 (c1,c2,create_date) VALUES (@p_loop,UUID(),DATE_ADD(@p_date,INTERVAL RAND()*10000 MINUTE)); INSERT INTO t2 (c1,c2,create_date) VALUES (@p_loop,UUID(),DATE_ADD(@p_date,INTERVAL RAND()*10000 MINUTE)); INSERT INTO t2 (c1,c2,create_date) VALUES (@p_loop,UUID(),DATE_ADD(@p_date,INTERVAL RAND()*10000 MINUTE)); INSERT INTO t2 (c1,c2,create_date) VALUES (@p_loop,UUID(),DATE_ADD(@p_date,INTERVAL RAND()*10000 MINUTE)); INSERT INTO t2 (c1,c2,create_date) VALUES (@p_loop,UUID(),DATE_ADD(@p_date,INTERVAL RAND()*10000 MINUTE)); INSERT INTO t2 (c1,c2,create_date) VALUES (@p_loop,UUID(),DATE_ADD(@p_date,INTERVAL RAND()*10000 MINUTE)); SET @p_loop = @p_loop+1; END while; END
這是典型的一條數據示例(訂單和其物流信息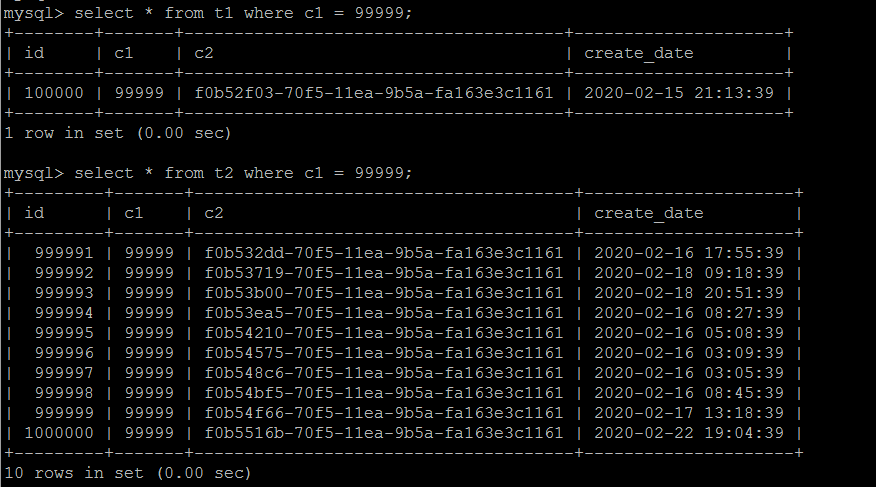
派生表的性能問題
按照最通用的寫法,就是實現一個類似於商業資料庫中的row_number()功能,按照訂單號分組,然後求給每個訂單號的物流信息排序,最後取第一條物流信息即可。
為了簡單起見,這個SQL只查詢一個訂單的最新的物流信息。
於是就這麼寫了一個語句,其中通過一個派生表,用到了典型的row_number()分析函數等價實現,這個語句執行起來邏輯上當然沒有什麼問題,結果也完全符合預期,但是執行時間會接近3秒鐘,這個是遠遠超出過預期的。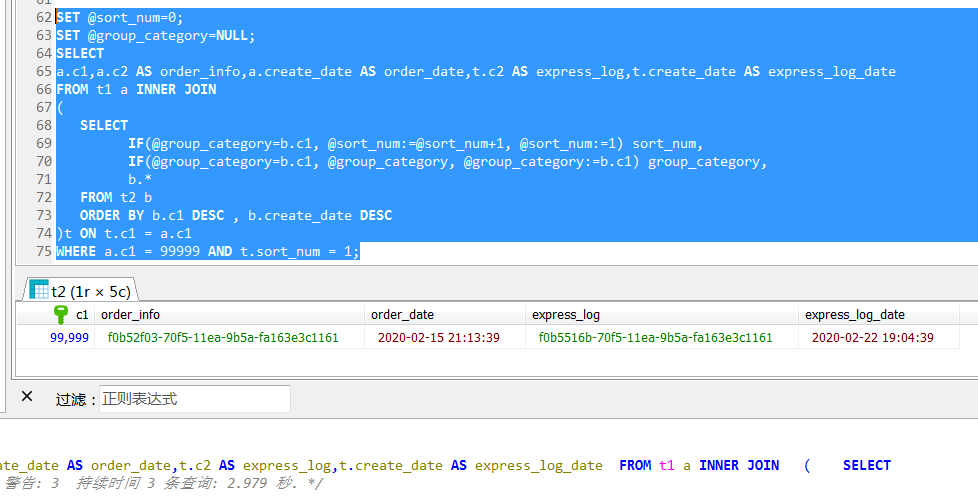
這裡插一句:很多人包括面試都會問,SQL優化有哪些技巧?
