
Redis持久化 官方文檔: https://redis.io/topics/persistence Redis用戶認證 redis預設開啟了保護模式,只允許本地迴環地址登錄並訪問資料庫 禁止protected mode protected mode yes/no (保護模式,是否只允許本地訪問) ...
Redis持久化
官方文檔:
https://redis.io/topics/persistence
1.RDB和AOF優缺點
RDB: 可以在指定的時間間隔內生成數據集的時間點快照,把當前記憶體里的狀態快照到磁碟上
優點: 壓縮格式/恢復速度快,適用於備份,主從複製也是基於rdb持久化功能實現
缺點: 可能會丟失數據
AOF: 類似於mysql的binlog,重寫,、每次操作都寫一次/1秒寫一次,文件中的命令全部以redis協議的格式保存,新命令會被追加到文件的末尾
優點: 安全,有可能會丟失1秒的數據
缺點: 文件比較大,恢復速度慢
2.配置RDB
#900秒內有一個更改,300秒內有10個更改,.......
save 900 1
save 300 10
save 60 10000
dir /data/redis_6379/
dbfilename redis_6379.rdb
結論:
1.執行shutdown的時候,內部會自動執行bgsave,然後再執行shutdown
2.pkill kill killall 都類似於執行shutdown命令.會觸發bgsave持久化
3.恢復的時候,rdb文件名稱要和配置文件里寫的一樣
4.如果沒有配置save參數,執行shutdown不會自動bgsave持久化
5.如果沒有配置save參數,可以手動執行bgsave觸發持久化保存
6.kill -9 redis 不會出發持久化
常用命令:
ll /data/redis_6379/
cat /opt/redis_6379/conf/redis_6379.conf
vim /opt/redis_6379/conf/redis_6379.conf
pkill redis
redis-server /opt/redis_6379/conf/redis_6379.conf
redis-cli -h db01
redis-cli -h db01 shutdown
bash for.sh
3.配置AOF
appendonly yes #是否打開aof日誌功能
appendfsync always #每1個命令,都立即同步到aof
appendfsync everysec #每秒寫1次
appendfsync no #寫入工作交給操作系統,由操作系統判斷緩衝區大小,統一寫入到aof.
appendfilename "redis_6379.aof"
appendonly yes
appendfsync everysec
實驗:
如果aof和rdb文件同時存在,redis會如何讀取:
實驗步驟:
1.插入一條數據
aof: 有記錄
rdb: 沒有記錄
2.複製到其他地方
3.把redis停掉
4.清空數據目錄
5.把數據文件拷貝過來
aof: 有記錄
rdb: 沒有記錄
6.啟動redis
7.測試,如果有新插入的數據,就表示讀取的是aof,如果沒有,就表示讀取的是rdb
實驗結論:
如果2種數據格式都存在,優先讀取aof
如何選擇:
好的,那我該怎麼用?
通常的指示是,如果您希望獲得與PostgreSQL可以提供的功能相當的數據安全性,則應同時使用兩種持久性方法。
如果您非常關心數據,但是在災難情況下仍然可以承受幾分鐘的數據丟失,則可以僅使用RDB。
有很多用戶單獨使用AOF,但我們不建議這樣做,因為不時擁有RDB快照對於進行資料庫備份,加快重啟速度以及AOF引擎中存在錯誤是一個好主意。
註意:由於所有這些原因,我們將來可能會最終將AOF和RDB統一為一個持久性模型(長期計劃)。
以下各節將說明有關這兩個持久性模型的更多詳細信息。
Redis用戶認證
redis預設開啟了保護模式,只允許本地迴環地址登錄並訪問資料庫
禁止protected-mode
protected-mode yes/no (保護模式,是否只允許本地訪問)
1.Bind :指定IP進行監聽
vim /opt/redis_cluster/redis_6379/conf/redis_6379.conf
bind 10.0.0.51 127.0.0.1
#增加requirepass {password}
vim /opt/redis_cluster/redis_6379/conf/redis_6379.conf
requirepass 123456
2.使用密碼登錄
兩種方式:
第一種:
redis-cli -h db01
AUTH 123456
第二種:
redis-cli -h db01 -a 123456 get k_1
========================================
#禁用危險命令
配置文件里添加禁用危險命令的參數
1)禁用命令
rename-command KEYS ""
rename-command FLUSHALL ""
rename-command FLUSHDB ""
rename-command CONFIG ""
2)重命名命令
rename-command KEYS "XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX"
rename-command FLUSHALL "XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX"
rename-command FLUSHDB "XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX"
rename-command CONFIG "XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX"
Redis主從複製
主從複製介紹
在分散式系統中為瞭解決單點問題,通常會把數據複製多個副本到其他機器,滿足故障恢復和負載均衡等求.
Redis也是如此,提供了複製功能.
複製功能是高可用Redis的基礎,後面的哨兵和集群都是在複製的基礎上實現高可用的.
配置複製的方式有三種
1.在配置文件中加入slaveof {masterHost} {masterPort} 隨redis啟動生效.
2.在redis-server啟動命令後加入—slaveof {masterHost} {masterPort}生效.
3.直接使用命令:slaveof {masterHost} {masterPort}生效.
#查看複製狀態信息命令
Info replication快速創建第二台redis節點命令:
rsync -avz db01:/opt/* /opt/
rm -rf /data (先備份)
mkdir /data/redis_6379/ -p
cd /opt/redis
make install
sed -i 's#51#52#g' /opt/redis_6379/conf/redis_6379.conf
redis-server /opt/redis_6379/conf/redis_6379.conf
配置方法:
方法1: 臨時生效
[root@db-02 ~]# redis-cli -h 10.0.0.52
10.0.0.52:6379> SLAVEOF 10.0.0.51 6379
OK
方法2: 寫入配置文件
SLAVEOF 10.0.0.51 6379
取消主從複製
SLAVEOF no one
註意!!!
1.從節點只讀不可寫
2.從節點不會自動故障轉移,它會一直同步主
10.0.0.52:6379> set k1 v1
(error) READONLY You can't write against a read only slave.
