
原文首發於個人博客「 "tobe的囈語" 」歡迎大家的訪問收藏啊~ 我們知道,在面對大規模數據的計算和存儲時,有兩種處理思路: 垂直擴展(scale up) :通過升級 單機 的硬體,如 CPU、記憶體、磁碟等,提高電腦的處理能力。 水平擴展(scale out) :通過添加 更多的機器 到分散式系 ...
原文首發於個人博客「tobe的囈語」歡迎大家的訪問收藏啊~
我們知道,在面對大規模數據的計算和存儲時,有兩種處理思路:
- 垂直擴展(scale up):通過升級單機的硬體,如 CPU、記憶體、磁碟等,提高電腦的處理能力。
- 水平擴展(scale out):通過添加更多的機器到分散式系統中,提高整個系統的處理能力。
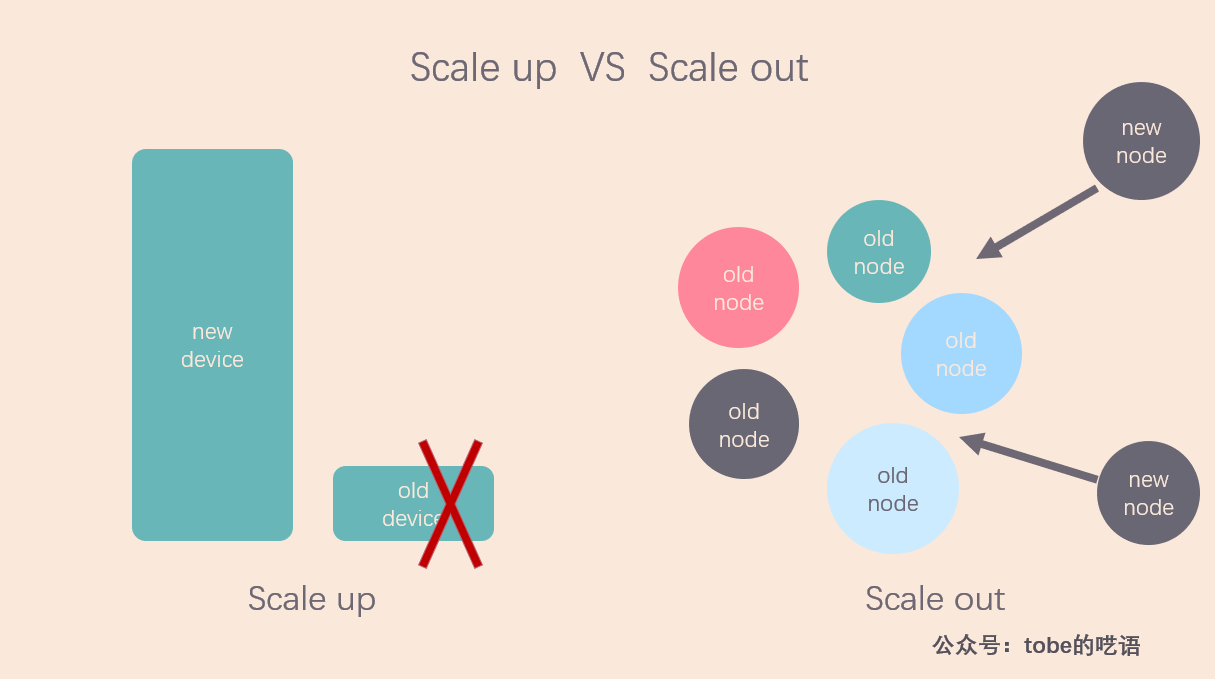
在分散式技術尚未成熟的時候,小型機、中型機、大型機、超級電腦逐步升級的方案幾乎是大型公司的唯一選擇,但是這種垂直擴展是有天花板的,硬體升級的速度遠遠比不上數據規模的增速,即使是超級電腦也無法滿足人們對計算資源的需求。
水平擴展方案,也就是在一個系統里不斷添加機器的方案,就這麼走上了歷史舞臺。這就是現在的分散式技術。
在這篇文章里,我將分別介紹單機系統下的 RAID 存儲技術以及分散式系統下的存儲分佈技術,這兩種技術在思想上有很相近的地方,希望讀者慢慢體會。
RAID