不排除一部分人的言外之意就是要你列舉出來一些”固定的套路”,比如where條件怎麼樣了,索引怎麼建了,什麼亂七八糟的,列舉出來一大堆,這麼多年過去了,這中套路式的列舉依然是我最最最討厭的套路。
實際情況千變萬化,固定的套路可能會好使,但是更多的時候,需要根據是情況做具體分析,而不是死套套路,如果真的有一個(系列)規則可以套,那麼執行計劃是不是又回到最原始的RBO模式了?
面對一個需要優化的SQL,弄清楚這個sql的邏輯之後:先不管它實際上是怎麼執行的,首先自己心中要有一個執行計劃,要有一個預期的執行方式,理論上是相對較好的一種執行方式(計劃)。
1,如果按照預期的方式執行,但是性能並沒有達到預期,需要反思是什麼因素造成的?
2,如果沒有按照預期的方式執行,同樣需要反思了,為什麼沒有按照預期的方式執行,可能會是什麼原因造成的?
對於這個SQL,我個人傾向於先通過派生表對子表做一個清晰的排序實現,然後父查詢進行過濾(篩選最新的一條數據),
我個人臆測的執行計劃如下:
因為join條件是t.c1 = a.c1,where條件是a.c1 = 99999,按道理來說,是比較清晰的邏輯,既然a.c1 = 99999又t.c1 = a.c1,這個篩選條件會直接推進到子查詢(派生表內部),篩選一下就完事了
這個性能錶面,實際的執行計劃很可能不是這麼走的,其實卻是出乎意料的。
可以看到,派生表內部是一個全表掃描,也就是說跟t2做做一個全表掃描,然後對每個訂單的物流信息排序,然後再根據外層的查詢進行訂單號的篩選(where a.c1 = 99999)
這個可以說是完全出乎意料的,一開始並不知道外層的查詢條件,是無法能推進到派生表內部來做過濾的。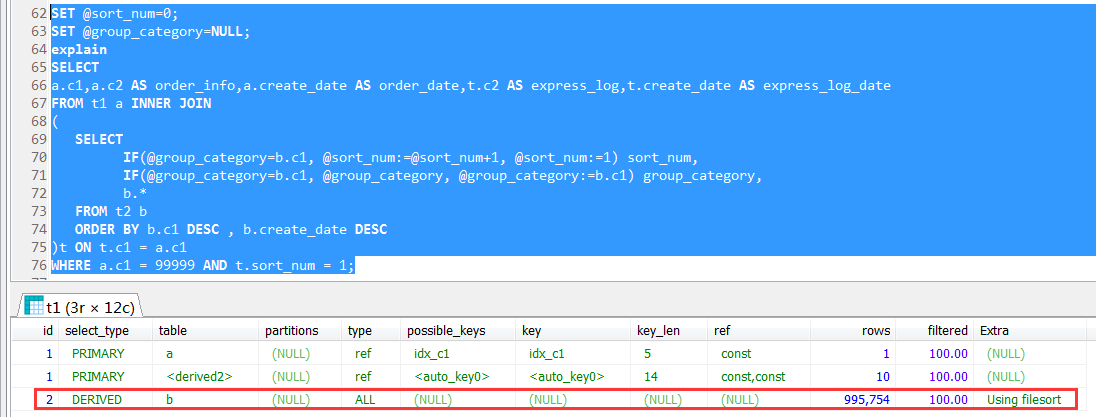
