
恢復內容開始 1、Hadoop是什麼? Hadoop是一個Apache基金會所開發的分散式系統基礎框架(Hive、Hbase、spark都是基於hadoop架構進行數據存儲)。 主要解決:海量數據存儲和海量數據分析計算問題。 廣義上來說,Hadoop通常是指一個更廣泛的概念-Hadoop生態圈。 2 ...
------------恢復內容開始------------
1、Hadoop是什麼?
- Hadoop是一個Apache基金會所開發的分散式系統基礎框架(Hive、Hbase、spark都是基於hadoop架構進行數據存儲)。
- 主要解決:海量數據存儲和海量數據分析計算問題。
- 廣義上來說,Hadoop通常是指一個更廣泛的概念-Hadoop生態圈。
2、Hadoop發展歷史
1)Lucene框架是Doug Cutting開創的開源軟體,用Java書寫代碼,實現與Google類似的全文搜索功能,他提供全文搜索
引擎架構,包括完整的查詢引擎和索引引擎。
2)2001年年底 Lucene成為Apache基金會的一個子項目。
3)對於海量數據的場景,Lucene面對與Google同樣的困難,存儲數據困難,檢索速度慢。
4)學習和模仿Google解決這些問題的辦法:微型版Nutch。
5)可以說Google是Hadoop的思想之源(Google在大數據方面的三篇論文)。
GFS-->HDFS (G代表Google) Hadoop分散式文件系統
Map-Reduce-->MR
BigTable-->HBase
6)2003-2004 Google公開了部分GFS和MapReduce思想的細節,以此為基礎Doug Cutting等人用了2年
業餘時間實現了DFS和MapReduce機制,使Nutch性能飆升。
7)2005年Hadoop成為Lucene子項目Nuntch的一部分正式引入Apache基金會
8)2006年3月,Map-Reduce和Nutch Distributed File System(NDFS)分別被納入Hadoop的項目中
9)名字來源於Doug Cutting兒子的玩具大象
10)Hadoop就此誕生並迅速發展,標志著大數據時代的來臨
## 3.Hadoop的優勢
1)高可靠性:Hadoop底層維護多個數據副本,所有即使Hadoop某個計算元素出現故障,也不會導致數據的丟失。
2)高擴展性:在集群間分配任務數據,可方便的擴展數以千計的節點。
3)高效性:在MapReduce的思想下,Hadoop的並行工作的,以加快任務處理速度
4)高容錯性:能夠自動將失敗的任務重新分配
### 1.Hadoop組成(解決數據和計算問題)
1)Hadoop1.x和Hadoop2.x的區別
