
javaSE學習筆記(10) List、Set 1、數據存儲的數據結構 常見的數據結構 數據存儲的常用結構有:棧、隊列、數組、鏈表和紅黑樹。 1、棧 棧 : stack ,又稱堆棧,它是運算受限的線性表,其限制是僅允許在標的一端進行插入和刪除操作,不允許在其他任何位置進行添加、查找、刪除等操作。 簡 ...
javaSE學習筆記(10)---List、Set
1、數據存儲的數據結構
常見的數據結構
數據存儲的常用結構有:棧、隊列、數組、鏈表和紅黑樹。
1、棧
- 棧:stack,又稱堆棧,它是運算受限的線性表,其限制是僅允許在標的一端進行插入和刪除操作,不允許在其他任何位置進行添加、查找、刪除等操作。
簡單的說:採用該結構的集合,對元素的存取有如下的特點
先進後出(即,存進去的元素,要在後它後面的元素依次取出後,才能取出該元素)。例如,子彈壓進彈夾,先壓進去的子彈在下麵,後壓進去的子彈在上面,當開槍時,先彈出上面的子彈,然後才能彈出下麵的子彈。
棧的入口、出口的都是棧的頂端位置。
- 壓棧:就是存元素。即,把元素存儲到棧的頂端位置,棧中已有元素依次向棧底方向移動一個位置。
彈棧:就是取元素。即,把棧的頂端位置元素取出,棧中已有元素依次向棧頂方向移動一個位置。
2、隊列
- 隊列:queue,簡稱隊,它同堆棧一樣,也是一種運算受限的線性表,其限制是僅允許在表的一端進行插入,而在表的另一端進行刪除。
簡單的說,採用該結構的集合,對元素的存取有如下的特點:
- 先進先出(即,存進去的元素,要在後它前面的元素依次取出後,才能取出該元素)。例如,小火車過山洞,車頭先進去,車尾後進去;車頭先出來,車尾後出來。
- 隊列的入口、出口各占一側。
3、數組
- 數組:Array,是有序的元素序列,數組是在記憶體中開闢一段連續的空間,併在此空間存放元素。就像是一排出租屋,有100個房間,從001到100每個房間都有固定編號,通過編號就可以快速找到租房子的人。
簡單的說,採用該結構的集合,對元素的存取有如下的特點:
查找元素快:通過索引,可以快速訪問指定位置的元素
- 增刪元素慢
- 指定索引位置增加元素:需要創建一個新數組,將指定新元素存儲在指定索引位置,再把原數組元素根據索引,複製到新數組對應索引的位置。
- 指定索引位置刪除元素:需要創建一個新數組,把原數組元素根據索引,複製到新數組對應索引的位置,原數組中指定索引位置元素不複製到新數組中。
4、鏈表
- 鏈表:linked list,由一系列結點node(鏈表中每一個元素稱為結點)組成,結點可以在運行時i動態生成。每個結點包括兩個部分:一個是存儲數據元素的數據域,另一個是存儲下一個結點地址的指針域。我們常說的鏈表結構有單向鏈表與雙向鏈表,那麼這裡介紹的是單向鏈表。
簡單的說,採用該結構的集合,對元素的存取有如下的特點:
多個結點之間,通過地址進行連接。例如,多個人手拉手,每個人使用自己的右手拉住下個人的左手,依次類推,這樣多個人就連在一起了。
查找元素慢:想查找某個元素,需要通過連接的節點,依次向後查找指定元素
增刪元素快:
增加元素:只需要修改連接下個元素的地址即可。
刪除元素:只需要修改連接下個元素的地址即可。
紅黑樹
- 二叉樹:binary tree ,是每個結點不超過2的有序樹(tree) 。