RAID,全稱是Redundant Array of Inexpensive/Independent Disks,也就是磁碟冗餘陣列,這裡的 I 有兩種說法,一種是 Inexpensive,廉價,另一種是Independent ,獨立。所謂 RAID 就是將多塊磁碟組合在一起,對外抽象成一個容量大,讀寫速度高,容錯性好的大型磁碟。
我很喜歡「抽象」這個概念,因為它為我們屏蔽了更底層的細節,比如操作系統中的文件系統,虛擬記憶體等。在我看來,RAID 就是對多個獨立磁碟的抽象。
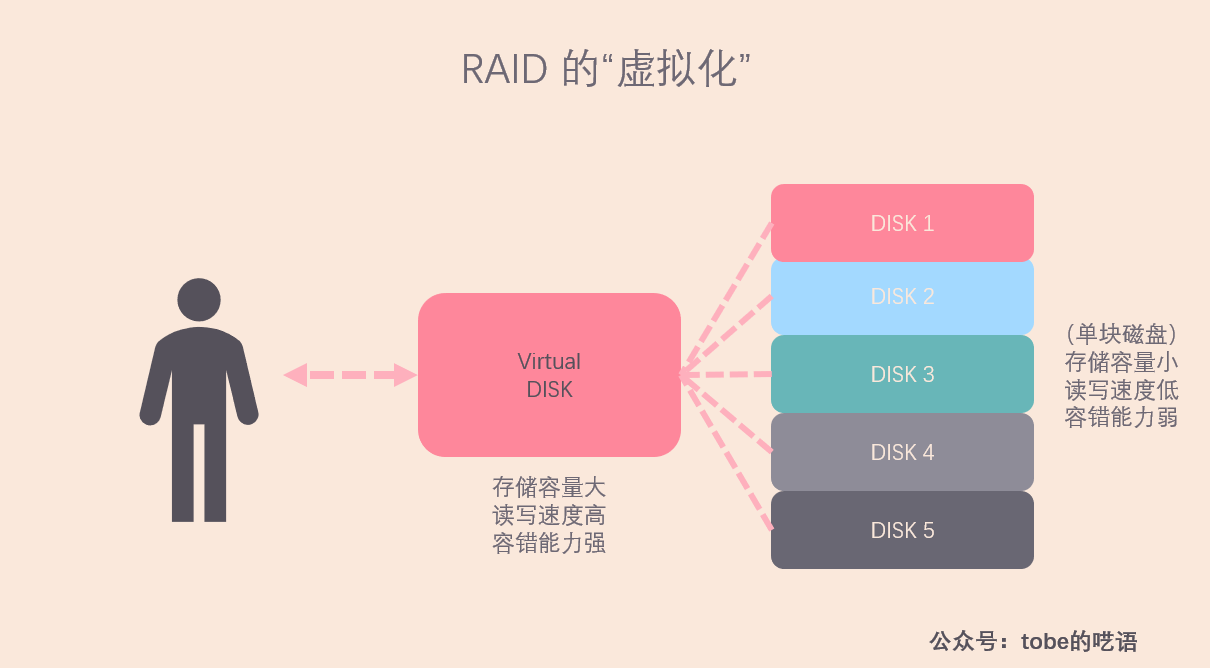
註意,上面的圖裡的三個方面(存儲容量、讀寫速度、數據可靠性)是衡量存儲系統的重要標準,我們在分散式系統里也會提及,不過現在讓我們先來看看常用的 RAID 技術。
RAID 0
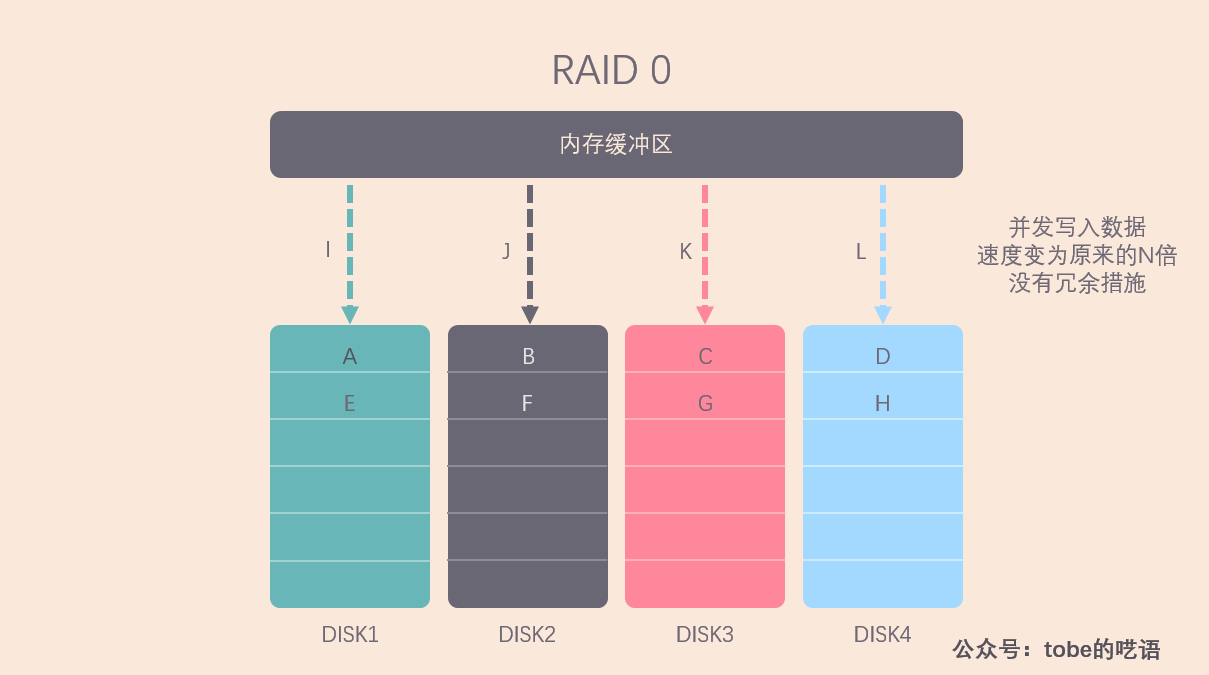
RAID 0 是數據在從記憶體緩衝區寫入磁碟時,根據磁碟的數量,將數據分成 N 份,然後把這些數據併發寫入 N 塊磁碟,每塊磁碟上存儲不同的數據,這樣整體的數據寫入速度是單個磁碟的 N 倍,讀取當然也是併發執行的。
因此 RAID 0 具有極快的數據讀寫速度。但是RAID 0不做數據備份,N塊磁碟中只要有一塊損壞,數據完整性就被破壞,其他磁碟的數據就無法使用了。
RAID 1
