
一、分析網站內容 本次爬取網站為opgg,網址為:” http://www.op.gg/champion/statistics” 由網站界面可以看出,右側有英雄的詳細信息,以Garen為例,勝率為53.84%,選取率為16.99%,常用位置為上單 現對網頁源代碼進行分析(右鍵滑鼠在菜單中即可找到 ...
一、分析網站內容
本次爬取網站為opgg,網址為:” http://www.op.gg/champion/statistics”
![]()
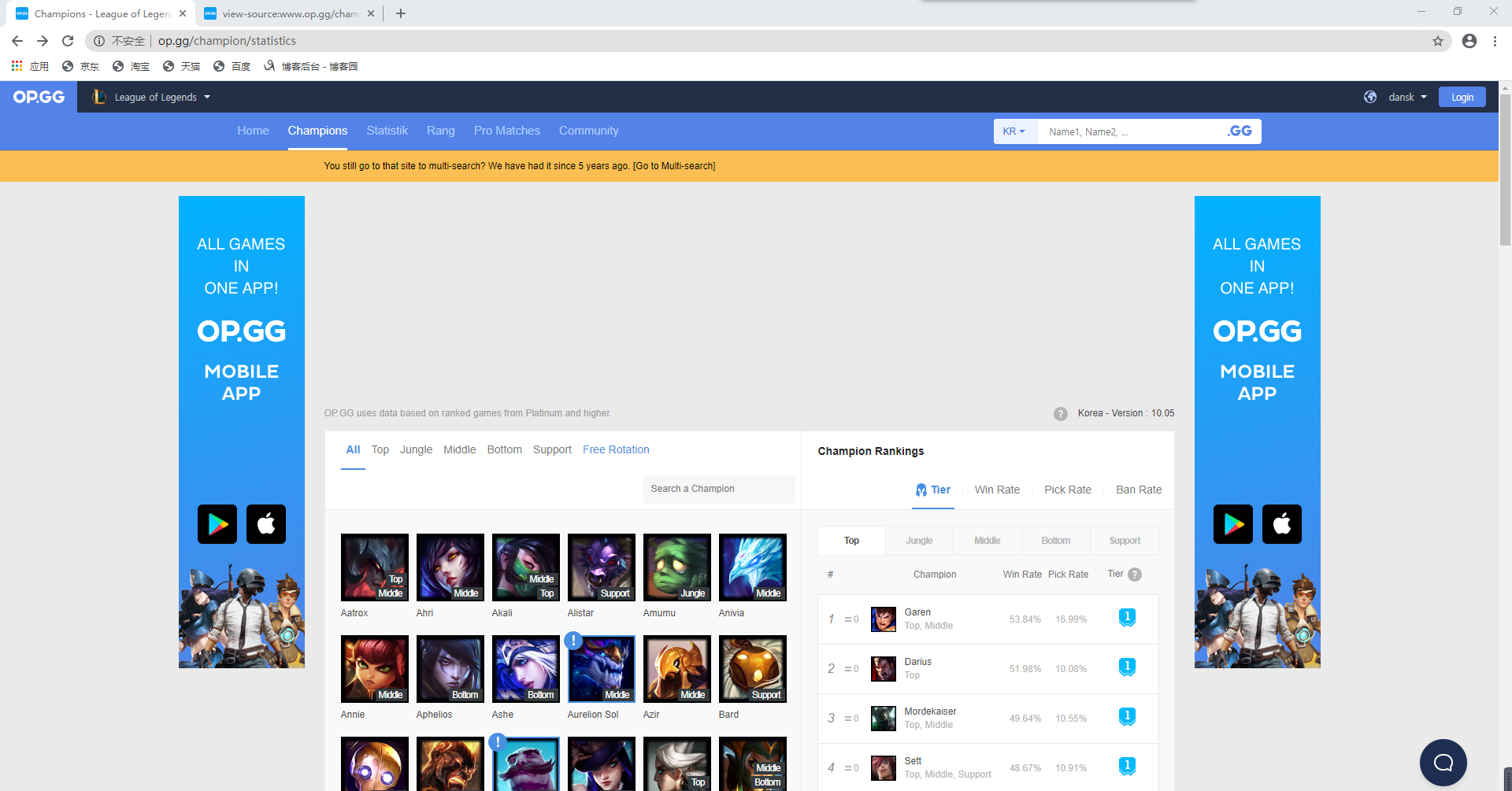
由網站界面可以看出,右側有英雄的詳細信息,以Garen為例,勝率為53.84%,選取率為16.99%,常用位置為上單
現對網頁源代碼進行分析(右鍵滑鼠在菜單中即可找到查看網頁源代碼)。通過查找“53.84%”快速定位Garen所在位置
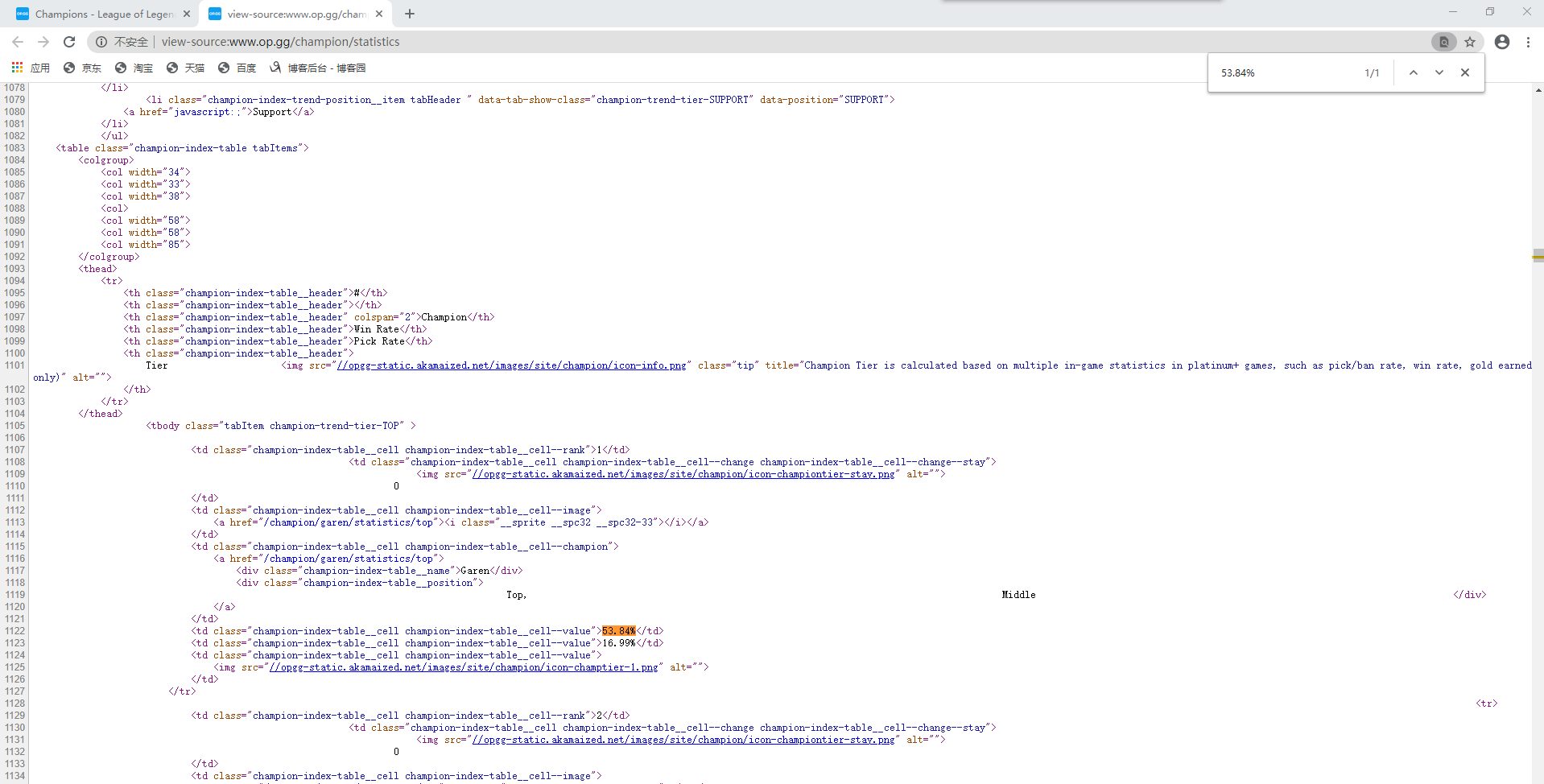
由代碼可看出,英雄名、勝率及選取率都在td標簽中,而每一個英雄信息在一個tr標簽中,td父標簽為tr標簽,tr父標簽為tbody標簽。
對tbody標簽進行查找

代碼中共有5個tbody標簽(tbody標簽開頭結尾均有”tbody”,故共有10個”tbody”),對欄位內容分析,分別為上單、打野、中單、ADC、輔助信息
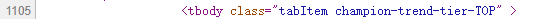

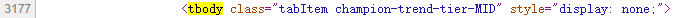
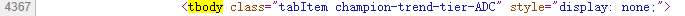

以上單這部分英雄為例,我們需要首先找到tbody標簽,然後從中找到tr標簽(每一條tr標簽就是一個英雄的信息),再從子標簽td標簽中獲取英雄的詳細信息
二、爬取步驟
爬取網站內容->提取所需信息->輸出英雄數據