簡單的理解,就是一種類似於我們生活中樹的結構,只不過每個結點上都最多只能有兩個子結點。
二叉樹是每個節點最多有兩個子樹的樹結構。頂上的叫根結點,兩邊被稱作“左子樹”和“右子樹”。
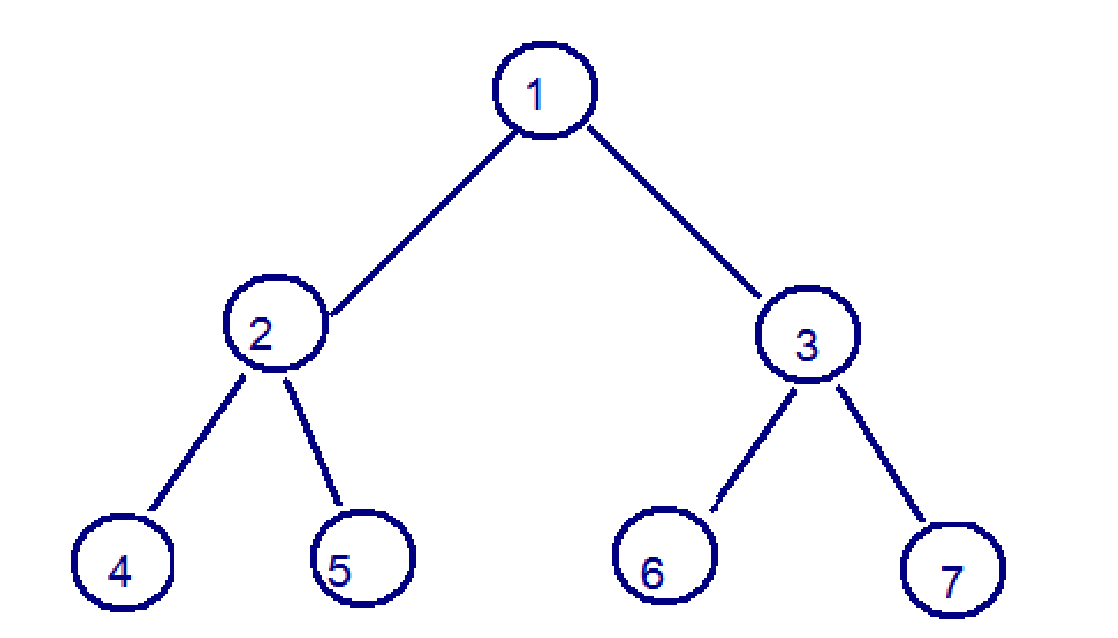
我們要說的是二叉樹的一種比較有意思的叫做紅黑樹,紅黑樹本身就是一顆二叉查找樹,將節點插入後,該樹仍然是一顆二叉查找樹。也就意味著,樹的鍵值仍然是有序的。
紅黑樹的約束:
節點可以是紅色的或者黑色的
根節點是黑色的
- 葉子節點(特指空節點)是黑色的
- 每個紅色節點的子節點都是黑色的
任何一個節點到其每一個葉子節點的所有路徑上黑色節點數相同
紅黑樹的特點:
速度特別快,趨近平衡樹,查找葉子元素最少和最多次數不多於二倍
2、List集合
我們掌握了Collection介面的使用後,再來看看Collection介面中的子類,主要學習Collection中的常用幾個子類(java.util.List集合、java.util.Set集合)。
List介面
java.util.List介面繼承自Collection介面,是單列集合的一個重要分支,習慣性地會將實現了List介面的對象稱為List集合。在List集合中允許出現重覆的元素,所有的元素是以一種線性方式進行存儲的,在程式中可以通過索引來訪問集合中的指定元素。另外,List集合還有一個特點就是元素有序,即元素的存入順序和取出順序一致。
List介面特點:
- 它是一個元素存取有序的集合。例如,存元素的順序是11、22、33。那麼集合中,元素的存儲就是按照11、22、33的順序完成的)。
- 它是一個帶有索引的集合,通過索引就可以精確的操作集合中的元素(與數組的索引是一個道理)。
- 集合中可以有重覆的元素,通過元素的equals方法,來比較是否為重覆的元素。
註意:之前已經學習過List介面的子類java.util.ArrayList類,該類中的方法都是來自List中定義。
List介面中常用方法
List作為Collection集合的子介面,不但繼承了Collection介面中的全部方法,而且還增加了一些根據元素索引來操作集合的特有方法,如下:
public void add(int index, E element): 將指定的元素,添加到該集合中的指定位置上。public E get(int index):返回集合中指定位置的元素。public E remove(int index): 移除列表中指定位置的元素, 返回的是被移除的元素。public E set(int index, E element):用指定元素替換集合中指定位置的元素,返回值的更新前的元素。
List集合特有的方法都是跟索引相關,再來複習一遍吧:
public class ListDemo {
public static void main(String[] args) {
// 創建List集合對象
List<String> list = new ArrayList<String>();
// 往 尾部添加 指定元素
list.add("圖圖");
list.add("小美");
list.add("不高興");
