
網路上有很多MySQL表碎片整理的問題,大多數是通過demo一個表然後參考data free來進行碎片整理,這種方式對myisam引擎或者其他引擎可能有效(本人沒有做詳細的測試).對Innodb引擎是不是準確的,或者data free是不是可以參考,還是值得商榷的。本文基於MySQL的Innodb存 ...
網路上有很多MySQL表碎片整理的問題,大多數是通過demo一個表然後參考data free來進行碎片整理,這種方式對myisam引擎或者其他引擎可能有效(本人沒有做詳細的測試).
對Innodb引擎是不是準確的,或者data free是不是可以參考,還是值得商榷的。
本文基於MySQL的Innodb存儲引擎,資料庫版本是8.0.18,對碎片(fragment)做一個簡單的分析,來說明如何量化表的碎片化程度。
涉及的參數
1,information_schema_stats_expiry
information_schema是一個基於共用表空間的虛擬資料庫,存儲的是一些系統元數據信息,某些系統表的數據並不是實時更新的,具體更新是基於參數information_schema_stats_expiry。
information_schema_stats_expiry預設值是86400秒,也就是24小時,意味著24小時刷新一次information_schema中的數據,做測試的時候可以設置為0,實時刷新information_schema中的元數據信息。
2,innodb_fast_shutdown
因為要基於磁碟做一些統計,需要將緩存或者redo log中的數據在重啟實例的時候實時刷入磁碟,這裡設置為0,在重啟資料庫的時候將緩存或者redo log實時寫入表的物理文件。
3,innodb_stats_persistent_sample_pages
因為涉及一些系統數據更新時對page的採樣比例,這裡設置為一個較大的值,為100000,儘可能高比例採樣來生成系統數據。
4,innodb_flush_log_at_trx_commit sync_binlog
因為涉及大量數據的寫操作,為加快測試,關閉double 1模式。
5,innodb_fill_factor
頁面填充率保留預設的設置,預設值是100
以上涉及的參數僅針對本測試,並不一定代表最優,同時測試過程中(數據寫入或者刪除後)會不斷地重啟實例,以刷新相對應的物理文件。
碎片的概念
數據存儲在文件系統上的時候,總是不能100%利用分配給它的物理空間,比如刪除數據會在頁面上留下一些”空洞”,或者隨機寫入(聚集索引非線性增加)會導致頁分裂,頁分裂會導致頁面的利用空間少於50%。
另外對錶進行增刪改,包括對應的二級索引值的隨機的增刪改,都會導致數據頁面上留下一些“空洞”,雖然這些位置有可能會被重覆利用,但終究會導致部分物理空間未被使用,也就是碎片。
即便是設置了填充因數為100%,Innodb也會主動留下page頁面1/16的空間作為預留使用(An innodb_fill_factor setting of 100 leaves 1/16 of the space in clustered index pages free for future index growth.)。
關係資料庫的存儲結構原理上是類似的,理論上很簡單,就不過多啰嗦了。
測試表以及數據
做個簡單的測試,表結構如下,
CREATE TABLE `fragment_test` ( `id` INT NOT NULL AUTO_INCREMENT, `c1` INT NULL DEFAULT NULL, `c2` INT NULL DEFAULT NULL, `c3` VARCHAR(50) NULL DEFAULT NULL, `c4` DATETIME(6) NULL DEFAULT NULL, PRIMARY KEY (`id`) ); CREATE INDEX idx_c1 ON fragment_test(c1); CREATE INDEX idx_c2 ON fragment_test(c2); CREATE INDEX idx_c3 ON fragment_test(c3);
生成200W測試數據(CALL test_insertdata(2000000);)
CREATE DEFINER=`root`@`%` PROCEDURE `test_insertdata`( IN `loopcount` INT ) BEGIN declare v_uuid varchar(50); while loopcount>0 do set v_uuid = uuid(); INSERT INTO fragment_test(c1,c2,c3,c4) VALUES (RAND()*200000000,RAND()*200000000,UUID(),NOW(6)); set loopcount = loopcount -1; end while; END
查詢語句,參考自最後的鏈接中的文章
SELECT NAME, TABLE_ROWS, UPDATE_TIME, format_bytes(data_length) DATA_SIZE, format_bytes(index_length) INDEX_SIZE, format_bytes(data_length+index_length) TOTAL_SIZE, format_bytes(data_free) DATA_FREE, format_bytes(FILE_SIZE) FILE_SIZE, format_bytes((FILE_SIZE/10 - (data_length/10 + index_length/10))*10) WASTED_SIZE FROM information_schema.TABLES as t JOIN information_schema.INNODB_TABLESPACES as it ON it.name = concat(table_schema,"/",table_name) WHERE TABLE_NAME = 'fragment_test';
碎片的測試
上面說到數據在存儲的時候,總是無法100%利用物理存儲空間,Innodb甚至會自己主動預留一部分空閑的空間(1/16),那麼如何衡量一個表究竟有多少尚未利用的空間?