1)Hadoop1.x組成
MapReduce(計算和資源調度)
HDFS(數據存儲)
Common(輔助工具)
2)Hadoop2.x組成
MapReduce(計算)
Yarn(資源調度)
HDFS(數據存儲)
Common(輔助工具)
2.HDFS架構概述
1)NameNode(nn):存儲文件的元數據,如文件名,文件目錄結構,文件屬性(生成時間、副本數、文件許可權),
以及每個文件的塊列表和塊所在的DataNode等。(目錄)
2)DataNode(dn):在本地文件系統中存儲文件塊的數據,以及數據的校驗和(目錄下實實在在的數據)
3)Secondary NameNode(2nn):用來監控HDFS狀態的輔助後臺,每個一段時間間獲取HDFS元數據的快照
3.Yarn 架構概述
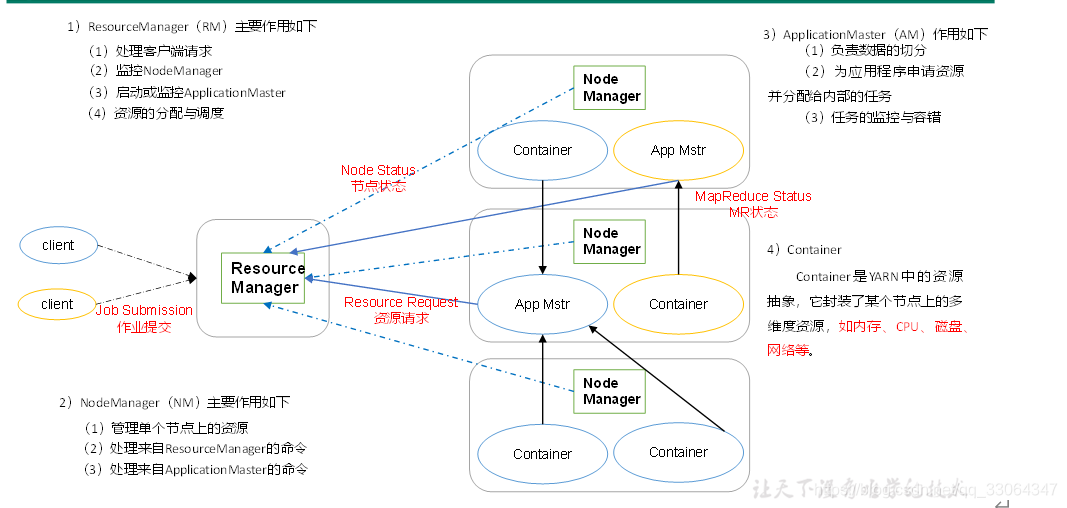
1)ResourceManager(RM)主要作用:
(1)處理客戶端請求
(2)監控NodeManager
(3)啟動或監控ApplicationMaster
(4)資源的分配與調度
2)NodeManger(NM)
(1)管理單個節點上的資源
(2)處理來自ResourceManager的命令
(3)處理來自ApplicationMaster的命令
3)Application
(1)負責數據的切分
(2)為應用程式申請資源並分配給內部任務
(3)任務的監控與容錯
4)Container
(1)Container是Yarn中的資源抽象,它是封裝了某個節點上的多維度資源,如記憶體,CPU,磁碟,網路
4.MapReduce架構概述
1)MapReduce將計算過程分為兩個階段:Map和Reduce
(1)Map階段並行處理輸入數據
(2)Reduce階段是對Map結果進行彙總
## 6.大數據技術生態體系
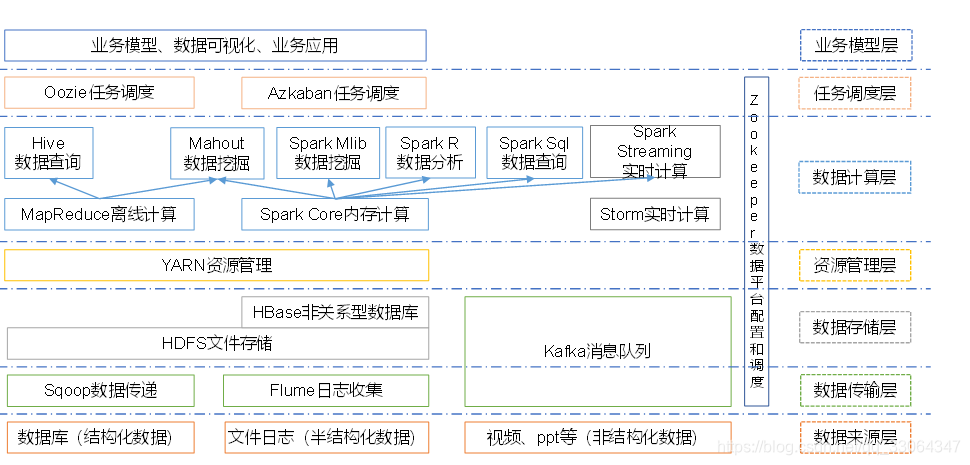
1)Sqoop:Sqoop是一款開源的工具,主要用於在Hadoop、Hive與傳統的資料庫(MySql)間進行數據的傳遞,可以將一個關係型資料庫
(例如 :MySQL,Oracle 等)中的數據導進到Hadoop的HDFS中,也可以將HDFS的數據導進到關係型資料庫中。
2)Flume:Flume是Cloudera提供的一個高可用的,高可靠的,分散式的海量日誌採集、聚合和傳輸的系統,Flume支持在日誌系統中
定製各類數據發送方,用於收集數據;同時,Flume提供對數據進行簡單處理,並寫到各種數據接受方(可定製)的能力。
3)Kafka:Kafka是一種高吞吐量的分散式發佈訂閱消息系統,有如下特性:
(1)通過O(1)的磁碟數據結構提供消息的持久化,這種結構對於即使數以TB的消息存儲也能夠保持長時間的穩定性能。
(2)高吞吐量:即使是非常普通的硬體Kafka也可以支持每秒數百萬的消息。
(3)支持通過Kafka伺服器和消費機集群來分區消息。
(4)支持Hadoop並行數據載入。
4)Storm:Storm用於“連續計算”,對數據流做連續查詢,在計算時就將結果以流的形式輸出給用戶。
5)Spark:Spark是當前最流行的開源大數據記憶體計算框架。可以基於Hadoop上存儲的大數據進行計算。
6)Oozie:Oozie是一個管理Hdoop作業(job)的工作流程調度管理系統。
7)Hbase:HBase是一個分散式的、面向列的開源資料庫。HBase不同於一般的關係資料庫,它是一個適合於非結構化數據存儲的資料庫
8)Hive:Hive是基於Hadoop的一個數據倉庫工具,可以將結構化的數據文件映射為一張資料庫表,並提供簡單的SQL查詢功能,可以將
SQL語句轉換為MapReduce任務進行運行。 其優點是學習成本低,可以通過類SQL語句快速實現簡單的
MapReduce統計,不必開發專門的MapReduce應用,十分適合數據倉庫的統計分析。
10)R語言:R是用於統計分析、繪圖的語言和操作環境。R是屬於GNU系統的一個自由、免費、源代碼開放的軟體,它是一個用於
統計計算和統計製圖的優秀工具。
11)Mahout:Apache Mahout是個可擴展的機器學習和數據挖掘庫。
12)ZooKeeper:Zookeeper是Google的Chubby一個開源的實現。它是一個針對大型分散式系統的可靠協調系統,
提供的功能包括:配置維護、名字服務、 分散式同步、組服務等。ZooKeeper的目標就是封裝好複雜易出錯的關鍵服務,
將簡單易用的介面和性能高效、功能穩定的系統提供給用戶
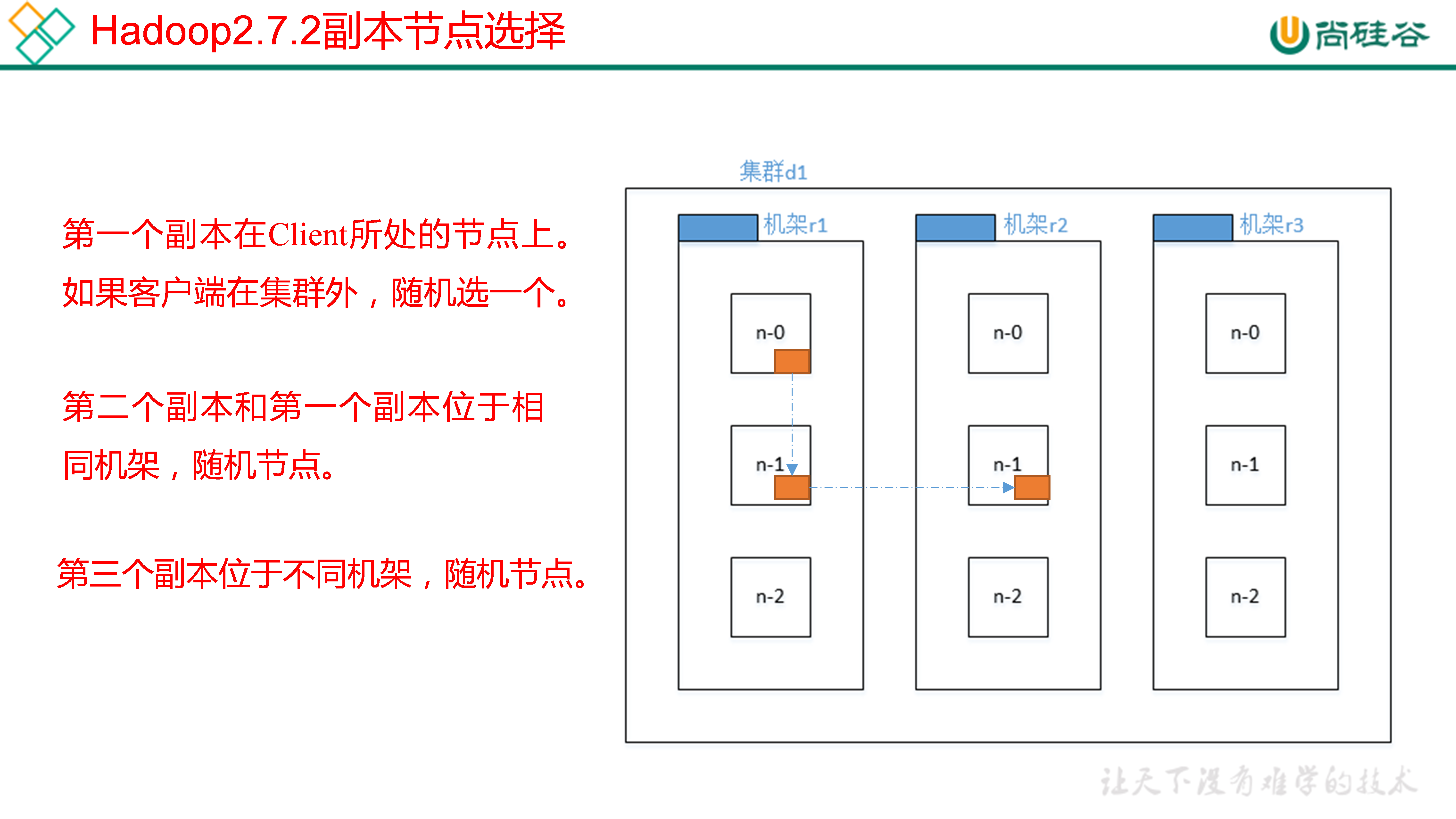
## 7.推薦系統項目架構
 述](https://img-blog.csdnimg.cn/20200218231858193.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3FxXzMzMDY0MzQ3,size_16,color_FFFFFF,t_70)
述](https://img-blog.csdnimg.cn/20200218231858193.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3FxXzMzMDY0MzQ3,size_16,color_FFFFFF,t_70)
------------恢復內容結束------------


