
1、何為explain執行計劃? 使用explain關鍵字可以模擬優化器執行SQL語句,從而知道MySQL是如何使用索引來處理你的SQL查詢語句以及連接表,可以分析查詢語句或是結構的性能瓶頸,幫助我們選擇更好的索引和寫出更優化的查詢語句。(說白了,就是優化SQL的工具) 2、如何使用explain? ...
1、何為explain執行計劃?
使用explain關鍵字可以模擬優化器執行SQL語句,從而知道MySQL是如何使用索引來處理你的SQL查詢語句以及連接表,可以分析查詢語句或是結構的性能瓶頸,幫助我們選擇更好的索引和寫出更優化的查詢語句。(說白了,就是優化SQL的工具)
2、如何使用explain?
在你的SQL查詢語句前加上 explain 即可,如explain select * from table,MySQL會在查詢上設置一個標記,執行查詢時,會返回執行計劃的信息,而不是執行這條SQL(如果 from 中包含子查詢,仍會執行該子查詢,將結果放入臨時表)。
3、使用explain的例子
需要使用三張表,分別為 actor 演員表,film 電影表,film_actor 電影-演員關聯表。
CREATE TABLE `actor` (
`id` int(11) NOT NULL COMMENT '主鍵id',
`name` varchar(45) DEFAULT NULL COMMENT '演員名稱',
`update_time` datetime DEFAULT NULL COMMENT '修改時間',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
insert into `actor` (`id`, `name`, `update_time`) values('1','a','2020-02-11 22:56:00');
insert into `actor` (`id`, `name`, `update_time`) values('2','b','2020-02-11 22:56:00');
insert into `actor` (`id`, `name`, `update_time`) values('3','c','2020-02-11 22:56:00');
CREATE TABLE `film` (
`id` int(11) NOT NULL AUTO_INCREMENT COMMENT '主鍵id',
`name` varchar(10) DEFAULT NULL COMMENT '電影名稱',
PRIMARY KEY (`id`),
KEY `idx_name` (`name`)
) ENGINE=InnoDB AUTO_INCREMENT=4 DEFAULT CHARSET=utf8;
insert into `film` (`id`, `name`) values('3','film0');
insert into `film` (`id`, `name`) values('1','film1');
insert into `film` (`id`, `name`) values('2','film2');
CREATE TABLE `film_actor` (
`id` int(11) NOT NULL COMMENT '主鍵id',
`film_id` int(11) NOT NULL COMMENT '電影id',
`actor_id` int(11) NOT NULL COMMENT '演員id',
`remark` varchar(255) DEFAULT NULL COMMENT '備註',
PRIMARY KEY (`id`),
KEY `idx_film_actor_id` (`film_id`,`actor_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
insert into `film_actor` (`id`, `film_id`, `actor_id`, `remark`) values('1','1','1',NULL);
insert into `film_actor` (`id`, `film_id`, `actor_id`, `remark`) values('2','1','2',NULL);
insert into `film_actor` (`id`, `film_id`, `actor_id`, `remark`) values('3','2','1',NULL);
執行完以上SQL後,三張表數據對應如下:

下麵展示explain中每個列的信息:
(1)id列
id列的編號是select語句的序列號,有幾個 select 就有幾個id,並且id的序號是按 select 出現的順序而增長的(id越大,對應的select語句越先執行,如果id相等,則從上往下執行,id為NULL最後執行)。
MySQL將select查詢分為簡單查詢(SIMPLE)和複雜查詢(PRIMARY)。
複雜查詢分為三類:簡單子查詢、派生表(from語句中的子查詢)、union查詢。
1)簡單子查詢
執行SQL語句:EXPLAIN SELECT (SELECT 1 FROM actor LIMIT 1) FROM film

2)from子句中的子查詢
執行SQL語句:EXPLAIN SELECT id FROM (SELECT id FROM film) AS der

分析:這個查詢執行時有個臨時表別名為der,外部select查詢引用了這個臨時表。
3)union查詢
執行SQL語句:EXPLAIN SELECT 1 UNION ALL SELECT 1

