
本文是自己對MySQL的 索引的理解,如有錯誤,還望不吝指出。 1 索引 索引這兩個字著實有些太泛,而在我的理解中,其就是一個查字典的過程,比方說現在我們要從一本字典中查一個 字,那麼我們可以從目錄中的 字母找到這個 字,發現在 頁,然後翻到 就可以看到關於 這個的解釋、用法等。 可以看到我們不是從 ...
本文是自己對MySQL的
InnoDB索引的理解,如有錯誤,還望不吝指出。
1 索引
索引這兩個字著實有些太泛,而在我的理解中,其就是一個查字典的過程,比方說現在我們要從一本字典中查一個牛字,那麼我們可以從目錄中的n字母找到這個牛字,發現在164頁,然後翻到164頁就可以看到關於牛這個的解釋、用法等。
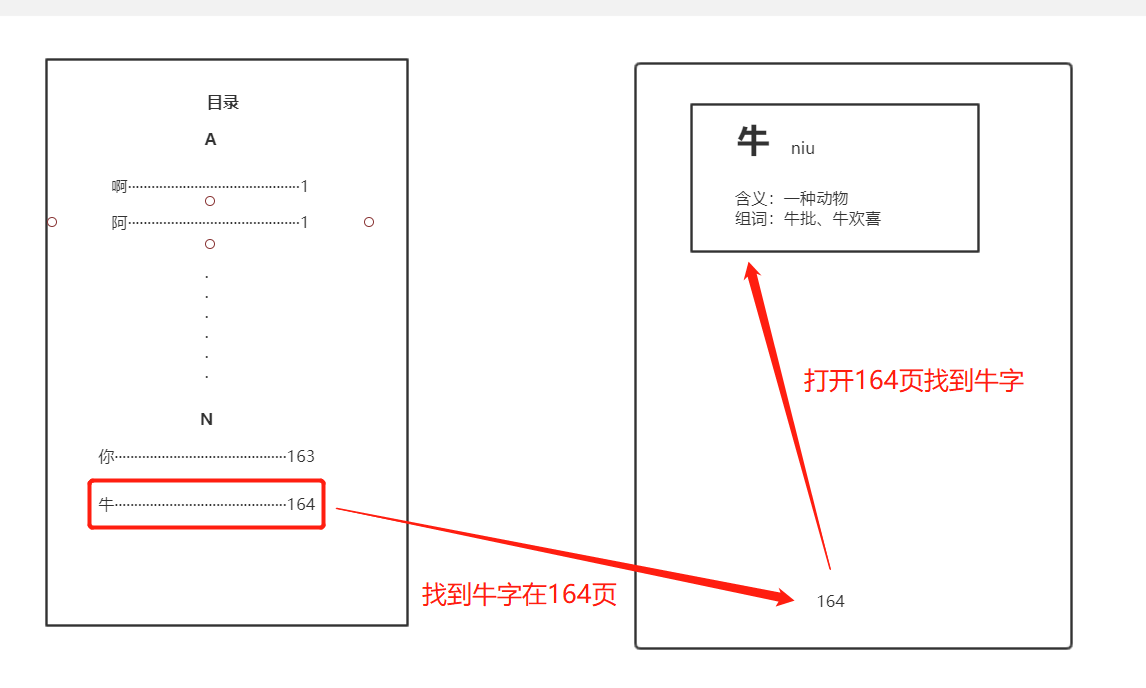
可以看到我們不是從第一頁開始一頁一頁的找,而是先從目錄中根據拼音開頭找,找到之後翻到其對應的頁數就找到了我們所需要的牛字。在這整個過程中,這個目錄的字母就是我們所說的索引。我們查找數據的時候先通過這個目錄找到對應記錄的地址,再去這個地址找到我們所需要的數據,這個過程相比我們從頭找到尾的效率要高許多,這就是索引的作用——提高性能。
接下來所講的內容如果沒有備註則都是以InnoDB為主。
2 索引的類型
在MySQL的InnoDB引擎中,最常見的索引就是B-Tree索引和Hash索引。
B-Tree索引:B-Tree索引是一種通用的叫法,在不同的儲存引擎中可能有不同的實現方式,而在InnoDB中則是用B+Tree來實現,跟普通的的B-Tree不同的是B+Tree只有在葉子節點才存放數據,在非葉子節點中只是存放一個Key值和節點的引用,具體關B+Tree索引我們放在下麵詳細講,普通的索引用的就是B+Tree。(以前會把B-Tree讀成B減樹,暴露了自己文盲的事實,正確的讀法應該是B樹,中間的-是杠不是減,B+Tree則是讀成B加樹)Hash索引:意思就是講欄位的值經過一個Hash演算法之後得到一個Hash值,再將這個Hash值以K-V的形式寫入到一個Hash表中,key就是這個hash值,value則是我們所需要的數據鏈表,類似於Java中HashMap的實現,使用鏈表的原因是因為可能演算法的一些問題而導致哈希衝突的問題。