System.out.println(list);
// add(int index,String s) 往指定位置添加
list.add(1,"沒頭腦");
System.out.println(list);
// String remove(int index) 刪除指定位置元素 返回被刪除元素
// 刪除索引位置為2的元素
System.out.println("刪除索引位置為2的元素");
System.out.println(list.remove(2));
System.out.println(list);
// String set(int index,String s)
// 在指定位置 進行 元素替代(改)
// 修改指定位置元素
list.set(0, "三毛");
System.out.println(list);
// String get(int index) 獲取指定位置元素
// 跟size() 方法一起用 來 遍歷的
for(int i = 0;i<list.size();i++){
System.out.println(list.get(i));
}
//還可以使用增強for
for (String string : list) {
System.out.println(string);
}
}
}3、List的子類
ArrayList集合
java.util.ArrayList集合數據存儲的結構是數組結構。元素增刪慢,查找快,由於日常開發中使用最多的功能為查詢數據、遍曆數據,所以ArrayList是最常用的集合。
許多程式員開發時非常隨意地使用ArrayList完成任何需求,並不嚴謹,這種用法是不提倡的。
LinkedList集合
java.util.LinkedList集合數據存儲的結構是鏈表結構。方便元素添加、刪除的集合。
LinkedList是一個雙向鏈表,那麼雙向鏈表是什麼樣子的呢,我們用個圖瞭解下
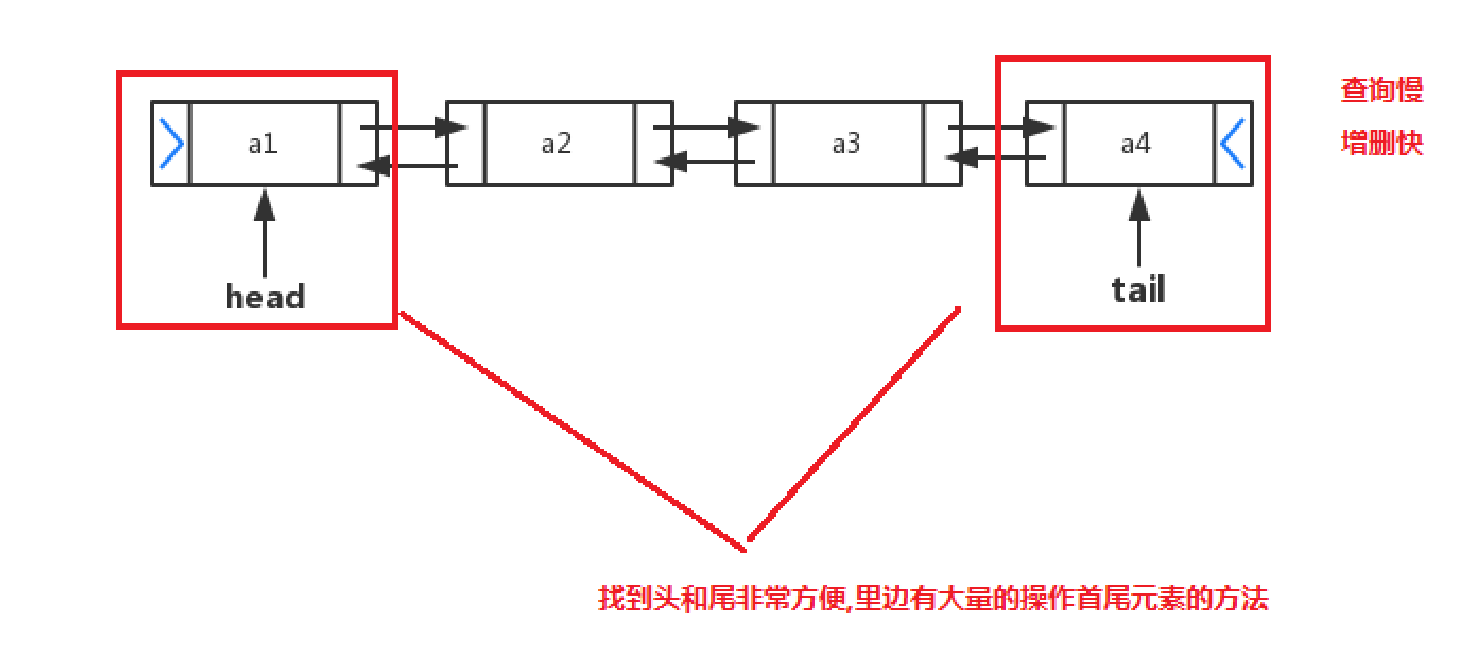
實際開發中對一個集合元素的添加與刪除經常涉及到首尾操作,而LinkedList提供了大量首尾操作的方法。這些方法作為瞭解即可:
public void addFirst(E e):將指定元素插入此列表的開頭。public void addLast(E e):將指定元素添加到此列表的結尾。public E getFirst():返回此列表的第一個元素。public E getLast():返回此列表的最後一個元素。public E removeFirst():移除並返回此列表的第一個元素。public E removeLast():移除並返回此列表的最後一個元素。public E pop():從此列表所表示的堆棧處彈出一個元素。public void push(E e):將元素推入此列表所表示的堆棧。public boolean isEmpty():如果列表不包含元素,則返回true。
LinkedList是List的子類,List中的方法LinkedList都是可以使用,這裡就不做詳細介紹,我們只需要瞭解LinkedList的特有方法即可。在開發時,LinkedList集合也可以作為堆棧,隊列的結構使用。(瞭解即可)
方法演示:
public class LinkedListDemo {
public static void main(String[] args) {
LinkedList<String> link = new LinkedList<String>();
//添加元素
link.addFirst("abc1");
link.addFirst("abc2");
link.addFirst("abc3");
System.out.println(link);
// 獲取元素
System.out.println(link.getFirst());
System.out.println(link.getLast());
// 刪除元素
System.out.println(link.removeFirst());
System.out.println(link.removeLast());
while (!link.isEmpty()) { //判斷集合是否為空
System.out.println(link.pop()); //彈出集合中的棧頂元素
}
System.out.println(link);
}
}4、Set介面
java.util.Set介面和java.util.List介面一樣,同樣繼承自Collection介面,它與Collection介面中的方法基本一致,並沒有對Collection介面進行功能上的擴充,只是比Collection介面更加嚴格了。與List介面不同的是,Set介面中元素無序,並且都會以某種規則保證存入的元素不出現重覆。
Set集合有多個子類,這裡介紹其中的java.util.HashSet、java.util.LinkedHashSet這兩個集合。
註意:Set集合取出元素的方式可以採用:迭代器、增強for。
HashSet集合介紹
java.util.HashSet是Set介面的一個實現類,它所存儲的元素是不可重覆的,並且元素都是無序的(即存取順序不一致)。java.util.HashSet底層的實現其實是一個java.util.HashMap支持。
HashSet是根據對象的哈希值來確定元素在集合中的存儲位置,因此具有良好的存取和查找性能。保證元素唯一性的方式依賴於:hashCode與equals方法。
先來使用一下Set集合存儲,看下現象,再進行原理的講解:
public class HashSetDemo {
public static void main(String[] args) {
//創建 Set集合
HashSet<String> set = new HashSet<String>();
//添加元素
set.add(new String("cba"));
set.add("abc");
set.add("bac");
set.add("cba");
//遍歷
for (String name : set) {
System.out.println(name);
}
}
}輸出結果如下,說明集合中不能存儲重覆元素:
cba
abc
bactips:根據結果我們發現字元串"cba"只存儲了一個,也就是說重覆的元素set集合不存儲。
HashSet集合存儲數據的結構(哈希表)
什麼是哈希表呢?
