
HBase隸屬於hadoop生態系統,它參考了谷歌的BigTable建模,實現的編程語言為 Java, 建立在hdfs之上,提供高可靠性、高性能、列存儲、可伸縮、實時讀寫的資料庫系統。它僅能通過主鍵(row key)和主鍵的range來檢索數據,主要用來存儲非結構化和半結構化的鬆散數據。與hadoo ...
HBase隸屬於hadoop生態系統,它參考了谷歌的BigTable建模,實現的編程語言為 Java, 建立在hdfs之上,提供高可靠性、高性能、列存儲、可伸縮、實時讀寫的資料庫系統。它僅能通過主鍵(row key)和主鍵的range來檢索數據,主要用來存儲非結構化和半結構化的鬆散數據。與hadoop一樣,Hbase目標主要依靠橫向擴展,通過不斷增加廉價的商用伺服器,來增加計算和存儲能力。Hbase資料庫中的表一般有這樣的特點:
- 大: 一個表可以有上億行,上百萬列
- 面向列: 面向列(族)的存儲和許可權控制,列(族)獨立檢索
- 稀疏: 對於為空(null)的列,並不占用存儲空間,因此,表可以設計的非常稀疏
目錄:
- 系統架構
- 數據模型
- RegionServer
- nameSpace
- HBase定址
- write
- Compaction
- splite
- read
系統架構:
HBase採用Master/Slave架構搭建集群,由HMaster節點、HRegionServer節點、ZooKeeper集群組成,而在底層,它將數據存儲於HDFS中,因而涉及到HDFS的NN、DN等,總體結構如下(註意:在hadoop(四): 本地 hbase 集群配置 Azure Blob Storage 介紹過,也可以將底層的存儲配置為 Azure Blob Storage 或 Amazon Web Services),圖A較清楚表達各組件之間的訪問及內部實現邏輯,圖B更直觀表達hbase 與 hadoop hdfs 部署結構及 hadoop NN 和 HMaster 的 SPOF 解決方案
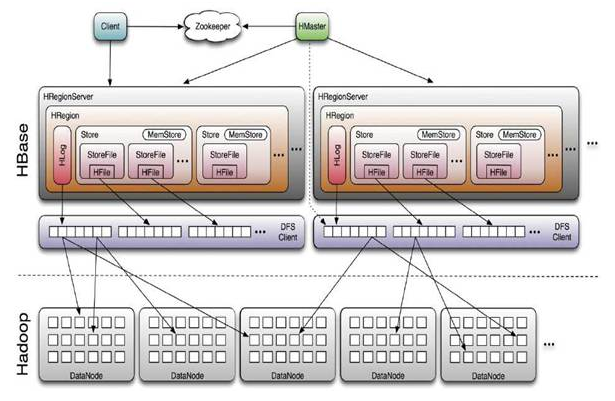
架構圖A

架構圖B
- Client的主要功能:
- 使用HBase的RPC機制與HMaster和HRegionServer進行通信
- 對於管理類操作,Client與HMaster進行RPC
- 對於數據讀寫類操作,Client與HRegionServer進行RPC
- Zookeeper功能:
- 通過選舉,保證任何時候,集群中只有一個master,Master與RegionServers 啟動時會向ZooKeeper註冊
- 實時監控Region server的上線和下線信息,並實時通知給Master
- 存貯所有Region的定址入口和HBase的schema和table元數據
- Zookeeper的引入實現HMaster主從節點的failover
詳細工作原理如下圖:
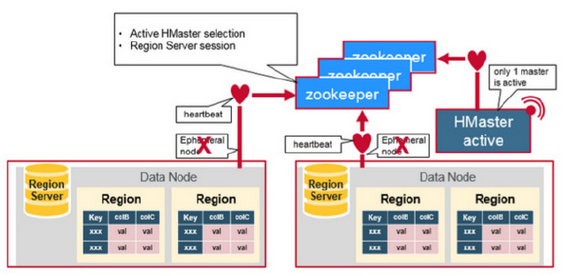
- 在HMaster和HRegionServer連接到ZooKeeper後創建Ephemeral節點,並使用Heartbeat機制維持這個節點的存活狀態,如果某個Ephemeral節點失效,則HMaster會收到通知,並做相應的處理
- HMaster通過監聽ZooKeeper中的Ephemeral節點(預設:/hbase/rs/*)來監控HRegionServer的加入和宕機
