
本文為筆者在InfoQ首發的原創文章,主要介紹了SQL Server 2019的新特性和產品演進思路。現轉載回自己的博客,請大家多多指教。 ...
本文為筆者在InfoQ首發的原創文章,主要利用周末時間陸續寫成,也算近期用心之作。現轉載回自己的公眾號,請大家多多指教。
11 月 4 日,微軟正式發佈了其新一代資料庫產品 SQL Server 2019,帶來了大數據集群、數據虛擬化等重磅特性。本次發佈距離上一個大版本 SQL Server 2017 不過短短兩年時間,這樣的迭代速度對於高度複雜的資料庫系統而言頗為驚人。兩年前 InfoQ 曾刊登長文《SQL Server 2017 正式發佈,微軟老牌資料庫如何繼往開來?》,此次我們再度與該文作者合作,為大家深度解讀 SQL Server 2019 的進展與特色。
21 世紀以來,數據平臺的戰場上烽火連天、精彩紛呈。所謂江山代有才人出,以 MongoDB、Redis、Neo4j 等為代表的 NoSQL 資料庫和 Hive、Impala、Presto 等 Hadoop 體系大數據解決方案風頭一時無兩。在這些年輕後輩們的衝擊之下,關係資料庫作為數據架構的中堅力量,不但沒有節節敗退,近年反倒有王者歸來、愈戰愈勇之勢。在如今各類關鍵系統的設計和架構中,關係型資料庫仍然以穩定的表現和豐富的特性占據著核心地位。
SQL Server是關係資料庫中的傑出代表,是與 Oracle、DB2 齊名的企業級商用資料庫“三巨頭”之一。長達數十年的發展和磨礪,已讓它非常成熟穩定;而跟隨時代發展不斷地融合技術新趨勢,又使它非常全面。尤其上一個版本 SQL Server 2017 更是將此款傳奇資料庫帶入了廣闊的 Linux 世界,進一步拓展了它的潛在客戶群體和使用場景。
我們大可先簡單回顧 SQL Server 琳琅滿目的豐富特性。在兩年前的文章中我們提到,SQL Server 已經集傳統行存儲、可更新的列存儲、記憶體表、圖資料庫、機器學習等十八般武藝於一身。這其中許多先進的特性,有些是開源資料庫仍在苦苦追趕的領域,或是無法在同一個資料庫中進行完美的集成。這正是商業資料庫的價值所在:以高穩定性、高性能與高集成度贏得青睞,在幫助客戶支撐解決關鍵業務問題的同時,亦能簡化技術架構、減輕維護負擔。
僅僅兩年的時間,微軟就在上一代的基礎上發展構建出了全新的 SQL Server 2019,這樣的迭代速度對於高度複雜的資料庫系統而言頗為驚人。快節奏發佈固然和如今業界普遍激進的版本策略有關,但大家也一定好奇,一個已經高度成熟的商業資料庫系統,在這樣短的時間里究竟能取得怎樣的進步?又在哪些方面針對變幻莫測的市場作出了自己的回應呢?本文將與大家一同探索。
結合 SQL Server 2019 的新特性,我們接下來分別從核心引擎增強、數據虛擬化以及此版本最大亮點 SQL Server 大數據集群三個方面來進行分析和探討。
核心引擎增強
我們首先從核心引擎部分說起。HTAP (Hybrid transaction/analytical processing) 混合負載能力是當今資料庫世界的趨勢,SQL Server 在這方面是行業引領者之一,之前版本已通過在單一引擎中完美集成行存儲和列存儲實現了對 OLTP 和 OLAP 工作負載的同時支撐。用戶不但可以同時查詢和連接行存和列存表,甚至可以為一個行存儲表添加非聚集的列存儲索引,使得單表能夠同時較好地支持 OLTP 和 OLAP 兩種工作模式和查詢場景。
SQL Server 2019 中繼續強化了對於混合負載能力的支持,通過潤物細無聲式的改進讓相關引擎進一步成熟,也使得日常使用更為便捷。例如在列存儲索引方面,現已允許線上地創建或重新構建 (REBUILD) 聚集列存儲索引——這將大大方便生產環境中大型列存儲表的維護和使用,既能節省存儲空間,又能提高後續查詢性能。在筆者接觸的生產環境中就常有列存儲表由於部分行的更新導致碎片問題,但為了保障線上業務的連續性,一直只能使用相對輕量的 REORGANIZE 命令進行簡單的維護。該問題有望在資料庫升級後徹底解決。
上一代 SQL Server 2017 中引入的圖數據引擎在 SQL Server 2019 中也得到了相當幅度的增強。其改進既包括在存儲層面支持圖數據表和索引使用多 filegroup 進行分區,還新增了極為重要的任意長度模式 (Arbitrary Length Pattern) 支持,用戶終於可以表達節點間任意次數的跳躍連通關係了。我們來看一個針對人物關係圖的官方查詢樣例:
SELECT PersonName, Friends FROM ( SELECT Person1.name AS PersonName, STRING_AGG(Person2.name, '->') WITHIN GROUP (GRAPH PATH) AS Friends, LAST_VALUE(Person2.name) WITHIN GROUP (GRAPH PATH) AS LastNode FROM Person AS Person1, friendOf FOR PATH AS fo, Person FOR PATH AS Person2 WHERE MATCH(SHORTEST_PATH(Person1(-(fo)->Person2)+)) AND Person1.name = 'Jacob' ) AS JacobReach WHERE JacobReach.LastNode = 'Alice'
