
其實這個坑呢,說實話是非常的有意思,因為當時這個坑弄得我甚至是以為編譯器壞了。 昨天我在寫關於豆瓣的爬蟲的時候,有這樣一個需求: 我想抓這個a標簽,拿他的鏈接地址。這個時候在瀏覽器里右鍵該標簽,複製其xpath結果如下: //*[@id="content"]/div/div[1]/div[2]/ta ...
其實這個坑呢,說實話是非常的有意思,因為當時這個坑弄得我甚至是以為編譯器壞了。
昨天我在寫關於豆瓣的爬蟲的時候,有這樣一個需求:
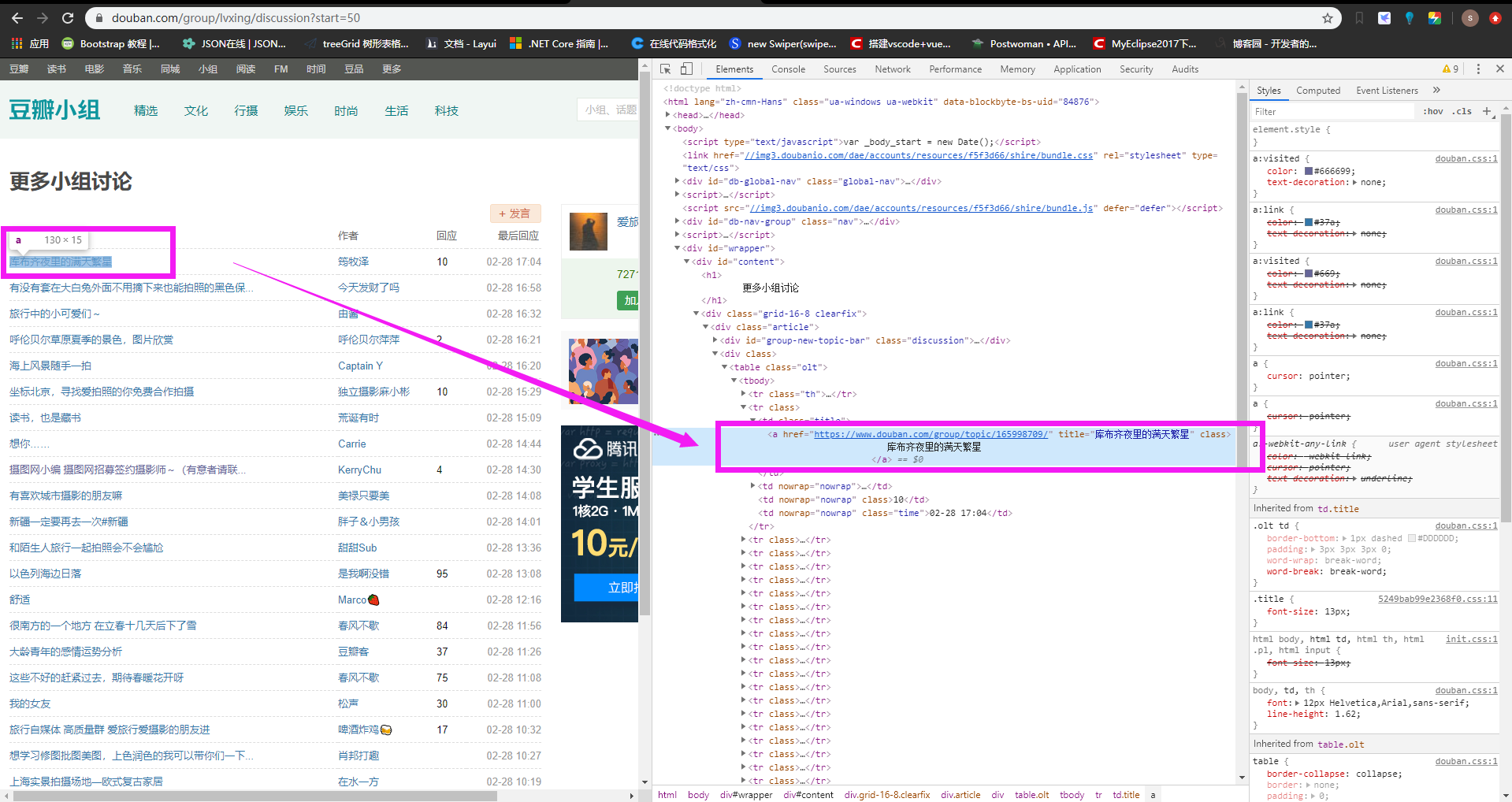
我想抓這個a標簽,拿他的鏈接地址。這個時候在瀏覽器里右鍵該標簽,複製其xpath結果如下:
//*[@id="content"]/div/div[1]/div[2]/table/tbody/tr[2]/td[1]/a
然後在代碼中,則按照這個xpath路徑去找,發現根本就沒用,什麼都找不到。
然後後面在調試的時候,我故意在即時視窗里,這樣子去試驗這條xpath路徑:
我先檢測 //*[@id="content"] 這樣能不能找到內容,然後發現可以;
然後檢測 //*[@id="content"]/div 發現也可以;
一直到 //*[@id="content"]/div/div[1]/div[2]/table/tbody 這個的時候,發現返回 null ,找不到?
最後我嘗試把 tbody 去掉,直接用 //*[@id="content"]/div/div[1]/div[2]/table/tr[2]/td[1]/a (把tbody刪了)
發現終於得到了我想要的那個標簽節點。
總結
其實這個坑就是說,xpath裡面不能帶 tbody ,碰到這個節點,直接跳過,進行到下一節點去