這種索引是十分迅速的,相對於B+Tree中依賴樹高度的O(logN),其時間複雜度為O(1),既然如此迅速,為什麼InnoDB還是選擇B+Tree作為預設的索引類型?因為其雖然快速,但是還是有許多缺點:- 需要額外的列來儲存
hash值:比方說我們在表中有url列,用普通索引滿足不了性能要求,我們可以使用hash索引,增加一個url_hash列來儲存其hash值,那麼每次我們查詢的時候就會變成where url_hash = hash("www.baidu.com") and url = www.baidu.com,這樣的查詢效率可以有很大的提升,但是付出的代價是多一列的維護空間。 - 不能使用例如
limit,order by等數據範圍操作:因為中間還要經過一個hash演算法,所以這種索引在這些方面的表現十分不理想,在這方面B+Tree的表現則十分的優異,平均性能來說還是B+Tree更高,況且對於平常的需求來說範圍數據的查詢要更多一些。
- 需要額外的列來儲存
這兩種算是比較常見的索引類型,除此之外還有一種全文索引,可以實現搜索引擎類似的功能,但還沒見人用過,便不加瞭解。
3 B+Tree的結構
首先先看看B+Tree是怎麼出現的。
在一開始的時候使用的是平衡二叉樹作為索引樹,但是隨著數據量的增大二叉樹的表現有點疲軟,後來便出現的一種新的結構叫作B-Tree,這種數據結構有多個子節點(不再是固定兩個),而在每個節點上面都存著數據和其他節點的引用,很大程度上解決了二叉樹帶來的效率問題,然而時間再次推進,B-Tree的表現也逐漸下滑,此時則出現了一種新的實現方式——B+Tree。
關於B+Tree,我們先看一個圖。
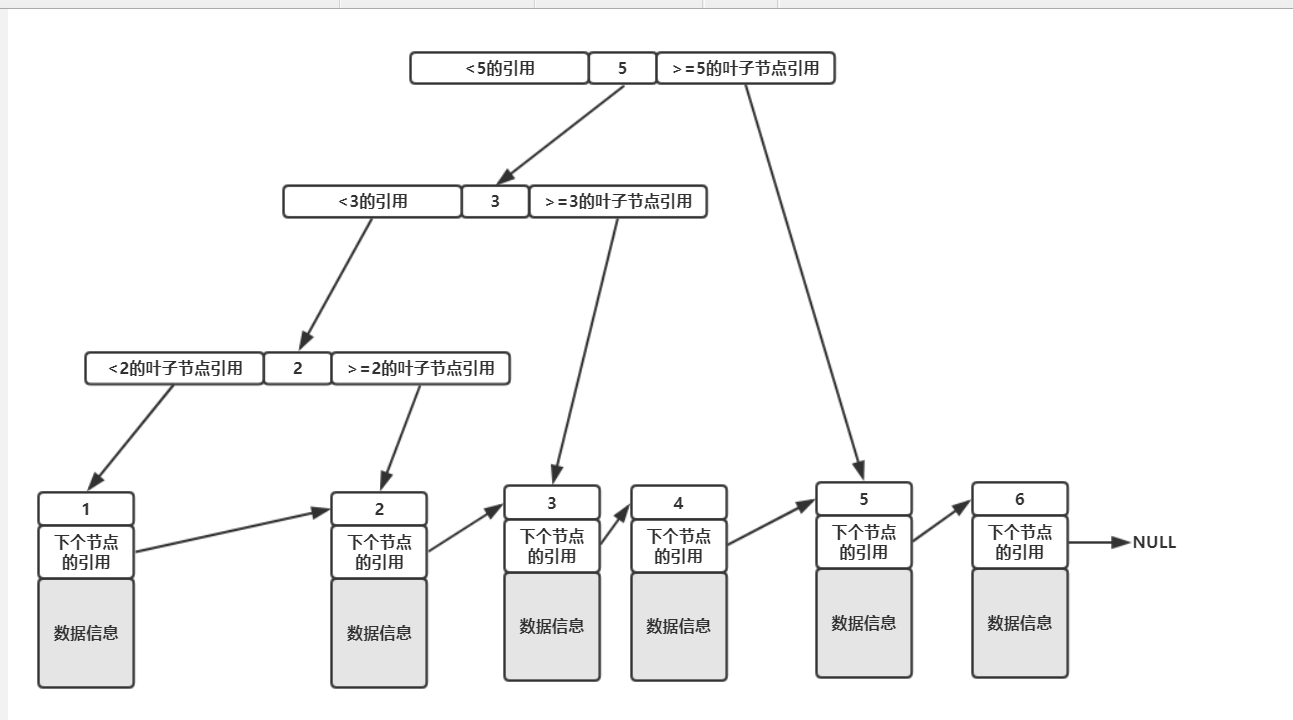
如上圖,我們存儲的數據是1、2、3、4、5、6,所有的數據都在葉子節點中,所謂的葉子節點就是上圖中最下層真正存放數據的節點,而上面那些只存了key和引用的則稱之為非葉子節點。