3.主從複製故障轉移需要人工介入
- 修改代碼指向REDIS的IP地址
- 從節點需要執行SLAVEOF no one
註意!!!
1.從節點會清空自己原有的數據,如果同步的對象寫錯了,就會導致數據丟失
2.主庫有密碼從庫的配置
masterauth 123456
安全的操作:
1.無論是同步,無論是主節點還是從節點
2.先備份一下數據
3.配置持久化(為了重新載入數據)
4.重啟從節點請求同步:
2602:S 09 Nov 15:58:25.703 * The server is now ready to accept connections on port 6379
2602:S 09 Nov 15:58:25.703 * Connecting to MASTER 10.0.1.51:6379
2602:S 09 Nov 15:58:25.703 * MASTER <-> SLAVE sync started
2602:S 09 Nov 15:58:25.703 * Non blocking connect for SYNC fired the event.
2602:S 09 Nov 15:58:25.703 * Master replied to PING, replication can continue...
2602:S 09 Nov 15:58:25.704 * Partial resynchronization not possible (no cached master)
2602:S 09 Nov 15:58:25.705 * Full resync from master: be1ed4812a0bd83227af30dc6ebe36d88bca5005:1
主節點收到請求之後開始持久化保存數據:
12703:M 09 Nov 15:58:25.708 * Slave 10.0.1.52:6379 asks for synchronization
12703:M 09 Nov 15:58:25.708 * Full resync requested by slave 10.0.1.52:6379
12703:M 09 Nov 15:58:25.708 * Starting BGSAVE for SYNC with target: disk
12703:M 09 Nov 15:58:25.708 * Background saving started by pid 12746
12746:C 09 Nov 15:58:25.710 * DB saved on disk
12746:C 09 Nov 15:58:25.710 * RDB: 6 MB of memory used by copy-on-write
從節點接收主節點發送的數據,然後載入記憶體:
2602:S 09 Nov 15:58:25.805 * MASTER <-> SLAVE sync: receiving 95 bytes from master
2602:S 09 Nov 15:58:25.805 * MASTER <-> SLAVE sync: Flushing old data
2602:S 09 Nov 15:58:25.805 * MASTER <-> SLAVE sync: Loading DB in memory
2602:S 09 Nov 15:58:25.806 * MASTER <-> SLAVE sync: Finished with success
主節點收到從節點同步完成的消息:
12703:M 09 Nov 15:58:25.809 * Background saving terminated with success
12703:M 09 Nov 15:58:25.809 * Synchronization with slave 10.0.1.52:6379 succeeded
主從複製流程:
1.從節點發送同步請求到主節點
2.主節點接收到從節點的請求之後,做瞭如下操作
- 立即執行bgsave將當前記憶體里的數據持久化到磁碟上
- 持久化完成之後,將rdb文件發送給從節點
3.從節點從主節點接收到rdb文件之後,做瞭如下操作
- 清空自己的數據
- 載入從主節點接收的rdb文件到自己的記憶體里
4.後面的操作就是和主節點實時的了Redis哨兵
Redis Sentinel 是一個分散式系統, Redis Sentinel為Redis提供高可用性。可以在沒有人為干預的情況下阻止某種類型的故障。
Redis 的 Sentinel 系統用於管理多個 Redis 伺服器(instance)該系統執行以下三個任務:
1.監控(Monitoring):
Sentinel 會不斷地定期檢查你的主伺服器和從伺服器是否運作正常。
2.提醒(Notification):
當被監控的某個 Redis 伺服器出現問題時, Sentinel 可以通過 API 向管理員或者其他應用程式發送通知。
3.自動故障遷移(Automatic failover):
當一個主伺服器不能正常工作時, Sentinel 會開始一次自動故障遷移操作, 它會將失效主伺服器的其中一個從伺服器升級為新的主伺服器, 並讓失效主伺服器的其他從伺服器改為複製新的主伺服器; 當客戶端試圖連接失效的主伺服器時, 集群也會向客戶端返回新主伺服器的地址, 使得集群可以使用新主伺服器代替失效伺服器
Sentinel 節點是一個特殊的 Redis 節點,他們有自己專屬的 API(埠)
規劃安裝配置命令
哨兵是基於主從複製,所以需要先部署好主從複製
手工操作步驟如下:
1.先配置和創建好1台伺服器的節點和哨兵
2.使用rsync傳輸到另外2台機器
3.修改另外兩台機器的IP地址
建議使用ansible劇本批量部署結構圖
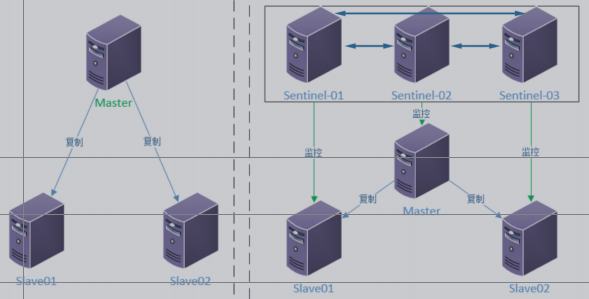
做db03的主從
1.db03上執行快速安裝第3個redis節點
rsync -avz 10.0.0.51:/opt/* /opt/
mkdir /data/redis_6379 -p
cd /opt/redis
make install
sed -i 's#51#53#g' /opt/redis_6379/conf/redis_6379.conf
redis-server /opt/redis_6379/conf/redis_6379.conf
redis-cli
2.啟動所有的單節點
redis-server /opt/redis_6379/conf/redis_6379.conf
3.配置主從複製(任意節點)
redis-cli -h 10.0.0.52 slaveof 10.0.0.51 6379
redis-cli -h 10.0.0.53 slaveof 10.0.0.51 6379安裝部署3個哨兵節點-----基於主從的前提
!!!!註意!!!!