- 在第一個HMaster連接到ZooKeeper時會創建Ephemeral節點(預設:/hbasae/master)來表示Active的HMaster,其後加進來的HMaster則監聽該Ephemeral節點,如果當前Active的HMaster宕機,則該節點消失,因而其他HMaster得到通知,而將自身轉換成Active的HMaster,在變為Active的HMaster之前,它會創建在/hbase/back-masters/下創建自己的Ephemeral節點
- HMaster功能:
- 管理HRegionServer,實現其負載均衡
- 管理和分配HRegion,比如在HRegion split時分配新的HRegion;在HRegionServer退出時遷移其內的HRegion到其他HRegionServer上
- 監控集群中所有HRegionServer的狀態(通過Heartbeat和監聽ZooKeeper中的狀態)
- 處理schema更新請求 (創建、刪除、修改Table的定義), 如下圖:

- HRegionServer功能:
- Region server維護Master分配給它的region,處理對這些region的IO請求
- Region server負責切分在運行過程中變得過大的region
- 小結:
- client訪問hbase上數據的過程並不需要master參與(定址訪問zookeeper,數據讀寫訪問regione server),master僅僅維護者table和region的元數據信息,負載很低
- HRegion所處理的數據儘量和數據所在的DataNode在一起,實現數據的本地化
數據模型:
- Table: 與傳統關係型資料庫類似,HBase以表(Table)的方式組織數據,應用程式將數據存入HBase表中
- Row: HBase表中的行通過 RowKey 進行唯一標識,不論是數字還是字元串,最終都會轉換成欄位數據進行存儲;HBase表中的行是按RowKey字典順序排列
- Column Family: HBase表由行和列共同組織,同時引入列族的概念,它將一列或多列組織在一起,HBase的列必須屬於某一個列族,在創建表時只需指定表名和至少一個列族
- Cell: 行和列的交叉點稱為單元格,單元格的內容就是列的值,以二進位形式存儲,同時它是版本化的
- version: 每個cell的值可保存數據的多個版本(到底支持幾個版本可在建表時指定),按時間順序倒序排列,時間戳是64位的整數,可在寫入數據時賦值,也可由RegionServer自動賦值
- 註意:
- HBase沒有數據類型,任何列值都被轉換成字元串進行存儲
- 與關係型資料庫在創建表時需明確包含的列及類型不同,HBase表的每一行可以有不同的列
- 相同RowKey的插入操作被認為是同一行的操作。即相同RowKey的二次寫入操作,第二次可被可為是對該行某些列的更新操作
- 列由列族和列名連接而成, 分隔符是冒號,如 d:Name (d: 列族名, Name: 列名)
- 以一個示例來說明關係型數據表和HBase表各自的解決方案(示例:博文及作者),關係型資料庫表結構設計及數據如下圖:
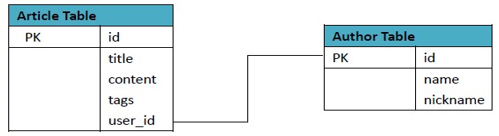
表結構設計

示例數據
用HBase設計表結構如下圖:

存儲示例數據如下:
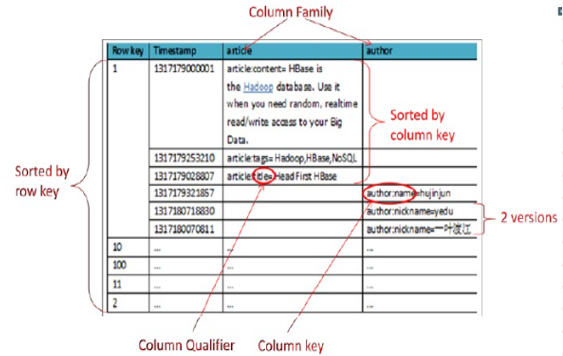
- 小結:
- HBase不支持條件查詢和Order by等查詢,讀取記錄只能按Row key(及其range)或全表掃描
- 在表創建時只需聲明表名和至少一個列族名,每個Column Family為一個存儲單元,在下節物理模型會詳細介紹