在JDK1.8之前,哈希表底層採用數組+鏈表實現,即使用鏈表處理衝突,同一hash值的鏈表都存儲在一個鏈表裡。但是當位於一個桶中的元素較多,即hash值相等的元素較多時,通過key值依次查找的效率較低。而JDK1.8中,哈希表存儲採用數組+鏈表+紅黑樹實現,當鏈表長度超過閾值(8)時,將鏈表轉換為紅黑樹,這樣大大減少了查找時間。
簡單的來說,哈希表是由數組+鏈表+紅黑樹(JDK1.8增加了紅黑樹部分)實現的,如下圖所示。

看到這張圖就有人要問了,這個是怎麼存儲的呢?
為了方便理解我結合一個存儲流程圖來說明一下:
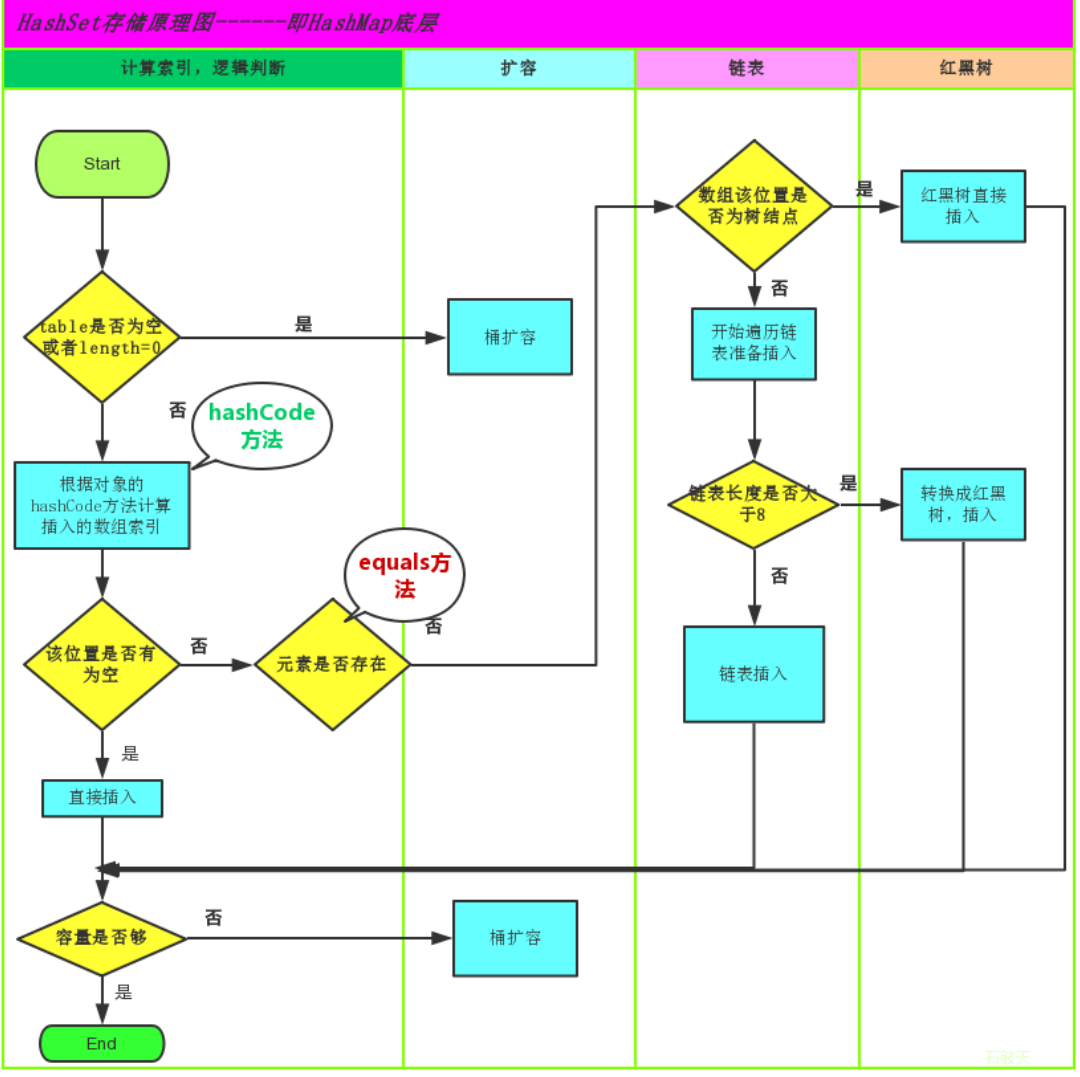
總而言之,JDK1.8引入紅黑樹大程度優化了HashMap的性能,那麼對於我們來講保證HashSet集合元素的唯一,其實就是根據對象的hashCode和equals方法來決定的。如果我們往集合中存放自定義的對象,那麼保證其唯一,就必須覆寫hashCode和equals方法建立屬於當前對象的比較方式。
HashSet存儲自定義類型元素
給HashSet中存放自定義類型元素時,需要重寫對象中的hashCode和equals方法,建立自己的比較方式,才能保證HashSet集合中的對象唯一
創建自定義Student類
public class Student {
private String name;
private int age;
public Student() {
}
public Student(String name, int age) {
this.name = name;
this.age = age;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
@Override
public boolean equals(Object o) {
if (this == o)
return true;
if (o == null || getClass() != o.getClass())
return false;
Student student = (Student) o;
return age == student.age &&
Objects.equals(name, student.name);
}
@Override
public int hashCode() {
return Objects.hash(name, age);
}
}public class HashSetDemo2 {
public static void main(String[] args) {
//創建集合對象 該集合中存儲 Student類型對象
HashSet<Student> stuSet = new HashSet<Student>();
//存儲
Student stu = new Student("於謙", 43);
stuSet.add(stu);
stuSet.add(new Student("郭德綱", 44));
stuSet.add(new Student("於謙", 43));
stuSet.add(new Student("郭麒麟", 23));
stuSet.add(stu);
for (Student stu2 : stuSet) {
System.out.println(stu2);
}
}
}
執行結果:
Student [name=郭德綱, age=44]
Student [name=於謙, age=43]
Student [name=郭麒麟, age=23]LinkedHashSet
我們知道HashSet保證元素唯一,可是元素存放進去是沒有順序的,那麼我們要保證有序,怎麼辦呢?
在HashSet下麵有一個子類java.util.LinkedHashSet,它是鏈表和哈希表組合的一個數據存儲結構。
演示代碼如下:
public class LinkedHashSetDemo {
public static void main(String[] args) {
Set<String> set = new LinkedHashSet<String>();
set.add("bbb");
set.add("aaa");
set.add("abc");
set.add("bbc");
Iterator<String> it = set.iterator();
while (it.hasNext()) {
System.out.println(it.next());