==三個節點的bind IP修改為自己的IP地址==
mkdir -p /data/redis_26379
mkdir -p /opt/redis_26379/{conf,pid,logs}
#.配置哨兵的配置文件
註意!三台機器都操作
cat >/opt/redis_26379/conf/redis_26379.conf << EOF
bind $(ifconfig eth0|awk 'NR==2{print $2}')
port 26379
daemonize yes
logfile /opt/redis_26379/logs/redis_26379.log
dir /data/redis_26379
sentinel monitor myredis 10.0.0.51 6379 2
sentinel down-after-milliseconds myredis 3000
sentinel parallel-syncs myredis 1
sentinel failover-timeout myredis 18000
EOF
#.啟動哨兵
redis-sentinel /opt/redis_26379/conf/redis_26379.conf
#.驗證主節點(註意對應的節點)
redis-cli -h 10.0.0.51 -p 26379 Sentinel get-master-addr-by-name myredis
redis-cli -h 10.0.0.52 -p 26379 Sentinel get-master-addr-by-name myredis
redis-cli -h 10.0.0.53 -p 26379 Sentinel get-master-addr-by-name myredis配置文件的變化
當所有節點啟動後,配置文件的內容發生了變化,體現在三個方面:
1)Sentinel節點自動發現了從節點,其餘Sentinel節點
2)去掉了預設配置,例如parallel-syncs failover-timeout參數
3)添加了配置紀元相關參數查看配置文件命令
[root@db01 ~]# tail -6 /opt/redis_cluster/redis_26379/conf/redis_26379.conf
# Generated by CONFIG REWRITE
sentinel known-slave mymaster 10.0.0.52 6379
sentinel known-slave mymaster 10.0.0.53 6379
sentinel known-sentinel mymaster 10.0.0.53 26379 7794fbbb9dfb62f4d2d7f06ddef06bacb62e4c97
sentinel known-sentinel mymaster 10.0.0.52 26379 17bfab23bc53a531571790b9b31558dddeaeca40
sentinel current-epoch 0模擬故障轉移
- 關閉主節點服務上的所有redis進程
- 觀察其他2個節點會不會發生選舉
- 查看配置文件里會不會自動更新
- 查看新的主節點能不能寫入
- 查看從節點能否正常同步
模擬故障修複上線
- 啟動單節點
- 啟動哨兵
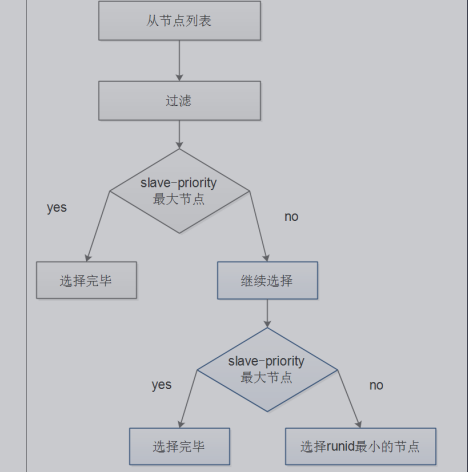
模擬權重選舉,權重相同的id小的優先(最好其他權重設置為0,100以上有問題)
- 設置其他節點的權重為0
- 手動發起重新選舉
- 觀察所有節點消息是否同步
- 觀察切換結果是否符合預期
命令解釋:
1.查詢命令:CONFIG GET slave-priority
2.設置命令:CONFIG SET slave-priority 0
3.主動切換(哨兵):sentinel failover myredis
redis-cli -h 10.0.0.52 -p 6379 CONFIG SET slave-priority 0
redis-cli -h 10.0.0.53 -p 6379 CONFIG SET slave-priority 0
redis-cli -h 10.0.0.51 -p 26379 sentinel failover myredis驗證選舉結果:
redis-cli -h 10.0.0.51 -p 26379 Sentinel get-master-addr-by-name myredisRedis哨兵+主從+密碼
主從密碼配置文件里添加2行參數:
requirepass "123456"
masterauth "123456"
哨兵配置文件添加一行參數:
sentinel auth-pass myredis 123456Redis哨兵設置權重手動故障轉移
1.查看權重
CONFIG GET slave-priority
2.設置權重
在其他節點把權重設為0
CONFIG SET slave-priority 0
3.主動發起重新選舉
sentinel failover mymaster
4.恢復預設的權重
CONFIG SET slave-priority 100redis集群安裝部署-----基於主從的前提
Redis Cluster 是 redis的分散式解決方案,在3.0版本正式推出
當遇到單機、記憶體、併發、流量等瓶頸時,可以採用Cluster架構方案達到負載均衡目的。
Redis Cluster之前的分散式方案有兩種:
- 客戶端分區方案,優點分區邏輯可控,缺點是需要自己處理數據路由,高可用和故障轉移等。
- 代理方案,優點是簡化客戶端分散式邏輯和升級維護便利,缺點加重架構部署和性能消耗。
官方提供的 Redis Cluster集群方案,很好的解決了集群方面的問題
數據分佈
分散式資料庫首先要解決把整個資料庫集按照分區規則映射到多個節點的問題,即把數據集劃分到多個節點上,每個節點負責整體數據的一個子集,需要關註的數據分片規則,redis clusterciyong哈希分片規則
手動搭建部署集群
思路:
- 部署一臺伺服器上的2個集群節點
- 發送完成後修改其他主機的ip地址
- 使用ansible批量部署
拓撲圖
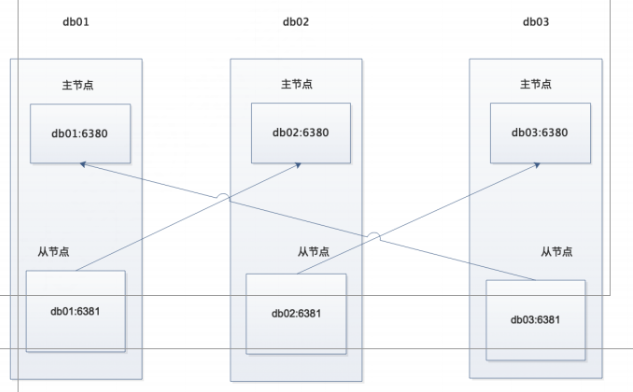
1.目錄規劃
主節點 6380
從節點 6381
# redis安裝目錄
/opt/redis_{6380,6381}/{conf,logs,pid}
# redis數據目錄
/data/redis_{6380,6381}
# redis運維腳本
/root/scripts/redis_shell.sh2.db01創建命令
#為了關閉其他redis埠,生產中需要註意
