
白皮書首次完整介紹了我司數據中台的數據資產管理、數據開放共用、開發協作調度、數據採集與遷移管理、數據可視化及自助分析、平臺運維管控六大技術領域,並從抽象出來的平臺支撐、數據管理和數據產品三大體系逐一拆開講解。 ...
白皮書作者:趙興申
顧問:鄭昀
出品方:禧雲集團-基礎技術中心-大數據與演算法部
數據分析組:譚清勇、王明軍、徐蕊、曹壽波
平臺開發組:劉永飛、李喜延
數據可視化組:陳少明、董建昌
基礎架構組:崔明黎、邱志偉、陳賞
第一章:數芯大數據平臺
1.1 禧雲大數據發展歷程
知名咨詢公司麥肯錫稱:『數據,已經滲透到當今每一個行業和業務職能領域,成為重要的生產因素。人們對海量數據的挖掘和運用,預示著新一波生產率增長和消費盈餘浪潮的到來。』良好的數據管理和處理技術,已經成為企業不可或缺的競爭優勢。
禧雲集團(以下簡稱禧雲)將大數據列為企業發展戰略,始終秉持『數據驅動』的理念,時刻跟隨大數據發展趨勢。經過幾年的探索和發展,逐步構建起集數據管理、開發協作、自助分析、數據開放和運維管控等於一體的數芯大數據平臺。

圖1:數芯大數據平臺
1.2 數芯大數據平臺介紹
數芯大數據平臺建設始終圍繞『開放共用、數據賦能』的理念,為集團、合作伙伴的運營發展提供強有力的支撐和助力。經過多年的實踐,逐步構建了從底層數據採集、數據處理,到數據應用服務以及數據產品的全鏈路、高管控、開放式的大數據體系。圖2所示,是數芯大數據平臺賦能業務全景圖。
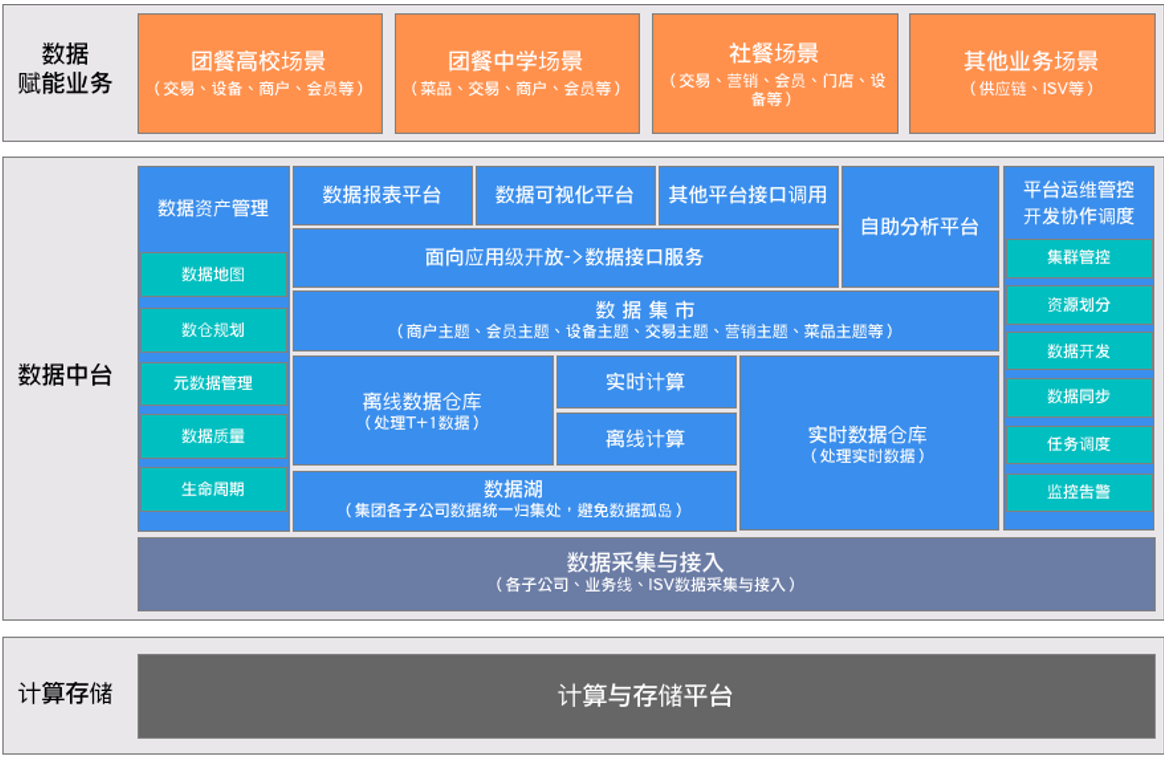
圖2:數芯大數據平臺賦能業務全景圖
為覆蓋數據處理的整個鏈路環節,數芯大數據平臺建設之初,規划了數據資產管理、數據開放共用、開發協作調度、數據採集與遷移管理、數據可視化及自助分析、平臺運維管控六大技術領域,分別對應數芯大數據平臺的不同子系統,我們將在下章節中詳細展開。
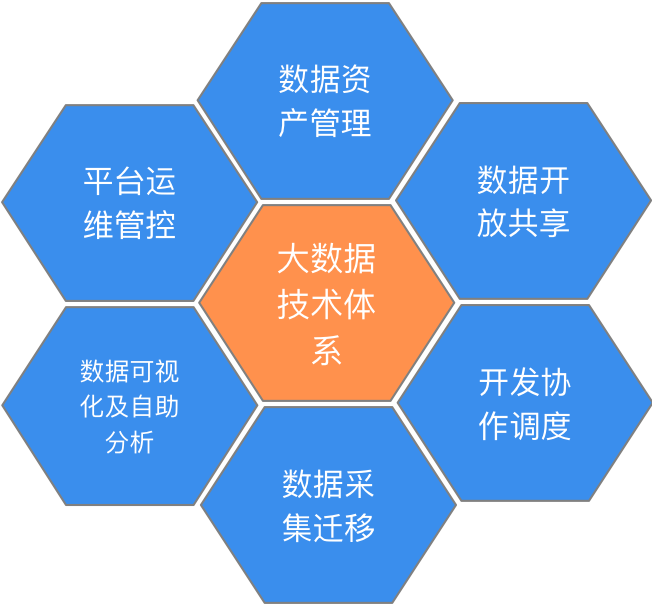
圖3:數芯六大技術領域
從數據生產效率和對外賦能角度,數芯大數據平臺又可抽象出數據產品體系、平臺支撐體系和數據管理體系三大支撐體系。具體作用如圖4所示:
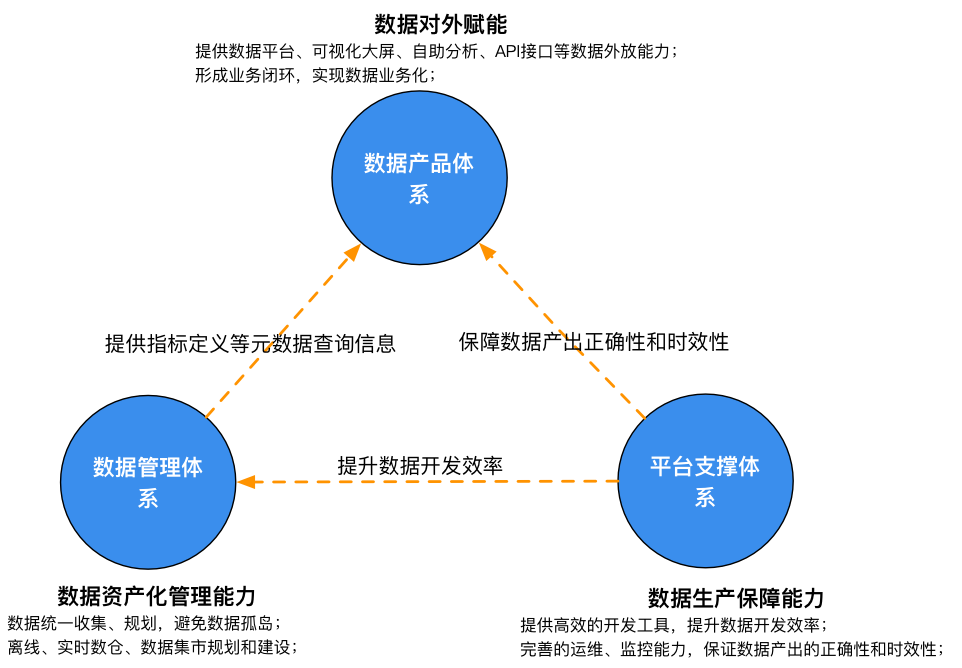
圖4:數芯三大支撐體系
本文以數芯三大支撐體係為章節,本著相互學習、交流的態度,詳細介紹數芯大數據平臺的建設過程。在當前『一切業務數據化,一切數據業務化』的背景下,數據已經成為企業戰略和在市場競爭中取得優勢的關鍵,因此我們以數芯大數據平臺的數據管理體系開篇。
第二章:數據管理體系
禧雲下設信息、數科、世紀品牌等諸多子公司,每個下屬公司或關聯ISV都獨立運營,專註於解決團餐的某一領域業務問題。如果沒有良好的數據管理體系,很容易造成數據煙囪式生產、信息孤島等現象,無法為集團決策部門提供全面立體的數據支撐,大大地降低子公司間的協同增幅能力。
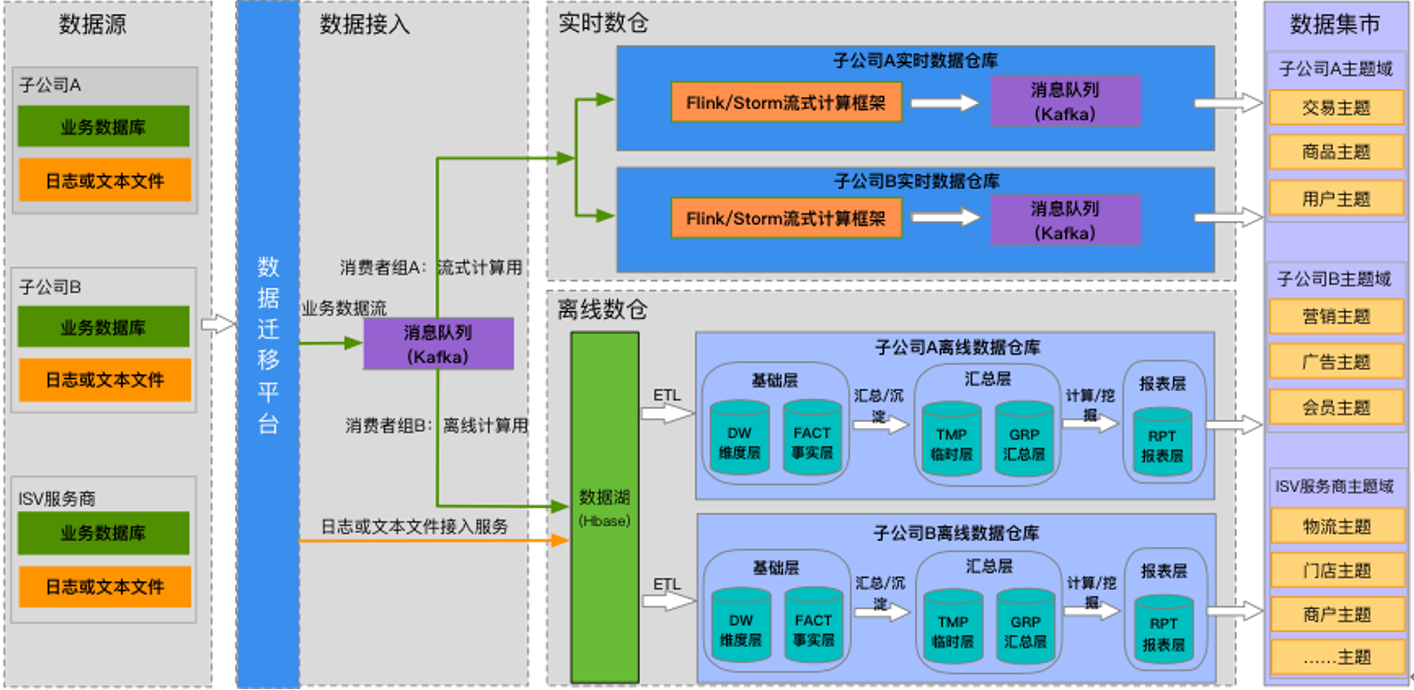
圖5:數據管理體系圖
如圖5所示,數芯大數據平臺數據管理體系在數據接入、數據倉庫規劃建設、數據集市方面制定了統一的規範,對接集團各子公司和關聯ISV,可以構建同時面向集團、各業務單元和子公司的數據分析系統。數據湖、數據倉庫和數據集市加上數據接入、數據清洗、數據生產等規範共同組成了數據管理體系。
2.1 數據湖
·數據湖作用
數據湖的定義以及與數據倉庫的區別,目前業內還沒有達成一致的意見,但許多企業已經開始實踐。數據湖在禧雲的實踐是作為存儲集團各子公司、ISV各種各樣原始數據的大型倉庫,其中的數據可供存取、處理、分析和傳輸。這樣處理主要有以下兩方面優點:
1. 數據統一存儲,統一規劃,可同時支持集團、各子公司和ISV的數據分析業務;
2. 與上游系統解耦,數據一次接入,多次利用,接入後的數據可用於實時分析和數據倉庫建設等不同用途,減少與上游系統的耦合。
·技術解決方案
禧雲數據大多為關係型資料庫和鍵值數據存儲等結構化、半結構化數據,基於數據吞吐性能和查詢分析能力,我們選擇Apache HBase(一個高可靠性、高性能、面向列、可伸縮的分散式資料庫)作為數據湖的技術解決方案。