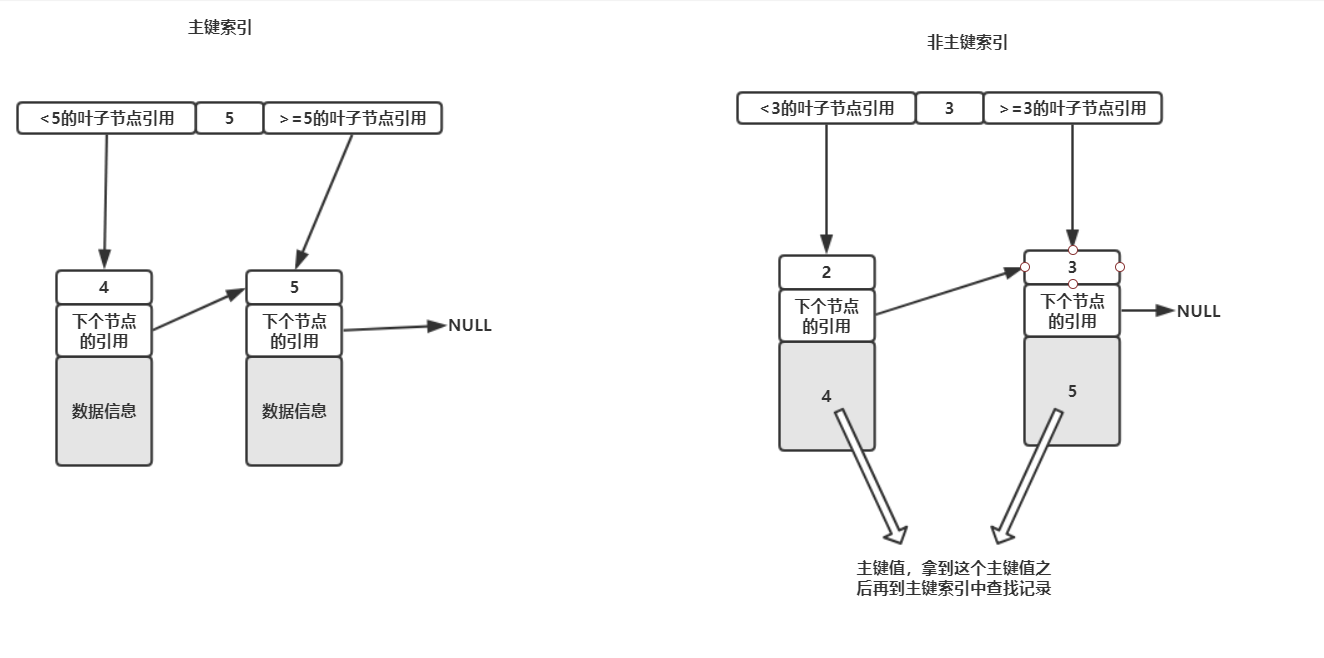
這裡需要註意的是,在InnoDB中,只有主鍵索引的葉子節點存放才是真正的數據信息,其他列的索引在葉子節點中存放的數據信息是主鍵的值,也就是說如果我們使用的是普通的索引,那麼其查找的過程為:
在使用的索引樹(有多少個索引就有多少棵樹)中進行查找,找到了對應的葉子節點之後拿到其儲存的主鍵值,再去主鍵索引樹中查找對應主鍵的葉子節點的數據信息,而一般把通過主鍵去磁碟中讀取數據的操作叫做'回表'。
主鍵索引和普通索引可以結合下圖理解
這就是InnoDB中B+Tree的實現方式,跟普通的B-Tree相比有了穩定的性能,並且在範圍查詢(比方說id<10)方面表現的更加優異。如上所說,B-Tree的結構直接把數據的信息放在節點中,沒有是否葉子節點之分,查到之後就立馬返回,如下: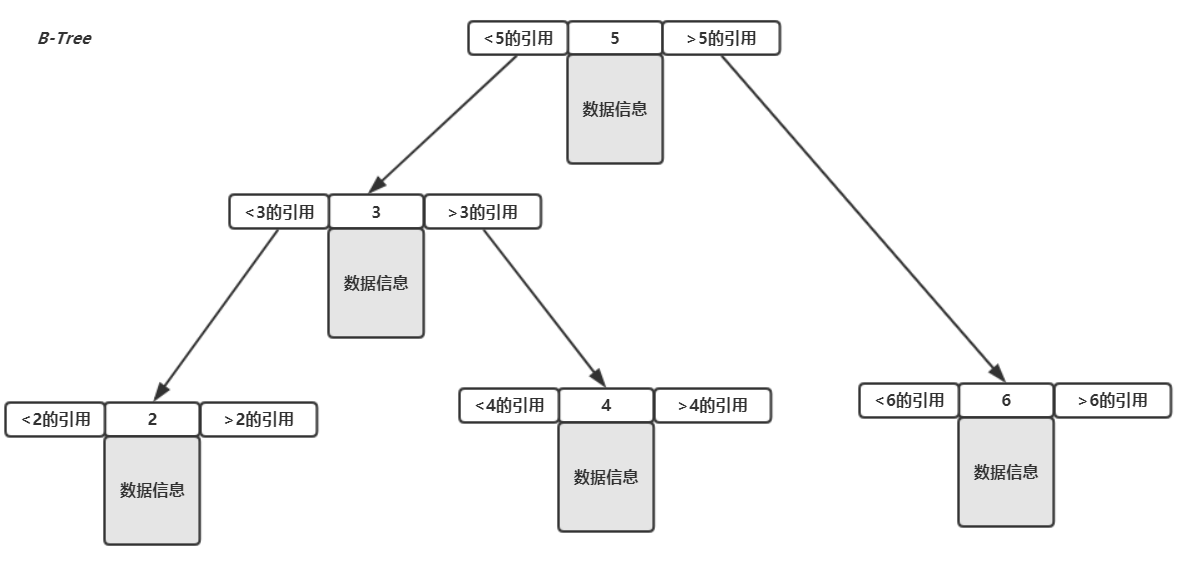
4 聚簇索引和非聚簇索引
聚簇索引並非一種索引類型而是一種儲存方式,表示索引的鍵值對和臨近的數據行儲存在一起,在物理的儲存順序是有序的,在InooDB中,主鍵索引就是聚簇索引的實現。
由於數據行只有一顆索引樹有存,所以也就只有一個聚簇索引,也就是說除了主鍵索引是聚簇索引之外,其他列的索引都是非聚簇索引。而聚簇索引的儲存特性也就決定了我們在查到範圍數據比如limit 10這種操作的時候能夠進行順序IO而非隨機IO從而提升了查找的效率。
當然有優必有劣,聚簇索引的儲存方式也就決定了主鍵只有在遞增的時候發揮得比較好,主鍵是遞增的,每次插入時往上次插入位置的下一個位置插入就行(因為新增的主鍵一定比之前的大),如果頁滿了就插入下一頁,但是如果主鍵是不規則的,譬如UUID來做主鍵,由於其每次插入的主鍵不一定比之前的大,那麼則要進行比較從而進行數據的移動,需要花費的時間和空間要更多一些,並且如果插入一個飽滿的頁中就會引發列分裂從而造成空間碎片。
