
細說Spark Streaming和Structured Streaming的區別 ...
簡介
Spark Streaming
Spark Streaming是spark最初的流處理框架,使用了微批的形式來進行流處理。
提供了基於RDDs的Dstream API,每個時間間隔內的數據為一個RDD,源源不斷對RDD進行處理來實現流計算
Structured Streaming
Spark 2.X出來的流框架,採用了無界表的概念,流數據相當於往一個表上不斷追加行。
基於Spark SQL引擎實現,可以使用大多數Spark SQL的function
區別
1. 流模型
Spark Streaming

Spark Streaming採用微批的處理方法。每一個批處理間隔的為一個批,也就是一個RDD,我們對RDD進行操作就可以源源不斷的接收、處理數據。
spark streaming微批終是批
Structured Streaming
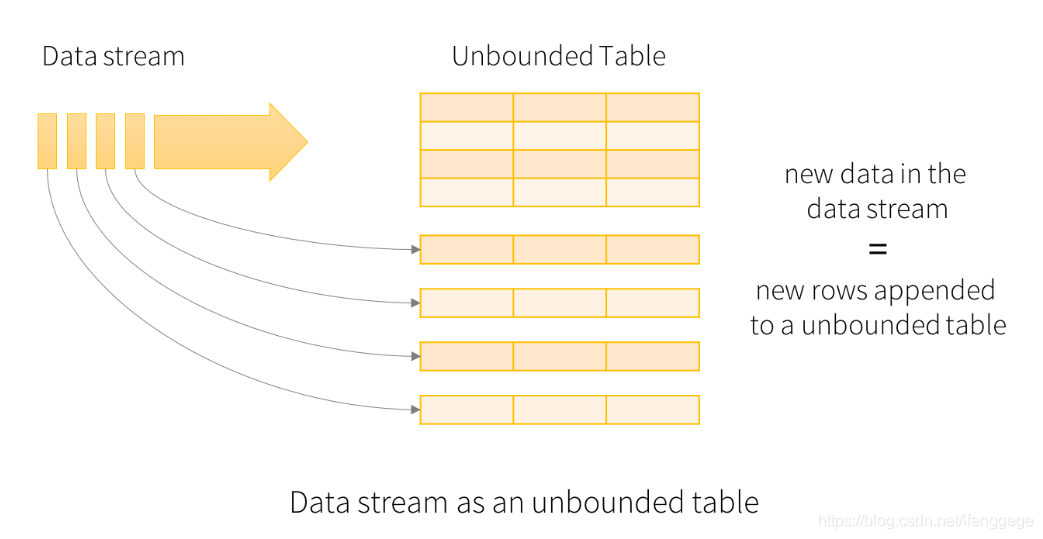
Structured Streaming is to treat a live data stream as a table that is being continuously appended
Structured Streaming將實時數據當做被連續追加的表。流上的每一條數據都類似於將一行新數據添加到表中。
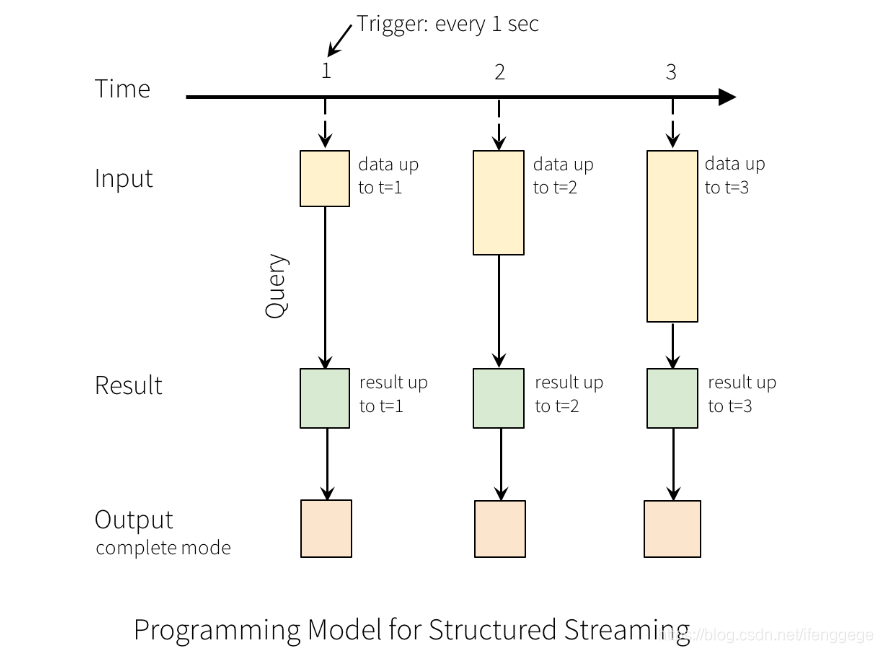
以上圖為例,每隔1秒從輸入源獲取數據到Input Table,並觸發Query計算,然後將結果寫入Result Table,之後根據指定的Output模式進行寫出。
上面的1秒是指定的觸發間隔(trigger interval),如果不指定的話,先前數據的處理完成後,系統將立即檢查是否有新數據。
需要註意的是,Spark Streaming本身設計就是一批批的以批處理間隔劃分RDD;而Structured Streaming中並沒有提出批的概念,Structured Streaming按照每個Trigger Interval接收數據到Input Table,將數據處理後再追加到無邊界的Result Table中,想要何種方式輸出結果取決於指定的模式。所以,雖說Structured Streaming也有類似於Spark Streaming的Interval,其本質概念是不一樣的。Structured Streaming更像流模式。
2. RDD vs. DataFrame、DataSet
Spark Streaming中的DStream編程介面是RDD,我們需要對RDD進行處理,處理起來較為費勁且不美觀。
stream.foreachRDD(rdd => {
balabala(rdd)
})Structured Streaming使用DataFrame、DataSet的編程介面,處理數據時可以使用Spark SQL中提供的方法,數據的轉換和輸出會變得更加簡單。
spark
.readStream
.format("kafka")
.option("kafka.bootstrap.servers", "hadoop01:9092")
.option("subscribe", "order_data")
.load()
.select($"value".cast("string"))
.as[String]
.writeStream
.outputMode("complete")
.format("console")3. Process Time vs. Event Time