pkill redis
mkdir -p /opt/redis_{6380,6381}/{conf,logs,pid}
mkdir -p /data/redis_{6380,6381}
cat >/opt/redis_6380/conf/redis_6380.conf<<EOF
bind 10.0.0.51
port 6380
daemonize yes
pidfile "/opt/redis_6380/pid/redis_6380.pid"
logfile "/opt/redis_6380/logs/redis_6380.log"
dbfilename "redis_6380.rdb"
dir "/data/redis_6380/"
cluster-enabled yes
cluster-config-file nodes_6380.conf
cluster-node-timeout 15000
EOF
cd /opt/
cp redis_6380/conf/redis_6380.conf redis_6381/conf/redis_6381.conf
sed -i 's#6380#6381#g' redis_6381/conf/redis_6381.conf
rsync -avz /opt/redis_638* 10.0.0.52:/opt/
rsync -avz /opt/redis_638* 10.0.0.53:/opt/
redis-server /opt/redis_6380/conf/redis_6380.conf
redis-server /opt/redis_6381/conf/redis_6381.conf
ps -ef|grep redis3.db02操作命令
pkill redis
find /opt/redis_638* -type f -name "*.conf"|xargs sed -i "/bind/s#51#52#g"
mkdir –p /data/redis_{6380,6381}
redis-server /opt/redis_6380/conf/redis_6380.conf
redis-server /opt/redis_6381/conf/redis_6381.conf
ps -ef|grep redis4.db03操作命令
pkill redis
find /opt/redis_638* -type f -name "*.conf"|xargs sed -i "/bind/s#51#53#g"
mkdir –p /data/redis_{6380,6381}
redis-server /opt/redis_6380/conf/redis_6380.conf
redis-server /opt/redis_6381/conf/redis_6381.conf
ps -ef|grep redis手動配置節點發現
當把所有節點都啟動後查看進程會有cluster的字樣,但是登錄後執行CLUSTER NODES命令會發現只有每個節點自己的ID,目前集群內的節點,還沒有互相發現,所以搭建redis集群我們第一步要做的就是讓集群內的節點互相發現.,在執行節點發現命令之前我們先查看一下集群的數據目錄會發現有生成集群的配置文件,查看後發現只有自己的節點內容,等節點全部發現後會把所發現的節點ID寫入這個文件
集群模式的Redis除了原有的配置文件之外又加了一份集群配置文件.當集群內節點. 信息發生變化,如添加節點,節點下線,故障轉移等.節點會自動保存集群狀態到配置文件.
需要註意的是,Redis自動維護集群配置文件,不需要手動修改,防止節點重啟時產生錯亂.
節點發現使用命令: CLUSTER MEET {IP} {PORT}
提示:在集群內任意一臺機器執行此命令就可以
發現節點(db01)
redis-cli -h 10.0.0.51 -p 6380 CLUSTER MEET 10.0.0.51 6381
redis-cli -h 10.0.0.51 -p 6380 CLUSTER MEET 10.0.0.52 6380
redis-cli -h 10.0.0.51 -p 6380 CLUSTER MEET 10.0.0.52 6381
redis-cli -h 10.0.0.51 -p 6380 CLUSTER MEET 10.0.0.53 6380
redis-cli -h 10.0.0.51 -p 6380 CLUSTER MEET 10.0.0.53 6381查詢
redis-cli -h 10.0.0.51 -p 6380 CLUSTER NODES
[root@db01 opt]# redis-cli -h 10.0.0.51 -p 6380 CLUSTER NODES
0a138d3b47ae0ac83719d150ac5e46f1986c92f9 10.0.0.52:6381 master - 0 1577372412387 3 connected
f1c6d6a418edb08f986715f093934646d92f99e3 10.0.0.53:6381 master - 0 1577372411377 0 connected
dc225e89785179d0045d82a2b3f0c1d072466713 10.0.0.53:6380 master - 0 1577372410361 4 connected 10922-16383
81b466115f32423ecd32a2cb4477f1e1a9913437 10.0.0.52:6380 master - 0 1577372408341 5 connected 5461-10921
83d86340bf4859023994ba75f4b1d84778a58840 10.0.0.51:6381 master - 0 1577372413402 2 connected
b0cda45c78d5a7fe288f46fa85c4041da795a5ec 10.0.0.51:6380 myself,master - 0 0 1 connected 0-5460
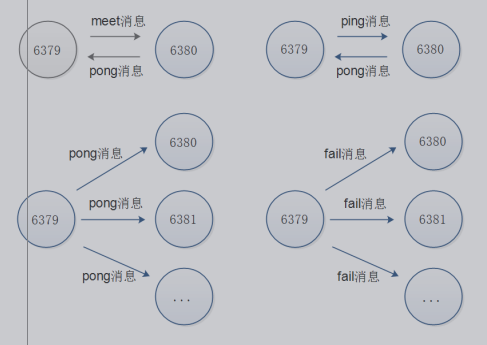
Redis Cluster 通訊流程
在分散式存儲中需要提供維護節點元數據信息的機制,所謂元數據是指:節點負責哪些數據,是否出現故障燈狀態信息,redis 集群採用 Gossip(流言)協議,Gossip 協議工作原理就是節點彼此不斷交換信息,一段時間後所有的節點都會知道集群完整信息,這種方式類似流言傳播。
通信過程:
==集群中的每一個節點都會單獨開闢一個 Tcp 通道,用於節點之間彼此通信,通信埠在基礎埠上家10000==.