分析:union結果總是放在一個匿名臨時表中,臨時表不在SQL中出現,因此它的id為NULL。(不推薦使用union,性能不高)
(2)select_type列
這一列表示對應行是簡單還是複雜查詢,如果是複雜查詢,又是上述三種複雜查詢中的哪一種。
1)SIMPLE:簡單查詢。查詢不包含子查詢和union。
執行SQL語句:EXPLAIN SELECT * FROM film WHERE id=2

2)PRIMARY:複雜查詢中最外層的select。
3)SUBQUERY:包含在select中的子查詢(不在from子句中)。
4)DERIVED:包含在from子句中的子查詢。MySQL會將結果存放在一個臨時表中,也稱為派生表(DERIVED的英文含義)。
執行SQL語句:EXPLAIN SELECT (SELECT 1 FROM actor WHERE id=1) FROM (SELECT * FROM film WHERE id=1) der

5)UNION:在union中的第二個和隨後的select。
6)UNION RESULT:從union臨時表檢索結果的select。
執行SQL語句:EXPLAIN SELECT 1 UNION ALL SELECT 1

(3)table列
這一列表示explain的一行正在訪問哪個表。
當from子句中有子查詢時,table列是<DERIVED N>格式,表示當前查詢依賴id=N的查詢,於是先執行id=N的查詢。
當有union時,UNION RESULT的table列的值為<union 1,2>,1和2表示參與union的select行id。
(4)type列
(溫馨提示:以下部分理論有可能解釋完還是懵逼,沒關係,繼續往下看,有實踐例子)
這一列表示關聯類型或訪問類型,即MySQL決定如何查找表中的行,查找數據記錄的大概範圍。
SQL語句查詢效率從最優到最差依次為:system > const > eq_ref > ref > range > index > ALL。
一般來說,得保證查詢達到range級別,最好達到ref。
NULL:MySQL能夠在SQL語句執行之前(即優化階段)分析分解查詢語句,在執行階段用不著再訪問表或索引。例如:在索引列中選取最小值,可以單獨查找索引來完成,不需要在執行時訪問表,出現的頻率不高。
const,system:MySQL能夠對查詢的某部分進行優化並將其轉化成一個常量(可以看show warnings的結果)。用於主鍵索引或唯一索引的所有列與常數比較時,表最多有一個匹配行,讀取1次,速度比較快。system是const的特例,表裡只有一條記錄匹配時為system。
執行SQL語句:EXPLAIN EXTENDED SELECT * FROM (SELECT * FROM film WHERE id=1) tmp

分析:上面的子查詢SELECT * FROM film WHERE id = 1語句where後面id使用的是主鍵索引查詢,主鍵是唯一的,所以查詢結果一定是只有一條記錄,對於明確知道結果集只有一條記錄的查詢,它的type為const類型,性能已經非常高了;而第一個select複雜查詢的表只有一條記錄,所以結果也肯定只有一條記錄(第二個select子查詢之前表中可能是多條記錄),這種特例它的type為system類型,性能最高。
執行SQL語句:EXPLAIN EXTENDED SELECT * FROM (SELECT * FROM film WHERE id=1) tmp; SHOW WARNINGS;

分析:用explain extended查看執行計劃會比explain多一列filtered,該列給出一個百分比的值,這個值和rows列一起使用,可以估計出那些將要和explain中的前一個表進行連接的行的數目,前一個表就是指explain的id列的值比當前表的id小的表。explain extended還可以搭配show warnings一起使用,它可以給出一個優化建議,真正執行時是執行優化建議的那條SQL,但是如果是很複雜的SQL,它優化出來的結果可能都沒你原先的SQL性能高。
eq_ref:主鍵索引或唯一索引的所有部分被連接使用,最多只會返回一條符合條件的記錄。這可能是在const之外最好的連接類型了,簡單的select查詢不會出現這種type。
執行SQL語句:EXPLAIN SELECT * FROM film_actor LEFT JOIN film ON film_actor.film_id=film.id

分析:有兩條記錄,說明有2次查詢, id相等,則從上往下執行,說明第1條先執行查詢film_actor表,第2條左連接查詢film表。左連接film表並關聯film.id,由於film.id是唯一索引,film表只能關聯一行記錄,所以第2條select的type為eq_ref。
ref:相比eq_ref,不使用唯一索引,而是使用普通索引或者唯一索引的首碼部分,索引要和某個值相比較,可能會找到多條符合條件的記錄。
① 簡單select查詢,name是普通索引(非唯一索引)
執行SQL語句:EXPLAIN SELECT * FROM film WHERE NAME="film1"