如圖5所示,上游數據經過自研的數據遷移平臺(第三章:平臺支撐體系部分介紹)會批量或實時寫入數據湖,利用Apache HBase列式存儲的特點,數據遷移平臺解決了上游數據元數據發生變更(例如:增加或刪除欄位)對數據湖的寫入無感知問題。
·數據存儲規範
為合理利用存儲資源,根據數據的不同特點,對存儲在數據湖中的數據制定了相應的數據存儲規範,例如對交易流水等數據量較大的表,在數據倉庫中做好數據分區和備份後,利用Apache HBase TTL(數據生存時間)特性,設置相應的生命周期(生命周期預設保存六個月,指從當前時刻開始向前六個月時間內產生的數據)。
2.2 數據倉庫
為支撐集團運營發展和決策分析,禧雲起建之初構建了完善的數據倉庫體系,我們稱之為離線數據倉庫階段。
隨著市場競爭環境的不斷加劇,企業對數據的時效性要求越來越高,為應對市場變化,從2019年3月份開始規劃實時數據倉庫的建設,到2019年9月份歷時六個月實時數據倉庫結項,中間實時數倉順利支撐了團餐峰值周運營活動。
如圖5所示,現階段數據管理體系中的數據倉庫包含離線數據倉庫和實時數據倉庫兩大部分。
2.2.1 離線數據倉庫
·數據倉庫作用
離線數據倉庫處理T+1(當日產生的數據,下一日才能看到)場景的數據,為企業運營發展提供決策支持。
如圖5所示,離線數據倉庫的數據來源為數據湖,可對接不同子公司的數據,為保證公司間數據相互獨立和許可權劃分,禧雲離線數據倉庫以公司為主線進行建設。
·技術解決方案
數據倉庫依托數芯大數據平臺完整的大數據生態體系進行構建,數據存儲為HDFS、離線計算框架為Hive、Spark、SparkSQL,採用Yarn作為資源隔離與調度框架。在數據分析處理方面,我們通過開發協作平臺(詳見第三章:平臺支撐體系部分)來完成離線計算任務的提交、工作流調度、運行監控等工作。
·數據存儲規範
這裡的數據存儲規範包括數據分層規範和數據命名規範兩種,數據分層是數據倉庫設計中重要的一環,良好的分層設計能夠讓整個數據體系更易理解和使用。三層模型、四層模型是業內比較通用的分層模型,由於數據湖的存在,我們省去了ODS層(操作數據存儲層,存儲原始數據),採用三層模型,為更好的理解和使用數據,我們重新命名了倉庫層級。
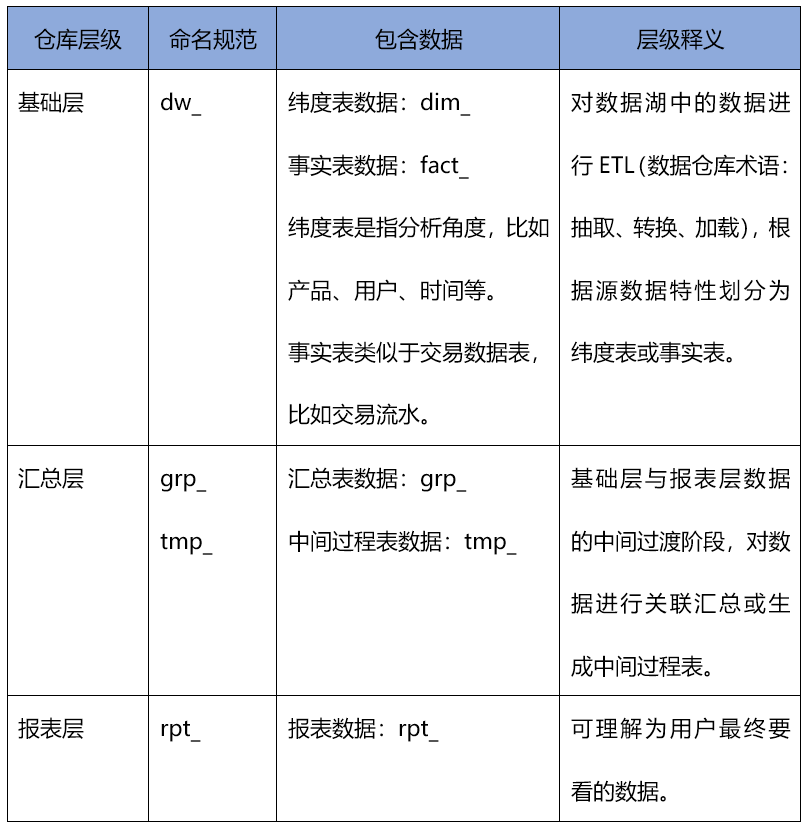
表1:數據存儲規範
2.2.2 實時數據倉庫
·數據倉庫作用
實時數據倉庫主要解決數據時效性問題,禧雲有許多業務場景需要數據的實時支撐,例如不定期舉行的團餐峰值周活動,峰值周會將目標分拆到每一天,運營人員需要實時把控目標完成情況,及時調整策略,確保目標完成。換句話說實時數據倉庫完成T+0(當日產生的數據,當日看到)場景的數據分析工作。
·技術解決方案
實時數倉內部數據流轉如圖6所示:
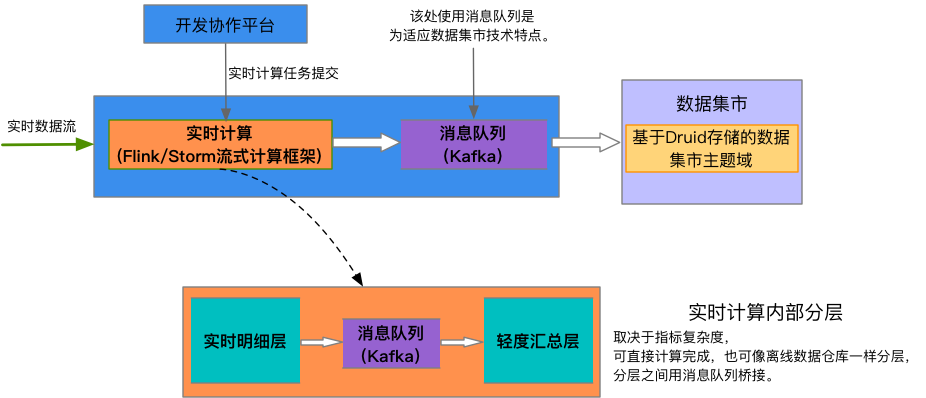
圖6:實時數倉技術架構圖
實時數據倉庫的流式計算框架為Apache Flink和Apache Storm,在實時數據倉庫未正式商用前,Apache Storm是主要的流式計算框架。隨著Apache Flink的普及“批流合一”的計算特性,禧雲內部Flink已經逐步取代Storm。實時數據流在計算框架里計算彙總後,寫入Kafka消息隊列,存入基於Druid存儲的數據集市主題域中。關於Druid部分將在數據集市中詳細介紹。
·數據處理規範
實時數據倉庫層級概念體現在實時計算部分,我們大致可以遵循以下規範,即根據計算指標的複雜度,可直接計算完成(複雜度低),也可像離線數據倉庫一樣分層處理,分層之間用消息隊列橋接。上述規範不強制遵循,但從數據重覆利用(每層數據可用於不同用途)、出現問題排查角度考慮,建議分層處理。
2.3 數據集市
數據集市的建設在禧雲一直是個痛點,整個集團目前還處於快速成長期,業務發展變化快,階段不同側重點不同,因此相同數據指標的定義在不同階段會發生變化,很難固化成某一緯度的主題數據。再加上數據開發需求多,數據指標缺乏統一的規劃和梳理,經常造成相同數據指標重覆開發,不同報表相同指標項數據不一致的現象,給數據使用人員造成了一定的困擾。
為解決上述痛點,我們對數據指標項進行了統一的梳理,發現分類治理可以解決當前問題。我們將數據指標分為活躍指標和穩定指標兩類,具體定義和處理方式如下:

表2:數據集市數據指標定義
在技術解決方案上,我們調研了市面上比較流行的OLAP引擎,從社區活躍度、查詢性能、自身數據特點等方面考慮,我們採用Apache Druid作為數據集市的載體。禧雲數據集市已經開始支持運營人員自助分析和可視化。
·數據集市作用
數據集市在不同企業的實踐過程中有的劃分到數據倉庫中,作為數據倉庫的一個層級,有的作為數據倉庫的下游。數據集市中的數據根據特定的業務或主題組織起來,可以被部門或子公司直接使用。
禧雲數據集市按照各部門或子公司進行劃分,下屬不同主題,例如:交易主題、用戶主題、營銷主題等。集市數據可以直接用於部門或子公司自助分析,也可以經過數據介面服務封裝後供數據報表平臺、數據可視化平臺和其他平臺使用。其中數據介面服務、數據報表平臺、數據可視化平臺將在《第三章:平臺支撐體系》和《第四章:數據產品體系》部分詳細介紹。
·技術解決方案
技術上,禧雲數據集市主要圍繞著Apache Druid來建設,Apache Druid是一個分散式時序資料庫,可滿足以下場景:
- Historical(歷史節點)數據存儲使用HDFS等分散式文件存儲系統,高可用,支持水平擴容;
- Lambda架構(詳見附錄2),Realtime(實時節點)使用LSM-Tree實現,滿足流數據的即時查詢需求。
- 支持SQL查詢。
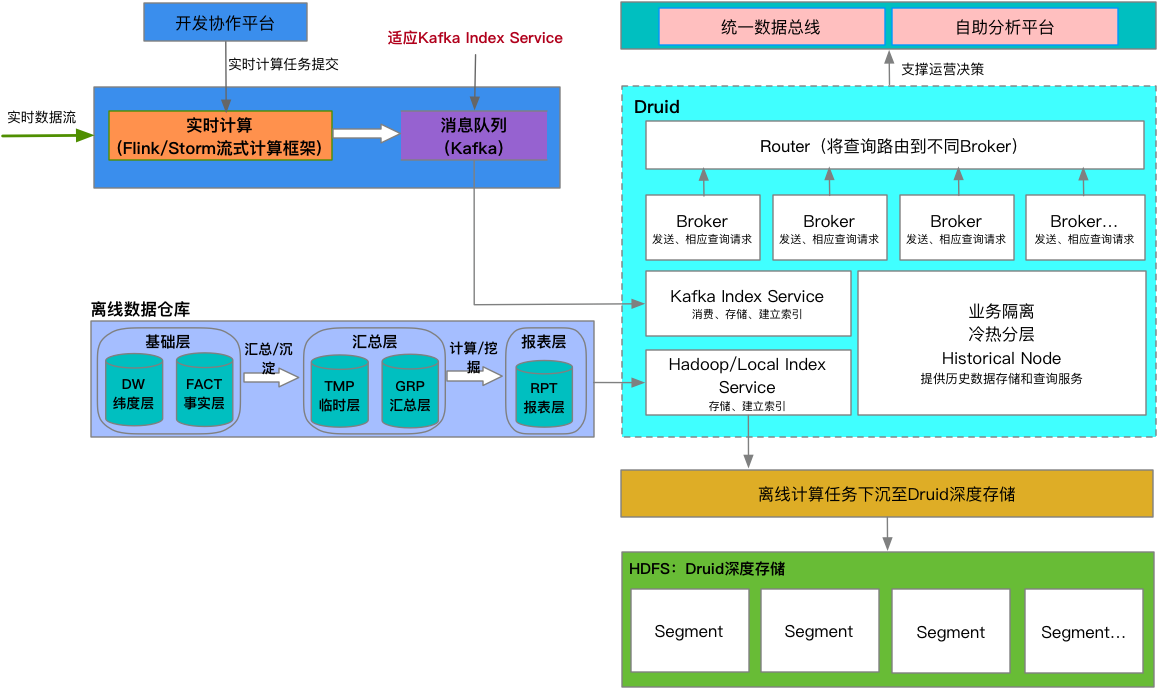
圖7:數據集市技術架構圖
從上圖可以看出,數據倉庫生產的數據通過Apache Druid提供的寫入服務進入數據集市,實時數據倉庫的數據,可以支持快速查詢,分析。離線數據倉庫的數據根據具體業務場景,進行冷熱分層處理,經常被使用的數據做到高效查詢。
·數據存儲規範
禧雲數據集市目前處於剛起步階段,我們現在僅制定了比較簡單的命名規範,來區分一級部門或子公司、所屬主題和具體使用場景。命名規範如下圖所示:
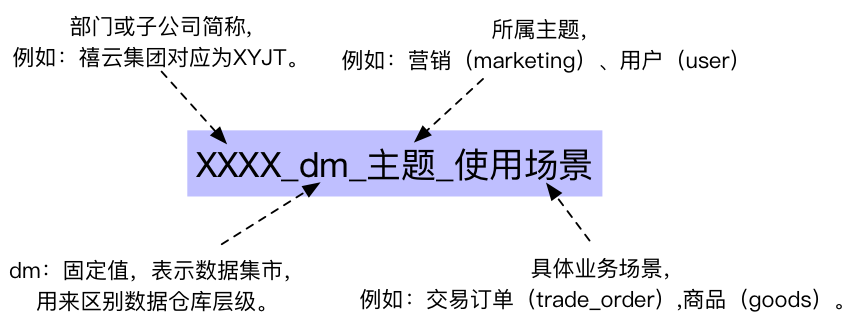
圖8:數據集市命名規範
2.4 本章小結
數據湖、數據倉庫、數據集市以及相應的管理規範共同構成了禧雲的數據管理體系。我們在講述過程中沒有過多介紹數據倉庫和數據集市的概念、模型(星型、雪花、星座等)等約定俗成的東西,而是將重點放在數據流程和技術實現上,主要是想跟大家探討我們在數據體系建設過程中遇到的痛點和如何解決的,拋磚引玉,起到相互促進的作用。
本章內容在講述數據管理體系的基礎上,同時引出了我們的數據生產流程,穩定、高效的生產流程是支撐決策分析的前提條件,為此我們構建了比較完善的平臺支撐體系。
第三章:平臺支撐體系
禧雲數據平臺支撐體系旨在提供高效的開發工具,提升數據開發人員工作效率,提供完善的運維、監控能力,保證數據生產的正確性和時效性。平臺支撐體系從數據接入、數據計算、數據服務和數據應用四個層級為數據生產提供全方位的支持和保障。

圖9:數芯大數據平臺技術架構圖
如上圖所示,平臺支撐體系由數據遷移平臺、開發協作平臺、數據質量平臺、數據開放平臺、數據介面服務,以及貫穿數據接入層、計算層和服務層的運維監控平臺六大子系統組成。我們按照上述順序展開每個子系統的具體實現方式。
3.1 數據遷移平臺
數據遷移平臺(代號:移山,以下簡稱移山),是集第三方數據接入、實時數據同步、異構數據源間遷移於一體的一站式解決方案。提供簡潔、易用的圖像化界面,完成數據接入、同步或遷移等配置工作。目前移山每日完成千萬級第三方數據接入、億級內部數據遷移和實時數據同步工作。
·產生背景
在移山之前,禧雲在數據遷移方面主要面臨以下三個問題:
1. 實時同步:禧雲採用阿裡開源的Canal(主要用途是基於MySQL資料庫增量日誌解析,提供增量數據訂閱和消費)作為數據實時同步組件,下游解析資料庫數據變更事件寫入Kafka消息隊列,消息隊列里的數據供實時數倉分析使用或寫入數據湖。上述實現通過腳本的方式配置完成,操作複雜並且容易出錯。
2. 數據遷移:離線數倉分析結果導出和計算任務封裝在一個Spark計算任務中,數據計算和數據導出耦合性較高,數據導出時間過長會出現計算資源不能釋放或計算任務假死等現象。除此之外,缺少統一的異構數據源遷移工具。
