
1、前言 公司內考慮到伺服器資源成本的問題,目前業務上還在進行服務的容器化改造和遷移,計劃將容器化後的服務,以及一些中間件(MQ、DB、ES、Redis等)儘量都遷移到其他機房。 那你們為什麼不用阿裡雲啊,騰訊雲啊,還用自己的機房? 的確是這樣,公司內部目前還是有專門的運維團隊。也是因為歷史原因,當 ...
1、前言
公司內考慮到伺服器資源成本的問題,目前業務上還在進行服務的容器化改造和遷移,計劃將容器化後的服務,以及一些中間件(MQ、DB、ES、Redis等)儘量都遷移到其他機房。
那你們為什麼不用阿裡雲啊,騰訊雲啊,還用自己的機房?
的確是這樣,公司內部目前還是有專門的運維團隊。也是因為歷史原因,當時業務發展比較迅猛,考慮到數據的安全性也是自建機房的。對於中小型公司這樣做,顯然成本太高了,所以一般都用阿裡雲。對於中大型企業或者對數據安全性要求高的公司,自建機房維護的也不再少數。
對於中間件來說,比如 Redis 緩存,有的業務也是因為歷史原因,當時上線後都是單獨申請,並部署的一套集群,但是量並不是很大,所以類似這種情況的,可以考慮跟其他項目使用的集群合併為一個,這樣就可能節省了一部分伺服器資源。
現在大多數企業都已經微服務化,容器化了。
所以,將非容器化的業務要求都遷移到容器中,這裡的容器基本都是指 Kubernetes 平臺了,通過容器發佈調度服務,對於運維來說,維護變得更加便捷,高效。
對於研發來說,業務需要部署服務,不再需要重新提 JIRA 工單,走一系列審核流程,最後給到你的可能還是一臺虛擬機,依賴的軟體單獨安裝部署。用了容器,只要在 集裝箱 中提前安裝好所需軟體環境,按照發佈規範打好鏡像,發佈服務的過程一路就是 點點點...。

2、線上業務場景介紹
繼續來說今天的主題。