這裡從系統表information_schema.tables和information_schema.innodb_tablespaces,來對比實際使用空間和已分配空間來對比,來間接量化碎片或者說未利用空間的程度。
然後觀察數據空間的分配情況,儘管系統表中的數據不是完全準確的,但是也比較接近實際的200W,系統表顯示1971490,暫時拋開這一小點誤差。
可以很清楚地看到,數據和索引的空間是329MB,文件空間是344MB,DATA_FREE空間是6MB。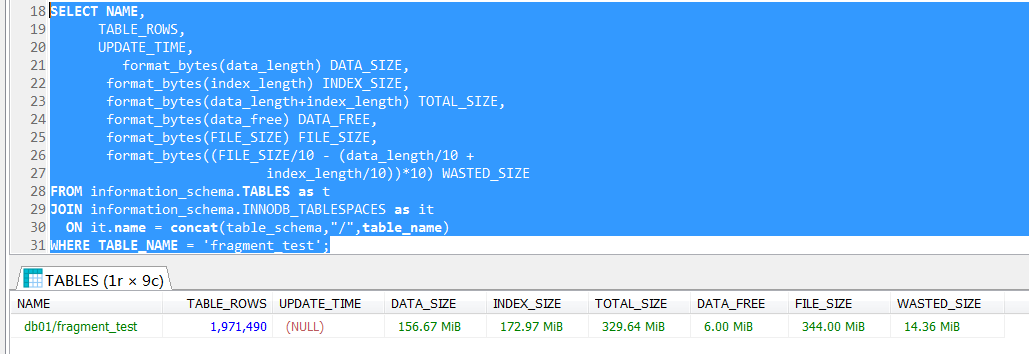
隨機刪除1/4的數據,也就是50W行,然後重啟實例,並分析表(analyze table),繼續來觀察這個空間的分配(DELETE FROM fragment_test ORDER BY RAND() LIMIT 500000;)
這裡看到,
1,系統表顯示150000行,跟表中的數據完全一致(儘管更多的時候這個值是一個大概的值,並不一定准確,嚴格說可能非常不准確,這裡歸因於innodb_stats_persistent_sample_pages的設置)。
2,數據文件空間沒有增加(344MB),可以理解,因為這裡是刪數據操作,所以不用申請空間。
3,刪除了1/4的數據,數據和索引的的大小基本上不變,這裡就開始有疑問了,為什麼沒有成比例減少?