3. 第三方數據接入:第三方數據接入主要採用點對點方式,每次對接都需要單獨開發程式,沒有統一的數據標準,數據接入時間周期較長。
·技術實現
為解決上述三個問題,構建一個通用的數據遷移平臺,我們對現有程式重新設計、開發,調研業界開源的異構數據源遷移工具。移山在上述整合的基礎上產生,移山提供以下三種數據遷移服務能力:
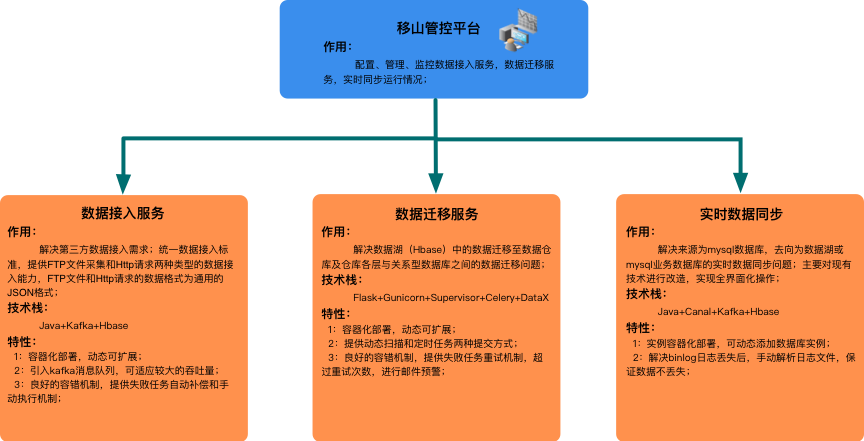
圖10:移山技術架構圖
- 數據接入服務
數據接入服務約定JSON格式為統一的數據傳輸格式,支持HTTP請求和FTP文件採集兩種數據接入能力。數據接入服務通過暴露HTTP請求介面的方式對外提供服務,請求類型根據介面參數不同分為消息指令和業務數據上報兩種。數據接入流程如下圖所示:
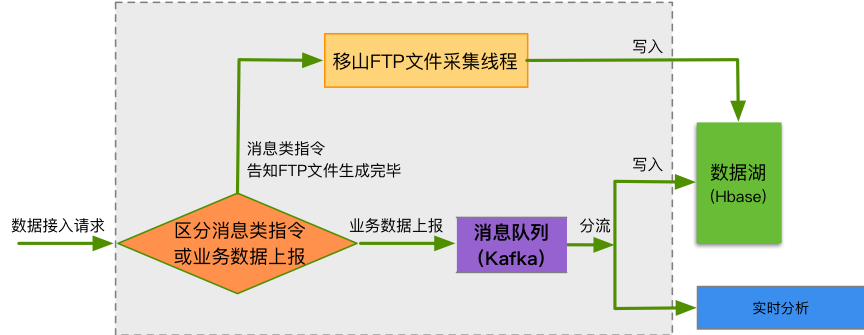
圖11:數據接入服務流程圖
- 數據遷移服務
我們採用阿裡開源的DataX(詳見附錄1)作為數據遷移服務組件。DataX配置過程比較複雜,並且只支持命令行方式執行,為降低使用難度,我們將配置過程進行了圖形化處理,採用Python的Flask框架進行封裝,任務執行支持HTTP請求調用。數據遷移服務支持定時或指令兩種執行方式,具體作用如下:
定時執行:定時拉取數據湖數據到數據倉庫中或定時執行業務庫間數據遷移工作。
指令執行:接收離線任務計算發送的數據遷移指令,將分析結果數據遷移至數據集市對應存儲中。
依托DataX強大的插件體系,數據遷移服務支持目前主流的RDBMS資料庫、NOSQL資料庫、HDFS大數據存儲之間的數據遷移能力。
- 實時同步服務
禧雲各子公司的數據大多以關係型資料庫MySQL為主,目前的實時同步服務只針對MySQL進行同步,數據同步服務採用阿裡開源的Canal作為同步組件,業務數據經過Canal寫入Kafka消息隊列,Kafka中的數據根據需要寫入資料庫或供實時分析使用。
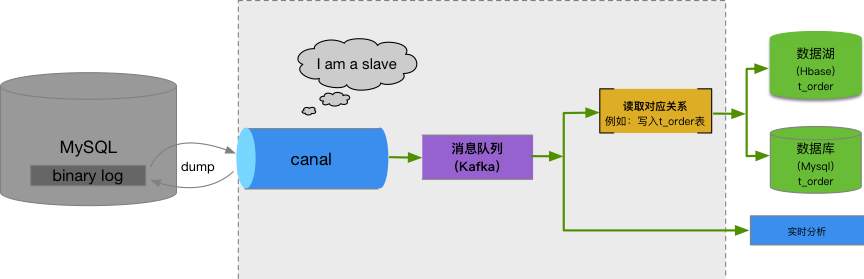
圖12:實時同步服務流程圖
業務系統會產生各種類型的數據,例如訂單數據、日誌數據等,而下游數據分析往往只針對某一類型數據,為了不造成存儲等資源浪費,實時同步服務通過對應關係表來管理數據同步,例如,離線數據分析要用到業務庫的訂單表t_order,需要在移山實時同步任務中添加t_order對應關係,上游數據才能同步到數據湖或資料庫中。如圖12所示,同步到數據湖中的數據與上游業務庫數據需要保持最終一致性,數據在Kafka消息隊列傳輸過程中可能會出現亂序,導致數據最終不一致。我們在實時同步服務中通過比對binary log時間戳和偏移量,結合HBase特性解決上述亂序問題。我們以t_order表數據寫入來解釋亂序的處理過程。
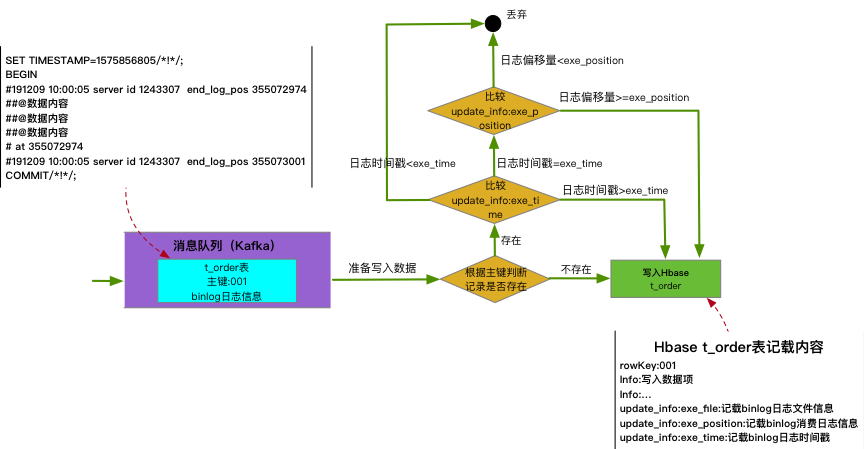
圖13:實時同步亂序處理過程
移山將數據接入、數據遷移和實時同步整合在一個平臺中,開發人員只需要簡單的界面化配置,就可完成上述三種操作。為保障數據遷移的穩定性和可靠性,移山同時具備完善的監控報警和數據分析能力。
3.2 開發協作平臺
開發協作平臺(代號:魔盒,以下簡稱魔盒),是一套幫助數據開發人員完成離線、實時計算任務打包、測試、數據核驗和發佈上線等工作的一套調度和管理系統。魔盒對離線計算任務提供串列、並行等複雜工作流設置,並提供完善的任務運行監控報警體系。
·產生背景
禧雲數據分析主要分為實時計算任務和離線計算任務兩種。在魔盒之前,上述兩種任務主要通過在終端伺服器上運行命令行方式執行,任務之間的依賴依靠腳本來控制。在任務比較多的情況下,管理起來比較困難,出現問題難以排查,直接影響數據生產。
·技術實現
為保障數據正常生產,提高開發人員工作效率,我們從資源劃分(測試環境資源、生產環境資源)、任務管理、程式打包上線和運行監控報警等方面重新規劃,開發出了開發協作平臺魔盒。
- 離線計算
離線計算為多種業務場景提供基礎計算能力,針對不再變化的數據進行分析,具有計算數據量大、業務邏輯複雜等特點,禧雲離線計算支持Hive、Spark等計算框架,Hive主要用於臨時數據分析,Spark為離線計算任務的主要開發框架。開發人員用Spark或SparkSQL編寫完分析代碼後,通過魔盒打包上線。測試、上線流程如下圖所示:
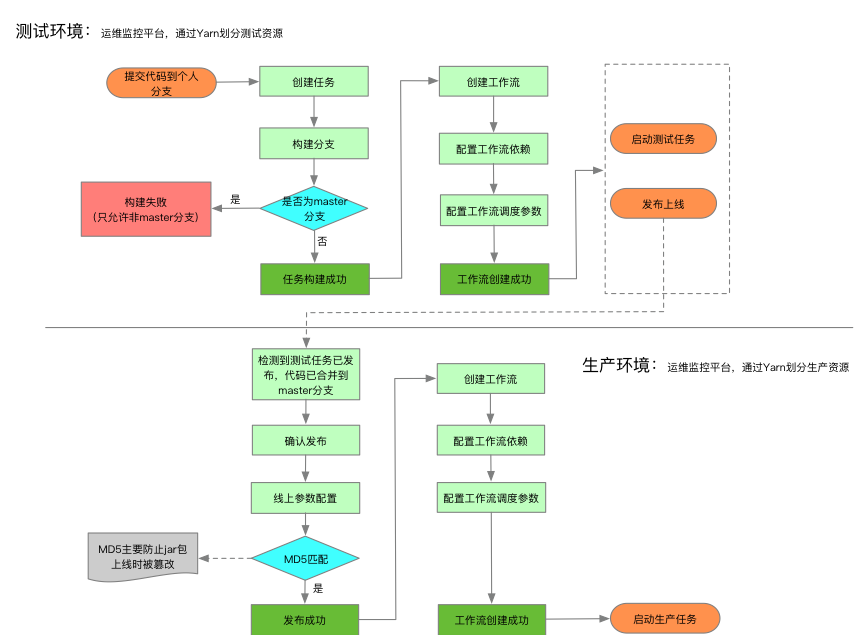
圖14:離線計算任務測試上線流程
禧雲每天運行著上百個離線分析任務,每個分析任務服務於不同子公司或業務場景,任務之間會有依賴關係,不同優先順序的任務調度時機不同。基於以上問題,魔盒的離線計算部分集成了Linkedin開源的工作流引擎Azkaban。離線計算任務工作流提交過程如下圖:
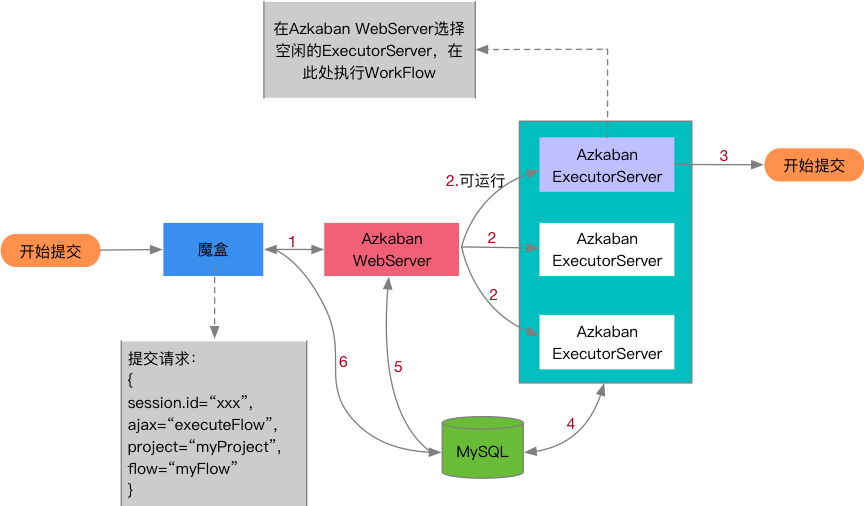
圖15:離線計算任務工作流提交過程
1. 魔盒提交請求到AzkabanWebServer;
2. AzkabanWebServer將任務分發到可運行的執行器上;
3. 執行工作流;
4. 將執行過程產生的元數據信息寫入MySql資料庫。
5. AzkabanWebServer讀取MySql數據監控任務執行狀態。
6. 魔盒讀取MySql數據監控任務執行狀態。
目前魔盒離線計算任務支持串列、並行等複雜工作流設置,如下圖:

圖16:複雜工作流設置
- 實時計算
禧雲目前在用的實時計算框架為Apache Storm和Apache Flink。Storm主要相容以前的實時分析任務,隨著Flink開源社區的活躍和批、流合一的優勢,在禧雲內部Flink將逐漸取代Storm。因此魔盒實時計算目前僅支持Flink計算框架。魔盒實時計算的測試和上線過程如下圖17所示:
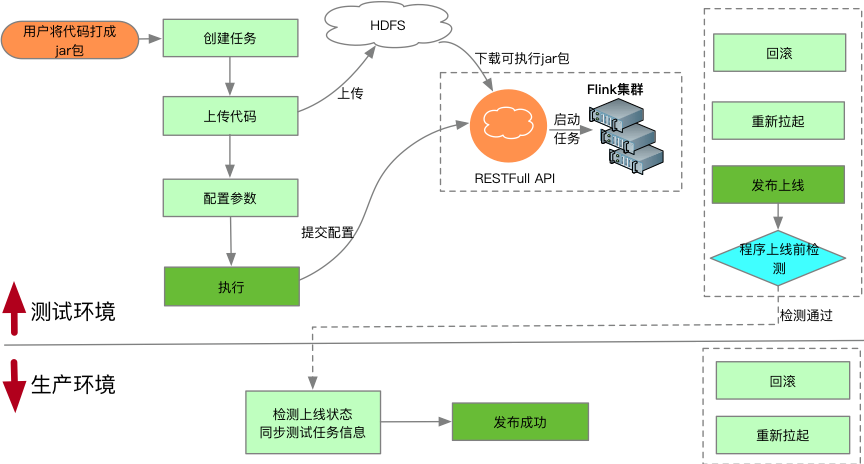
圖17:實時計算任務測試上線流程
實時計算任務(流計算)上線後會長期運行,運行中可能由於伺服器宕機等原因導致任務運行失敗、數據丟失。為避免上述問題發生,魔盒報警體系會檢測實時任務運行狀態,一旦失敗將立即報警。為防止數據丟失,結合Flink的CheckPoint機制,魔盒對運行失敗的任務提供重新拉起操作。重新拉起時魔盒會自動檢測失敗任務的上一個檢查點(CheckPoint),預設從上一個檢查點處開始執行,開發人員也可以手動輸入檢查點路徑進行拉起。
- 監控報警
為保證計算任務正常運行,魔盒具備完善的監控報警體系,魔盒報警體系根據計算任務分為以下兩類:

表3:魔盒監控報警分類
魔盒已經成為禧雲數據開發人員主要的工作平臺。在流程規範性和開發效率上極大地提高了開發人員的工作效率。完善的監控報警體系能夠保障數據生產的穩定性和時效性。
3.3 數據質量平臺
隨著大數據技術的普及,『數據即資產』的觀念已經成為共識。數據資產化需要將雜亂無章的數據進行合理有效的組織,同時需要考慮到隱私、合法、合規等數據確權問題,因此數據資產化進程必將是一個緩慢、複雜的過程。然而,良好的數據質量是數據資產化的前提條件。數據質量平臺(代號:能量塊或元數據管理系統,以下簡稱能量塊),是禧雲進行數據資產化的第一步,主要解決數據倉庫元數據管理、數據血緣關係、生命周期和業務數據監控等當前工作中亟需解決的問題。
·產生背景
禧雲在生產過程中產生了大量的業務數據,數據在進入數據倉庫的過程中會產生大量的元數據信息。上述元數據信息在使用過程中主要面臨以下問題:
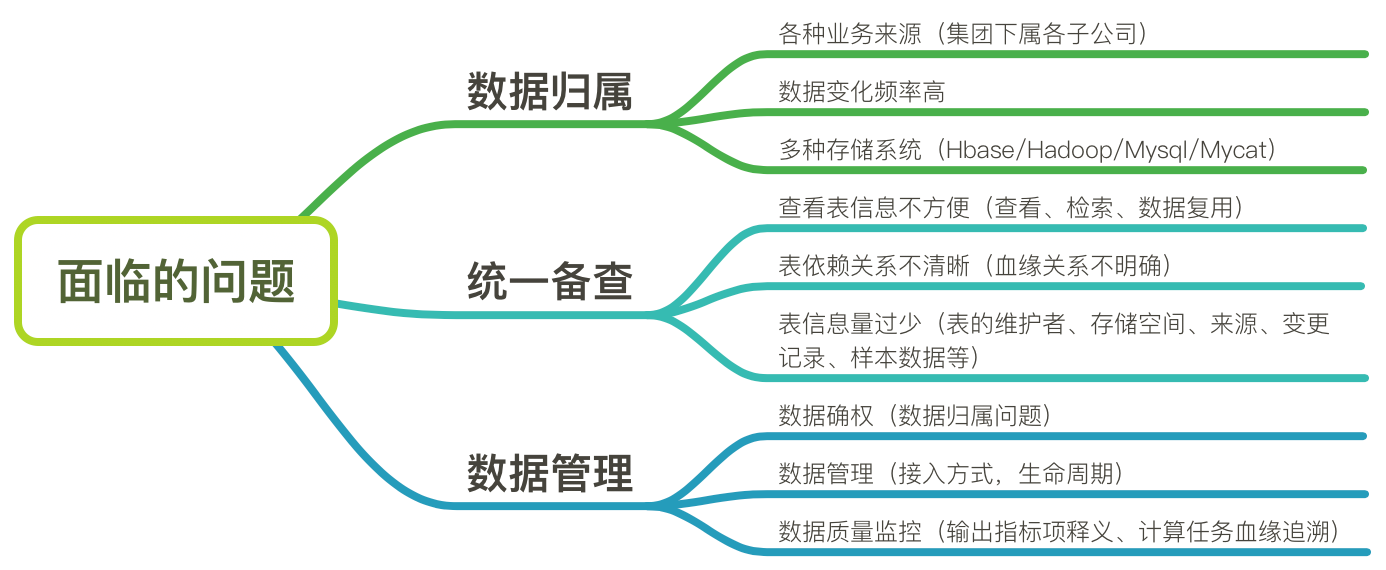
圖18:數據質量管理面臨的問題
為解決上述問題,邁好數據資產化進程的第一步,我們首先從數據歸屬、元數據統一備查和數據管理三個方面入手,來建設數據質量平臺。
·技術實現
- 基本概念
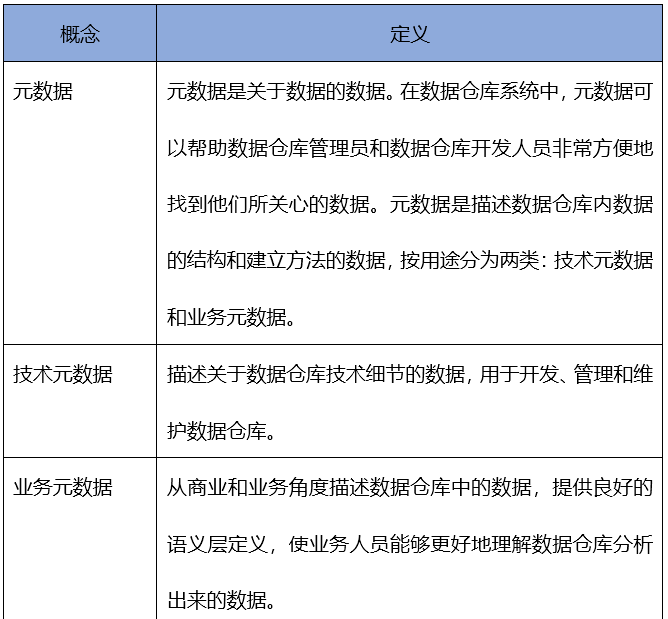
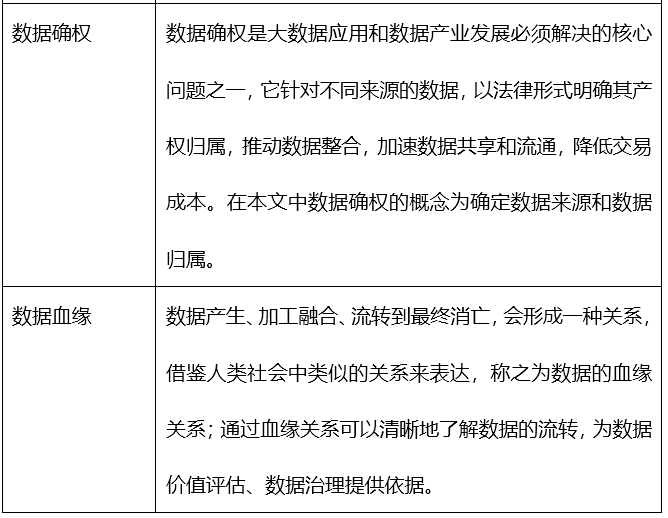
表4:數據質量平臺基本概念
- 元數據管理
能量塊中的元數據管理主要從數據倉庫表級確定數據歸屬(例如禧雲信息團餐業務線),按照技術元數據和業務元數據為數據開發人員和使用人員提供統一查詢入口。元數據信息包含以下信息:
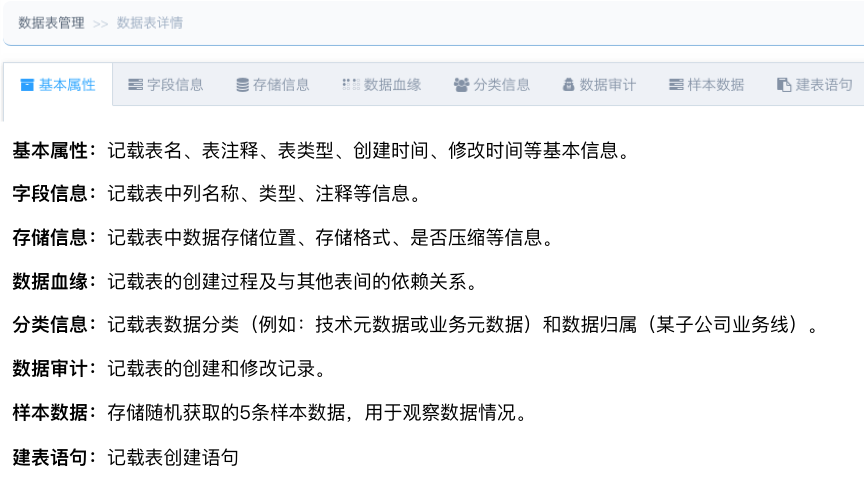
圖19:元數據管理詳細信息