有一個項目是 SpringCloud 架構的,其中使用到了 網關 Zuul,並且也使用了到了 Eureka 作為註冊中心。
因為該項目提前已經遷移到北京機房節點部署的容器環境,我們最終目標是遷移到其他機房(如:天津機房)。
北京有兩個機房:A機房、B機房,因為都在北京,所以兩個機房之間的 網路延時 是可以接受的。
微服務也同樣在這兩個機房之間都有部署。
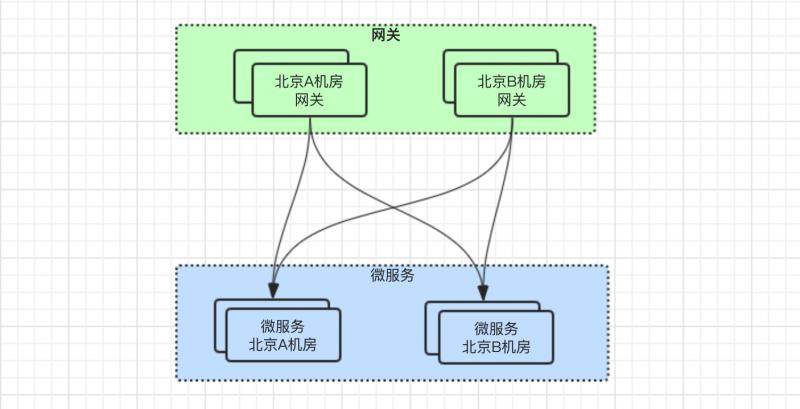
此時,如果只是將微服務部署到 天津機房,會變成如下圖所示的關係:
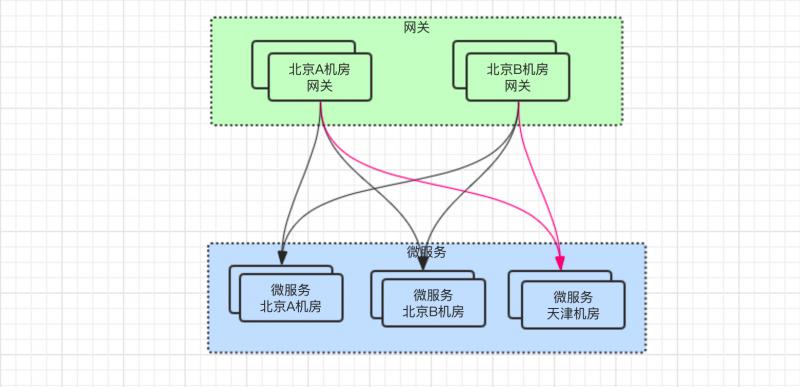
問題很明顯,就是網關服務只有北京的,而微服務新增了天津機房的,此時會導致 跨機房調用,即北京網關調用到了天津微服務。
儘管北京到天津 ping 的網路延時僅有 3 毫秒 之差,但是服務與服務之間的調用,可就不止這 3 毫秒了。
其中包括伺服器與伺服器之間 TCP連接的建立、數據傳輸的網路開銷,如果數據包過大,跨機房訪問耗時就會很明顯了。
所以呢,儘量避免跨機房訪問,當然要將網關也要遷移到天津機房。
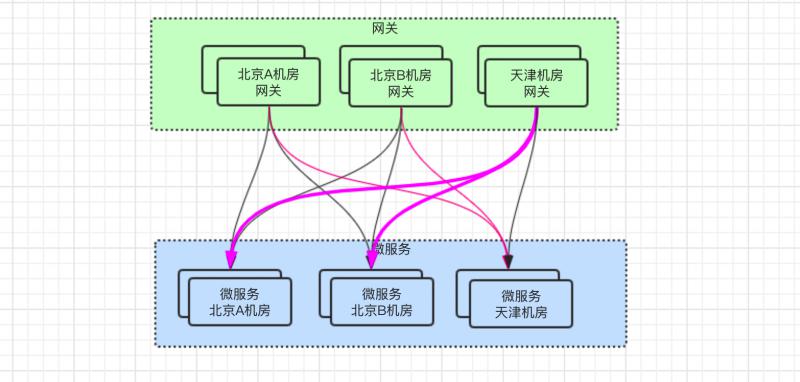
但是,大家看 粉紅色粗體 的線條,仍然存在跨機房調用,天津網關調用到北京微服務。
對於線上併發訪問量稍微大點,或者有些介面響應體大的,又或者網路抖動等場景下,可能就會導致介面響應時間變長了。
如何解決呢?
因大部分業務都部署到天津,可以將天津機房的服務權重調高
SLB配置 (類Nginx):
upstream {
server 北京機房網關IP 20;
server 天津機房網關IP 80;
}網關與微服務之間,都是通過 Eureka 註冊中心媒介來溝通,即 註冊服務 拉取服務。
僅僅在網關層配置好權重還不夠,此時還會存在天津網關路由到北京微服務上。