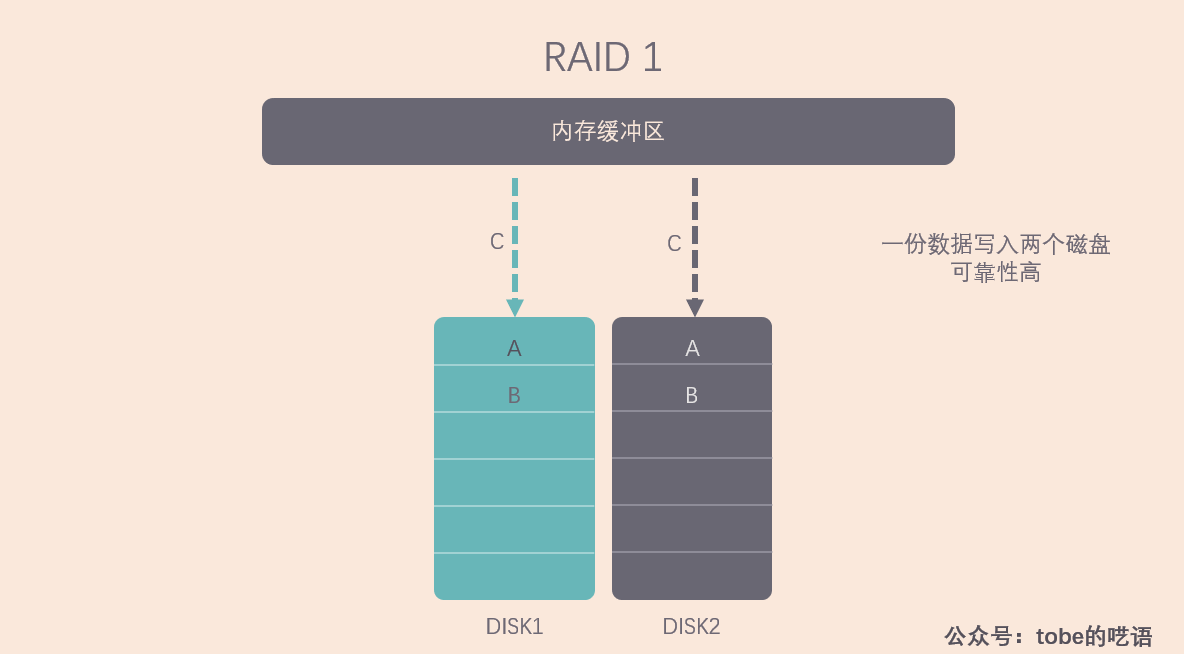
RAID 1 的策略更為簡單,不管你有幾個磁碟,都給我存一樣的數據,這樣數據的可靠性極高,但是寫入速度收到很大影響。
Any read request can be serviced by any drive in the set. If a request is broadcast to every drive in the set, it can be serviced by the drive that accesses the data first (depending on its seek time and rotational latency), improving performance. Sustained read throughput, if the controller or software is optimized for it, approaches the sum of throughputs of every drive in the set, just as for RAID 0. Actual read throughput of most RAID 1 implementations is slower than the fastest drive. Write throughput