為實現上述功能,我們調研了很多業內元數據管理方面的開源框架,從體繫結構完整度和自身技術特點方面考慮,我們選擇Apache Atlas作為能量塊的元數據管理框架。
- 血緣關係採集
在禧雲一個複雜的離線數據分析任務,需要經過多表關聯,外加很多約束條件限制。業務人員對某個數據指標提出質疑時,數據開發人員需要重新梳理該指標的邏輯,甚至需要翻看代碼,費時費力。
為降低問題排查和解釋成本,我們在離線計算任務中集成Spline(from Spark lineage),通過解析Spark執行計划動態生成計算任務血緣關係圖譜。
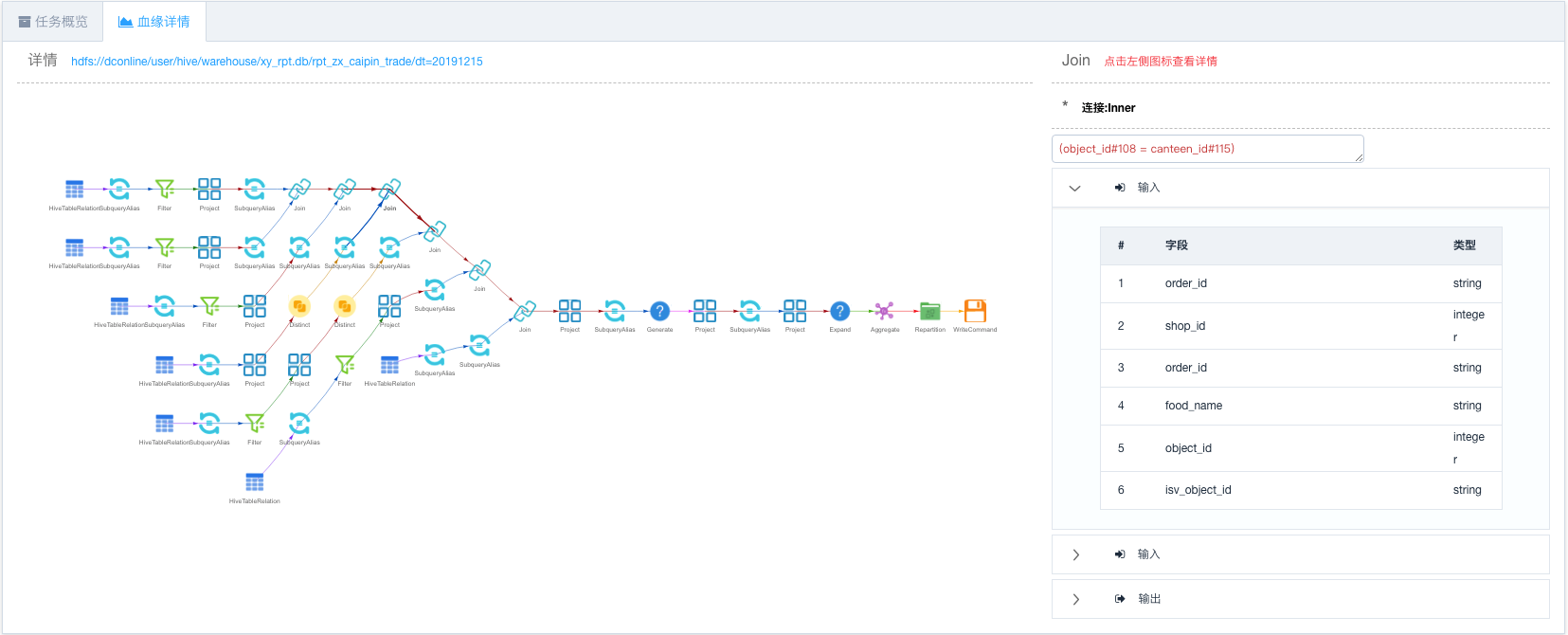
圖20:離線計算血緣關係圖譜
開發人員或業務人員在能量塊的圖形化界面上,可以清晰地瞭解數據指標的計算過程,極大地提高了問題排查和邏輯梳理效率。
- 數據質量監控
數據倉庫作為業務數據的下游,經常會出現上游業務數據發生變更,導致數據分析結果不正確的現象。為避免上述問題產生,我們在與上游業務方建立溝通機制的基礎上,在能量塊中增加了數據質量監控模塊。
數據質量監控模塊用於監控數據指標的上下游數據情況,例如:每日訂單數據是否在合理的數據範圍內。對此,我們根據業務線制定了不同的規則引擎,在關鍵數據指標計算前,首先觸發規則引擎,規則引擎校驗通過後,才能進行數據計算。對校驗不通過的數據,第一時間通知到上游業務方處理。
能量塊除上述功能外,還具有數據使用情況統計功能,對未使用的數據提供下線清理操作。目前能量塊僅僅解決了數據歸屬、元數據統一備查和簡單的數據監控管理功能,數據質量和資產管理是個很大的課題,禧雲剛剛完成了小升初,後續還有很多東西要學,數據質量的好壞直接關係到信息的精準度,影響到企業的生存和競爭力,禧雲將在該方面加大投入力度。
3.4 數據開放平臺
禧雲數據開放平臺(代號:數據開放實驗室,以下簡稱實驗室),是一套安全、高效、自助式的數據開放平臺,實驗室在不暴露隱私數據的前提下,通過多種安全機制實現數據授權,為使用人員提供SQL互動式查詢分析、數據定製下載能力,對分析結果提供自助式報表配置功能。
·產生背景
隨著業務的發展,禧雲在數據支撐方面的需求越來越多,單純依靠數據部門提供數據支持,已日漸捉襟見肘。再結合禧雲數據方向的發展戰略,亟需將數據分析能力下放到各部門、子公司或ISV手中。數據開放實驗室在此背景下產生。
·技術實現
實驗室可將數據倉庫、數據集市中的數據授權給各部門、子公司或ISV進行查詢分析。為保證數據安全和企業間數據相互隔離,實驗室在實現過程中定義了企業專區的概念,一個企業專區可以理解為一個部門、子公司或ISV。企業專區由實驗室後臺管理負責開通,專區內設管理員和操作員,管理員負責添加操作員賬號,操作員可在實驗室內進行查詢分析、數據下載、報表配置等操作。實驗室架構圖如下圖所示:
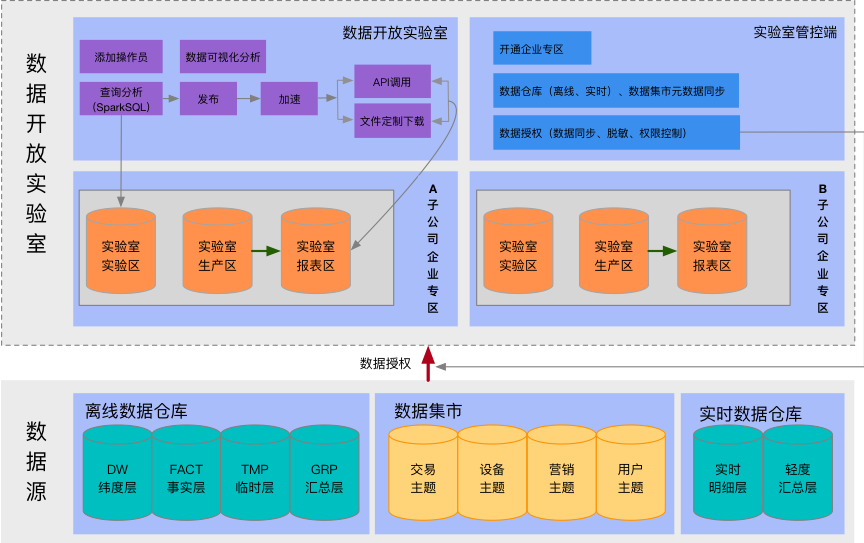
圖21:數據開放實驗室架構圖
專區內又分為實驗區、生產區和報表區,具體概念如下表所示:
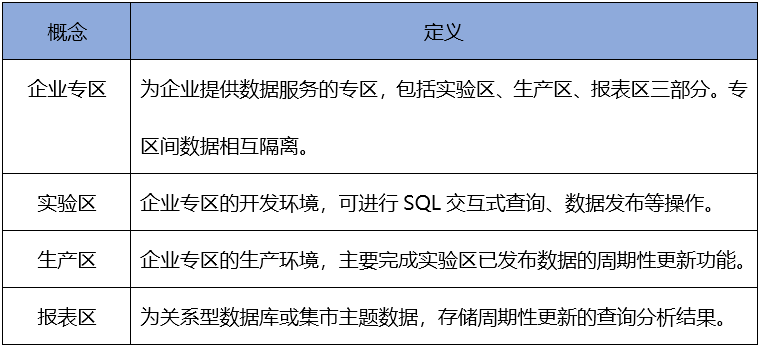
表5:分區定義
數據開放實驗室在技術實現上分為後臺管理(實驗室管控端)和查詢分析(數據開放實驗室)兩部分。
- 實驗室管控端
適用人員為數據部門的數據管理人員,管控端主要完成數據倉庫、集市等元數據同步、企業專區開通、數據授權等操作。
數據管理人員根據各部門、子公司或ISV申請,開通企業專區賬號,賬號開通後由企業專區負責人添加操作員賬號。
企業專區賬號開通後,數據管理人員根據數據授權申請,向企業專區進行數據授權,授權流程如下圖所示:
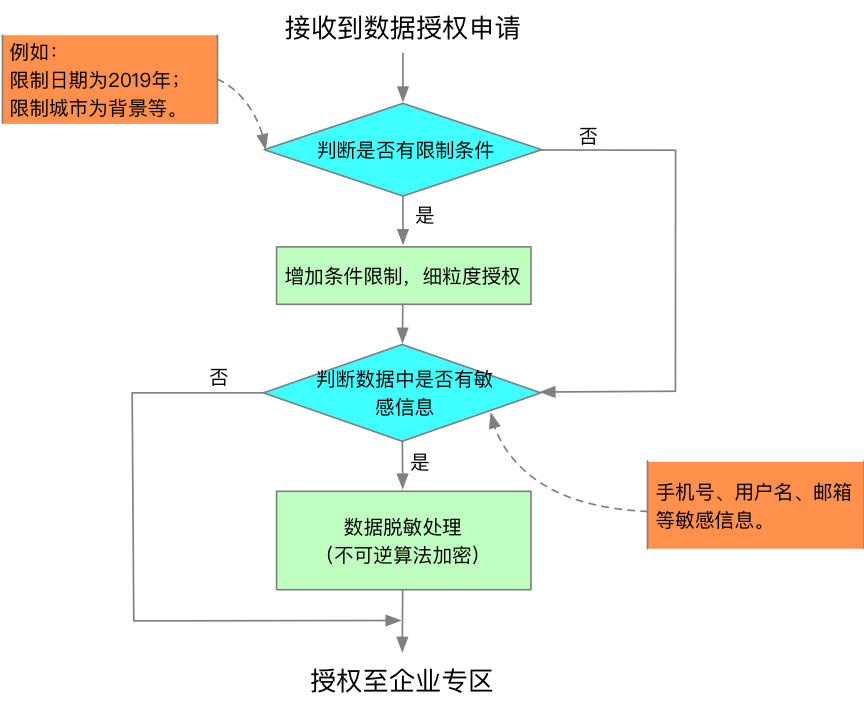
圖22:實驗室管控端授權流程
為做到相互隔離和數據安全,實驗室管控端通過條件限制控制數據的授權,對手機號、身份證號、郵箱等敏感信息管控端採用加密演算法防止數據泄露。
- 數據開放實驗室
數據開放實驗室適用人員主要為部門、子公司、ISV的查詢分析人員。實驗室對查詢分析結果提供定製下載、API介面調用和報表配置三種數據輸出能力。
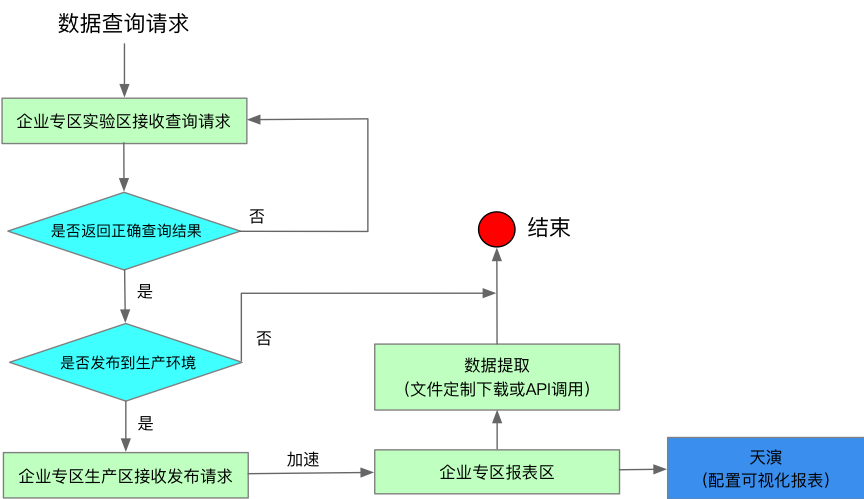