- 在上例中設計了一個HBase表blog,該表有兩個列族:article和author,但在實際應用中強烈建議使用單列族
- Column不用創建表時定義即可以動態新增,同一Column Family的Columns會群聚在一個存儲單元上,並依Column key排序,因此設計時應將具有相同I/O特性的Column設計在一個Column Family上以提高性能。註意:這個列是可以增加和刪除的,這和我們的傳統資料庫很大的區別。所以他適合非結構化數據
- HBase通過row和column確定一份數據,這份數據的值可能有多個版本,不同版本的值按照時間倒序排序,即最新的數據排在最前面,查詢時預設返回最新版本。如上例中row key=1的author:nickname值有兩個版本,分別為1317180070811對應的“一葉渡江”和1317180718830對應的“yedu”(對應到實際業務可以理解為在某時刻修改了nickname為yedu,但舊值仍然存在)。Timestamp預設為系統當前時間(精確到毫秒),也可以在寫入數據時指定該值
- 每個單元格值通過4個鍵唯一索引,tableName+RowKey+ColumnKey+Timestamp=>value, 例如上例中{tableName=’blog’,RowKey=’1’,ColumnName=’author:nickname’,Timestamp=’ 1317180718830’}索引到的唯一值是“yedu”
- 存儲類型:
-
- TableName 是字元串
- RowKey 和 ColumnName 是二進位值(Java 類型 byte[])
- Timestamp 是一個 64 位整數(Java 類型 long)
- value 是一個位元組數組(Java類型 byte[])
RegionServer:
- HRegionServer一般和DN在同一臺機器上運行,實現數據的本地性,如圖B。HRegionServer包含多個HRegion,由WAL(HLog)、BlockCache、MemStore、HFile組成,如圖A,其中圖A是0.94-的架構圖,圖B是0.96+的新架構圖

圖A

圖B
- WAL(Write Ahead Log):它是HDFS上的一個文件,所有寫操作都會先保證將數據寫入這個Log文件後,才會真正更新MemStore,最後寫入HFile中
- 採用這種模式,可以保證HRegionServer宕機後,依然可以從該Log文件中讀取數據,Replay所有的操作,來保證數據的一致性
- 一個HRegionServer只有一個WAL實例,即一個HRegionServer的所有WAL寫都是串列,這當然會引起性能問題,在HBase 1.0之後,通過HBASE-5699實現了多個WAL並行寫(MultiWAL),該實現採用HDFS的多個管道寫,以單個HRegion為單位
- Log文件會定期Roll出新的文件而刪除舊的文件(那些已持久化到HFile中的Log可以刪除)。WAL文件存儲在/hbase/WALs/${HRegionServer_Name}的目錄中
- BlockCache(圖B):是一個讀緩存,將數據預讀取到記憶體中,以提升讀的性能
- HBase中提供兩種BlockCache的實現:預設on-heap LruBlockCache和BucketCache(通常是off-heap)。通常BucketCache的性能要差於LruBlockCache,然而由於GC的影響,LruBlockCache的延遲會變的不穩定,而BucketCache由於是自己管理BlockCache,而不需要GC,因而它的延遲通常比較穩定,這也是有些時候需要選用BucketCache的原因