5 複合索引和覆蓋索引
首先我們得知道這兩個不是同一個概念。
複合索引:表示在一個索引中使用到了多個列,這個索引在記憶體中的排序則是依照列在索引的順序來決定的。比方說複合索引
idx_userId_sex_age('user_id', 'sex', 'age'),我們在使用where user_id = '1'的時候會到user_id的索引,使用where user_id = '1' and sex = '1'的時候會用到user_id和sex兩個列的索引,也就是說只有當首碼列出現了再用此列索引才有效,如where sex = '1'或者where sex = '1' and age = '11'都不會用到索引idx_userId_sex_age,因為當前的首碼列是user_id。覆蓋索引:指的是當某個索引包含查詢所需要的所有欄位的時候,這個時候找到記錄之後則不再去主鍵樹中查找數據,而是直接返回索引包含的欄位,只在記憶體操作而不進行IO,可以很大程度上提升效率,使用覆蓋索引的時候
explain中的extra會出現using index,如下圖。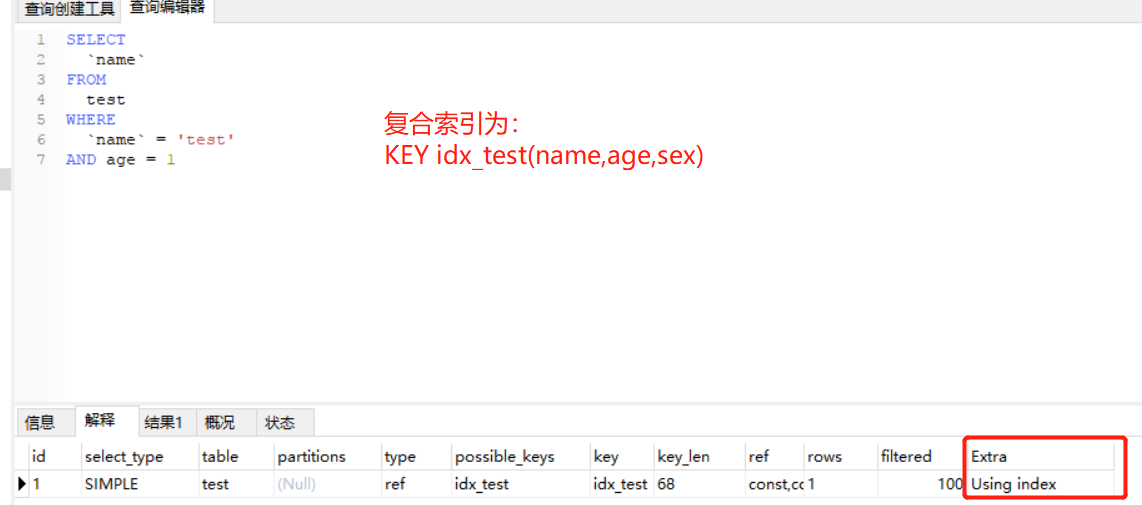
另外,使用覆蓋索引可以實現延遲關聯,從而提升查詢的效率(前提是使用覆蓋索引過濾的數據足夠多),比方說現在有一個SQL:
select * from user_info where user_number = '123' and user_name like '%三%'; 在user_info表中有複合索引(user_number, user_name),上面的寫法的執行過程為:
- 從索引樹中找到
user_number='123'的所有主鍵(user_name為全模糊,不會用到索引),註意這裡還沒執行user_name like '%三%'的操作。- 根據這些主鍵從主鍵索引中找到對應的數據行,將這些數據行從磁碟載入到記憶體中
- 載入完成之後,從這些數據行中篩選出
user_name like '%三%'的數據,將這些數據返回