每個節點在固定周期內通過特定規則選擇結構節點發送 ping 消息
接收到 ping 消息的節點用 pong 消息作為響應。集群中每個節點通過一定規則挑選要通信的節點,每個節點可能知道全部節點,也可能僅知道部分節點,只要這些節點彼此可以正常通信,最終他們會打成一致的狀態,當節點出現故障,新節點加入,主從角色變化等,它能夠給不斷的ping/pong消息,從而達到同步目的。
通訊消息類型:
Gossip
Gossip 協議職責就是信息交換,信息交換的載體就是節點間彼此發送Gossip 消息。
常見 Gossip 消息分為:ping、 pong、 meet、 fail 等meet
meet 消息:用於通知新節點加入,消息發送者通知接受者加入到當前集群,meet 消息
通信正常完成後,接收節點會加入到集群中併進行ping、 pong 消息交換
ping
ping 消息:集群內交換最頻繁的消息,集群內每個節點每秒想多個其他節點發送 ping 消息,用於檢測節點是否線上和交換彼此信息。
pong
Pong 消息:當接收到 ping,meet 消息時,作為相應消息回覆給發送方確認消息正常通信,節點也可以向集群內廣播自身的 pong 消息來通知整個集群對自身狀態進行更新。fail
fail 消息:當節點判定集群內另一個節點下線時,迴向集群內廣播一個fail 消息,其他節點收到 fail 消息之後把對應節點更新為下線狀態。
通訊示意圖:
手動分配槽位
redis集群一共有16384個槽,所有的槽都必須分配完畢,
有一個槽沒分配整個集群都不可用,每個節點上槽位的順序無所謂,重點是槽位的個數,
hash分片演算法足夠隨機,足夠平均
不要去手動修改集群的配置文件
我們雖然有6個節點,但是真正負責數據寫入的只有3個節點,其他的3個節點只是作為主節點的從節點,也就是說,只需要分配期中三個節點的的槽位就可以
非配槽位需要在每個主節點上來配置,兩種方法執行:
- 分別登陸到每個主節點的客戶端來執行命令
- 一臺遠程登錄在其主節點上執行
1.槽位規劃
db01:6380 0-5460
db02:6380 5461-10921
db03:6380 10922-163832.分配槽位(有的版本有坑,會報錯,需要註意)
redis-cli -h 10.0.0.51 -p 6380 CLUSTER ADDSLOTS {0..5460}
redis-cli -h 10.0.0.52 -p 6380 CLUSTER ADDSLOTS {5461..10920}
redis-cli -h 10.0.0.52 -p 6380 CLUSTER ADDSLOTS 10921
redis-cli -h 10.0.0.53 -p 6380 CLUSTER ADDSLOTS {10922..16383}3.查看集群狀態
redis-cli -h db01 -p 6380 CLUSTER info允許的槽位個數誤差範圍2%以內
手動配置集群的高可用
雖然這時候集群是可用的了,但是整個集群只要有一臺機器壞掉了,那麼整個集群都是不可用的.
所以這時候需要用到其他三個節點分別作為現在三個主節點的從節點,以應對集群主節點故障時可以進行自動切換以保證集群持續可用.
註意:
1.不要讓複製節點複製本機器的主節點, 因為如果那樣的話機器掛了集群還是不可用狀態, 所以複製節點要複製其他伺服器的主節點.
2.使用redis-trid工具自動分配的時候會出現複製節點和主節點在同一臺機器上的情況,需要註意
手動部署複製關係
#查詢id
redis-cli -h 10.0.0.51 -p 6380 CLUSTER NODES
redis-cli -h 10.0.0.51 -p 6381 CLUSTER REPLICATE 35b5ee70a887b5256089a5eebf521aa21a0a7a7a
redis-cli -h 10.0.0.52 -p 6381 CLUSTER REPLICATE 65baaa3b071f906c14da10452c349b0871317210
redis-cli -h 10.0.0.53 -p 6381 CLUSTER REPLICATE a1d47ccb19411eaf12d5af4b22cafbbefc8e2486測試集群
1.嘗試插入一條數據發現報錯
10.0.0.51:6380> set k1 v1
(error) MOVED 12706 10.0.0.53:6380
2.目前的現象
- 在db01的6380節點插入數據提示報錯
- 報錯內容提示應該移動到db03的6380上
- 在db03的6380上執行相同的插入命令可以插入成功
- 在db01的6380節點插入數據有時候可以,有時候不行
- 使用-c參數後,可以正常插入命令,並且節點切換到了提示的對應節點上
3.問題原因
因為集群模式又ASK路由規則,加入-c參數後,會自動跳轉到目標節點處理
並且最後由目標節點返回信息
4.測試足夠隨機足夠平均
#!/bin/bash
for i in $(seq 1 1000)
do
redis-cli -c -h db01 -p 6380 set k_${i} v_${i} && echo "set k_${i} is ok"
done控制腳本
sh redis_shell.sh login 6380 10.0.0.52
[root@db03 script]# cat redis_shell.sh
#!/bin/bash
USAG(){
echo "sh $0 {start|stop|restart|login|ps|tail} PORT"
}
if [ "$#" = 1 ]
then
REDIS_PORT='6379'
elif
[ "$#" -gt 2 -a -z "$(echo "$2"|sed 's#[0-9]##g')" ]
then
REDIS_PORT="$2"
else
USAG
exit 0
fi
REDIS_IP=$3
PATH_DIR=/opt/redis_${REDIS_PORT}/
PATH_CONF=/opt/redis_${REDIS_PORT}/conf/redis_${REDIS_PORT}.conf
PATH_LOG=/opt/redis_${REDIS_PORT}/logs/redis_${REDIS_PORT}.log
CMD_START(){
redis-server ${PATH_CONF}
}
CMD_SHUTDOWN(){
redis-cli -c -h ${REDIS_IP} -p ${REDIS_PORT} shutdown
}
CMD_LOGIN(){
redis-cli -c -h ${REDIS_IP} -p ${REDIS_PORT}
}
CMD_PS(){
ps -ef|grep redis
}
CMD_TAIL(){
tail -f ${PATH_LOG}
}
case $1 in
start)
CMD_START
CMD_PS
;;
stop)
CMD_SHUTDOWN
CMD_PS
;;
restart)
CMD_START
CMD_SHUTDOWN
CMD_PS
;;
login)
CMD_LOGIN
;;
ps)
CMD_PS
;;
tail)
CMD_TAIL
;;
*)
USAG
esac
模擬故障轉移
至此,我們已經手動的把一個redis高可用的集群部署完畢了, 但是還沒有模擬過故障
這裡我們就模擬故障,停掉期中一臺主機的redis節點,然後查看一下集群的變化
我們使用暴力的kill -9殺掉 db02上的redis集群節點,然後觀察節點狀態
理想情況應該是db01上的6381從節點升級為主節點
在db01上查看集群節點狀態
雖然我們已經測試了故障切換的功能,但是節點修複後還是需要重新上線
所以這裡測試節點重新上線後的操作
重新啟動db02的6380,然後觀察日誌
觀察db01上的日誌
這時假如我們想讓修複後的節點重新上線,可以在想變成主庫的從庫執行CLUSTER FAILOVER命令
這裡我們在db02的6380上執行
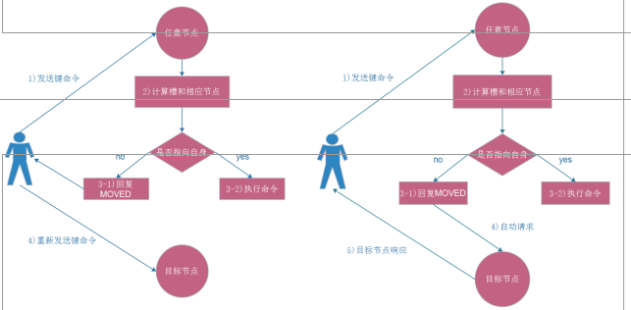
Redis Cluster ASK路由介紹
在集群模式下,Redis接受任何鍵相關命令時首先會計算鍵對應的槽,再根據槽找出所對應的節點 如果節點是自身,則處理鍵命令;否則回覆MOVED重定向錯誤,通知客戶端請求正確的節點,這個過程稱為Mover重定向.