is always slower because every drive must be updated, and the slowest drive limits the write performance. The array continues to operate as long as at least one drive is functioning.1
這段話意思是說,RAID 1 的讀取速度取決於哪一個硬碟能最先訪問到待讀取的數據,如果軟體上有優化,可以達到 RAID 0 的讀取速度。但是最慢的磁碟限制了寫入速度,因為系統需要等待最慢的磁碟完成寫入並做好檢驗工作。RAID 1 的可靠性好,只要陣列里有任意一塊磁碟還能用,陣列就能繼續工作,而且當新磁碟替代舊磁碟後,系統會自動複製數據。
RAID 10
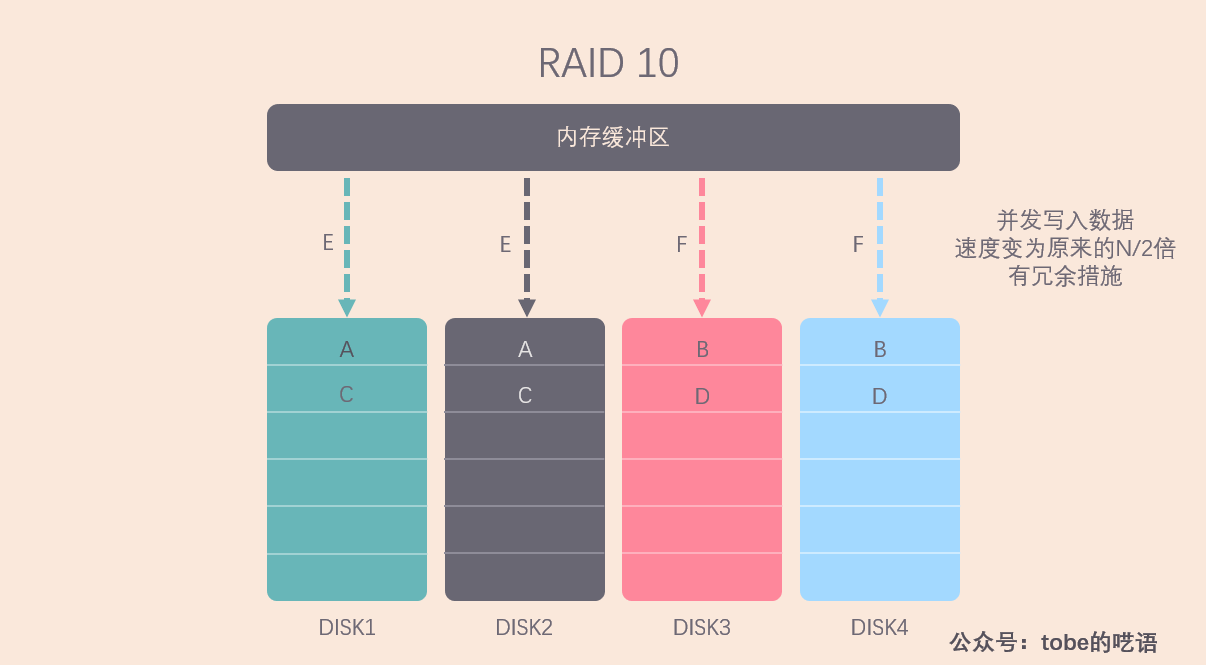
RAID 0 讀寫速度高,但沒有數據冗餘, RAID 1 做了數據備份,但讀寫速度受到制約,所以就需要想辦法結合 RAID 0 和 RAID 1,揚長避短,RAID 10 就這麼出現了。
RAID 10 就是將 N 個磁碟平均分成兩份,這兩份互為鏡像,相當於是 RAID 1,但對於每份磁碟中的 N/2 塊磁碟來說,其存儲方式像 RAID 0 一樣,可以做到併發讀寫。這樣就做到了折中,在讀寫速度和容錯能力上有一個平衡。