getHTMLText(url)->fillHeroInformation(hlist,html)->printHeroInformation(hlist)
getHTMLText(url)函數是返回url鏈接中的html內容
fillHeroInformation(hlist,html)函數是將html中所需信息提取出存入hlist列表中
printHeroInformation(hlist)函數是輸出hlist列表中的英雄信息
三、代碼實現
1、getHTMLText(url)函數

1 def getHTMLText(url): #返回html文檔信息 2 try: 3 r = requests.get(url,timeout = 30) 4 r.raise_for_status() 5 r.encoding = r.apparent_encoding 6 return r.text #返回html內容 7 except: 8 return ""
2、fillHeroInformation(hlist,html)函數

以一個tr標簽為例,tr標簽內有7個td標簽,第4個td標簽內屬性值為"champion-index-table__name"的div標簽內容為英雄名,第5個td標簽內容為勝率,第6個td標簽內容為選取率,將這些信息存入hlist列表中
1 def fillHeroInformation(hlist,html): #將英雄信息存入hlist列表
2 soup = BeautifulSoup(html,"html.parser")
3 for tr in soup.find(name = "tbody",attrs = "tabItem champion-trend-tier-TOP").children: #遍歷上單tbody標簽的兒子標簽
4 if isinstance(tr,bs4.element.Tag): #判斷tr是否為標簽類型,去除空行
5 tds = tr('td') #查找tr標簽下的td標簽