這是正常的執行過程,但是我們可以改寫這個SQL,讓其變成使用覆蓋索引的形式:
SELECT
*
FROM
user_info
INNER JOIN (
SELECT
id
FROM
user_info
WHERE
user_number = '123'
AND user_name LIKE '%三%'
) t ON user_info.id = t.id; 這樣臨時表t則是使用覆蓋索引生成的記錄,是在記憶體操作,註意由於索引的葉子節點存儲的是主鍵值,所以使用主鍵值的話也能用到覆蓋索引。
這個寫法跟上面不同的地方在於,由於使用了覆蓋索引,所以對於user_number和user_name的條件過濾都是在記憶體中進行的,在記憶體過濾完成之後將拿到的主鍵值再去主鍵索引取數據行。跟第一種寫法的效率區別則是在於覆蓋索引能夠過濾多少條數據。
拿這兩個SQL舉個例子,假設在user_info表中user_number='123'的數據有10W條,user_name中包含'三'的數據有200條,那麼如果是第一種寫法,則有:
從索引中拿到
10W條user_number='123'的主鍵值到主鍵索引中拿到10W條數據行然後載入到記憶體中,再從記憶體中的10W條數據中找出user_name包含'三'的200條數據。
而如果是第二種寫法,則變成了:
先在索引中找到
user_number='123'的節點,然後再從這些節點中找出user_name包含'三'的200個主鍵值,註意到目前為止都是記憶體操作還沒進行IO,然後根據這200個主鍵值從磁碟載入200條數據數據行到記憶體中返回。
對比可以清楚的看到,第一種寫法進行了10W數據的IO再過濾,而使用覆蓋索引的方式則只進行200條數據的IO,性能的提升肯定是非常大的,這種使用覆蓋索引來提升性能的方式就叫做'延遲關聯'。當然,性能的提升決定於覆蓋索引能夠過濾的數據行數,如果上面的例子中user_name包含'三'的記錄有9W條,那麼此時'延遲關聯'的寫法提升就沒那麼明顯了。
6 Extra中的一些信息