這裡涉及到一個derived_merge相關的實現,
指的是一種查詢優化技術,作用就是把派生表合併到外部的查詢中,提高數據檢索的效率。這個特性在MySQL5.7版本中被引入(參考https://blog.csdn.net/sun_ashe/article/details/89522394)。
舉一個實際的例子,比如對於select * from (select * from table_name)t where id= 100;
用土話說就是,外層查詢的條件會推進到派生表的子查詢中,實際的執行過程就變為:select * from (select * from table_name where id =100)t where id= 100,
在商業資料庫中,這一切都是非常的自然的一個過程,在MySQL中是不一定的,所以不得不承認MySQL的優化器太弱了。
基於此重新改寫了一下SQL,如下,主表和子表先join起來,同時對子表進行排序,然後再外層篩選最新的一條信息(t.sort_num = 1),
改寫之後,這個查詢只需要0.125秒,大概有20倍+的提升,這是沒有任何外界條件的變化的情況下。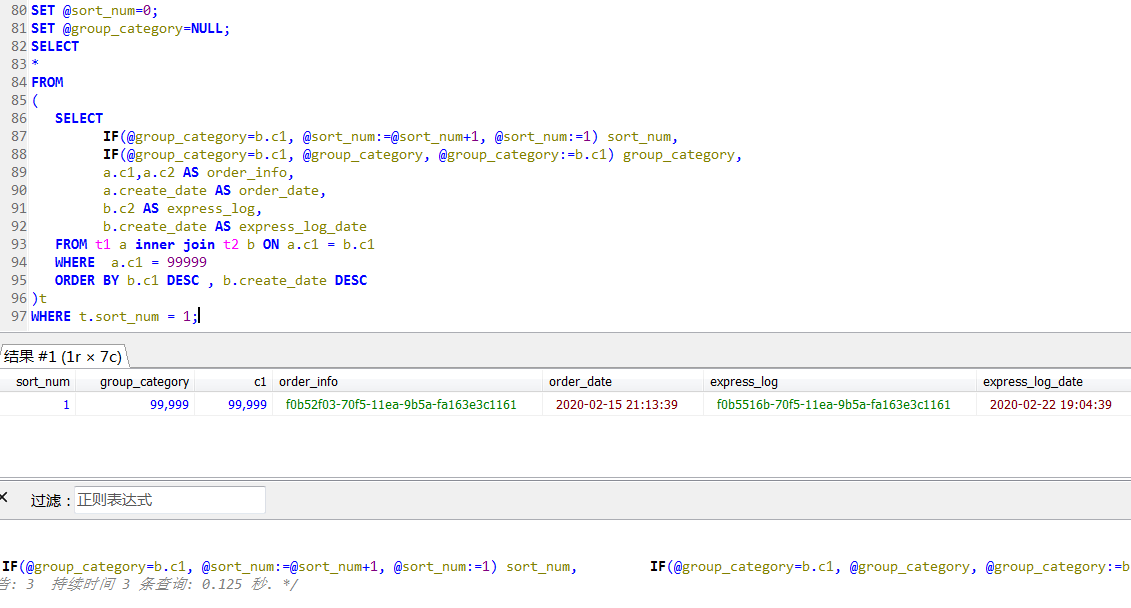
其實這個執行計劃,才是上面提到的“預期的”執行計劃,篩選條件同時應用到了兩張表中,進過篩選之後再做邏輯上的排序計算。
至於為什麼第一次沒有用到這些寫法,其實寫SQL每個人都有自己的習慣,個人的思路就是首先可以做到不牽涉任何join的時候,先對目標對象進行排序計算等等,完成份內的事之後,然後再join主表取數據。
個人認為這是一種寫法的邏輯看上去更加清晰易懂,尤其是在較多的表join的時候,每一步先完成自己份內的事,然後再跟其他表join(當然這也是一個見仁見智的問題,個人思路都可能不一樣,這裡有點跑偏了)