6 heroName = tds[3].find(attrs = "champion-index-table__name").string #英雄名
7 winRate = tds[4].string #勝率
8 pickRate = tds[5].string #選取率
9 hlist.append([heroName,winRate,pickRate]) #將英雄信息添加到hlist列表中
3、printHeroInformation(hlist)函數
1 def printHeroInformation(hlist): #輸出hlist列表信息
2 print("{:^20}\t{:^20}\t{:^20}\t{:^20}".format("英雄名","勝率","選取率","位置"))
3 for i in range(len(hlist)):
4 i = hlist[i]
5 print("{:^20}\t{:^20}\t{:^20}\t{:^20}".format(i[0],i[1],i[2],"上單"))
4、main()函數
網站地址賦值給url,新建一個hlist列表,調用getHTMLText(url)函數獲得html文檔信息,使用fillHeroInformation(hlist,html)函數將英雄信息存入hlist列表,再使用printHeroInformation(hlist)函數輸出信息
1 def main(): 2 url = "http://www.op.gg/champion/statistics" 3 hlist = [] 4 html = getHTMLText(url) #獲得html文檔信息 5 fillHeroInformation(hlist,html) #將英雄信息寫入hlist列表 6 printHeroInformation(hlist) #輸出信息
四、結果演示
1、網站界面信息
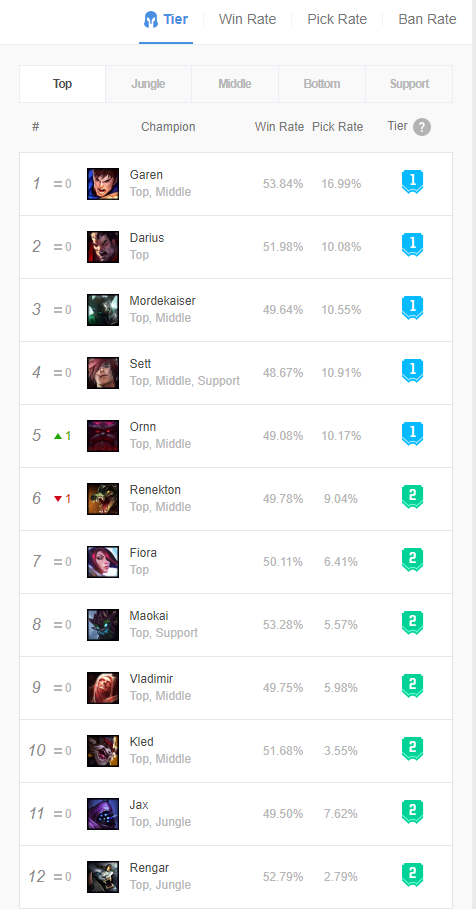