知道了ask路由後,我們使用-c選項批量插入一些數據
使用工具搭建部署Redis Cluster
手動搭建集群便於理解集群創建的流程和細節,不過手動搭建集群需要很多步驟,當集群節點眾多時,必然會加大搭建集群的複雜度和運維成本,因此官方提供了 redis-trib.rb的工具方便我們快速搭建集群。
redis-trib.rb是採用 Ruby 實現的 redis 集群管理工具,內部通過 Cluster相關命令幫我們簡化集群創建、檢查、槽遷移和均衡等常見運維操作,使用前要安裝 ruby 依賴環境
1.安裝依賴-只要在db01上操作
yum makecache fast
yum install rubygems -y
gem sources --remove https://rubygems.org/
gem sources -a http://mirrors.aliyun.com/rubygems/
gem update –system
gem install redis -v 3.3.5
2.還原環境-所有節點都執行!!!
pkill redis
rm -rf /data/redis_6380/*
rm -rf /data/redis_6381/*
3.啟動集群節點-所有節點都執行
redis-server /opt/redis_6380/conf/redis_6380.conf
redis-server /opt/redis_6381/conf/redis_6381.conf
ps -ef|grep redis
4.使用工具搭建部署Redis(一臺部署)
cd /opt/redis/src/
./redis-trib.rb create --replicas 1 10.0.0.51:6380 10.0.0.52:6380 10.0.0.53:6380 10.0.0.51:6381 10.0.0.52:6381 10.0.0.53:6381
5.檢查集群完整性
./redis-trib.rb check 10.0.0.51:6380
6.檢查集群負載是否合規
./redis-trib.rb rebalance 10.0.0.51:6380使用工具擴容節點
redis集群的擴容操作規劃
- 準備新節點
- 加入集群
- 遷移槽和數據(遷移過程千萬不能中斷,以防集群故障)
擴容流程圖
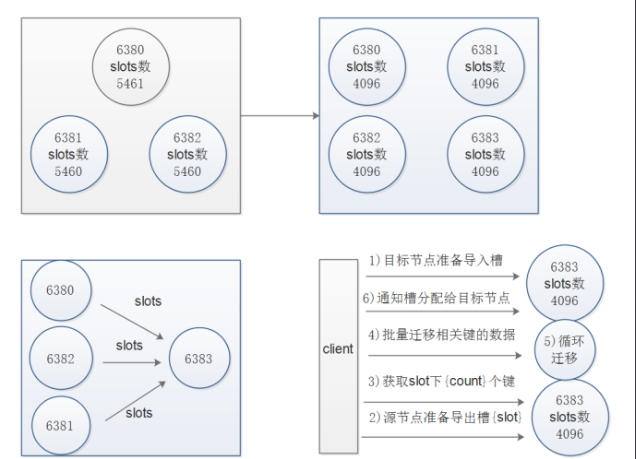
列印出進群每個節點信息後,reshard命令需要確認遷移的槽數量,這裡我們輸入4096個:
How many slots do you want to move (from 1 to 16384)? 4096
輸入6390的節點ID作為目標節點,也就是要擴容的節點,目標節點只能指定一個
What is the receiving node ID? xxxxxxxxx
之後輸入源節點的ID,這裡分別輸入每個主節點的6380的ID最後輸入done,或者直接輸入all
Source node #1:all
遷移完成後命令會自動退出,這時候我們查看一下集群的狀態
./redis-trib.rb rebalance 10.0.0.51:63801.創建新節點-db01操作
mkdir -p /opt/redis_{6390,6391}/{conf,logs,pid}
mkdir -p /data/redis_{6390,6391}
cd /opt/
cp redis_6380/conf/redis_6380.conf redis_6390/conf/redis_6390.conf
cp redis_6380/conf/redis_6380.conf redis_6391/conf/redis_6391.conf
sed -i 's#6380#6390#g' redis_6390/conf/redis_6390.conf
sed -i 's#6380#6391#g' redis_6391/conf/redis_6391.conf
redis-server /opt/redis_6390/conf/redis_6390.conf
redis-server /opt/redis_6391/conf/redis_6391.conf
ps -ef|grep redis
redis-cli -c -h db01 -p 6380 cluster meet 10.0.0.51 6390
redis-cli -c -h db01 -p 6380 cluster meet 10.0.0.51 6391
redis-cli -c -h db01 -p 6380 cluster nodes
2.使用工具擴容步驟
cd /opt/redis/src/
./redis-trib.rb reshard 10.0.0.51:6380
第一次交互:每個節點保留多少個槽位
How many slots do you want to move (from 1 to 16384)? 4096
第二次交互:接收節點的ID是什麼
What is the receiving node ID? 6390的ID
第三次交互:哪個節點需要導出
Source node #1: all
第四次交互:確認是否執行分配
Do you want to proceed with the proposed reshard plan (yes/no)? yes
3.檢查集群完整性
./redis-trib.rb check 10.0.0.51:6380
4.檢查集群負載是否合規
./redis-trib.rb rebalance 10.0.0.51:6380
5.調整複製順序
redis-cli -h 10.0.0.53 -p 6381 CLUSTER REPLICATE 51-6390的ID
redis-cli -h 10.0.0.51 -p 6391 CLUSTER REPLICATE 51-6380的ID
6.測試寫入腳本
[root@db01 ~]# cat for.sh
#!/bin/bash
for i in $(seq 1 100000)
do
redis-cli -c -h db01 -p 6380 set k_${i} v_${i} && echo "set k_${i} is ok"
done
7.測試讀腳本
[root@db03 ~]# cat du.sh
#!/bin/bash
for i in $(seq 1 100000)
do
redis-cli -c -h db01 -p 6380 get k_${i}
sleep 0.1
done使用工具收縮節點
流程說明
- 確定下線節點是否有負責的槽,如果是,要把槽遷移到其他節點,保證節點下線後整個集群槽節點映射的完整性
- 當下線節點不再負責槽或者本身是從節點時,就可以通知群內其他節點忘記下線節點,當所有的節點忘記該節點後可以正常關閉