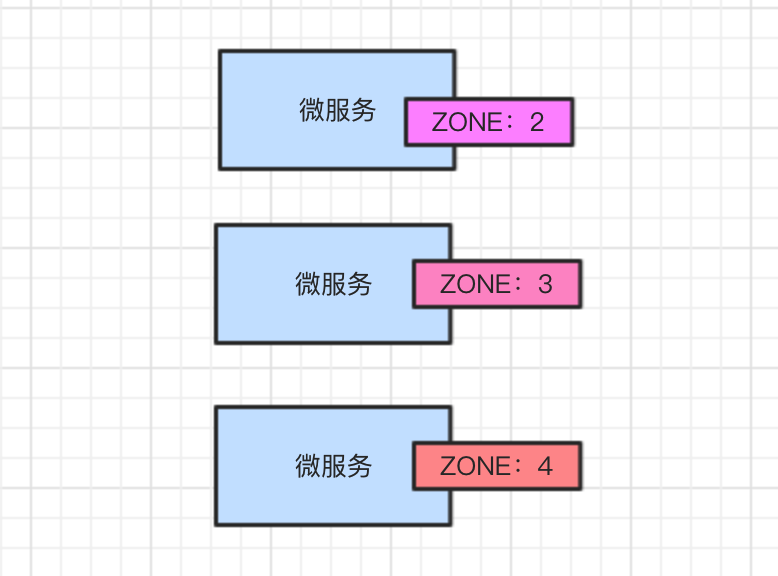
Eureka 內部是基於 Ribbon 實現負載均衡的,自行實現按權重的負載均衡策略,Eureka做一點改造,界面上支持權重的修改。
下圖截圖了部分示例:

IP後面的就是權重值,可以在界面上輸入權重值進行調整。
我們可以將北京微服務權重調低,天津微服務權重調高。
相當於網關以及微服務兩側都是通過基於 權重 的負載均衡演算法來儘量減少跨機房調用的,但是無法避免跨機房調用。
使用 Eureka 的分區改進
上面描述的方案對於 20% 的流量仍然存在跨機房訪問,我們能不能做到先訪問同一機房的服務,如果同一機房的服務都不可用了,再訪問其他機房的呢?
答案是 可以的。
我們可以藉助於 Eureka 註冊中心裡提供了 region 和 zone 的概念來實現。
region 和 zone 兩個概念均來自亞馬遜的 AWS:
region:簡單理解為地理上的分區,比如亞洲地區,或者華北地區等等,沒有具體大小的限制。根據項目情況,自行合理劃分 region。
zone:簡單理解為 region 內的具體機房,比如說 zone 劃分為北京、天津,且北京有兩個機房,就可以在 region 內劃分為三個zone,北京劃分為zone1、zone2,天津為zone3。
結合上面的示例,假設僅設置一個 region 為京津地區。
然後我們給這個區域下的網關服務、微服務打上 zone 機房標簽,在系統運維上將機房也稱作 IDC 數據中心。
網關服務打上zone標簽:

微服務打上zone標簽:
這個功能都是在 Eureka註冊中心 上實現的,在給服務配置 zone 前,調用路徑如下所示:
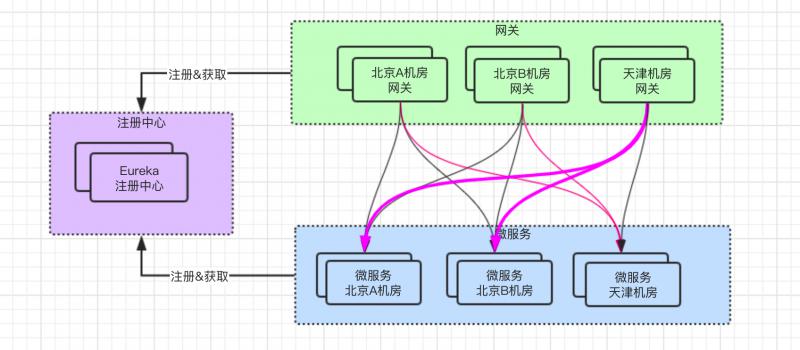
給服務配置 zone 之後,框架內部的路由機制的實現下,調用路徑如下所示:
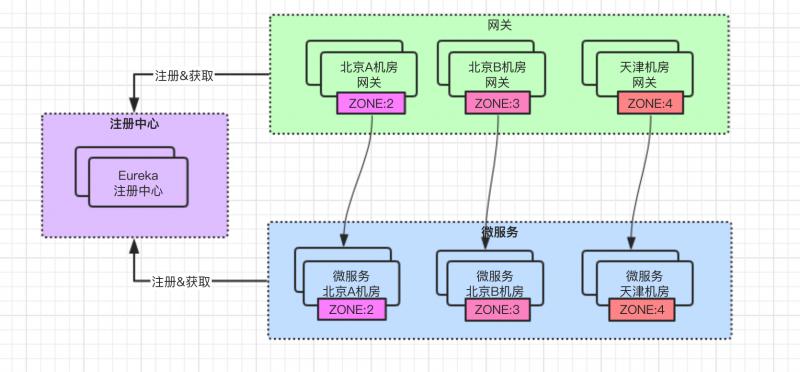
當前使用的 Eureka 是部署在北京,如果想讓服務在註冊、續約、拉取 動作時也能實現 就近機房訪問,部署架構就變成如下這個樣子:
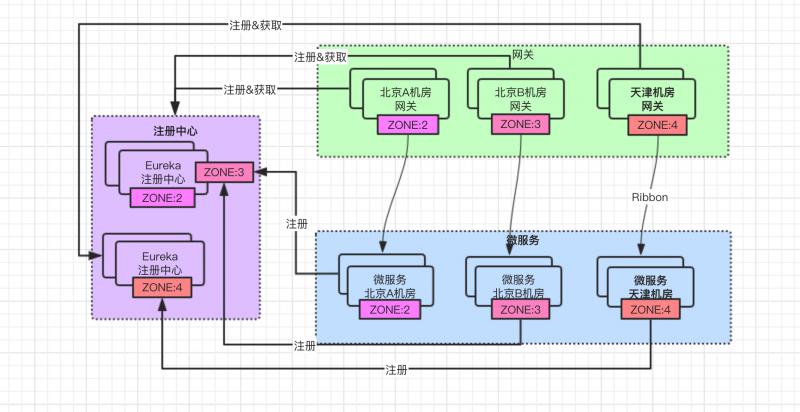
北京區域不同機房假設認為網路延時小,所以北京兩個機房可以使用同一個 Eureka 集群;天津可以單獨再部署一套 Eureka 集群,這樣就可以實現優先路由到同機房訪問。
服務註冊的關鍵配置
基本原理就是這樣,貼上一段 Eureka 使用 region 和 zone 的配置供大家參考:
spring:
application:
name: mananger
server:
port: ${EUREKA_SERVER_PORT:8011}
eureka:
instance:
# 全網服務實例唯一標識
instance-id: ${EUREKA_SERVER_IP:127.0.0.1}:${server.port}
# 服務實例的meta數據鍵值對集合,可由註冊中心進行服務實例間傳遞
metadata-map:
# [HA-P配置]-當前服務實例的zone
zone: ${EUREKA_SERVER_ZONE:tz-1}
profiles: ${spring.profiles.active}
# 開啟ip,預設為false=》hostname
prefer-ip-address: true
ip-address: ${EUREKA_SERVER_IP:127.0.0.1}
# [HA-P配置]-當前服務實例的region
client:
region: ${EUREKA_SERVER_REGION:cn-bj}