② 關聯表查詢,idx_film_actor_id是film_id和actor_id的聯合索引,這裡使用了film_actor的索引左邊首碼部分 film_id。
執行SQL語句:EXPLAIN SELECT * FROM film LEFT JOIN film_actor ON film.id=film_actor.film_id

range:範圍掃描通常出現在in(),between,>,<,>=等操作中。使用一個索引來檢索給定範圍的行。
執行SQL語句:EXPLAIN SELECT * FROM actor WHERE id>1

index: 掃描全表索引,這通常會比ALL快一些。(index是從索引中讀取的,而ALL是從硬碟中讀取)
執行SQL語句:EXPLAIN SELECT * FROM film;(film表所有欄位都加了索引)

ALL: 即全表掃描,意味著MySQL需要從頭到尾去查找所需要的行(不走索引)。通常情況下這需要增加索引來優化了。
執行SQL語句:EXPLAIN SELECT * FROM actor;(actor表有一個欄位沒加索引)

(5)possible_keys列
這一列顯示查詢可能使用哪些索引來查找。
explain時可能出現possible_key有列,而key顯示NULL的情況,這種情況是因為表中數據不多,MySQL認為索引對此查詢幫助不大,選擇了全表查詢。
如果該列是NULL,則沒有相關的索引。在這種情況下,可以通過檢查where子句是否可以創造一個適當的索引來提高查詢性能,然後用explain查看效果。
(6)key列
這一列顯示MySQL實際採用哪個索引來優化對該表的訪問。
如果沒有使用索引,則該列是NULL。如果想強制MySQL使用或忽視possible_keys列中的索引,在查詢中使用force index、ignore index。
(7)key_len列
這一列顯示了MySQL在索引里使用的位元組數,通過這個值可以算出具體使用了索引中的哪些列。
舉例來說,film_actor表的聯合索引idx_film_actor_id由film_id和actor_id兩個int列組成,並且每個int是4位元組。通過下麵結果中的key_len=4可推斷出只使用了第一個列flim_id來執行索引查找。
執行SQL語句:EXPLAIN SELECT * FROM film_actor WHERE film_id=2

key_len計算規則如下:
① 字元串
- char(n):n位元組長度
- varchar(n):2位元組存儲字元串長度,如果是UTF-8,則長度為3n+2
② 數值類型
- tinyint:1位元組
- smallint:2位元組
- int:4位元組
- bigint:8位元組
③ 時間類型
- date:3位元組
- timestamp:4位元組
- datetime:8位元組
④ 如果欄位允許為NULL,需要1位元組記錄是否為NULL
(8)ref列
這一列顯示了在key列記錄的索引中,表查找值所用到的列或常量,常見的有:const(常量)、欄位名(例:film.id)。
(9)rows列
這一列是MySQL估計要讀取並檢測的行數,註意這個不是結果集里的行數。
(10)Extra列
這一列展示的是額外信息。常見的重要值如下:
Using index: 查詢的列被索引覆蓋,並且where篩選條件是索引的前導列(類似聯合索引的最左首碼原則),是性能高的表現。一般是使用了覆蓋索引(即索引包含了所有查詢的欄位)。對於InnoDB來說,如果是普通索引性能會有不少提高。
執行SQL語句:EXPLAIN SELECT film_id FROM film_actor WHERE film_id=1

Using where:查詢的列不完全被索引覆蓋,where篩選條件非索引的前導列。(不走索引,性能較低)
執行SQL語句:EXPLAIN SELECT * FROM actor WHERE name='a'

Using where; Using index:查詢的列被索引覆蓋,並且where篩選條件是索引列之一但不是索引的前導列,意味著無法直接通過索引來查找符合條件的數據。
執行SQL語句:EXPLAIN SELECT film_id FROM film_actor WHERE actor_id=1

NULL:查詢的列未被索引覆蓋,並且where篩選條件是索引的前導列,意味著用到了索引,但是部分欄位未被索引覆蓋,必須通過“回表”來實現,不是純粹地用到了索引,也不是完全沒用到索引。
執行SQL語句:EXPLAIN SELECT * FROM film_actor WHERE film_id=1