- 計劃將6390和6391節點下線,收縮和擴容的方向相反,6390變為源節點,其他節點變為目標節點,源節點把自己負責的4096個槽均勻的遷移到其他節點上,由於
redis-trib.rb reshard命令只能有一個目標節點,因此需要執行3次reshard命令,分別遷移1365,1365,1366個槽
收縮流程圖

1.使用工具收縮節點
cd /opt/redis/src/
./redis-trib.rb reshard 10.0.0.51:6380
2.第一次交互: 要遷移多少個
How many slots do you want to move (from 1 to 16384)? 1365
3.第二次交互: 輸入第一個需要接收節點的ID
What is the receiving node ID? db01的6380的ID
4.第三次交互: 輸入需要導出的節點的ID
Please enter all the source node IDs.
Type 'all' to use all the nodes as source nodes for the hash slots.
Type 'done' once you entered all the source nodes IDs.
Source node #1: db01的6390的ID
Source node #2: done
5.第四次交互: 確認
Do you want to proceed with the proposed reshard plan (yes/no)? yes
6.繼續重覆的操作,直到6390所有的槽位都分配給了其他主節點
7.確認集群狀態是否正常,確認6390槽位是否都遷移走了
10.0.0.51:6380> CLUSTER NODES
8.忘記以及下線節點(從節點可以直接刪除,主節點先移走數據,再刪除)
./redis-trib.rb del-node 10.0.0.51:6390 baf9585a780d9f6e731972613a94b6f3e6d3fb5e
./redis-trib.rb del-node 10.0.0.51:6391 e54a79cca258eb76fb74fc12dafab5ebac26ed90排錯思路
首先確定埠是否啟動
檢查防火牆,getenforce
./redis-trib.rb check 10.0.0.51:6380檢查
cluster nodes
企業案例
遷移過程中,ctrl+c,集群出現問題
解決辦法:
工具關閉槽
cd /opt/redis/src
./redis-trib.rb fix 10.0.0.51:6380
手動關閉:
連接對應的redis節點,執行cluster setslot 773 stable,(導入,導出問題槽位)
執行,reblance是出現#######,按下ctrl+c發現集群執行cluster info時.ok,但槽的狀態有問題
解決思路:
1手動關閉:
連接對應的redis節點,執行cluster setslot 773 stable,
查詢槽的狀態已經恢復
cluster info
檢查,有報錯,
./redis-trib.rb check 10.0.0.51:6380
cluster info 狀態ok,集群用fix,有問題,發現問題773槽位識別出現問題,其他節點上看0-773在6390上,6390上看而在6380上
2.刪除兩個問題槽位,6380,6390
cluster delslots 773
3.6390添加773
cluster addslots 773
發現大家看到的結果一致6390上,check.reblance ok
redis集群常用的命令
集群(cluster)
CLUSTER INFO 列印集群的信息
CLUSTER NODES 列出集群當前已知的所有節點(node),以及這些節點的相關信息。
節點(node)
CLUSTER MEET <ip> <port> 將 ip 和 port 所指定的節點添加到集群當中,讓它成為集群的一份子。
CLUSTER FORGET <node_id> 從集群中移除 node_id 指定的節點。
CLUSTER REPLICATE <node_id> 將當前節點設置為 node_id 指定的節點的從節點。
CLUSTER SAVECONFIG 將節點的配置文件保存到硬碟裡面。
槽(slot)
CLUSTER ADDSLOTS <slot> [slot ...] 將一個或多個槽(slot)指派(assign)給當前節點。
CLUSTER DELSLOTS <slot> [slot ...] 移除一個或多個槽對當前節點的指派。
CLUSTER FLUSHSLOTS 移除指派給當前節點的所有槽,讓當前節點變成一個沒有指派任何槽的節點。
CLUSTER SETSLOT <slot> NODE <node_id> 將槽 slot 指派給 node_id 指定的節點,如果槽已經指派給另一個節點,那麼先讓另一個節點刪除該槽>,然後再進行指派。
CLUSTER SETSLOT <slot> MIGRATING <node_id> 將本節點的槽 slot 遷移到 node_id 指定的節點中。
CLUSTER SETSLOT <slot> IMPORTING <node_id> 從 node_id 指定的節點中導入槽 slot 到本節點。
CLUSTER SETSLOT <slot> STABLE 取消對槽 slot 的導入(import)或者遷移(migrate)。
鍵 (key)
CLUSTER KEYSLOT <key> 計算鍵 key 應該被放置在哪個槽上。
CLUSTER COUNTKEYSINSLOT <slot> 返回槽 slot 目前包含的鍵值對數量。CLUSTER GETKEYSINSLOT <slot> <count> 返回 count 個 slot 槽中的鍵。數據遷移
需求背景
剛切換到redis集群的時候肯定會面臨數據導入的問題,所以這裡推薦使用redis-migrate-tool工具來導入單節點數據到集群里
官方地址:
http://www.oschina.net/p/redis-migrate-tool
導出工具
1.安裝工具
yum install libtool autoconf automake git bzip2 -y
cd /opt/
git clone https://github.com/vipshop/redis-migrate-tool.git
cd redis-migrate-tool/
autoreconf -fvi
./configure
make && make install
2.編寫配置文件
cat > 6379_to_6380.conf << EOF
[source]
type: single
servers:
- 10.0.0.51:6379
[target]
