
1、不要取出全部列,取出全部列,會讓優化器無法完成索引覆蓋掃描這類優化,還會為伺服器帶來額外的I/O、記憶體和CPU的消耗。應該嚴格禁止SELECT * 的寫法。MySQL使用如下三種方式應用WHERE條件,從好到壞依次為: 1.1 在索引中使用WHERE條件來過濾不匹配的記錄。這是在存儲引擎層完成的 ...
1、不要取出全部列,取出全部列,會讓優化器無法完成索引覆蓋掃描這類優化,還會為伺服器帶來額外的I/O、記憶體和CPU的消耗。應該嚴格禁止SELECT * 的寫法。MySQL使用如下三種方式應用WHERE條件,從好到壞依次為:
1.1 在索引中使用WHERE條件來過濾不匹配的記錄。這是在存儲引擎層完成的。
1.2 使用索引覆蓋掃描(Extra列中出現了Using index)來返回記錄,直接從索引中過濾不需要的記錄並返回命中的結果。這是在MySQL伺服器層完成的,但無須在回表查詢記錄。
1.3 從數據表中返回數據,然後過濾不滿足條件的記錄(在Extra列中出現Using Where)。這在MySQL伺服器層完成,MySQL需要先從數據表獨處記錄然後過濾。
上面的例子說明瞭好的索引很重要。
2、如果發現查詢需要掃描大量的數據但值返回少數的行,那麼可以嘗試下麵的技巧優化它:
2.1 使用索引覆蓋掃描,把所有需要用的列都放到索引中,這樣存儲引擎無須回表獲取對應行就可以返回結果了。
2.2 改變庫表結構。例如使用單獨的彙總表。
2.3 重寫這個複雜的查詢,讓MySQL優化器能夠以更優化的方式執行這個查詢。
重構查詢:
1、一個複雜查詢還是多個簡單查詢;
2、切分查詢;
例如:
DELECT FROM message WHERE created < DATE_SUB(NOW(),INTERVAL 3 MONTH); 改成: rows_affected=0 do{ rows_affected=do_query( "DELECT FROM message WHERE create created < DATE_SUB(NOW(),INTERVAL 3 MONTH) LIMIT 10000" ) } while rows_affected > 0
一次刪除一萬行數據一般來說比較高效,如果每次刪除數據後,都暫停一會兒再做下一次刪除,這樣也可以將伺服器上原本一次性的壓力分散到一個很長的時間段中,可以大大的減少對伺服器的影響
3、分解關聯查詢
查詢優化處理
查詢優化處理包括多個子階段:解析SQL、預處理、優化SQL執行計劃。這個過程中的任何錯誤(例如語法錯誤)都可能終止查詢。
優化策略可以簡單的分為兩種:
1、靜態優化:直接對解析樹進行分析,並完成優化
2、動態優化:動態優化跟查詢上下文有關,也可能和很多其他因素有關,例如WHERE條件中的取值、索引中條目對應的數據行數等。
MySQL能夠處理的優化類型:
- 重新定義關聯表的順序。
- 將外連接轉化成內連接。
- 使用等價變換規則。
- 優化COUNT()、MIN()和MAX()。
- 預估並轉化為常數表達式
- 覆蓋索引掃描
- 子查詢優化
- 提前終止查詢
- 等值傳播
- 列表IN()的比較
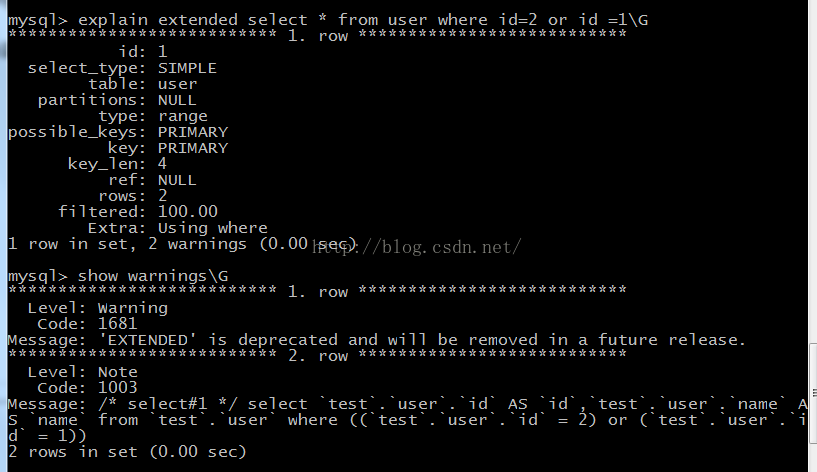
怎麼查看優化器重寫後的SQL?
用到了explain extended和showwarnings
用ORDER BY排序,如果查詢中有LIMIT的話,LIMT也會在排序之後應用,所以即使需要返回較少的數據,歷史表和需要排序的數據量仍然會非常大。MySQL5.6在這裡做了很多重要的改進。當只需要返回部分排序結果的時候,例如使用LIMIT子句,MySQL不再對所有的結果進行排序,而是根據實際情況,選擇拋棄不滿足條件的結果,然後再進行排序。
參考:
[1]Baron Schwartz等 著,寧海元等 譯 ;《高性能MySQL》(第3版); 電子工業出版社 ,2013