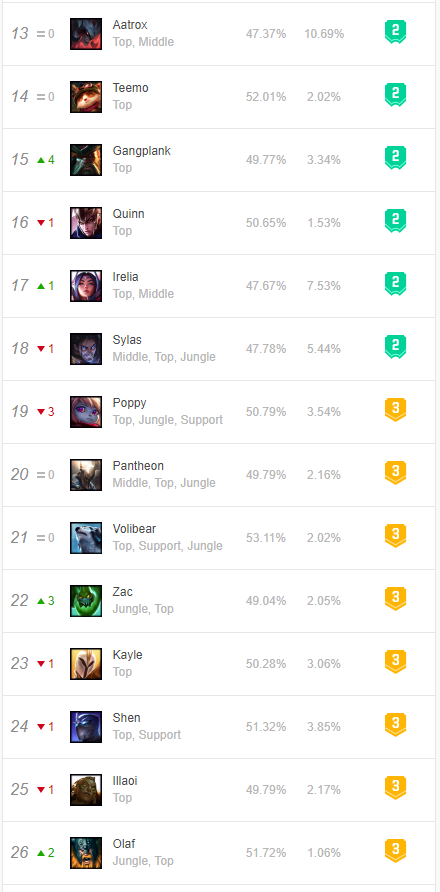

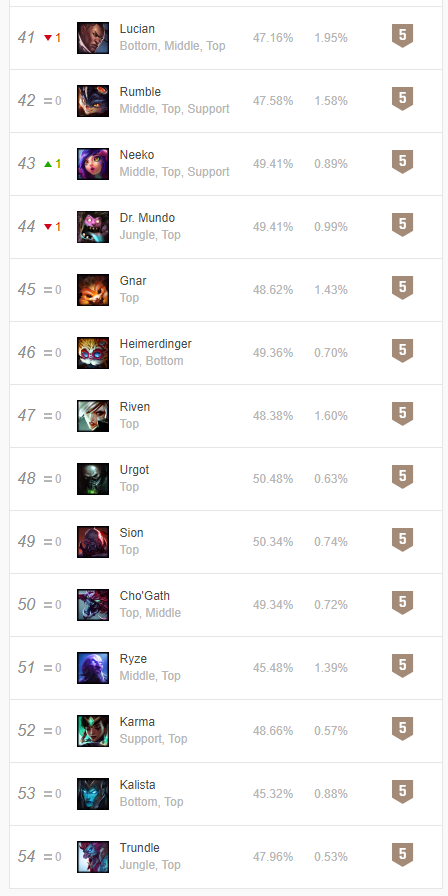
2、爬取結果
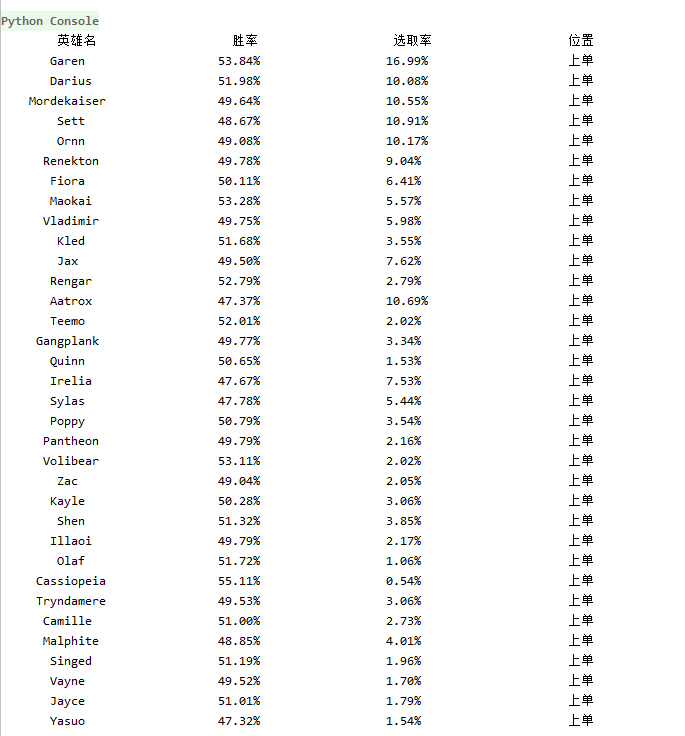

五、完整代碼
1 import requests
2 import re
3 import bs4
4 from bs4 import BeautifulSoup
5
6 def getHTMLText(url): #返回html文檔信息
7 try:
8 r = requests.get(url,timeout = 30)
9 r.raise_for_status()
10 r.encoding = r.apparent_encoding
11 return r.text #返回html內容
12 except:
13 return ""
14
15 def fillHeroInformation(hlist,html): #將英雄信息存入hlist列表
16 soup = BeautifulSoup(html,"html.parser")
17 for tr in soup.find(name = "tbody",attrs = "tabItem champion-trend-tier-TOP").children: #遍歷上單tbody標簽的兒子標簽
18 if isinstance(tr,bs4.element.Tag): #判斷tr是否為標簽類型,去除空行
19 tds = tr('td') #查找tr標簽下的td標簽
20 heroName = tds[3].find(attrs = "champion-index-table__name").string #英雄名
21 winRate = tds[4].string #勝率
22 pickRate = tds[5].string #選取率
