
背景 By 魯迅 By 高爾基 說明: 1. Kernel版本:4.14 2. ARM64處理器,Contex A53,雙核 3. 使用工具:Source Insight 3.5, Visio 1. 概述 在Linux內核中,實時進程總是比普通進程的優先順序要高,實時進程的調度是由 來管理,而普通進程 ...
背景
Read the fucking source code!--By 魯迅A picture is worth a thousand words.--By 高爾基
說明:
- Kernel版本:4.14
- ARM64處理器,Contex-A53,雙核
- 使用工具:Source Insight 3.5, Visio
1. 概述
在Linux內核中,實時進程總是比普通進程的優先順序要高,實時進程的調度是由Real Time Scheduler(RT調度器)來管理,而普通進程由CFS調度器來管理。
實時進程支持的調度策略為:SCHED_FIFO和SCHED_RR。
前邊的系列文章都是針對CFS調度器來分析的,包括了CPU負載、組調度、Bandwidth控制等,本文的RT調度器也會從這些角度來分析,如果看過之前的系列文章,那麼這篇文章理解起來就會更容易點了。
前戲不多,直奔主題。
2. 數據結構
有必要把關鍵的結構體羅列一下了:
struct rq:運行隊列,每個CPU都對應一個;struct rt_rq:實時運行隊列,用於管理實時任務的調度實體;struct sched_rt_entity:實時調度實體,用於參與調度,功能與struct sched_entity類似;struct task_group:組調度結構體;struct rt_bandwidth:帶寬控制結構體;
老規矩,先上張圖,捋捋這些結構之間的關係吧:
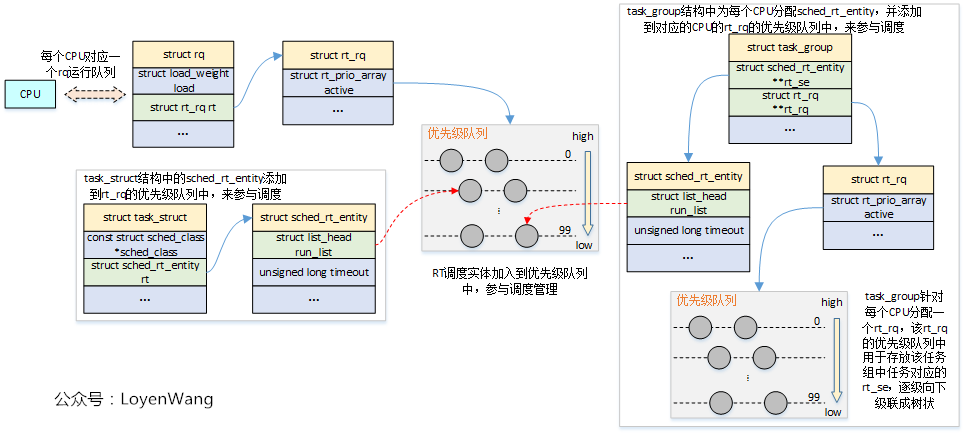
- 從圖中的結構組織關係看,與
CFS調度器基本一致,區別在與CFS調度器是通過紅黑樹來組織調度實體,而RT調度器使用的是優先順序隊列來組織實時調度實體; rt_rq運行隊列,維護了100個優先順序的隊列(鏈表),優先順序0-99,從高到底;- 調度器管理的對象是調度實體,任務
task_struct和任務組task_group都是通過內嵌調度實體的數據結構,來最終參與調度管理的; task_group任務組調度,自身為每個CPU維護rt_rq,用於存放自己的子任務或者子任務組,子任務組又能往下級聯,因此可以構造成樹;
上述結構體中,struct rq和struct task_group,在前文中都分析過。
下邊針對RT運行隊列相關的關鍵結構體,簡單註釋下吧:
struct sched_rt_entity {
struct list_head run_list; //用於加入到優先順序隊列中
unsigned long timeout; //設置的時間超時
unsigned long watchdog_stamp; //用於記錄jiffies值