# [HA-P配置]-開啟當前服務實例優先發現同zone的註冊中心,預設為true
prefer-same-zone-eureka: true
# [服務註冊]-允許當前服務實例註冊,預設為true
register-with-eureka: true
# [服務續約]-允許當前服務實例獲取註冊信息,預設為true
fetch-registry: true
# [HA-P配置]-可用region下zone集合
availability-zones:
cn-bj: ${eureka.instance.metadata-map.zone},zone-bj,zone-tj
service-url:
# [HA-P配置]-各zone下註冊中心地址列表
zone-bj: http://BJIP1:8011/eureka,http://BJIP2:8012/eureka
zone-tj: http://TJIP1:8013/eureka,http://TJIP2:8014/eurekaprefer-same-zone-eureka :
預設就為true,首先會通過 region 找到 availability-zones 內的第一個 zone,然後通過這個 zone 找到 service-url 對應該機房的註冊中心地址列表,並向該列表內的 第一個URL 地址發起註冊和心跳,不會再向其它的URL地址發起操作。只有當第一個URL地址註冊失敗的情況下,才會依次向其它的URL發起操作,重試一定次數仍然失敗,會間隔一段心跳時間繼續重試。
eureka.instance.metadata-map.zone:
服務提供者和消費者都要配置該參數,表示自己屬於哪一個機房的。網關服務也屬於消費者,從註冊中心拉取到註冊表之後會根據這個參數中指定的 zone 進行過濾,過濾後向同 zone 內的服務會有多個實例 ,通過 Ribbon 來實現負載均衡調用。如果同一 zone 內的所有服務都不可用時,會其他 zone 的服務發起調用。