我們不難看出來,RAID 10 的磁碟利用率較低,有一半的磁碟都拿來做備份了,著實有些奢侈。
就一般情況而言,伺服器上很少出現同時損壞兩塊磁碟的情況,往往是損壞一塊磁碟的時候,就換上新的磁碟,然後利用恢復技術恢復損壞磁碟上的數據,所以我們可以據此設計一個磁碟利用率更高的方案。
RAID 3 and RAID 5
有了前面的討論,我們可以想到,如果任何一塊磁碟上的數據,都能通過其它 N-1 塊磁碟上的數據恢復出來,不就解決我們的問題了嗎?
校驗機制正好滿足我們的要求。
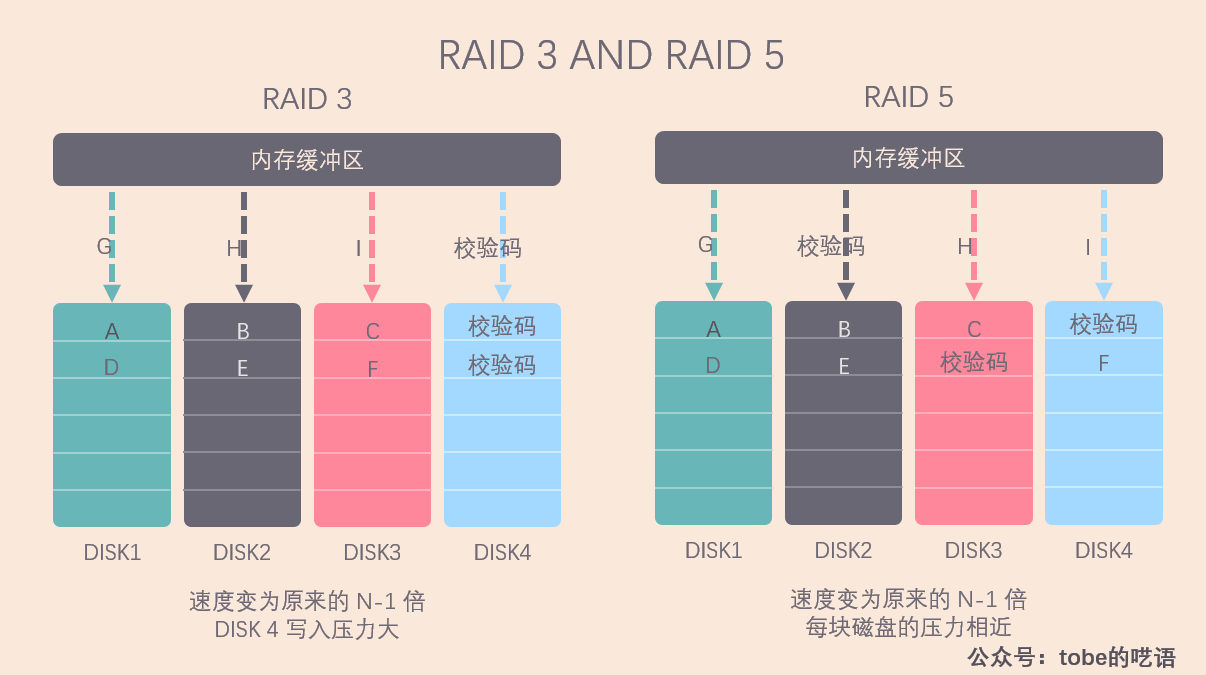
在寫入磁碟的時候,我們把數據分成 N-1 份,併發寫入 N-1 塊磁碟,然後用剩下的一塊磁碟記錄校驗數據,這樣我們就可以容忍任意一塊磁碟的損壞。
根據校驗數據寫入的位置,我們有了兩種方案:
- RAID 3:所有的校驗數據寫在同一塊磁碟上。在數據修改較頻繁的場景下,任何一塊磁碟上數據的修改都會導致校驗盤要重新寫入數據。這會導致校驗盤比其他磁碟更容易損壞,所以 RAID 3 很少在實踐中使用。用專業一點的話來說,就是負載不均衡了。
- RAID 5:校驗數據螺旋式地寫入所有磁碟。看上面的圖就能分辨出這兩種方案的差別,RAID 5 讓每一塊磁碟都承擔一部分的校驗工作,這樣修改校驗數據的壓力也就被分散到了所有的磁碟,做到了我們所期望的負載均衡。因此 RAID 5 是使用更為廣泛的方案。