type: redis cluster
servers:
- 10.0.0.51:6380
[common]
listen: 0.0.0.0:8888
source_safe: true
EOF
3.單節點生成測試數據
redis-server /opt/redis_6379/conf/redis_6379.conf
cat >input_6379.sh<<EOF
#!/bin/bash
for i in {1..1000}
do
redis-cli -c -h db01 -p 6379 set oldzhang_\${i} oldzhang_\${i}
echo "set oldzhang_\${i} is ok"
done
EOF
4.運行工具遷移單節點數據到集群
redis-migrate-tool -c 6379_to_6380.conf
5.運行工具驗證數據是否遷移完成
redis-migrate-tool -c 6379_to_6380.conf -C redis_check
RDB文件遷移到集群
1.先把集群的RDB文件都收集起來
- 在從節點上執行bgsave命令生成RDB文件
redis-cli -h db01 -p 6381 BGSAVE
redis-cli -h db02 -p 6381 BGSAVE
redis-cli -h db03 -p 6381 BGSAVE
2.把從節點生成的RDB文件拉取過來
mkdir /root/rdb_backup
cd /root/rdb_backup/
scp db01:/data/redis_6381/redis_6381.rdb db01_6381.rdb
scp db02:/data/redis_6381/redis_6381.rdb db02_6381.rdb
scp db03:/data/redis_6381/redis_6381.rdb db03_6381.rdb
3.清空數據
redis-cli -c -h db01 -p 6380 flushall
redis-cli -c -h db02 -p 6380 flushall
redis-cli -c -h db03 -p 6380 flushall
7.編寫配置文件
cat >rdb_to_cluter.conf <<EOF
[source]
type: rdb file
servers:
- /root/rdb_backup/db01_6381.rdb
- /root/rdb_backup/db02_6381.rdb
- /root/rdb_backup/db03_6381.rdb
[target]
type: redis cluster
servers:
- 10.0.0.51:6380
[common]
listen: 0.0.0.0:8888
source_safe: true
EOF
8.使用工具導入
redis-migrate-tool -c rdb_to_cluter.conf
使用工具分析key的大小(註意Python環境的安裝過程,有出錯多執行幾次)
需求背景
redis的記憶體使用太大鍵值太多,不知道哪些鍵值占用的容量比較大,而且線上分析會影響性能
0.需求背景
redis的記憶體使用太大鍵值太多,不知道哪些鍵值占用的容量比較大,而且線上分析會影響性能.
1.安裝命令:(pip可能會出錯,)
yum install python-pip gcc python-devel -y
cd /opt/
git clone https://github.com/sripathikrishnan/redis-rdb-tools
cd redis-rdb-tools
pip install python-lzf
python setup.py install
2.生成測試數據:
redis-cli -h db01 -p 6379 set txt $(cat txt.txt)
3.執行bgsave生成rdb文件
redis-cli -h db01 -p 6379 BGSAVE
3.使用工具分析:
cd /data/redis_6379/
rdb -c memory redis_6379.rdb -f redis_6379.rdb.csv
4.過濾分析
awk -F"," '{print $4,$3}' redis_6379.rdb.csv |sort -n
5.將結果整理彙報給領導,詢問開發這個key是否可以刪除預防redis不斷寫入數據
設置記憶體最大限制
config set maxmemory 2G
記憶體回收機制
當達到記憶體使用限制之後redis會出發對應的控制策略
redis支持6種策略:
1.noevicition 預設策略,不會刪除任務數據,拒絕所有寫入操作並返回客戶端錯誤信息,此時只響應讀操作
2.volatile-lru 根據LRU演算法刪除設置了超時屬性的key,指導騰出足夠空間為止,如果沒有可刪除的key,則退回到noevicition策略
3.allkeys-lru 根據LRU演算法刪除key,不管數據有沒有設置超時屬性
4.allkeys-random 隨機刪除所有key
5.volatile-random 隨機刪除過期key
5.volatile-ttl 根據key的ttl,刪除最近要過期的key
動態配置
config set maxmemory-policy
監控過期鍵
需求背景
因為開發重覆提交,導致電商網站優惠捲過期時間失效
問題分析
如果一個鍵已經設置了過期時間,這時候在set這個鍵,過期時間就會取消
解決思路
如何在不影響機器性能的前提下批量獲取需要監控鍵過期時間
1.Keys * 查出來匹配的鍵名。然後迴圈讀取ttl時間
2.scan * 範圍查詢鍵名。然後迴圈讀取ttl時間
Keys 重操作,會影響伺服器性能,除非是不提供服務的從節點
Scan 負擔小,但是需要去多次才能取完,需要寫腳本
腳本內容:
cat 01get_key.sh
#!/bin/bash
key_num=0
> key_name.log
for line in $(cat key_list.txt)
do
while true
do
scan_num=$(redis-cli -h 192.168.47.75 -p 6380 SCAN ${key_num} match ${line}\* count 1000|awk 'NR==1{print $0}')
key_name=$(redis-cli -h 192.168.47.75 -p 6380 SCAN ${key_num} match ${line}\* count 1000|awk 'NR>1{print $0}')
echo ${key_name}|xargs -n 1 >> key_name.log
((key_num=scan_num))
if [ ${key_num} == 0 ]
then
break
fi
done
done