最後講下MySQL的explain中Extra的using where、using index和using index condition。
using where:表示使用到了除使用索引列外的條件進行過濾,需要註意的是如果使用的是複合索引,那麽條件中不是該複合索引的列的話則
extra中會出現using where,即便後面的條件也是一個索引(但在當前查詢中沒有使用到)。
另外,using where不一定會進行回表,例如using where;using index同時出現的時候則表示,用到了覆蓋索引,並且where的條件中還有該覆蓋索引的其他列,但不是前導列,此時會在覆蓋索引的返回數據上進行過濾,而不再訪問數據行,這種情況下不會進行回表。using index:表示用到了覆蓋索引。using index condition:表示不使用到覆蓋索引的情況下,用到了複合索引中的其他非前導列作為查詢的條件。比方說複合索引為(user_id, name, age),SQL為:select * from user where user_id = 1 and age = 1 and sex = 1;
此時由於age不是前導列,但為複合索引的其中一列,並且查詢的是所有列,並不會用到覆蓋索引,所以是index condition;using where而不是或者using index,其中using where是因為 sex = 1這個條件,如果沒有的話則只有using index condition。
註意:using index condition用索引非前導列的條件(比方說上方的age)時,這部分的條件篩選是在記憶體中進行,而不是回表返回數據行之後再執行這個過濾條件。如上方的sql中,其順序就是先找到user_id = 1的索引記錄,然後在這些記錄中過濾出age = 1的記錄,到這裡都是記憶體操作,再通過回表返回的數據行中過濾sex = 1的數據,所以using index condition的過濾時間是發生在回表之前。
參考:《高性能MySQL》第三版


