
我用java爬蟲爬了一個圖片網站 最近想建立個網站,不想搞技術博客之類的網站了,因為像博客園還有CSDN這種足夠了。平時的問題也都是這些記錄一下就夠了。那搞個什麼網站好玩呢? 看到一個圖片網站還不錯,裡面好多圖片(當然有xxx圖片了....)哈哈,其實就是閑的,同時也介紹一下java爬蟲的相關用法把 ...
我用java爬蟲爬了一個圖片網站
最近想建立個網站,不想搞技術博客之類的網站了,因為像博客園還有CSDN這種足夠了。平時的問題也都是這些記錄一下就夠了。那搞個什麼網站好玩呢?
看到一個圖片網站還不錯,裡面好多圖片(當然有xxx圖片了....)哈哈,其實就是閑的,同時也介紹一下java爬蟲的相關用法把。
1、首先呢,爬蟲應該就是兩種了,一種是動態的介面請求返回的數據,這種json解析或者其他解析一下獲取自己需要的數據就可以了。
2、還有就是靜態html的網頁之類的。這種就需要解析html dom節點的數據。其實通俗點就是類似於 jquery 選擇器,html數據解析成dom節點的數據,java裡面有現成的類庫
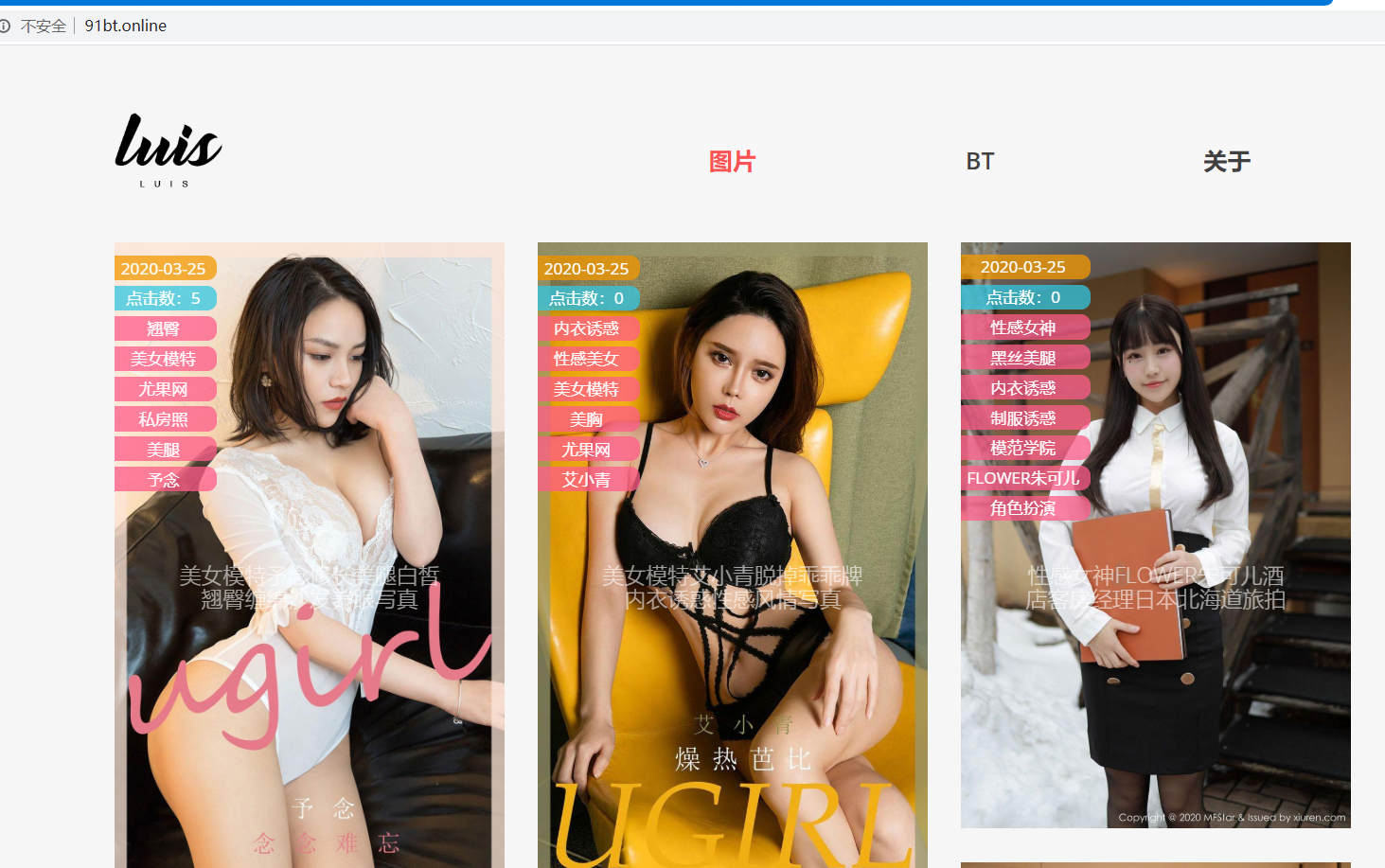
看下我根據爬取的圖片生成的網站效果把(代碼近期準備開源,隨便搞搞)
原網站:https://www.yeitu.com/meinv/
生成的網站:http://91bt.online/
說明一下,這個博客網站,是修改的 https://github.com/WinterChenS/my-site
需要的maven依賴,版本號自己去maven搜把
<!--網頁爬取-->
<!-- http -->
<dependency>
<groupId>org.apache.httpcomponents</groupId>
<artifactId>httpclient</artifactId>
</dependency>
<dependency>
<groupId>org.jsoup</groupId>
<artifactId>jsoup</artifactId>
</dependency>
接著介紹一下用法,
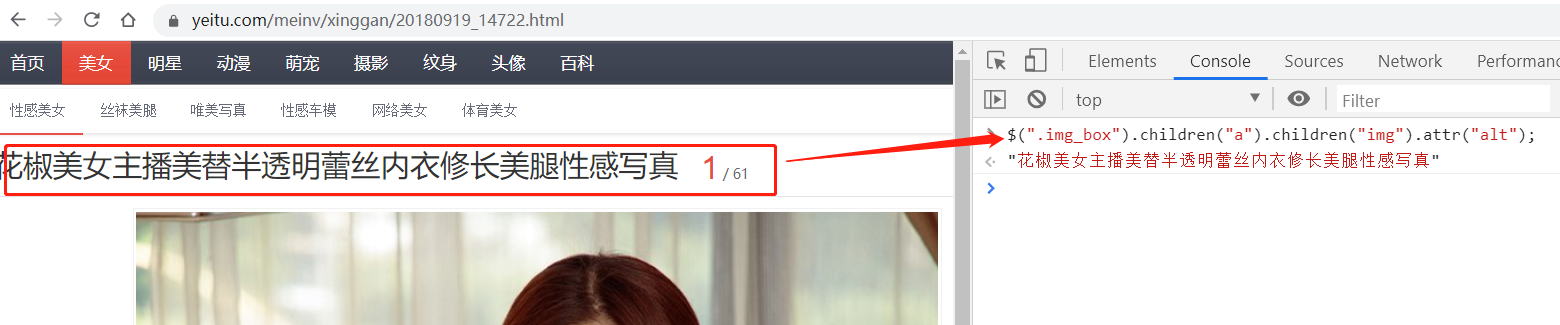
① 比如:爬取一個圖片靜態頁面: https://www.yeitu.com/meinv/xinggan/20180919_14722.html
我們正常用jquery獲取這個靜態頁面的標題(需要自己看dom節點的結構,用選擇器獲取)