Using index condition:MySQL 5.6版本開始加入的新特性,與Using where類似,查詢的列不完全被索引覆蓋,where條件中是一個前導列的範圍。
執行SQL語句:EXPLAIN SELECT * FROM film_actor WHERE film_id>1

Using temporary:MySQL需要創建一張臨時表來處理查詢。出現這種情況一般是要進行優化的,首先要想到用索引來優化。
① actor.name沒有索引,此時創建了一張臨時表來distinct。(distinct:去除查詢結果中的重覆記錄)
執行SQL語句:EXPLAIN SELECT DISTINCT NAME FROM actor

② film.name建立了idx_name索引,此時查詢時extra是Using index,沒有用臨時表。
執行SQL語句:EXPLAIN SELECT DISTINCT NAME FROM film

Using filesort:MySQL會對結果使用一個外部索引排序,而不是按照索引次序從表裡讀取行。此時MySQL會根據連接類型瀏覽所有符合條件的記錄,並保存排序關鍵字和行指針,然後排序關鍵字並按順序檢索行信息。這種情況下一般也是要考慮使用索引來優化。
① actor.name未創建索引,會瀏覽actor整個表,保存排序關鍵字name和對應的id,然後排序name並檢索行記錄。
執行SQL語句:EXPLAIN SELECT * FROM actor ORDER BY name

② film.name建立了idx_name索引,此時查詢時extra是Using index,因為索引底層數據結構已經是排好序的。
執行SQL語句:EXPLAIN SELECT * FROM film ORDER BY name

4、索引優化最佳實踐
使用了 employees 員工表:
CREATE TABLE `employees` (
`id` int(11) NOT NULL AUTO_INCREMENT COMMENT '主鍵id',
`name` varchar(24) NOT NULL COMMENT '員工姓名',
`age` int(11) NOT NULL DEFAULT '0' COMMENT '員工年齡',
`position` varchar(20) NOT NULL COMMENT '員工職位',
`hire_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '入職時間',
PRIMARY KEY (`id`),
KEY `idx_name_age_position` (`name`,`age`,`position`)
) ENGINE=InnoDB AUTO_INCREMENT=4 DEFAULT CHARSET=utf8;
insert into `employees` (`id`, `name`, `age`, `position`, `hire_time`) values('1','LiLei','22','manager','2020-02-13 14:22:55');
insert into `employees` (`id`, `name`, `age`, `position`, `hire_time`) values('2','HanMeimei','23','dev','2020-02-13 14:22:57');
insert into `employees` (`id`, `name`, `age`, `position`, `hire_time`) values('3','Lucy','23','dev','2020-02-13 14:22:59');
(1)全值匹配
執行SQL語句:EXPLAIN SELECT * FROM employees WHERE name='LiLei'

執行SQL語句:EXPLAIN SELECT * FROM employees WHERE name='LiLei' AND age=22

執行SQL語句:EXPLAIN SELECT * FROM employees WHERE name='LiLei' AND age=22 AND position='manager'

(2)索引最左首碼原則
如果索引了多列,要遵循最左首碼原則。指的是查詢從索引的最左前列開始並且不跳過索引中的列。
提問:為什麼聯合索引要想命中索引必須採用最左首碼原則?(命中索引:即是否用到了索引)
以下索引優化規則很多都可以結合下麵這張圖思考,聯合索引底層的索引數據結構圖(B+樹),索引的排序首先按10002排序,接著是Staff,最後才是1996-08-03,如果不先拿第一個欄位10002去比較,根本沒法比較,導致無法命中索引。
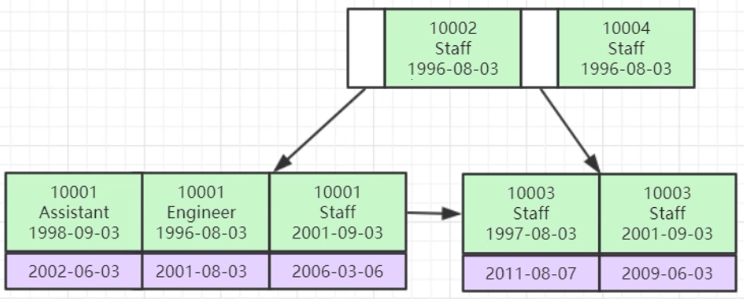
提問:以下SQL命中索引?
① EXPLAIN SELECT * FROM employees WHERE age = 22 AND position = 'manager';
② EXPLAIN SELECT * FROM employees WHERE position = 'manager';
③ EXPLAIN SELECT * FROM employees WHERE name = 'LiLei';
④ EXPLAIN SELECT * FROM employees WHERE name = 'LiLei' AND position = 'manager';
分析:
①中的where條件後面age=22不是索引的最左前列,後面就不用看了,沒有命中索引,②也是如此。

