
我一直想用 Python and Selenium 創建一個網頁爬蟲,但從來沒有實現它。 幾天前, 我決定嘗試一下,這聽起來可能是挺複雜的, 然而編寫代碼從 Unsplash 抓取一些美麗的圖片還是挺容易的。 PS:很多人在學習Python的過程中,往往因為遇問題解決不了或者沒好的教程從而導致自己放 ...
 我一直想用 Python and Selenium 創建一個網頁爬蟲,但從來沒有實現它。 幾天前, 我決定嘗試一下,這聽起來可能是挺複雜的, 然而編寫代碼從 Unsplash 抓取一些美麗的圖片還是挺容易的。
我一直想用 Python and Selenium 創建一個網頁爬蟲,但從來沒有實現它。 幾天前, 我決定嘗試一下,這聽起來可能是挺複雜的, 然而編寫代碼從 Unsplash 抓取一些美麗的圖片還是挺容易的。
PS:很多人在學習Python的過程中,往往因為遇問題解決不了或者沒好的教程從而導致自己放棄,為此我整理啦從基礎的python腳本到web開發、爬蟲、django、數據挖掘等【PDF等】需要的可以進Python全棧開發交流.裙 :一久武其而而流一思(數字的諧音)轉換下可以找到了,裡面有最新Python教程項目可拿,不懂的問題有老司機解決哦,一起相互監督共同進步!
簡易圖片爬蟲的組成部分
- Python (3.6.3 或者更新版本)
- Pycharm (Community edition 版本就可以)
- Requests
- Pillow
- Selenium
- Geckodriver (閱讀下麵的說明)
- Mozlla Firefox (如果你沒有,去安裝一下)
- 有效的網路連接 (顯而易見的)
- 你的 30 分鐘 (可能更少)
簡易圖片爬蟲的製作
把所有東西都安裝好了麽?不錯!跟著我們的代碼,我將開始解釋我們每一個爬蟲原料的作用。
第一件事情,我們將 把 Selenium webdriver 和 geckodriver 結合起來去打開一個為我們工作的瀏覽器視窗。首先,在 Pycharm 里創建一個項目,根據你的系統下載最新的 geckodriver , 打開下載的壓縮文件然後把 geckodriver 文件放到你的項目文件夾里。 Geckodriver 是 Selenium 控制 Firefox 的基礎, 因此我們需要把它放到我們項目的文件夾裡面,來讓我們能使用瀏覽器。
接下來我們要做的就是在代碼中導入 Selenium 的 webdriver 並且連接我們想要連接的 URL,所以讓我們這樣做吧:
from selenium import webdriver
# 你想打開的url地址
url = "https://unsplash.com"
# 用Selenium的webdriver去打開頁面
driver = webdriver.Firefox(executable_path=r'geckodriver.exe')
driver.get(url)
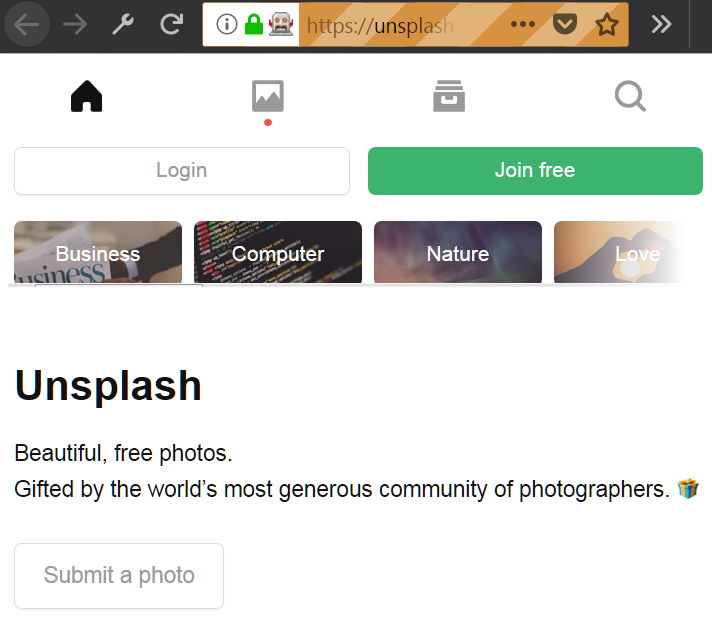
一個遠程式控制制的 Firefox 視窗
很簡單,是吧? 如果你每一步都操作正確, 你已經度過了困難的一部分,你應該看到和上面展示圖片類似的瀏覽器視窗。
接下來,我們應該下滑頁面,這樣在我們下載圖片之前可以載入更多的圖片。我們還需要等待幾秒鐘,以防萬一網路連接緩慢,圖片載入不全。由於 Unsplash 是基於 React 構建的, 等待 5 秒鐘似乎是合適的時間,因此我們使用 time 包來進行等待的操作。我們還需要使用一些 Javascript 代碼來滾動頁面 。
--- 我們將使用 window.scrollTo() 來完成這個。把它們放到一起, 你應該得到這樣的代碼:
unscrape.py
import time
from selenium import webdriver
url = "https://unsplash.com"
driver = webdriver.Firefox(executable_path=r'geckodriver.exe')
driver.get(url)
# 滾動頁面,然後等待5秒
driver.execute_script("window.scrollTo(0,1000);")
time.sleep(5)滾動頁面,然後等待 5 秒
在測試上面的代碼後,你應該看到瀏覽器向下滾動一些,下一件我們需要做的事情是在網頁上找到那些我們想要下載的圖片。在解析 recat 生成代碼後,我發現我們能用 CSS 選擇器在頁面代碼裡面定位我們想要的圖片。也許頁面具體的佈局和代碼在未來可能會改變, 但是在我寫代碼的這個時候我們可以用 #gridMulti img 選擇器來獲取所有出現在屏幕裡面的 <img> 標簽元素
我們能用 find_elements_by_css_selector() 得到這些標簽元素的 list 集合,但是我們想要的卻是是每個標簽元素的 src 的屬性。所以,我們可以遍歷 list 集合然後抓取它們:
unscrape.py