如果上上述第一種寫法,在SqlServer或者其他關係資料庫中,是完全等價於第二種寫法的,所以一開始是沒有預料到這種巨大的性能差異的。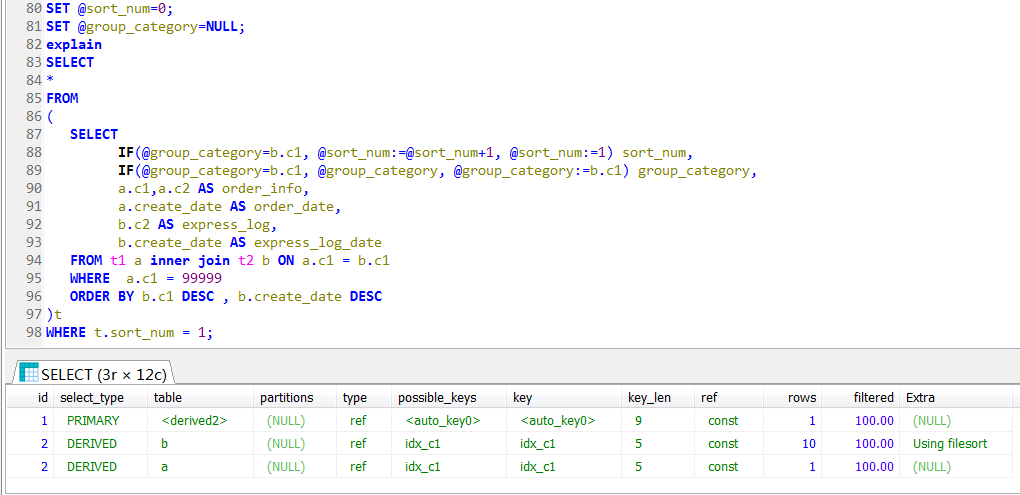
其實這裡就可以不回歸到本文一開始提到的派生表的限制了,這個截圖來自於這裡:https://blog.csdn.net/sun_ashe/article/details/89522394,侵刪。
任何走到continue中的邏輯,都是無法實現外層查詢篩選條件推進到派生表的子查詢的。
也就是說派生表中存在distinct,group by union /union all,having,關聯子查詢,limit offset,變數等情況下,無法進行derived_merge。
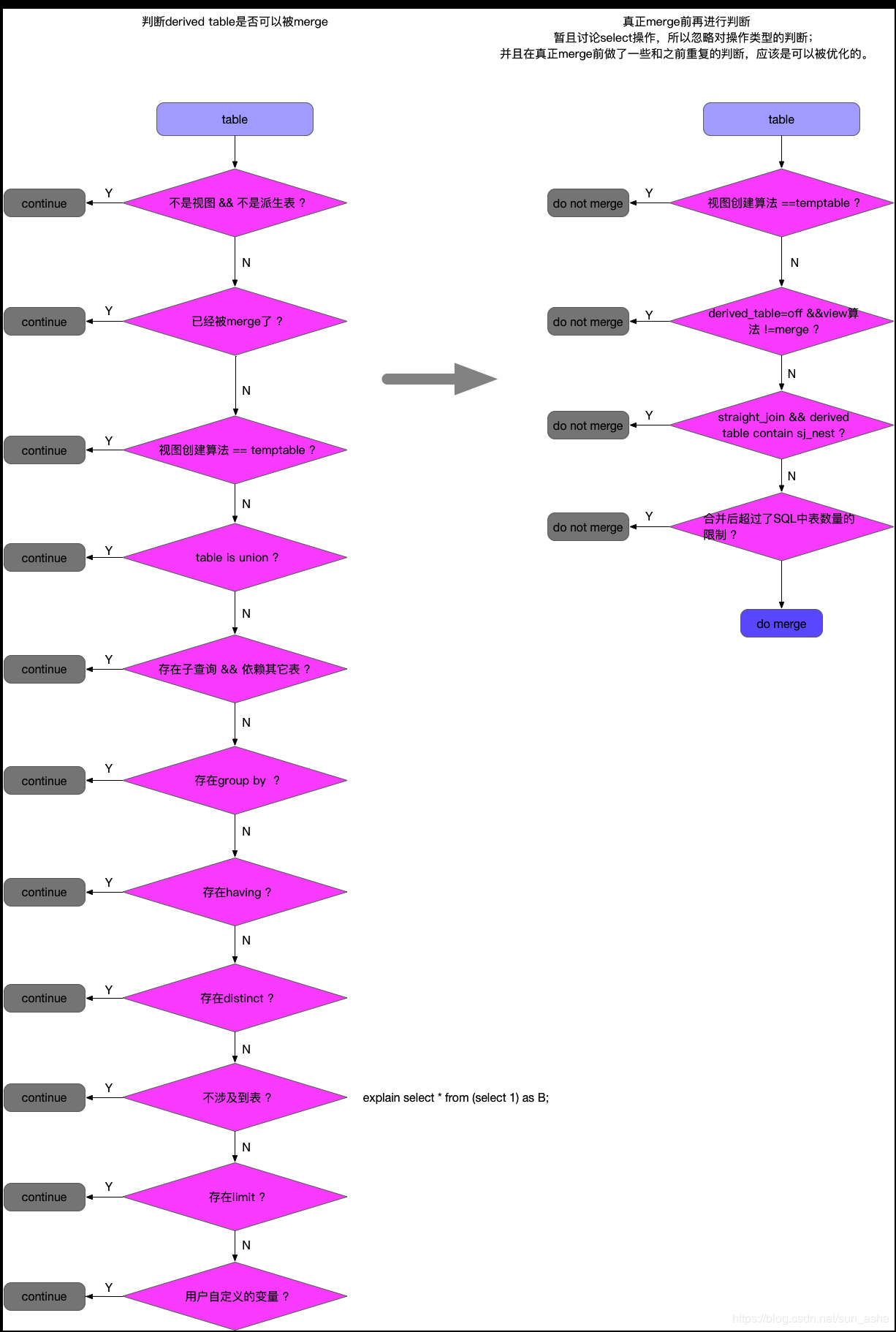
可以認為,任何一個走向continue的分支的情況,都是無法使用derived_merge的。
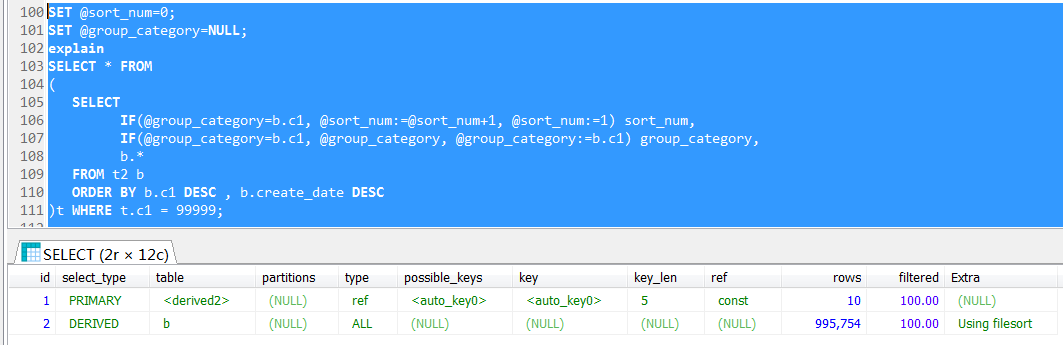
其實本文中的示例SQL繼續簡化一下,就非常明顯了,這裡不去join任何表,僅對t2表做一個分析查詢,然後刻意基於派生表實現篩選,其執行計劃並不是理想中的索引查找
也就是說,select * from (select * from table_name)t where id= 100在某些條件下是無法轉換為select * from (select * from table_name where id =100)t where id= 100的,外層查詢條件無法推進到內層查詢中。
上文中的查詢,與join的參與並無關係,其實就派生表中有用戶變數造成的,這裡看到執行計划走的是一個全表掃描