② 接著,我們怎麼用代碼爬取這個呢?
用httpclient工具類,寫一個get請求方法,最終返回一個string的html網頁內容
String url="https://www.yeitu.com/meinv/xinggan/20180919_14722.html";
HttpGet get = new HttpGet(url);// 設置參數 Builder customReqConf = RequestConfig.custom(); customReqConf.setConnectTimeout(connTimeout); customReqConf.setSocketTimeout(socketTimeout); customReqConf.setConnectionRequestTimeout(requestTimeout); get.setConfig(customReqConf.build()); get.addHeader("Connection", "Close"); HttpResponse res; // 執行 Http 請求. if (url.startsWith("https")) { // 執行 Https 請求. client = createSSLInsecureClient(); res = client.execute(get); } else { // 執行 Http 請求. client = HttpClientUtil.client; res = client.execute(get); } return EntityUtils.toString(res.getEntity(), charset);
③、接著把 html內容轉換一下
Document documentInner = Jsoup.parse(htmlInner);
//這個就是圖片中的jquery的選擇器 //$(".img_box").children("a").children("img").attr("alt");
//下麵就是對應jsoup框架寫法
String firstAlt = documentInner.select(".img_box").select("a").select("img").attr("alt");
總結一下,就是把jquery對應選擇器的寫法,寫成jsoup框架的寫法轉換一下下。其實也沒轉換什麼東西,自己操作一下就比較清晰了