圖23:實驗室查詢發佈流程
為方便查詢使用,實驗室對已授權數據提供詳細的元數據信息。此外,實驗室還集成了可視化平臺用於報表配置。數據開放共用是指按照統一的管理策略對組織內部的數據進行有選擇的對外開放,是實現數據跨組織、跨行業流轉的重要前提,也是數據價值最大化的基礎。數據開放共用能力,是衡量企業數據管理能力成熟度的重要衡量指標。數據開放實驗室通過安全、高效的授權策略打通了數據倉庫與各部門、子公司和ISV之間的數據壁壘,通過互動式查詢和可視化報表配置等功能將數據分析能力賦予禧雲各下屬企業。數據開放實驗室標志著禧雲數據的開放共用能力得到了進一步的提高。
3.5 數據介面服務
數據介面服務(代號:API服務),對外提供統一的數據調用介面和數據返回格式,用於數據報表平臺、可視化平臺和其他平臺的數據請求調用。數據介面服務基於RESTFul架構進行介面封裝,實現了數據與應用程式的解耦,有利於數據復用和各應用系統集成。
·產生背景
隨著業務的發展,禧雲各下屬企業需要數據支撐的場景越來越多(例如支付寶和微信小程式,移動客戶端等),數據獲取方式日漸多樣化,禧雲數據部門在數據提供方式上的局限性越來越明顯。主要表現在以下兩方面:
- 報表平臺與數據耦合性太嚴重,數據復用性不高;
- 數據提供方式單一,其他業務系統集成難度較高。
·技術實現
不同業務場景對數據的時效性和靈活性要求不同,例如:運營調度對數據時效性要求比較高;運營分析對數據統計的靈活性要求比較高。因此,禧雲數據集市採用MySql、Druid、HBase、Redis等不同存儲方式應對上述場景。
數據介面服務將不同的數據存儲封裝成不同的數據服務群,採用Spring Cloud微服務框架進行統一管理。總體架構如下圖所示:

圖24:數據介面服務架構圖
數據開發人員根據具體業務場景,將數據集市中的數據通過數據遷移平臺輸出到不同的數據存儲中。數據使用方通過調用數據介面服務對外暴露的介面來獲取數據。- 後臺管理數據介面服務以應用為單位對外提供數據,後臺管理負責開通應用訪問許可權和服務監控報警等工作。應用訪問許可權開通主要包含應用註冊(生成appId),生成應用訪問公私鑰,應用訪問安全限制(IP白名單,數據訪問許可權等)。- 數據請求流程應用訪問許可權開通後,數據使用方按照介面參數標準來獲取數據,獲取數據流程如下:
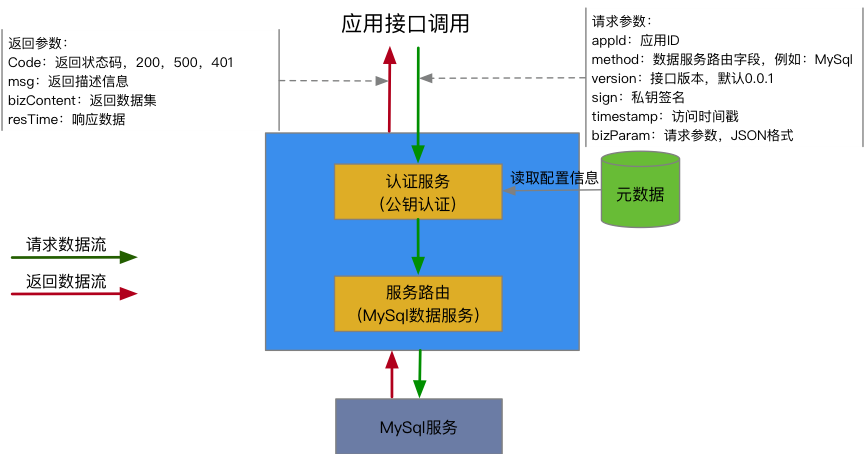
圖25:API服務數據獲取流程
數據介面服務通過統一的傳入和輸出標準對外提供數據,實現了數據與應用程式的解耦,極大地提升了數據的復用性。靈活的數據輸出方式方便了其他業務系統的集成,加快了數據流通速度。
3.6 運維監控平臺
考慮到目前正在使用的大數據生態體系,禧雲運維監控平臺(代號:磐石)直接使用Ambari大數據生態組件管理系統。Ambari包含安裝部署、配置管理、監控告警等大數據組件與集群管理功能,完全滿足禧雲在大數據集群上的運維和監控要求。
|
組件名稱 |
版本 |
說明 |
|
Ambari |
2.7.3.0 |
|
|
Hadoop |
3.1.1 |
|
|
Yarn |
3.1.0 |
|
|
Tez |
0.9.0 |
|
|
Hive |
3.1.0 |
對時間函數進行改造 |
|
HBase |
2.0.0 |
|
|
Sqoop |
1.4.7 |
|
|
ZooKeeper |
3.4.9 |
|
|
Storm |
1.2.1 |
|
|
Infra Solr |
0.1.0 |
|
|
Atlas |
0.7.0 |
|
|
Kafka |
1.0.0 |
|
|
Spark2 |
2.3.0 |
|
|
Druid |
0.15.1 |
|
|
Flink |
1.7.2 |
|
|
Superset |
0.28.1 |
二次開發 |
表6:大數據生態組件版本
Ambari相關介紹在這裡不再闡述,詳細細節請參照附錄3。上表為禧雲正在使用的大數據各組件版本信息。
3.7 本章小結