23 hlist.append([heroName,winRate,pickRate]) #將英雄信息添加到hlist列表中
24
25 def printHeroInformation(hlist): #輸出hlist列表信息
26 print("{:^20}\t{:^20}\t{:^20}\t{:^20}".format("英雄名","勝率","選取率","位置"))
27 for i in range(len(hlist)):
28 i = hlist[i]
29 print("{:^20}\t{:^20}\t{:^20}\t{:^20}".format(i[0],i[1],i[2],"上單"))
30
31 def main():
32 url = "http://www.op.gg/champion/statistics"
33 hlist = []
34 html = getHTMLText(url) #獲得html文檔信息
35 fillHeroInformation(hlist,html) #將英雄信息寫入hlist列表
36 printHeroInformation(hlist) #輸出信息
37
38 main()
如果需要爬取打野、中單、ADC或者輔助信息,只需要修改
fillHeroInformation(hlist,html)函數中的
for tr in soup.find(name = "tbody",attrs = "tabItem champion-trend-tier-TOP").children語句,將attrs屬性值修改為
"tabItem champion-trend-tier-JUNGLE"、"tabItem champion-trend-tier-MID"、"tabItem champion-trend-tier-ADC"、"tabItem champion-trend-tier-SUPPORT"等即可
吾生也有涯,而知也無涯