RAID 6
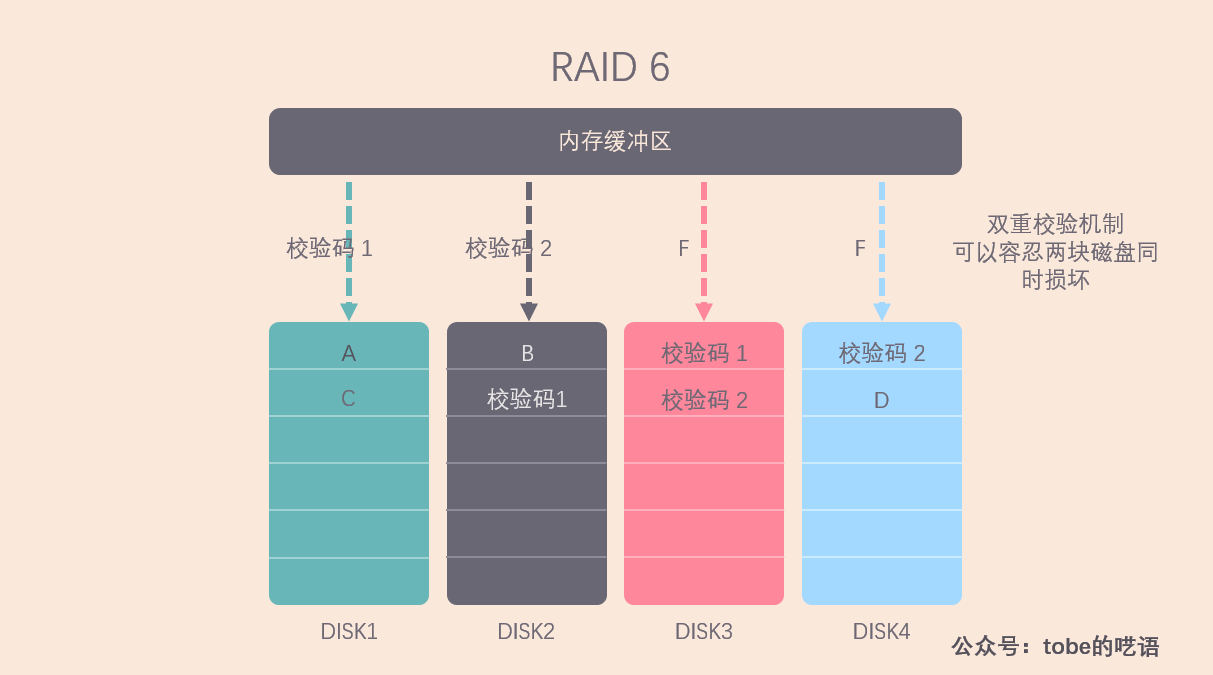
相較於 RAID 5,RAID 6 的可靠性更高,因為 RAID 6 採用了兩種校驗碼螺旋寫入的方案,這樣可以容忍兩塊磁碟同時損壞。
什麼情況下需要這樣的容錯能力?在大型伺服器上,每塊磁碟的容量往往很大,在某一塊磁碟損壞後,即使立馬替換上了新磁碟,也需要很長時間才能把所有數據恢復完畢,那麼在這段時間里,如果有另一塊磁碟損壞,數據就沒辦法恢復了,這是我們不能接受的,因此就需要 RAID 6 來確保數據的完整性。
分散式存儲方案
PS:本文著重於分散式系統的副本與數據分佈的關係,因為這部分的思想與 RAID 有相似之處,關於一致性哈希等問題將單獨寫一篇文章介紹。
分散式系統應對的存儲規模要比單機大很多,但基本思想和設計目標都是一致的:
- 提高系統的吞吐量
- 提高系統的存儲容量
- 利用數據備份,提高系統可靠性
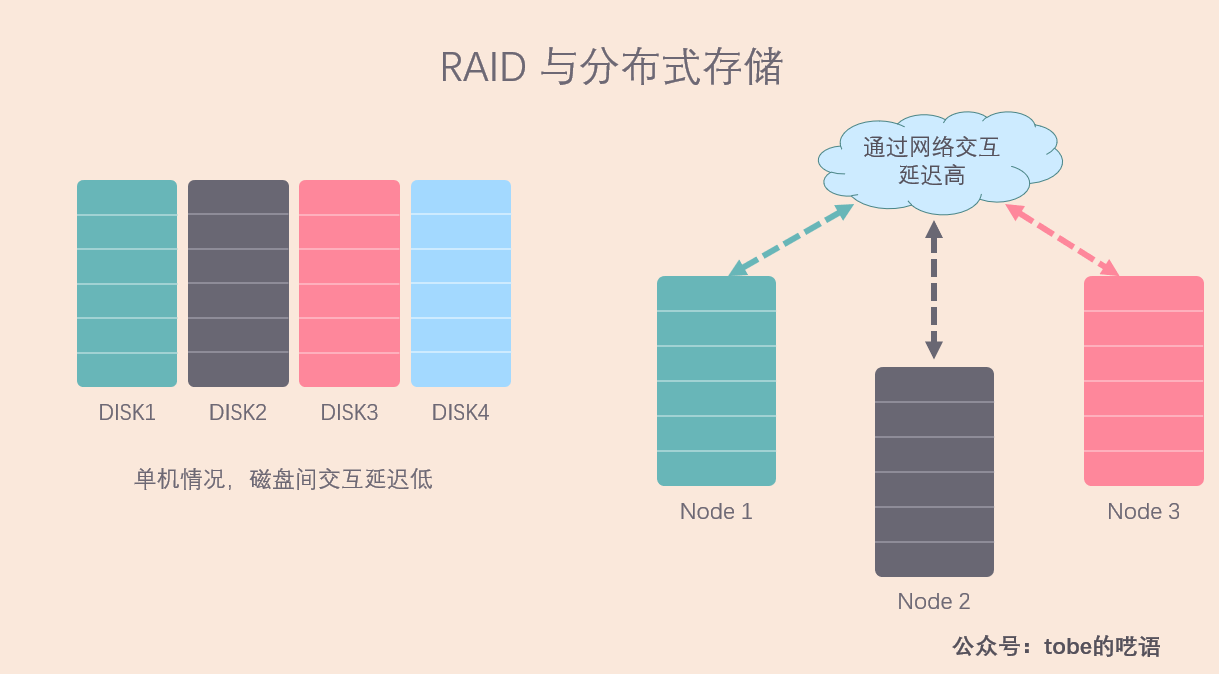
與單機情況不同,分散式系統面臨的問題要多得多,因為伺服器之間的數據是通過網路傳輸,延時較高,甚至可能會出現網路中斷,導致某些機器無法訪問。這對我們的存儲方案有很大影響,比如,我們還能用類似 RAID 5 的校驗方式來做冗餘嗎?