數據遷移平臺、開發協作平臺、數據質量平臺和運維監控平臺涵蓋了禧雲數據生產輸出、開發協作、質量監控和大數據集群運維監控整個數據生產流程。合理有效的的架構體系和方便易用的圖形化操作界面,極大地提高了數據開發人員和運維人員的工作效率。數據開放平臺和數據介面服務,通過安全靈活的方式為數據使用方賦能。平臺支撐體系和數據管理體系從技術和數據角度闡述了禧雲大數據體系的建設過程,在此基礎上禧雲還構建了完善的數據產品體系。
第四章:數據產品體系
隨著大數據的發展,數據產品的概念變得更加寬泛,我們在平臺支撐體系裡講的數據遷移平臺、數據質量平臺等廣義上也可以歸結到數據產品體系中。在本章內容中所說的數據產品體系是指報表平臺、可視化大屏等數據應用產品。為提供更方便快捷的大數據應用服務,禧雲打造了服務於集團各子公司和部門的數據產品體系。根據數據使用角度不同,產品體系分為數據報表平臺、自助分析平臺和數據可視化平臺三部分。
4.1 數據報表平臺
數據報表平臺(代號:禧鵲數據)是專門為業務運營人員和管理層打造的一款提升運營效率和決策效率的數據化運營產品。報表平臺整合了高校、中學等多個業務單元的相關指標,提供一站式數據展現服務。緯度方面覆蓋商戶、門店、項目、設備等,便於業務人員從不同角度分析數據指標。數據報表平臺提供列表、曲線圖等豐富圖形組件來完成報表配置工作,通過完善的許可權設計,可以為管理層、業務運營人員分配不同的數據許可權。- 適用範圍管理層、業務運營人員等。
4.2 自助分析平臺
自助分析平臺(代號:天演)是一款為數據分析師或數據分析人員開發的一站式自助分析平臺。自助分析平臺已與數據開放實驗室打通,數據分析人員可將實驗室中發佈的報表數據通過天演進行可視化分析。我們在數據開放平臺部分已經介紹了數據開放實驗室,實驗室通過安全靈活的授權方式將數據授權給數據分析人員,分析人員在實驗室中完成數據分析工作後,可在天演中探索數據,生成報表等操作。- 適用範圍數據分析師、數據分析人員等。
4.3 數據可視化平臺
數據可視化平臺(代號:數屏),是禧雲自主研發的數據可視化平臺,它可以通過圖形化界面快速搭建運營監控大屏、峰值日數據戰報,提供豐富的可視化組件,滿足業務監控、會議展覽、投資咨詢等多種展示需求,同時還可以自適應手機等移動設備。
- 適用範圍
業務監控、會議展覽、投資咨詢等。

4.4 本章小結
數據產品體系依托完善的數據管理體系和平臺支撐體系,滿足禧雲管理層、數據分析人員、運營人員等不同角色的數據需求。隨著『業務數據化,數據業務化』觀念的逐步深入,禧雲將在數據智能、數據創新等方面投入力度,利用數據為企業賦能,為禧雲服務的商家賦能。
第五章:未來規劃及展望
2019年數據中台概念變得火熱,被譽為大數據的下一站,核心思想是數據共用。數據中台以數據倉庫和數據中心為基礎,通過數據技術,對海量數據進行採集、計算、存儲、加工,同時統一標準和口徑,形成大數據資產層,進而為企業、客戶提供高效服務。禧雲始終圍繞『開放共用,數據賦能』的理念來進行數據建設,與數據中台的構建思路不謀而合。數據管理體系、平臺支撐體系和數據產品體系從數據資產管理、數據開放共用、開發協作調度、數據採集遷移、數據可視化及自助分析和平臺運維監控六個維度共同構成了禧雲的數據中台體系。隨著市場競爭環境日益加劇,如何利用數據推動企業發展,保持市場競爭力是目前大多數企業面臨的問題。禧雲將在現有數據中台的基礎上,穩步提升數據資產質量,加大數據智能投入,利用數據賦能業務,完成企業的數字化轉型。逐步實現『一切業務數據化,一切數據業務化』的生產閉環,為商家、合作伙伴、集團提供更好的服務,利用數據為產業賦能,讓天下沒有難做的團餐生意!
附錄
1:DataX:阿裡巴巴開源的離線數據同步工具,實現多種異構數據源間的數據同步功能。具體使用參照:https://github.com/alibaba/DataX。
2:Lambda架構:大數據平臺比較通用的架構,由Apache Storm作者Nathan Marz提出,是為了在處理大規模數據時,同時發揮流處理和批處理的優勢。http://lambda-architecture.net/。
3:Ambari:Apache基金會頂級開源項目,是一個集中部署、管理、監控大數據生態集群的工具。https://ambari.apache.org/。
關註“雲縱達摩院”公眾號,回覆關鍵詞“白皮書”即可獲得白皮書PDF下載鏈接。