如果不使用派生表的方式,其執行計劃就是索引查找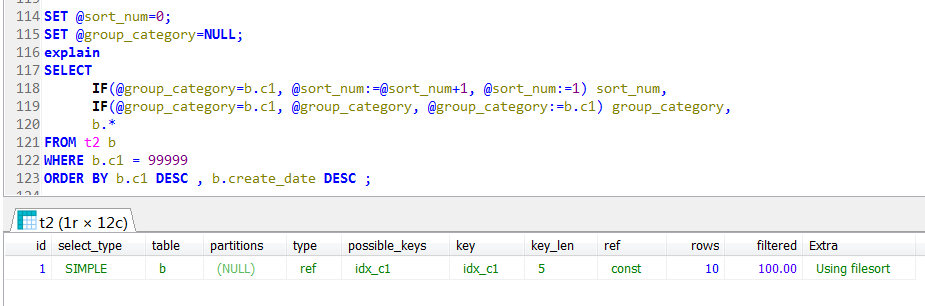
MySQL 8.0的分析函數
其實之前的寫法都是為了實現row_number這個分析函數的功能,如果直接採用MySQL 8.0分析函數,SQL會極大地地得到簡化,性能也會飛起來。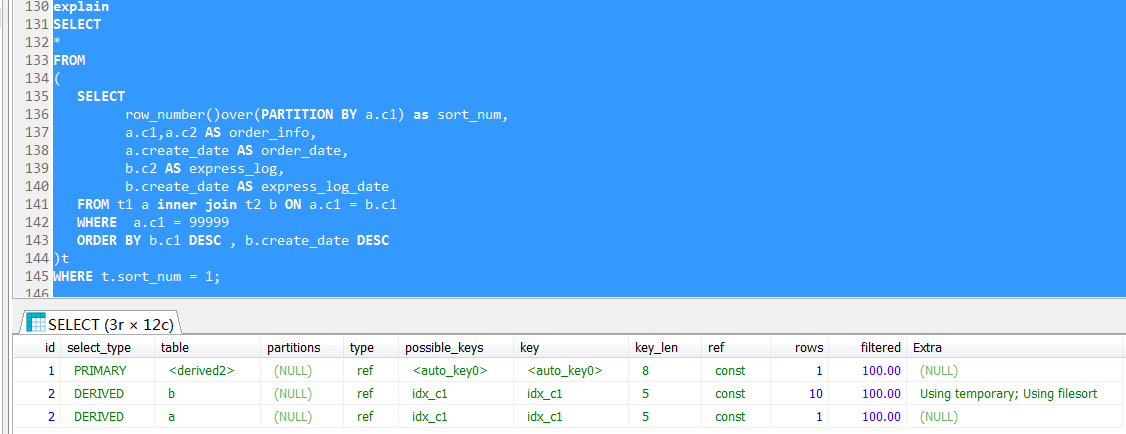
總結
以上通過一個簡單的案例,來說了了derived_merge的限制,可能這些在其他資料庫上不是問題的問題,在MySQL上都是問題,實際上MySQL優化器還是需要提升的。
如果一旦有類似派生表的情況,可能會遇到有性能問題,還是需要值得註意的。
demo的sql
SET @sort_num=0; SET @group_category=NULL; SELECT a.c1,a.c2 AS order_info,a.create_date AS order_date,t.c2 AS express_log,t.create_date AS express_log_date FROM t1 a INNER JOIN ( SELECT IF(@group_category=b.c1, @sort_num:=@sort_num+1, @sort_num:=1) sort_num, IF(@group_category=b.c1, @group_category, @group_category:=b.c1) group_category, b.* FROM t2 b ORDER BY b.c1 DESC , b.create_date DESC )t ON t.c1 = a.c1 WHERE a.c1 = 99999 AND t.sort_num = 1; SET @sort_num=0; SET @group_category=NULL; SELECT * FROM ( SELECT IF(@group_category=b.c1, @sort_num:=@sort_num+1, @sort_num:=1) sort_num, IF(@group_category=b.c1, @group_category, @group_category:=b.c1) group_category, a.c1,a.c2 AS order_info, a.create_date AS order_date, b.c2 AS express_log, b.create_date AS express_log_date FROM t1 a inner join t2 b ON a.c1 = b.c1 WHERE a.c1 = 99999 ORDER BY b.c1 DESC , b.create_date DESC )t WHERE t.sort_num = 1; SELECT * FROM ( SELECT row_number()over(PARTITION BY a.c1 ORDER BY b.create_date desc) as sort_num, a.c1, a.c2 AS order_info, a.create_date AS order_date, b.c2 AS express_log, b.create_date AS express_log_date FROM t1 a inner join t2 b ON a.c1 = b.c1 WHERE b.c1 = 99999 )t WHERE t.sort_num = 1;