4,data_free增加了3MB,顯然這不是跟刪除的數據成比例增加的
那麼怎麼理解碎片?DATA_FREE怎麼理解?碎片或者說可用空間又怎麼衡量?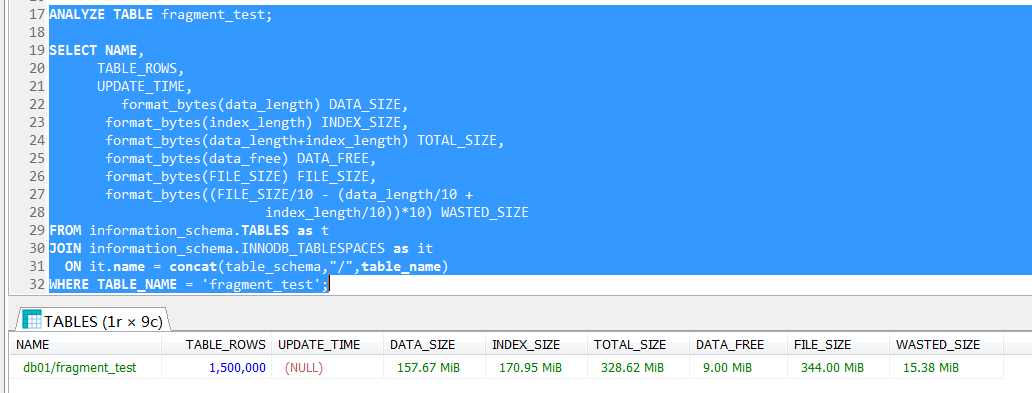
從200W數據中隨機刪除50W,也就是1/4,表的空間沒有變化,可以肯定的是現在存在大量的碎片或者說可用空間,但是表的總的大小沒變化,data_free也基本上沒有變化到這裡就有點說不通了。
那麼data free到底是怎麼計算的,看官方的解釋:
The number of allocated but unused bytes.
InnoDB tables report the free space of the tablespace to which the table belongs. For a table located in the shared tablespace, this is the free space of the shared tablespace.
If you are using multiple tablespaces and the table has its own tablespace, the free space is for only that table.
Free space means the number of bytes in completely free extents minus a safety margin. Even if free space displays as 0, it may be possible to insert rows as long as new extents need not be allocated.
data_free的計算方式或者說條件,是完全空閑的區(extents,每個區1MB,64個連續的16 kb 大小的page),只有一個完全沒有使用的區,才統計為data_free,因此data_free並不能反映出來真正的空閑空間。
同時測試中發現,performance_schema.tables中的table_rows會受到innodb_stats_persistent_sample_pages的影響,但是data_length和index_length看起來是不會受innodb_stats_persistent_sample_pages的影響的
這裡採樣比例已經足夠大,儘管table_rows已經是一個完全準確的數字了,但是data_length和index_length卻仍舊是一個誤差非常大的數字。
說到這裡,那麼這個碎片問題如何衡量?如果只是看performance_schema.tables或者information_schema.INNODB_TABLESPACES,其實依舊是一個無解的問題,因為無法通過這些信息,得到一個相對準確的碎片化程度。
其實在這裡(參考鏈接)的評論中也提到這個問題,我是比較贊同的。
如果要真正得到碎片程度,其實還是需要重建表來對比實現,這裡刪除了1/4的數據,理論上就有大概1/4的可用空間,但是上面的查詢結果並不能給出一個明確的答案,怎麼驗證這個答案呢?