unsigned int time_slice; //時間片,100ms,
unsigned short on_rq;
unsigned short on_list;
struct sched_rt_entity *back; //臨時用於從上往下連接RT調度實體時使用
#ifdef CONFIG_RT_GROUP_SCHED
struct sched_rt_entity *parent; //指向父RT調度實體
/* rq on which this entity is (to be) queued: */
struct rt_rq *rt_rq; //RT調度實體所屬的實時運行隊列,被調度
/* rq "owned" by this entity/group: */
struct rt_rq *my_q; //RT調度實體所擁有的實時運行隊列,用於管理子任務或子組任務
#endif
} __randomize_layout;
/* Real-Time classes' related field in a runqueue: */
struct rt_rq {
struct rt_prio_array active; //優先順序隊列,100個優先順序的鏈表,並定義了點陣圖,用於快速查詢
unsigned int rt_nr_running; //在RT運行隊列中所有活動的任務數
unsigned int rr_nr_running;
#if defined CONFIG_SMP || defined CONFIG_RT_GROUP_SCHED
struct {
int curr; /* highest queued rt task prio */ //當前RT任務的最高優先順序
#ifdef CONFIG_SMP
int next; /* next highest */ //下一個要運行的RT任務的優先順序,如果兩個任務都有最高優先順序,則curr == next
#endif
} highest_prio;
#endif
#ifdef CONFIG_SMP
unsigned long rt_nr_migratory; //任務沒有綁定在某個CPU上時,這個值會增減,用於任務遷移
unsigned long rt_nr_total; //用於overload檢查
int overloaded; //RT運行隊列過載,則將任務推送到其他CPU
struct plist_head pushable_tasks; //優先順序列表,用於推送過載任務
#endif /* CONFIG_SMP */
int rt_queued; //表示RT運行隊列已經加入rq隊列
int rt_throttled; //用於限流操作
u64 rt_time; //累加的運行時,超出了本地rt_runtime時,則進行限制
u64 rt_runtime; //分配給本地池的運行時
/* Nests inside the rq lock: */