另外註意一點 availability-zones 下 region 的配置是 ${eureka.instance.metadata-map.zone},... 這樣配置的好處是,你只要指定好了 eureka.instance.metadata-map.zone,優先會將這個參數放到可用分區下作為第一個 zone 來訪問。
Zuul 網關路由分區源碼分析
網關使用的 zuul,其內部也是通過 ribbon 和 eureka 的結合來實現服務之間的調用,因為網關實際也是個服務消費者,同樣會註冊到 eureka 上,被網關拉取過來的註冊表裡的服務,作為服務提供者,同樣會註冊到eureka上。
通過一張圖把控整個請求的大致脈絡:
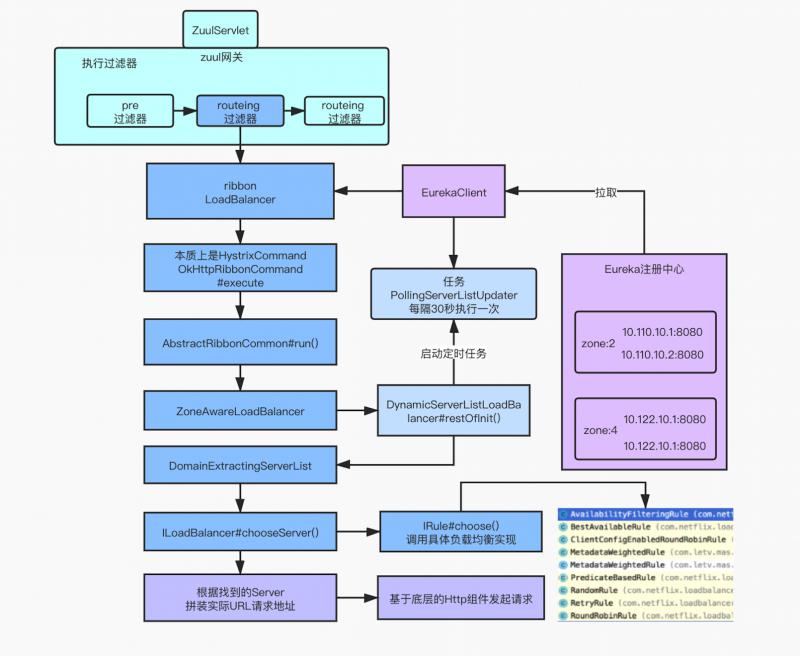
上述圖示中部分核心源碼如下所示:
PollServerListUpdater#start(final UpdateAction action) 啟動後會每隔30秒(預設)去Eureka註冊中心拉取一次註冊表信息,更新本地緩存的數據結構。
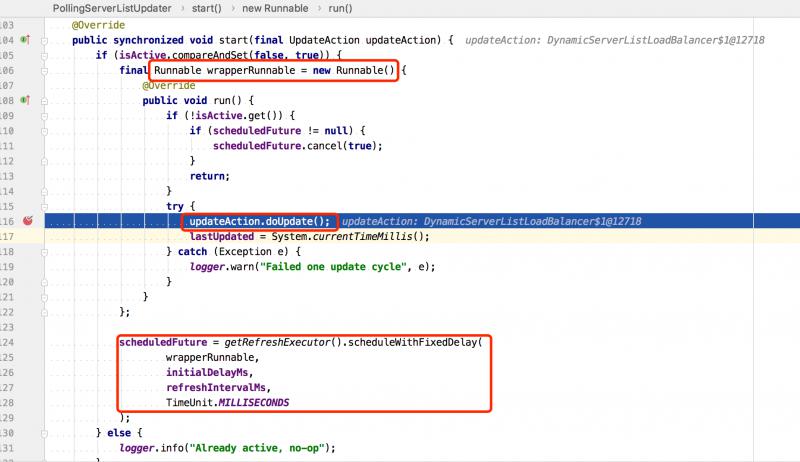
調用到了DyamicServerListLoadBalancer匿名實現類中。
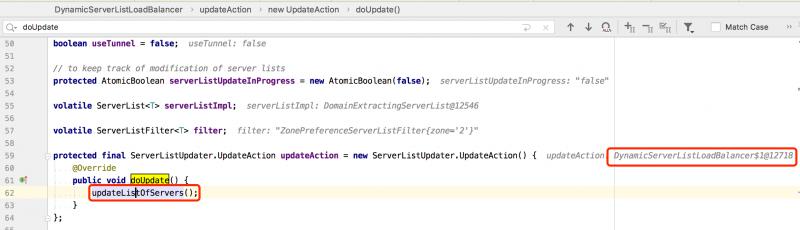
通過DyamicServerListLoadBalancer類調用了 updateListOfServer() 方法更新服務列表,serverListImpl的實現是DiscoveryEnabledNIWSServerList類