}
}
}
結果:
bbb
aaa
abc
bbc可變參數
在JDK1.5之後,如果我們定義一個方法需要接受多個參數,並且多個參數類型一致,我們可以對其簡化成如下格式:
修飾符 返回值類型 方法名(參數類型... 形參名){ }其實這個書寫完全等價與
修飾符 返回值類型 方法名(參數類型[] 形參名){ }只是後面這種定義,在調用時必須傳遞數組,而前者可以直接傳遞數據即可。
JDK1.5以後。出現了簡化操作。... 用在參數上,稱之為可變參數。
同樣是代表數組,但是在調用這個帶有可變參數的方法時,不用創建數組(這就是簡單之處),直接將數組中的元素作為實際參數進行傳遞,其實編譯成的class文件,將這些元素先封裝到一個數組中,在進行傳遞。這些動作都在編譯.class文件時,自動完成了。
代碼演示:
public class ChangeArgs {
public static void main(String[] args) {
int[] arr = { 1, 4, 62, 431, 2 };
int sum = getSum(arr);
System.out.println(sum);
// 6 7 2 12 2121
// 求 這幾個元素和 6 7 2 12 2121
int sum2 = getSum(6, 7, 2, 12, 2121);
System.out.println(sum2);
}
/*
* 完成數組 所有元素的求和 原始寫法
public static int getSum(int[] arr){
int sum = 0;
for(int a : arr){
sum += a;
}
return sum;
}
*/
//可變參數寫法
public static int getSum(int... arr) {
int sum = 0;
for (int a : arr) {
sum += a;
}
return sum;
}
}tips: 上述add方法在同一個類中,只能存在一個。因為會發生調用的不確定性
註意:如果在方法書寫時,這個方法擁有多參數,參數中包含可變參數,可變參數一定要寫在參數列表的末尾位置。
Collections
常用功能
java.utils.Collections是集合工具類,用來對集合進行操作。部分方法如下:public static <T> boolean addAll(Collection<T> c, T... elements):往集合中添加一些元素。public static void shuffle(List<?> list) 打亂順序:打亂集合順序。public static <T> void sort(List<T> list):將集合中元素按照預設規則排序。public static <T> void sort(List<T> list,Comparator<? super T> ):將集合中元素按照指定規則排序。
代碼演示:
public class CollectionsDemo {
public static void main(String[] args) {
ArrayList<Integer> list = new ArrayList<Integer>();
//原來寫法
//list.add(12);
//list.add(14);
//list.add(15);
//list.add(1000);
//採用工具類 完成 往集合中添加元素
Collections.addAll(list, 5, 222, 1,2);
System.out.println(list);
//排序方法
Collections.sort(list);
System.out.println(list);
}
}
結果:
[5, 222, 1, 2]
[1, 2, 5, 222]代碼演示之後 ,發現我們的集合按照順序進行了排列,可是這樣的順序是採用預設的順序,如果想要指定順序那該怎麼辦呢?
我們發現還有個方法沒有講,public static <T> void sort(List<T> list,Comparator<? super T> ):將集合中元素按照指定規則排序。接下來講解一下指定規則的排列。
Comparator比較器
還是先研究這個方法
public static <T> void sort(List<T> list):將集合中元素按照預設規則排序。
不過這次存儲的是字元串類型。
public class CollectionsDemo2 {