答案是否定的,因為做校驗的成本太高了,一次校驗需要其它 N-1 台機器的響應,一等就是幾十毫秒,效率極低,而且網路負載太大了。相反,RAID 10 的方案看起來更適合現在的情況。
以機器為單位的副本
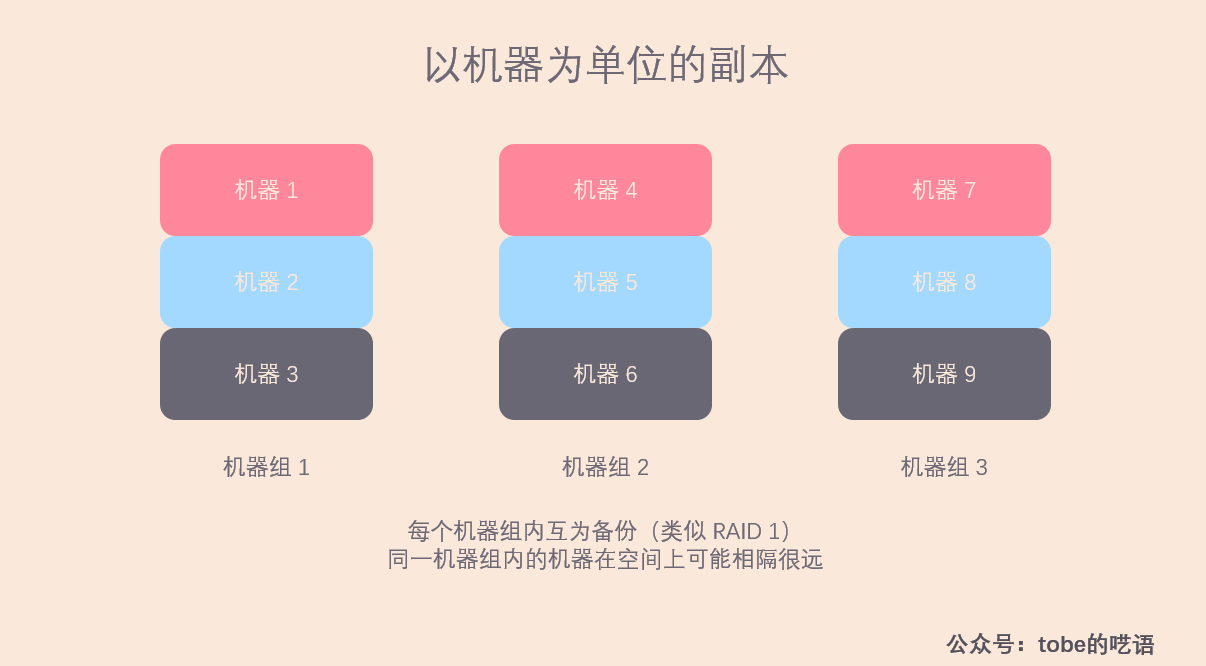
在該方式下,若幹機器互為副本,副本機器之間的數據是完全一樣的,就像 RAID 1 的方案一樣。這種方式的優點就是簡單,但缺點也很明顯:
- 恢複數據的效率低:假如機器 3 磁碟損壞,丟失了所有的數據,於是我們又調度一臺新機器進入該機器組,為了讓該機器儘快提供服務,需要從其他兩台機器上拷貝數據。但是由於網路帶寬的限制,數據恢復的速度慢。
- 可擴展性不高:每個機器組有三台機器,想要擴展,就需要一次加三台機器。
- 不利於系統容錯:一臺機器宕機,讀寫壓力將由剩下的兩台機器承擔,壓力增加了 50 %,很有可能超過單台機器的處理能力。
因此,以機器作為副本單位不適合當前的場景,我們需要尋找其它的途徑。
以數據段為單位的副本
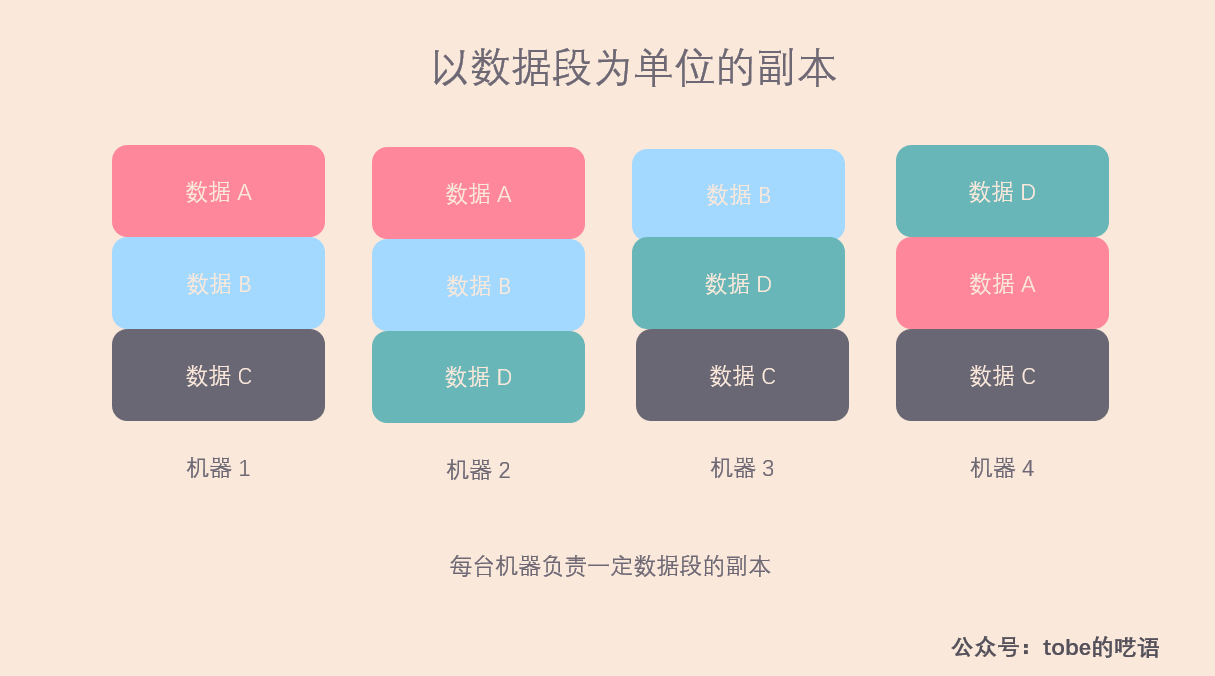
相較於以機器為副本單位,將數據拆分成以數據段為單位作為副本的靈活性更佳,下麵我就用一個更直觀例子來說明該方案的優點。
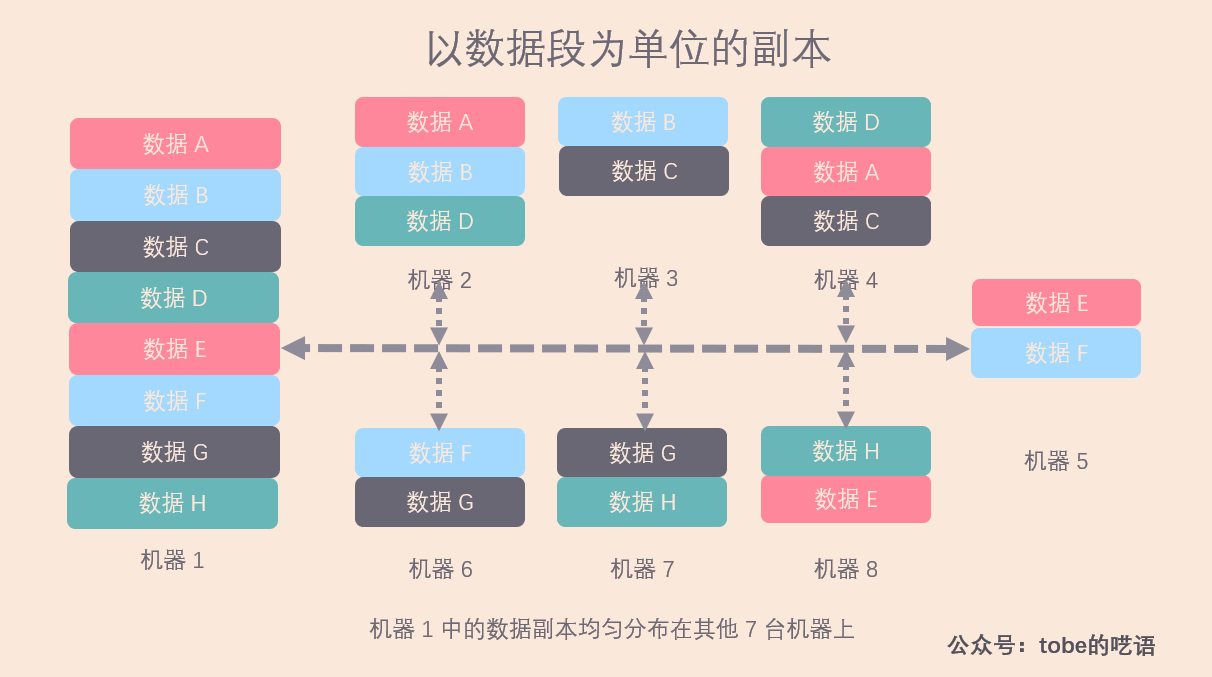