Process Time:流處理引擎接收到數據的時間
Event Time:時間真正發生的時間
Spark Streaming中由於其微批的概念,會將一段時間內接收的數據放入一個批內,進而對數據進行處理。劃分批的時間是Process Time,而不是Event Time,Spark Streaming沒有提供對Event Time的支持。
Structured Streaming提供了基於事件時間處理數據的功能,如果數據包含事件的時間戳,就可以基於事件時間進行處理。
這裡以視窗計數為例說明一下區別:
我們這裡以10分鐘為視窗間隔,5分鐘為滑動間隔,每隔5分鐘統計過去10分鐘網站的pv
假設有一些遲到的點擊數據,其本身事件時間是12:01,被spark接收到的時間是12:11;在spark streaming的統計中,會毫不猶豫的將它算作是12:05-12:15這個範圍內的pv,這顯然是不恰當的;在structured streaming中,可以使用事件時間將它劃分到12:00-12:10的範圍內,這才是我們想要的效果。
4. 可靠性保障
兩者在可靠性保證方面都是使用了checkpoint機制。
checkpoint通過設置檢查點,將數據保存到文件系統,在出現出故障的時候進行數據恢復。
在spark streaming中,如果我們需要修改流程式的代碼,在修改代碼重新提交任務時,是不能從checkpoint中恢複數據的(程式就跑不起來),是因為spark不認識修改後的程式了。
在structured streaming中,對於指定的代碼修改操作,是不影響修改後從checkpoint中恢複數據的。具體可參見文檔。
5. sink
二者的輸出數據(寫入下游)的方式有很大的不同。
spark streaming中提供了foreachRDD()方法,通過自己編程實現將每個批的數據寫出。
stream.foreachRDD(rdd => {
save(rdd)
})structured streaming自身提供了一些sink(Console Sink、File Sink、Kafka Sink等),只要通過option配置就可以使用;對於需要自定義的Sink,提供了ForeachWriter的編程介面,實現相關方法就可以完成。
// console sink
val query = res
.writeStream
.outputMode("append")
.format("console")
.start()最後
總體來說,structured streaming有更簡潔的API、更完善的流功能、更適用於流處理。而spark streaming,更適用於與偏批處理的場景。
在流處理引擎方面,flink最近也很火,值得我們去學習一番。
reference
https://blog.knoldus.com/spark-streaming-vs-structured-streaming/
https://dzone.com/articles/spark-streaming-vs-structured-streaming
https://spark.apache.org/docs/2.0.2/streaming-programming-guide.html
https://spark.apache.org/docs/latest/structured-streaming-programming-guide.html
以上為個人理解,如有不對的地方,歡迎交流指正。

個人公眾號:碼農峰,推送最新行業資訊,每周發佈原創技術文章,歡迎大家關註。