raw_spinlock_t rt_runtime_lock;
#ifdef CONFIG_RT_GROUP_SCHED
unsigned long rt_nr_boosted; //用於優先順序翻轉問題解決
struct rq *rq; //指向運行隊列
struct task_group *tg; //指向任務組
#endif
};
struct rt_bandwidth {
/* nests inside the rq lock: */
raw_spinlock_t rt_runtime_lock;
ktime_t rt_period; //時間周期
u64 rt_runtime; //一個時間周期內的運行時間,超過則限流,預設值為0.95ms
struct hrtimer rt_period_timer; //時間周期定時器
unsigned int rt_period_active;
};
3. 流程分析
3.1 運行時統計數據
運行時的統計數據更新,是在update_curr_rt函數中完成的:
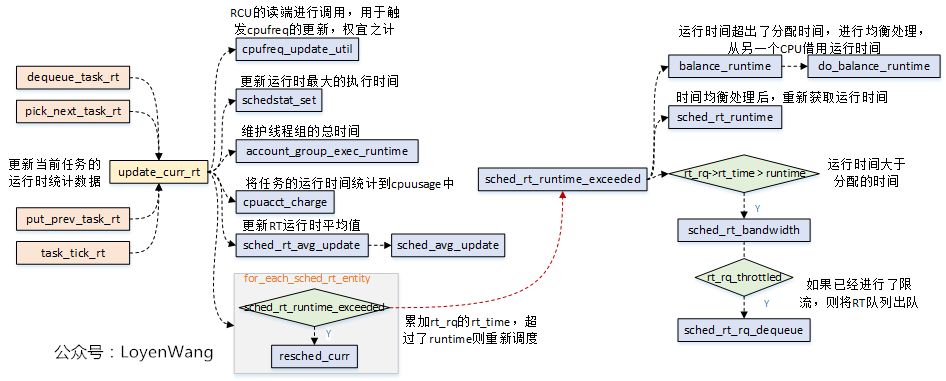
update_curr_rt函數功能,主要包括兩部分:- 運行時間的統計更新處理;
- 如果運行時間超出了分配時間,進行時間均衡處理,並且判斷是否需要進行限流,進行了限流則需要將RT隊列出隊,並重新進行調度;
為了更直觀的理解,下邊還是來兩張圖片說明一下:
sched_rt_avg_update更新示意如下:
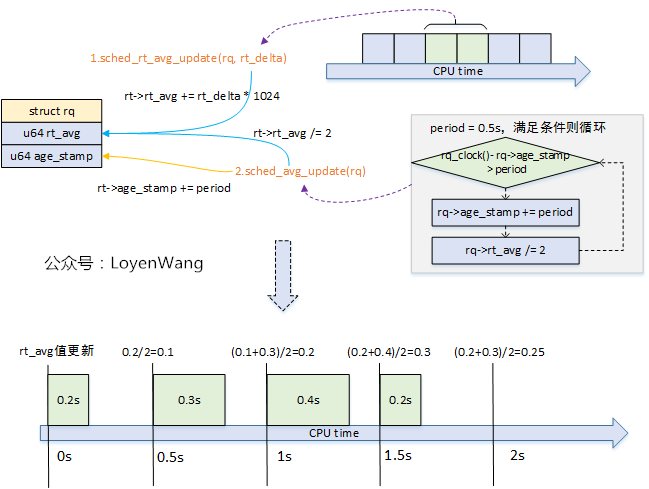
rq->age_stamp:在CPU啟動後運行隊列首次運行時設置起始時間,後續周期性進行更新;rt_avg:累計的RT平均運行時間,每0.5秒減半處理,用於計算CFS負載減去RT在CFS負載平衡中使用的時間百分比;
3.2 組調度
RT調度器與CFS調度器的組調度基本類似,CFS調度器的組調度請參考(四)Linux進程調度-組調度及帶寬控制。
看一下RT調度器組調度的組織關係圖吧:
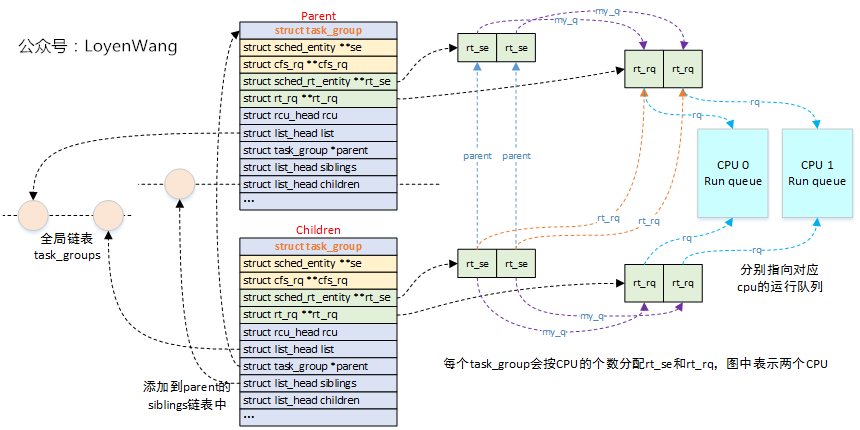
- 系統為每個CPU都分配了RT運行隊列,以及RT調度實體,任務組通過它包含的RT調度實體來參與調度;
- 任務組
task_group的RT隊列,用於存放歸屬於該組的任務或子任務組,從而形成級聯的結構;
看一下實際的組織示意圖:

3.3 帶寬控制
請先參考(四)Linux進程調度-組調度及帶寬控制。
RT調度器在帶寬控制中,調度時間周期設置的為1s,運行時間設置為0.95s:
/*
* period over which we measure -rt task CPU usage in us.
* default: 1s
*/
unsigned int sysctl_sched_rt_period = 1000000;
/*
* part of the period that we allow rt tasks to run in us.