該例子下,機器 1 的所有數據都分佈在其他的 7 台機器上,忽略集群中其他的機器。
這種方案為我們帶來了什麼好處?
- 恢複數據的效率高。假設機器 1 數據丟失,需要重新拷貝所有數據,由於數據分佈在剩下的 7 台機器上,我們可以從剩下的所有機器同時拷貝恢複數據,這樣,即使每台機器都以較低的資源做拷貝工作,也能很快將數據複製完畢。註意,集群越大,每台機器上承擔的工作量就越小,而且實現了負載均衡。
- 集群的可擴展性高。當加入一臺新的機器時,我們只需要從每台機器上遷移 1/8 比例的數據段到新機器上,實現新的負載均衡。
- 系統容錯性高。假設機器 1 宕機,暫時無法提供服務,那麼剩餘 7 台機器的壓力提高 14.3% ,可以接受。
但是這種方案不是沒有問題,因為我們需要一臺伺服器來記錄數據段與機器的對應關係,這台伺服器稱為元數據伺服器。可以想象,隨著集群規模的增長,需要管理的元數據的開銷也會不斷增大,副本的維護難度相應增大,所以現在一種折中的方案是,將某些數據段組成一個數據段分組,以數據段分組為粒度進行副本管理,這樣,可以將副本粒度控制在一個較為合適的範圍。
分散式存儲的副本分佈內容就介紹到這裡了,希望你在看完我的文章之後有所收穫,期待你的贊和轉發!
如果本文對你有幫助,歡迎關註我的公眾號 tobe的囈語 ,帶你深入電腦的世界~ 公眾號後臺回覆關鍵詞【電腦】有驚喜哦~