在DiscoveryEnabledNIWSServerList類內部會調用 obtainServersViaDiscovery() 方法,其內部通過 EurekaClient 來實現從 Eureka 註冊中心拉取服務列表。
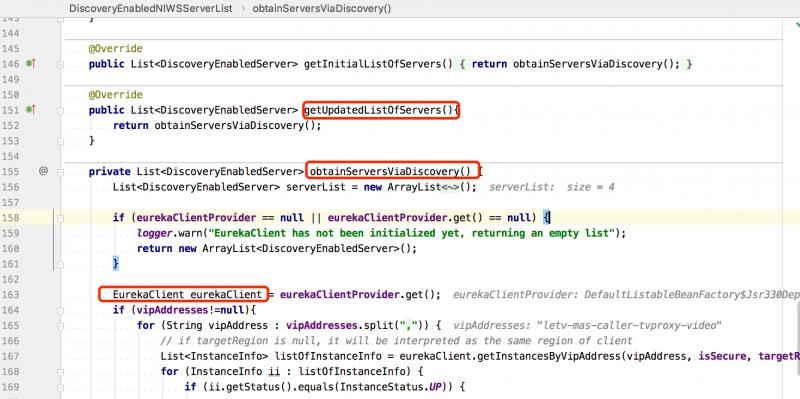
過濾器內部獲取同一機房(zone)的服務列表,先後會調用 ZonePreferenceServerListFilter 和 ZoneAffinityServerListFilter 兩個過濾器實現 zone 的過濾。
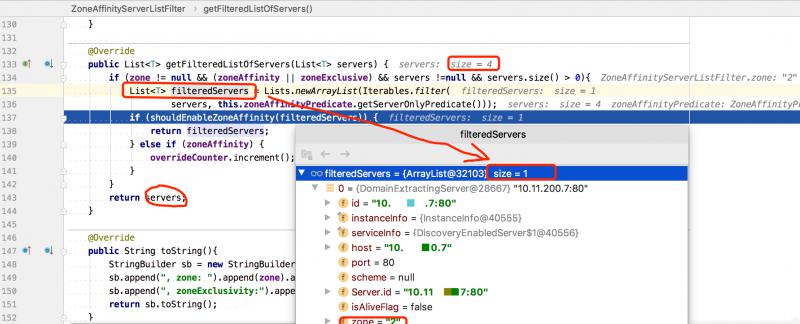
最開始獲取的Servers一共是有4條記錄,根據調試的代碼看,我們是為了獲取 zone 為2的服務,所以得到的結果是一條,即 zone = "2",說明找到了同 zone 服務。
請求介面後會調用到 LoadBalancerContext#getServerFromLoadBalancer(...),內部會調用到ILoadBalancer 具體實現的 chooseServer() 方法,最終會獲取到 zone="2" 里的一個Server。
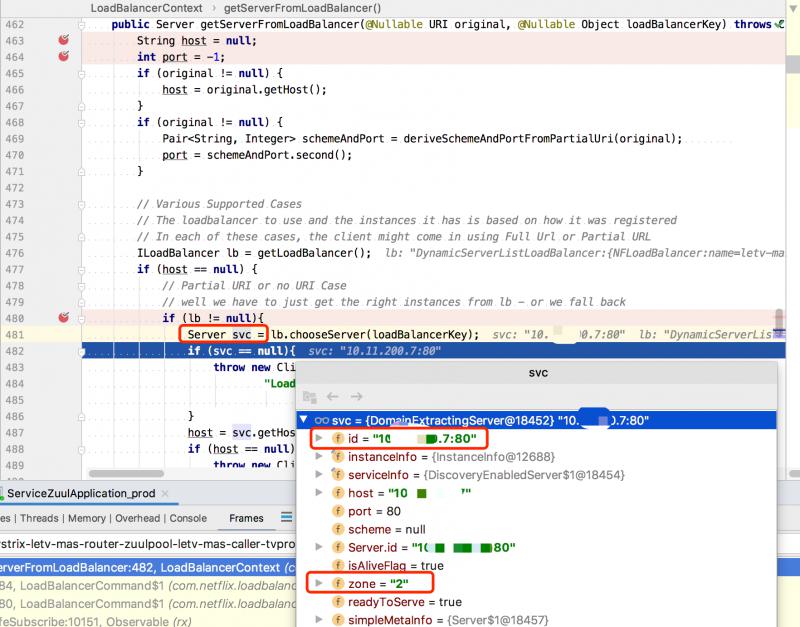
那麼這裡是如何選擇的Server呢?
本地調試時,只配置了已給可用的zone,所以這裡條件滿足會直接調用 super.chooseServer(key) 父類的方法:
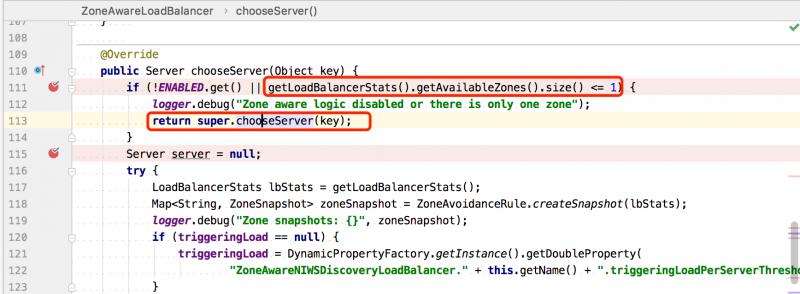
BaseLoadBalancer#chooseServer(...) 父類的選擇Server的方法,其內部通過 IRule#choose(key) 會調用到具體的負載均衡器的實現:
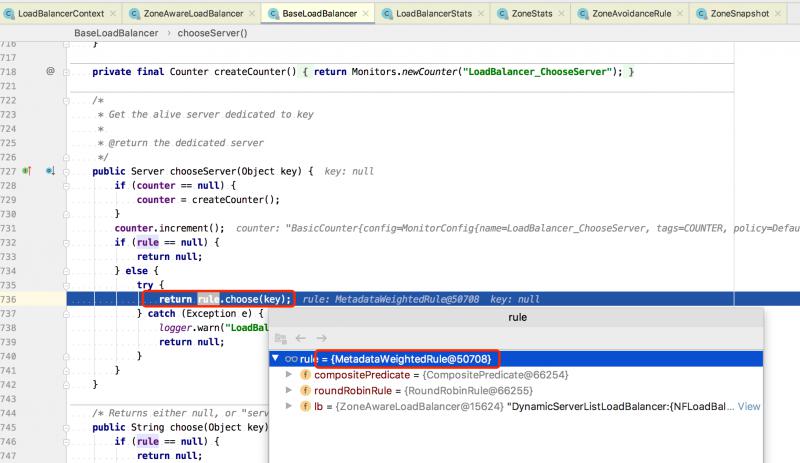
上述截圖中,能看到 MetadataWeightedRule ,這個類是我們自行基於權重負載均衡實現。
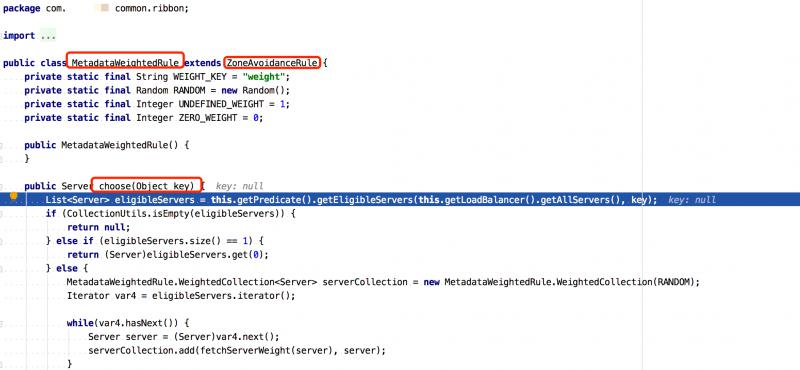
該實現類是繼承了 ZoneAviodanceRule ,目的就是利用了 zone 的概念,所重寫的 choose(Object key) 方法,調用了 this.getPredicate().getEligibleServers(...) 會走同樣的過濾規則獲取到同一機房(zone)下的所有服務列表,然後在基於每個服務配置的權重篩選一個Server。
獲取到 Server 後,拼接介面的URI請求地址 http://IP:PORT/api/.../xxx.json ,通過底層的 OkHttp 實現完成 Http 介面的調用過程。
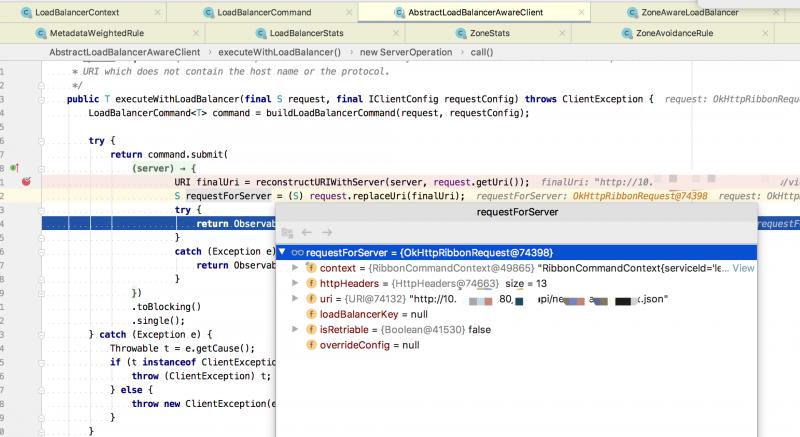
好了,到此基本就分析完了,從網關請求,通過 ribbon 組件從 eureka 註冊中心拉取服務列表,如何基於 zone 分區來實現多數據中心的訪問。
對於 服務註冊,要保證服務能註冊到同一個 zone 內的註冊中心,如果跨 zone 註冊,會導致網路延時較大,出現拉取註冊表,心跳超時等問題。
對於 服務調用,要保證優先調用同一個 zone 內的服務,當無法找到同 zone 或者 同 zone 內的服務不可用時,才會轉向調用其他 zone 里的服務。
本文提到的只是網關到微服務之間的調用,實際項目中,微服務還會調用其他第三方的服務,也要同時考慮到跨機房調用的問題,儘量都讓各服務之間在同機房調用,減少網路延時,提高服務的穩定性。
歡迎關註我的公眾號,掃二維碼關註獲得更多精彩原創文章,與你一同成長~