- HRegion:是一個Table中的一個Region在一個HRegionServer中的表達,是Hbase中分散式存儲和負載均衡的最小單元
- 一個Table擁有一個或多個Region,分佈在一臺或多台HRegionServer上
- 一臺HRegionServer包含多個HRegion,可以屬於不同的Table
- 見圖A,HRegion由多個Store(HStore)構成,每個HStore對應了一個Table在這個HRegion中的一個Column Family,即每個Column Family就是一個集中的存儲單元
- HStore是HBase中存儲的核心,它實現了讀寫HDFS功能,一個HStore由一個MemStore 和0個或多個StoreFile組成
- MemStore:是一個寫緩存(In Memory Sorted Buffer),所有數據的寫在完成WAL日誌寫後,會 寫入MemStore中,由MemStore根據一定的演算法將數據Flush到底層HDFS文件中(HFile),通常每個HRegion中的每個 Column Family有一個自己的MemStore
- HFile(StoreFile): 用於存儲HBase的數據(Cell/KeyValue)。在HFile中的數據是按RowKey、Column Family、Column排序,對相同的Cell(即這三個值都一樣),則按timestamp倒序排列
- 小結:
- Table中的所有行都按照row key的字典序排列,Table 在行的方向上分割為多個Hregion,如下圖1
- region按大小分割的,每個表一開始只有一個region,隨著數據不斷插入表,region不斷增大,當增大到一個閥值的時候,Hregion就會等分會兩個新的Hregion,如下圖2
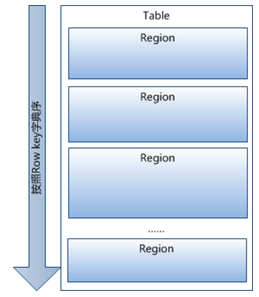
圖1
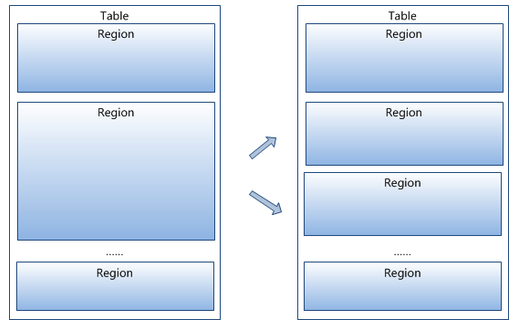
圖2
3、HRegion是Hbase中分散式存儲和負載均衡的最小單元。最小單元就表示不同的Hregion可以分佈在不同的HRegion server上。但一個Hregion是不會拆分到多個server上的,如下圖

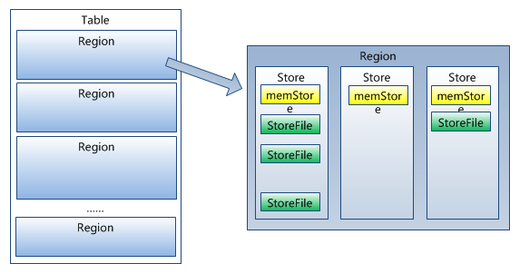
4、HRegion雖然是分散式存儲的最小單元,但並不是存儲的最小單元。事實上,HRegion由一個或者多個Store組成,每個store保存一個columns family,每個Strore又由一個memStore和0至多個StoreFile組成,如下圖,說明:StoreFile以HFile格式保存在HDFS上
nameSpace:
- 在HBase中,namespace命名空間指對一組表的邏輯分組,類似RDBMS中的database,方便對錶在業務上劃分。
- Apache HBase從0.98.0, 0.95.2兩個版本開始支持namespace級別的授權操作,HBase全局管理員可以創建、修改和回收namespace的授權
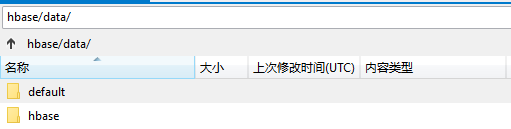
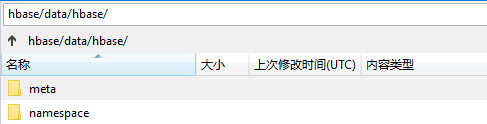
- HBase系統預設定義了兩個預設的namespace,見如下圖的目錄結構:
- hbase:系統內建表,包括namespace和meta表
- default:用戶建表時未指定namespace的表都創建在此