這裡就要粗暴地優化表了(optimize table fragment_test+analyze table),優化表只是“重整”了碎片,但是系統表的數據並沒有更新,因此必須要再執行一次分析表 analyze table來更新元數據信息
其實這裡也能說明,analyze table只是更新元數據,如果存儲空間沒有更新(recreated),單純地analyze table也是沒有用的。
對標進行optimize和anlayze之後,這裡可以看到,物理空間確實減少了大概1/4的量。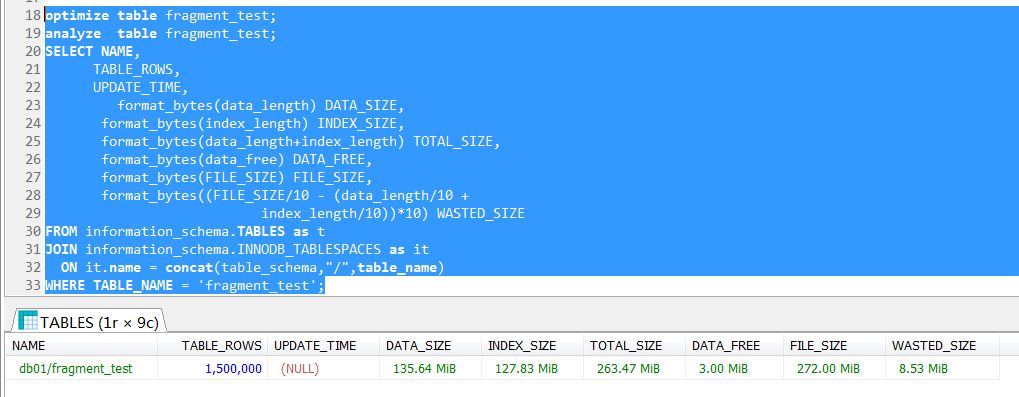
這裡其實就是為了說明一個問題:Innodb表無法通過data free來判斷表的碎片化程度。
然而這裡(參考鏈接)的測試說明刪除數據後data free有明顯的變化,這個又是為什麼,剛特麽說無法通過data free來判斷表的碎片化程度,現在又說刪除數據後data free有明顯的變化???
其實(參考鏈接)中有另外一個比較有意思的測試,相對用隨機刪除的方式,採用連續刪除的時候(或者是整個表的數據全部刪除),這個data free確實會相對準確地體現出來刪除數據後表size的變化情況。
這又是為什麼?其實不難理解,上面已經說了,data free的計算方式,是按照完全“乾凈”的區(extent)來做統計的,
如果按照聚集索引連續的方式刪除(相對隨機刪除),那些存儲連續數據的區(extent)是可以完全釋放出來的,這些區的空間釋放出來之後,會被認為是data free,所以data free此時又是相對來說準確的。
因此,很多測試,如果想到得到客觀的數據,需要儘可能多地考慮到對應的場景和測試數據情況。
碎片的衡量
實際業務中,對錶的刪除或者增刪改,很少是按照聚集索引進行批量刪除,或者說一旦存在隨機性的刪除或者更新(頁分裂),都會造成一定程度的碎片,而這個碎片化的程度是無法通過data free來衡量的。
那麼又如何衡量這個碎片程度呢?
1,自己根據業務進行預估,在可接受程度內進行optimize table,記錄optimize table之後的table size變化程度,來衡量一個表在一定時間操作後的碎片化程度,從而來指導是否,或者多久對該表再次進行optimize table
2,採用上述連接中提到的innodb_ruby 這個工具,直接解析表的物理文件,這種方式相對來說更加直接。不過這個工具本人沒來得及測試,理論上是沒有問題的。
這裡盜用上述鏈接中的圖片,綠色的是實際使用的空間,中間的黑塊就是所謂的碎片或者說是空洞。
補充:
早上起來,又想到了另外一種case,就是說隨機刪除後,剩餘空間中出現了“空洞”,這些空洞在寫數據的時候,會不會被再次利用?
驗證其實很簡單,寫入200W數據,隨機刪除50W後,analyze table更新performance_schema,然後繼續再寫入50W行的數據,如果會利用之前隨機刪除的空洞空間,那麼就不會重新分配物理空間,否則就會重新分配物理空間。
因為聚集索引的Id是自增的,相當於順序寫入,理論上是不會重用之前刪除留下的空洞的,測試的結果還是在預期之內的,重新寫入50W數據後,表對應的物理文件會有一個很明顯的增加。
參考鏈接:
https://dev.mysql.com/doc/refman/5.7/en/innodb-file-defragmenting.html
https://dev.mysql.com/doc/refman/8.0/en/tables-table.html
https://lefred.be/content/overview-of-fragmented-mysql-innodb-tables/
https://lefred.be/content/mysql-innodb-disk-space/
https://dev.mysql.com/doc/refman/5.7/en/innodb-parameters.html#sysvar_innodb_fill_factor