* default: 0.95s
*/
int sysctl_sched_rt_runtime = 950000;
這兩個值可以在用戶態通過/sys/fs/cgroup/cpu/rt_runtime_us和/sys/fs/cgroup/cpu/rt_period_us來進行設置。
看看函數調用流程:
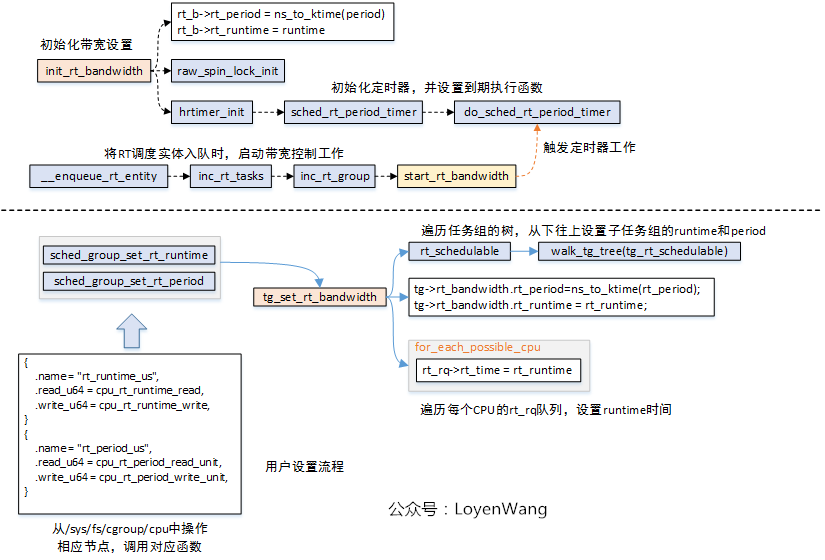
init_rt_bandwidth函數在創建分配RT任務組的時候調用,完成的工作是將rt_bandwidth結構體的相關欄位進行初始化:設置好時間周期rt_period和運行時間限制rt_runtime,都設置成預設值;- 可以從用戶態通過操作
/sys/fs/cgroup/cpu下對應的節點進行設置rt_period和rt_runtime,最終調用的函數是tg_set_rt_bandwidth,在該函數中會從下往上的遍歷任務組進行設置時間周期和限制的運行時間; - 在
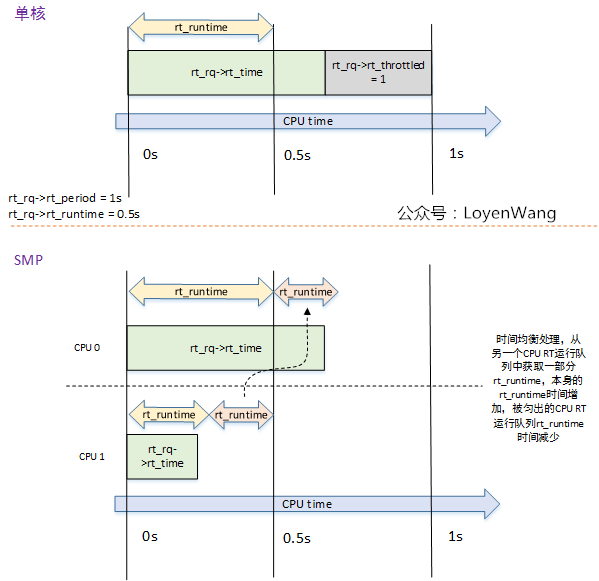
enqueue_rt_entity將RT調度實體入列時,最終觸發start_rt_bandwidth函數執行,當高精度定時器到期時調用do_sched_rt_period_timer函數; do_sched_rt_period_timer函數,會去判斷該RT運行隊列的累計運行時間rt_time與設置的限制運行時間rt_runtime之間的大小關係,以確定是否限流的操作。在這個函數中,如果已經進行了限流操作,會調用balance_time來在多個CPU之間進行時間均衡處理,簡單點說,就是從其他CPU的rt_rq隊列中勻出一部分時間增加到當前CPU的rt_rq隊列中,也就是將當前rt_rt運行隊列的限制運行時間rt_runtime增加一部分,其他CPU的rt_rq運行隊列限制運行時間減少一部分。