public static void main(String[] args) {
ArrayList<String> list = new ArrayList<String>();
list.add("cba");
list.add("aba");
list.add("sba");
list.add("nba");
//排序方法
Collections.sort(list);
System.out.println(list);
}
}結果:
[aba, cba, nba, sba]我們使用的是預設的規則完成字元串的排序,那麼預設規則是怎麼定義出來的呢?
說到排序了,簡單的說就是兩個對象之間比較大小,那麼在JAVA中提供了兩種比較實現的方式,一種是比較死板的採用java.lang.Comparable介面去實現,一種是靈活的當我需要做排序的時候在去選擇的java.util.Comparator介面完成。
那麼我們採用的public static <T> void sort(List<T> list)這個方法完成的排序,實際上要求了被排序的類型需要實現Comparable介面完成比較的功能,在String類型上如下:
public final class String implements java.io.Serializable, Comparable<String>, CharSequence {String類實現了這個介面,並完成了比較規則的定義,但是這樣就把這種規則寫死了,那比如我想要字元串按照第一個字元降序排列,那麼這樣就要修改String的源代碼,這是不可能的了,那麼這個時候我們可以使用
public static <T> void sort(List<T> list,Comparator<? super T> )方法靈活的完成,這個裡面就涉及到了Comparator這個介面,位於位於java.util包下,排序是comparator能實現的功能之一,該介面代表一個比較器,比較器具有可比性!顧名思義就是做排序的,通俗地講需要比較兩個對象誰排在前誰排在後,那麼比較的方法就是:
public int compare(String o1, String o2):比較其兩個參數的順序。兩個對象比較的結果有三種:大於,等於,小於。
如果要按照升序排序,
則o1 小於o2,返回(負數),相等返回0,01大於02返回(正數)
如果要按照降序排序
則o1 小於o2,返回(正數),相等返回0,01大於02返回(負數)
操作如下:
public class CollectionsDemo3 {
public static void main(String[] args) {
ArrayList<String> list = new ArrayList<String>();
list.add("cba");
list.add("aba");
list.add("sba");
list.add("nba");
//排序方法 按照第一個單詞的降序
Collections.sort(list, new Comparator<String>() {
@Override
public int compare(String o1, String o2) {
return o2.charAt(0) - o1.charAt(0);
}
});
System.out.println(list);
}
}結果如下:
[sba, nba, cba, aba]Comparable和Comparator兩個介面的區別
Comparable:強行對實現它的每個類的對象進行整體排序。這種排序被稱為類的自然排序,類的compareTo方法被稱為它的自然比較方法。只能在類中實現compareTo()一次,不能經常修改類的代碼實現自己想要的排序。實現此介面的對象列表(和數組)可以通過Collections.sort(和Arrays.sort)進行自動排序,對象可以用作有序映射中的鍵或有序集合中的元素,無需指定比較器。
Comparator強行對某個對象進行整體排序。可以將Comparator 傳遞給sort方法(如Collections.sort或 Arrays.sort),從而允許在排序順序上實現精確控制。還可以使用Comparator來控制某些數據結構(如有序set或有序映射)的順序,或者為那些沒有自然順序的對象collection提供排序。
練習
創建一個學生類,存儲到ArrayList集合中完成指定排序操作。
Student 初始類
public class Student{