import time
from selenium import webdriver
url = "https://unsplash.com"
driver = webdriver.Firefox(executable_path=r'geckodriver.exe')
driver.get(url)
driver.execute_script("window.scrollTo(0,1000);")
time.sleep(5)
# 選擇圖片標簽元素,列印它們的URL
image_elements = driver.find_elements_by_css_selector("#gridMulti img")
for image_element in image_elements:
image_url = image_element.get_attribute("src")
print(image_url)選擇圖片標簽元素,列印它們的 URL
現在,為了真正得到我們找到的圖片,我們將使用 requests 包和一部分 PIL 包,即 Image。我們還需要使用 io 包裡面的 BytesIO 來把圖片寫入一個 ./images/ 的文件夾,我們要在我們的項目文件夾裡面創建這個文件。 這樣,把所有東西組合在一起,我們需要給每個圖片的 URL 發送一個 HTTP 的 GET 請求,然後使用 Image 和 BytesIO,我們可以在我們得到的響應裡面存儲圖片,這裡是一個方法來實現這一步驟 :
unscrape.py
import requests
import time
from selenium import webdriver
from PIL import Image
from io import BytesIO
url = "https://unsplash.com"
driver = webdriver.Firefox(executable_path=r'geckodriver.exe')
driver.get(url)
driver.execute_script("window.scrollTo(0,1000);")
time.sleep(5)
image_elements = driver.find_elements_by_css_selector("#gridMulti img")
i = 0
for image_element in image_elements:
image_url = image_element.get_attribute("src")
# 發送一個HTTP的GET請求,在響應裡面獲取並存儲圖片
image_object = requests.get(image_url)
image = Image.open(BytesIO(image_object.content))
image.save("./images/image" + str(i) + "." + image.format, image.format)
i += 1下載圖片
下載一大堆免費的圖片幾乎是你的所有需求了。顯而易見的,除非你想設計圖片原型或者僅僅需要得到隨機的圖片,這個小爬蟲是沒有多大用處的。 因此,我花了一些時間,通過增加了更多的特性來提升它:
- 允許用戶使用命令行參數來指定搜索查詢的內容,同時使用滾動數值參數,這樣允許頁面為下載展示更多的圖片。
- 可定製化的
CSS選擇器。 - 根據搜索查詢定製結果的文件夾。
- 根據需要裁剪縮略圖的網址以獲得全高清圖像。
- 基於圖片的 URL 給圖片命名。
- 在程式結束後關閉瀏覽器視窗。
你可以 (也可能應該) 嘗試自己去實現其中的一些功能。可用的完整版的網頁爬蟲 這裡。 記得去單獨下載 geckodriver 並將其連接到你的項目,就像文章開頭說明的那樣 。
限制,思考和未來的改進
這個整體項目都是一個非常簡單的概念驗證,來看看網頁爬蟲是怎麼實現完成的,意味著有很多事情可以做,來改善這個小工具:
- 沒有記錄這些圖片的原始上傳者是一個很不好的主意,
Selenium是絕對有能力來做這些事情的,所以讓每個圖片都帶著作者的名字。 Geckodriver不應該被放置在項目的文件夾內,而更應該全局安裝,併成為PATH系統環境變數的一部分。- 搜索功能很容易地擴展到包括多個查詢,從而可以簡化下載大量圖片的過程。
- 預設的瀏覽器可以從
Firefox變成Chrome或者甚至 PhantomJS 對這類項目來說會好很多。
總結:很多人在學習Python的過程中,往往因為遇問題解決不了或者沒好的教程從而導致自己放棄,為此我整理啦從基礎的python腳本到web開發、爬蟲、django、數據挖掘等【PDF等】需要的可以進Python全棧開發交流.裙 :一久武其而而流一思(數字的諧音)轉換下可以找到了,裡面有最新Python教程項目可拿,不懂的問題有老司機解決哦,一起相互監督共同進步
本文的文字及圖片來源於網路加上自己的想法,僅供學習、交流使用,不具有任何商業用途,版權歸原作者所有,如有問題請及時聯繫我們以作處理。