HBase定址:
- 本節主要討論的問題:Client訪問用戶數據時如何找到某個row key所在的region?
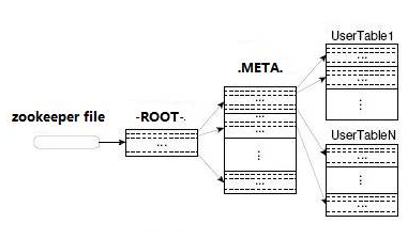
- 0.94- 版本 Client訪問用戶數據之前需要首先訪問zookeeper,然後訪問-ROOT-表,接著訪問.META.表,最後才能找到用戶數據的位置去訪問,中間需要多次網路操作,如下圖:
- 0.96+ 刪除了root 表,改為zookeeper裡面的文件,如下圖 A, 以讀為例,定址示意圖如B
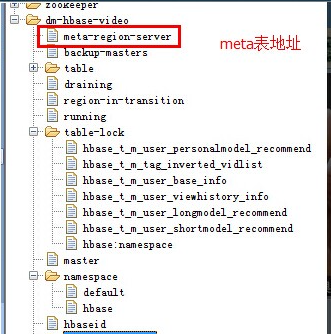
圖A
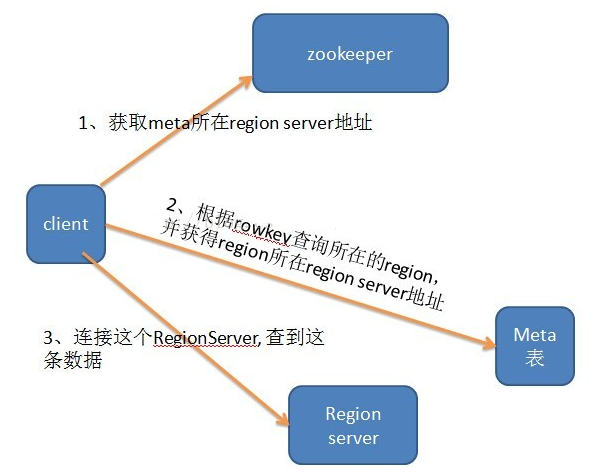
圖B
Write:
- 當客戶端發起一個Put請求時,首先根據RowKey定址,從hbase:meta表中查出該Put數據最終需要去的HRegionServer
- 客戶端將Put請求發送給相應的HRegionServer,在HRegionServer中它首先會將該Put操作寫入WAL日誌文件中(Flush到磁碟中),如下圖:
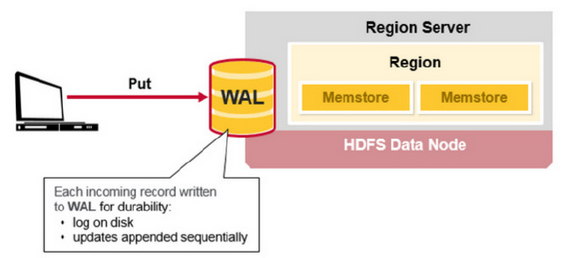
- 完WAL日誌文件後,HRegionServer根據Put中的TableName和RowKey找到對應的HRegion,並根據Column Family找到對應的HStore
- 將Put數據寫入到該HStore的MemStore中。此時寫成功,並返回通知客戶端
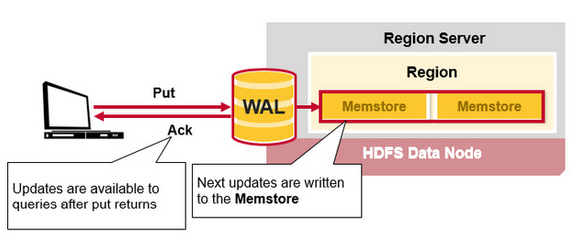
- 上一節介紹過,MemStore是一個In Memory Sorted Buffer,在每個HStore中都有一個MemStore,即它是一個HRegion的一個Column Family對應一個實例。
- 它的排列順序以RowKey、Column Family、Column的順序以及Timestamp的倒序,如下示意圖:
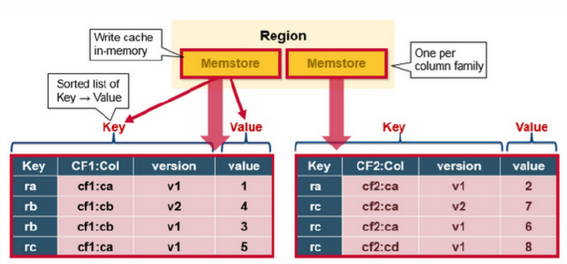
- 每一次Put請求都是先寫入到MemStore中,當MemStore滿後會Flush成一個新的StoreFile(底層實現是HFile),即一個HStore(Column Family)可以有0個或多個StoreFile(HFile)
- 註意:MemStore的最小Flush單元是HRegion而不是單個MemStore, 這就是建議使用單列族的原因,太多的Column Family一起Flush會引起性能問題
- MemStore觸發Flush動作的時機:
- 當一個MemStore的大小超過了hbase.hregion.memstore.flush.size的大小,此時當前的HRegion中所有的MemStore會Flush到HDFS中
- 當全局MemStore的大小超過了hbase.regionserver.global.memstore.upperLimit的大小,預設40%的記憶體使用量。此時當前HRegionServer中所有HRegion中的MemStore都會Flush到HDFS中,Flush順序是MemStore大小的倒序,直到總體的MemStore使用量低於hbase.regionserver.global.memstore.lowerLimit,預設38%的記憶體使用量
- 待確認:一個HRegion中所有MemStore總和作為該HRegion的MemStore的大小還是選取最大的MemStore作為參考?