private String name;
private int age;
public Student() {
}
public Student(String name, int age) {
this.name = name;
this.age = age;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
@Override
public String toString() {
return "Student{" +
"name='" + name + '\'' +
", age=" + age +
'}';
}
}測試類:
public class Demo {
public static void main(String[] args) {
// 創建四個學生對象 存儲到集合中
ArrayList<Student> list = new ArrayList<Student>();
list.add(new Student("rose",18));
list.add(new Student("jack",16));
list.add(new Student("abc",16));
list.add(new Student("ace",17));
list.add(new Student("mark",16));
/*
讓學生 按照年齡排序 升序
*/
// Collections.sort(list);//要求 該list中元素類型 必須實現比較器Comparable介面
for (Student student : list) {
System.out.println(student);
}
}
}發現,當我們調用Collections.sort()方法的時候 程式報錯了。
原因:如果想要集合中的元素完成排序,那麼必須要實現比較器Comparable介面。
於是我們就完成了Student類的一個實現,如下:
public class Student implements Comparable<Student>{
....
@Override
public int compareTo(Student o) {
return this.age-o.age;//升序
}
}再次測試,代碼就OK 了效果如下:
Student{name='jack', age=16}
Student{name='abc', age=16}
Student{name='mark', age=16}
Student{name='ace', age=17}
Student{name='rose', age=18}擴展
如果在使用的時候,想要獨立的定義規則去使用 可以採用Collections.sort(List list,Comparetor
Collections.sort(list, new Comparator<Student>() {
@Override
public int compare(Student o1, Student o2) {
return o2.getAge()-o1.getAge();//以學生的年齡降序
}
});效果:
Student{name='rose', age=18}
Student{name='ace', age=17}
Student{name='jack', age=16}
Student{name='abc', age=16}
Student{name='mark', age=16}如果想要規則更多一些,可以參考下麵代碼:
Collections.sort(list, new Comparator<Student>() {
@Override
public int compare(Student o1, Student o2) {
// 年齡降序
int result = o2.getAge()-o1.getAge();//年齡降序
if(result==0){//第一個規則判斷完了 下一個規則 姓名的首字母 升序
result = o1.getName().charAt(0)-o2.getName().charAt(0);
}
return result;
}
});效果如下:
Student{name='rose', age=18}
Student{name='ace', age=17}
Student{name='abc', age=16}
Student{name='jack', age=16}
Student{name='mark', age=16}