來一張效果示意圖:
3.4 調度器函數分析
來一張前文的圖:

看一下RT調度器實例的代碼:
const struct sched_class rt_sched_class = {
.next = &fair_sched_class,
.enqueue_task = enqueue_task_rt,
.dequeue_task = dequeue_task_rt,
.yield_task = yield_task_rt,
.check_preempt_curr = check_preempt_curr_rt,
.pick_next_task = pick_next_task_rt,
.put_prev_task = put_prev_task_rt,
#ifdef CONFIG_SMP
.select_task_rq = select_task_rq_rt,
.set_cpus_allowed = set_cpus_allowed_common,
.rq_online = rq_online_rt,
.rq_offline = rq_offline_rt,
.task_woken = task_woken_rt,
.switched_from = switched_from_rt,
#endif
.set_curr_task = set_curr_task_rt,
.task_tick = task_tick_rt,
.get_rr_interval = get_rr_interval_rt,
.prio_changed = prio_changed_rt,
.switched_to = switched_to_rt,
.update_curr = update_curr_rt,
};
3.4.1 pick_next_task_rt
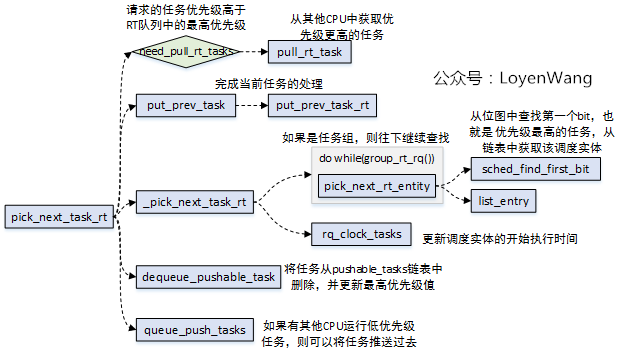