- 當前HRegionServer中WAL的大小超過了hbase.regionserver.hlog.blocksize * hbase.regionserver.max.logs的數量,當前HRegionServer中所有HRegion中的MemStore都會Flush到HDFS中,Flush使用時間順序,最早的MemStore先Flush直到WAL的數量少於hbase.regionserver.hlog.blocksize * hbase.regionserver.max.logs
- 註意:因為這個大小超過限制引起的Flush不是一件好事,可能引起長時間的延遲
- 在MemStore Flush過程中,還會在尾部追加一些meta數據,其中就包括Flush時最大的WAL sequence值,以告訴HBase這個StoreFile寫入的最新數據的序列,那麼在Recover時就直到從哪裡開始。在HRegion啟動時,這個sequence會被讀取,並取最大的作為下一次更新時的起始sequence,如下圖:
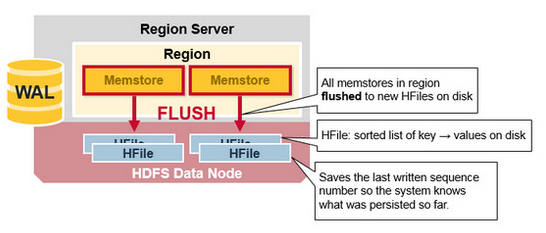
Compaction:
- MemStore每次Flush會創建新的HFile,而過多的HFile會引起讀的性能問題,HBase採用Compaction機制來解決這個問題
- HBase中Compaction分為兩種:Minor Compaction和Major Compaction
- Minor Compaction: 是指選取一些小的、相鄰的StoreFile將他們合併成一個更大的StoreFile,在這個過程中不會處理已經Deleted或Expired的Cell。一次Minor Compaction的結果是更少並且更大的StoreFile, 如下圖:
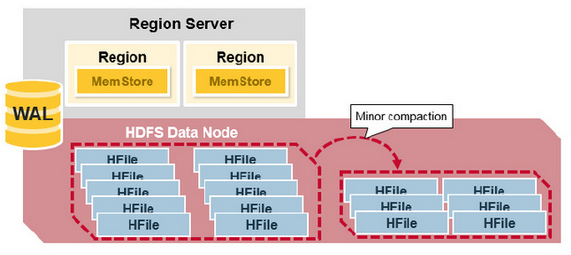
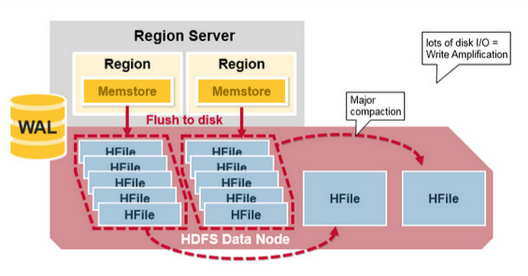
- Major Compaction: 是指將所有的StoreFile合併成一個StoreFile,在這個過程中,標記為Deleted的Cell會被刪除,而那些已經Expired的Cell會被丟棄,那些已經超過最多版本數的Cell會被丟棄。一次Major Compaction的結果是一個HStore只有一個StoreFile存在
- Major Compaction可以手動或自動觸發,然而由於它會引起很多的IO操作而引起性能問題,因而它一般會被安排在周末、凌晨等集群比較閑的時間, 如下示意圖:
- 修改Hbase配置文件可以控制compaction行為
- hbase.hstore.compaction.min :預設值為 3,(老版本是:hbase.hstore.compactionThreshold),即store下麵的storeFiles數量 減去 正在compaction的數量 >=3是,需要做compaction
- hbase.hstore.compaction.max 預設值為10,表示一次minor compaction中最多選取10個store file
- hbase.hstore.compaction.min.size 表示文件大小小於該值的store file 一定會加入到minor compaction的store file中
- hbase.hstore.compaction.max.size 表示文件大小大於該值的store file 一定會被minor compaction排除
splite:
- 最初,一個Table只有一個HRegion,隨著數據寫入增加,如果一個HRegion到達一定的大小,就需要Split成兩個HRegion,這個大小由hbase.hregion.max.filesize指定
- split時,兩個新的HRegion會在同一個HRegionServer中創建,它們各自包含父HRegion一半的數據,當Split完成後,父HRegion會下線,而新的兩個子HRegion會向HMaster註冊上線