③中的name是索引idx_name_age_position的最左前列,命中索引。

④中的name命中索引,position沒有命中索引,因為跳過索引中的age列,中間斷了,age列還是需要全表掃描。

(3)不要在索引列上做任何操作(如計算、函數、自動或手動類型轉換),否則會導致索引失效而轉向全表掃描
執行SQL語句:EXPLAIN SELECT * FROM employees WHERE LEFT(name, 3)='LiLei'

(4)存儲引擎不能使用索引中範圍條件右邊的列
執行SQL語句:EXPLAIN SELECT * FROM employees WHERE name='LiLei' AND age>22 AND position='manager'

分析:長度為78,name為74,age是int類型,所以為4,即只有name和age命中索引,position沒有命中索引,因為它屬於age範圍條件右邊的索引列。
(5)儘量使用覆蓋索引(只訪問索引的查詢,索引列包含查詢列),減少 select * 語句
執行SQL語句:EXPLAIN SELECT name,age FROM employees WHERE name='LiLei'

執行SQL語句:EXPLAIN SELECT * FROM employees WHERE name='LiLei'

(6)MySQL在使用不等於(!= 或者 <>)的時候無法使用索引,會導致全表掃描
執行SQL語句:EXPLAIN SELECT * FROM employees WHERE name != 'LiLei'

(7)is null,is not null也無法使用索引
執行SQL語句:
EXPLAIN SELECT * FROM employees WHERE name IS NULL

(8)like以通配符開頭('$abc'),MySQL索引會失效導致全表掃描
執行SQL語句:EXPLAIN SELECT * FROM employees WHERE name LIKE '%Lei'

執行SQL語句:EXPLAIN SELECT * FROM employees WHERE name LIKE 'Lei%'

提問:如何解決like '%字元串%' 索引沒有命中?
① 使用覆蓋索引,查詢欄位必須是建立覆蓋索引欄位
執行SQL語句:EXPLAIN SELECT name,age,position FROM employees WHERE name LIKE '%Lei%'

② 當覆蓋索引指向的欄位是varchar(380)及以上的欄位時,覆蓋索引會失效!
(9)字元串不加單引號,索引失效(內部會做一個字元串轉換函數)
執行SQL語句:EXPLAIN SELECT * FROM employees WHERE name=1000

(10)少用or或in,用它查詢時,非主鍵欄位的索引會失效,主鍵索引有時生效,有時不生效,跟數據量有關,具體還得看MySQL的查詢優化結果
執行SQL語句:EXPLAIN SELECT * FROM employees WHERE name='LiLei' OR name='Hanmeimei'

總結:
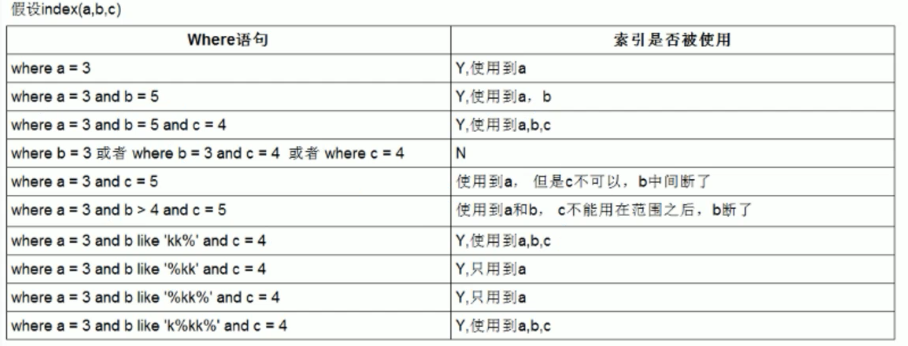
like KK% 相當於等於常量,%KK 和 %KK% 相當於範圍。