pick_next_task_rt函數是調度器用於選擇下一個執行任務。流程如下:
- 與
CFS調度器不同,RT調度器會在多個CPU組成的domain中,對任務進行pull/push處理,也就是說,如果當前CPU的運行隊列中任務優先順序都不高,那麼會考慮去其他CPU運行隊列中找一個更高優先順序的任務來執行,以確保按照優先順序處理,此外當前CPU也會把任務推送到其他更低優先順序的CPU運行隊列上。 _pick_next_task_rt的處理邏輯比較簡單,如果實時調度實體是task,則直接查找優先順序隊列的點陣圖中,找到優先順序最高的任務,而如果實時調度實體是task_group,則還需要繼續往下進行遍歷查找;
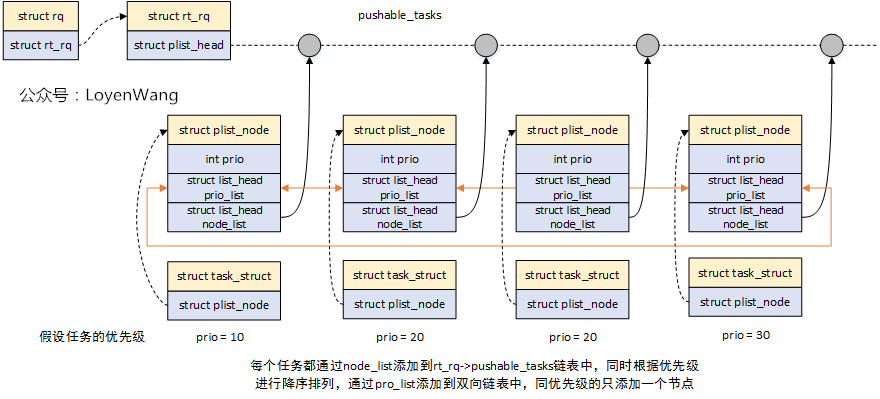
關於任務的pull/push,linux提供了struct plist,基於優先順序的雙鏈表,其中任務的組織關係如下圖:
pull_rt_task的大概示意圖如下:
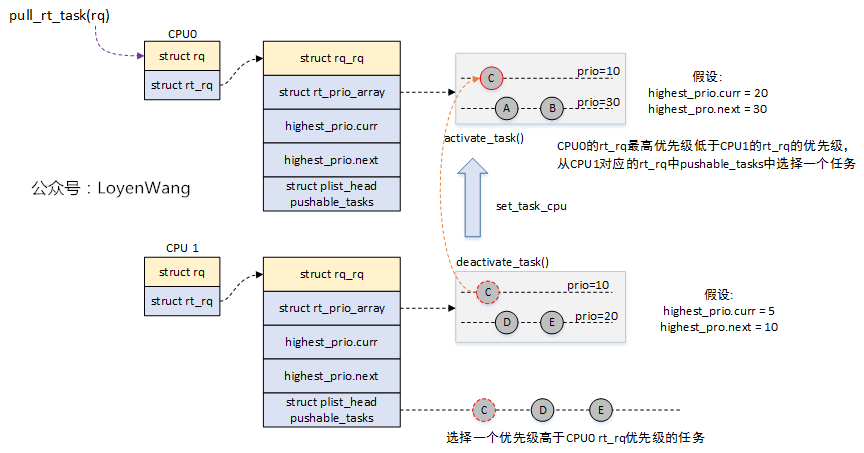
- 當前CPU上的優先順序任務不高,從另一個CPU的
pushable_tasks鏈表中找優先順序更高的任務來執行;
3.4.2 enqueue_task_rt/dequeue_task_rt
當RT任務進行出隊入隊時,通過enqueue_task_rt/dequeue_task_rt兩個介面來完成,調用流程如下:
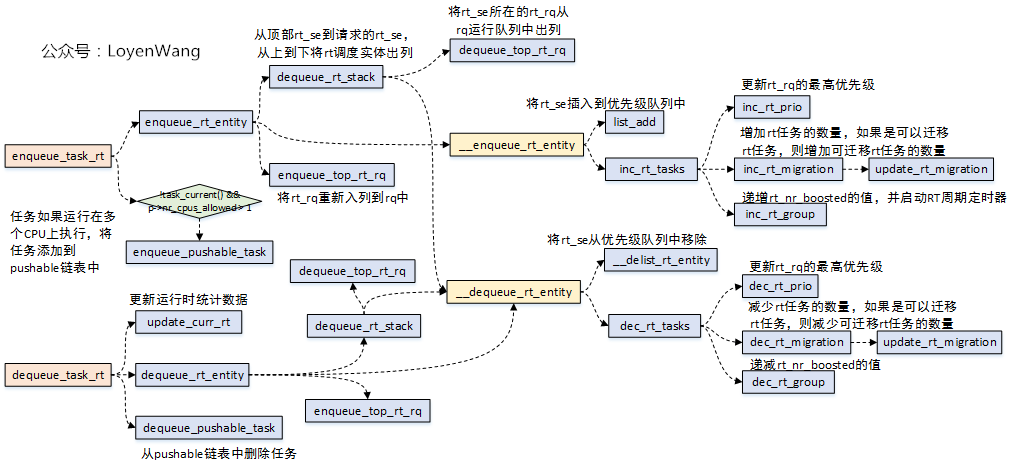
enqueue_task_rt和dequeue_task_rt都會調用dequeue_rt_stack介面,當請求的rt_se對應的是任務組時,會從頂部到請求的rt_se將調度實體出列;- 任務添加到rt運行隊列時,如果存在多個任務可以分配給多個CPU,設置overload,用於任務的遷移;
有點累了,收工了。