- 處於負載均衡的考慮,這兩個新的HRegion可能會被HMaster分配到其他的HRegionServer,示意圖如下:
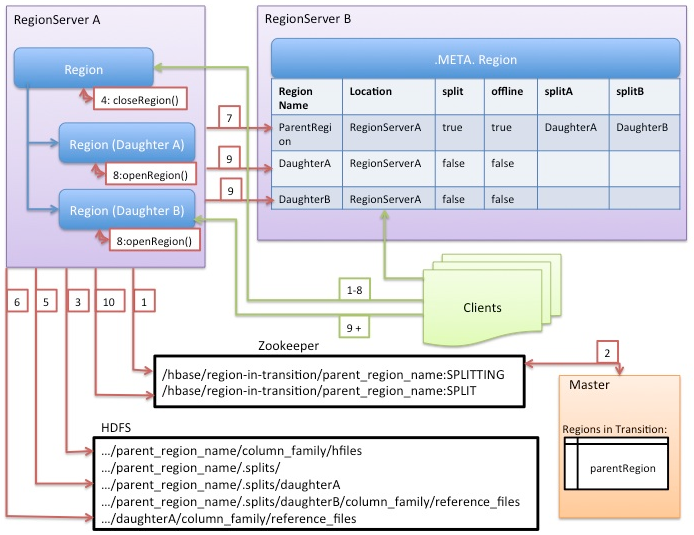
- 在zookeeper上創建ephemeral的znode指示parent region正在splitting
- HMaster監控父Regerion的region-in-transition znode
- 在parent region的文件夾中創建臨時split目錄
- 關閉parent region(會flush 所有memory store(memory file),等待active compaction結束),從現在開始parent region 不可服務。同時從本地server上offline parent region,每個region server都維護了一個valid region的list,該步將parent region從該list中移除
- Split所有的store file,這一步為每個文件做一個reference file,reference file由兩部分組成
- 第一部分是源文件的路徑,第二部分是新的reference file引用源文件split key以及引用上半截還是下半截
- 舉個例子:源文件是Table1/storefile.11,split point 是key1, 則split 成兩個子文件可能可能是Table1/storefile.11.bottom.key1,Table1/storefile.11.up.key1,表示從key1切開storefile.11後,兩個引用文件分別引用源文件的下半部分和上半部分
- 創建child region
- 設置各種屬性,比如將parent region的訪問指標平分給child region,每人一半
- 將上面在parent 文件夾中生成的臨時文件夾(裡面包含對parent region的文件reference)move到表目錄下,現在在目錄層次上,child region已經跟parent region平起平坐了
- 向系統meta server中寫入parent region split完畢的信息,並將child region的名字一併寫入(split狀態在meta層面持久化)
- 分別Open 兩個child region,主要包含以下幾個步驟:
- 將child region信息寫入meta server
- Load 所有store file,並replay log等
- 如果包含reference文件,則做一次compaction(類似merge),直到將所有的reference文件compact完畢,這裡可以看到parent region的文件是會被拆開寫入各個child regions的
- 將parent region的狀態由SPLITTING轉為SPLIT,zookeeper會負責通知master開始處理split事件,master開始offline parent region,並online child regions
- Worker等待master處理完畢之後,確認child regions都已經online,split結束
read:
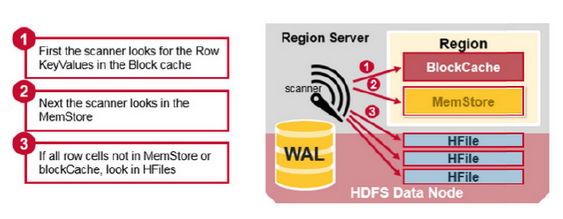
- 根據Rowkey定址(詳情見上一節定址部分),如下圖:
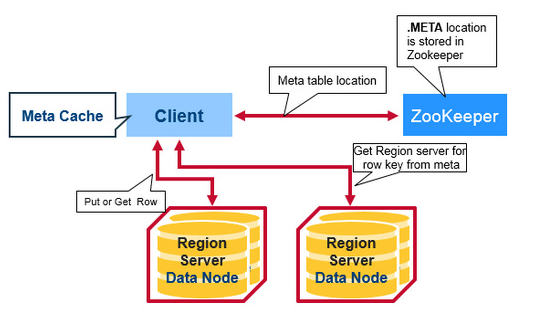
獲取數據順序規則,如下圖:
參考和來源:https://www.cnblogs.com/tgzhu/p/5857035.html
參考資料:
- http://hortonworks.com/blog/apache-hbase-region-splitting-and-merging/
- https://www.mapr.com/blog/in-depth-look-hbase-architecture#.VdNSN6Yp3qx