容易理解的是,該查詢將能夠幫助判斷 Jacob 與 Alice 兩人是否連通,並給出他們之間的最短關係路徑,而這條路徑的長度是不確定的。T-SQL 語法上的關鍵點在於 MATCH 子句:其中使用了一個 SHORTEST_PATH 方法來尋找計算圖中兩個給定節點間的最短距離。需註意該方法的輸入參數支持類似正則表達式語法的不定長模式,通過一個 + 號巧妙地表達了通過 friendOf 關係多次連續尋路,被加號括起的 -(fo)->Person2 即為可多次重覆的部分。
上述特性是圖資料庫應用最常見的高級查詢場景之一,數學上被稱為傳遞閉包 (transitive closure)。該特性的加入意味著 SQL Server 2019 在圖查詢能力方面終於登堂入室,開始逐漸具備與專用圖資料庫競爭的實力。
商用資料庫一向對於硬體領域發展較為關註,不斷通過最新的硬體最大化性能潛力。持久性記憶體 (Persistent Memory, 常縮寫為 PMEM) 以其遠優於 SSD 硬碟的 IO 能力,成為了當下伺服器端硬體的熱點之一,英特爾等廠商紛紛大力規劃發展如 Optane DC 這樣的企業級持久性記憶體硬體產品。為此,SQL Server 2019 不失時機地推出了混合緩衝池 (Hybrid Buffer Pool) 特性,可讓持久性記憶體作為間於 DRAM 記憶體和 SSD 硬碟的存儲層,在性能攸關的頁面緩衝池上發揮顯著的加速作用。用戶選擇開啟此特性後,頁面緩衝池可擴展到 PMEM 設備上的存儲空間,SQL Server 則直接通過記憶體映射 IO 訪問位於 PMEM 設備上的數據頁。在許多情況下這樣可避免數據頁頻繁地從傳統磁碟拷貝到 DRAM,進行頁訪問時也能夠繞過操作系統的存儲協議棧開銷,從而取得巨大的性能提升。
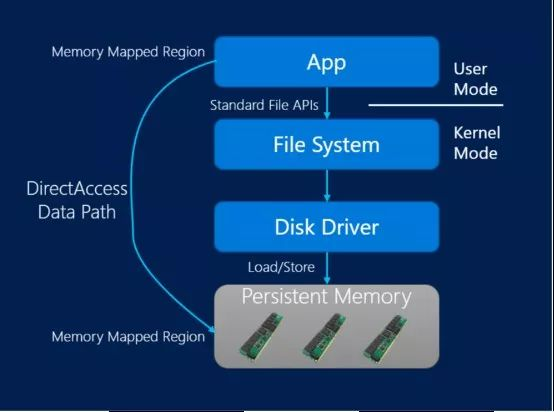
值得一提的是,甲骨文將於明年發佈的全新一代 Oracle 20c,同樣會提供對於持久性記憶體的支持——在這一點上,可謂與 SQL Server 英雄所見略同。
我們再來看編程語言集成方面。以往擴展 SQL Server 功能是 C#/.NET 的專利,例如用戶可以通過 SQL Server 的 CLR 集成調用.NET 編寫的 UDF。隨著微軟近年來的開放策略持續推進,更多語言進入了 SQL Server 的體系。兩年前我們曾介紹 SQL Server 2017 中集成了 Python/R 的環境以方便進行機器學習方面工作,而在 SQL Server 2019 中此次 Java 則成為了主要的集成和支持對象。通過全新的語言擴展體系 (SQL Server Language Extensions) 可使得 Java 類與方法直接在 SQL Server 伺服器上本地執行。用戶只需要實現微軟 Java 擴展 SDK (Microsoft Extensibility SDK for Java) 中的抽象類 AbstractSqlServerExtensionExecutor 即可讓自己封裝的 Java 代碼通過 sp_execute_external_script 存儲過程在資料庫 T-SQL 上下文中調用運行。
一個與 Java 支持相關的話題是,由於 Oracle 對於 Java 的版權控制和使用條款不斷收緊,為避免 SQL Server 中內嵌 Oracle Java 環境帶來不必要的限制和風險,微軟近期與 Java 開源貢獻者和發行商 Azul Systems 達成了一系列合作,使用 Azul Zulu JRE/JDK(基於 OpenJDK)作為 Azure 雲和 SQL Server 上 Java 的預設選項。這樣 Azure 和 SQL Server 的用戶就可獲得和使用一款免費且受支持的 Java 運行環境,該環境能夠提供安全更新和 Bug 修複,免除了後顧之憂。我們預計類似的做法會逐步成為各大廠的必然選擇。這個來自 Azul Systems 的 Java 環境不但有助於上述 SQL Server 的 Java 擴展功能,更會為接下來將介紹的 PolyBase 功能和 SQL Server 大數據集群起到至關重要的支撐作用。
上面涉及的各個新功能,只是 SQL Server 2019 引擎新能力的一部分。事實上新版本還有許多可圈可點的改進,如 APPROX_COUNT_DISTINCT 近似聚合函數、TempDB 元數據的記憶體化 (Memory-Optimized TempDB Metadata)、UTF-8 字元編碼支持、針對行存儲的批處理模式 (batch mode on rowstore) 支持以及行模式下的記憶體分配反饋 (row mode memory grant feedback) 等。這些特性分佈於存儲執行引擎的各個環節,進一步提升了 SQL Server 的能力和深度。
數據虛擬化
前面提到,支持多模型多範式已經成為商業資料庫追求的重要目標之一,以求確立和維護在企業整體數據架構中的核心地位。但在實際情況下,異構數據源總會客觀存在,所以從另一個思路上來說,如何加強並便利與異構數據源之間的互聯互通,也逐漸成為了現代資料庫產品中的重要考量和評定標準。
數據互聯互通,最容易想到的就是使用類似 SSIS 和 Azure Data Factory 這樣的 ETL 工具來進行定時的數據傳輸。這固然是行之有效的方法,但存在數據時效性和數據重覆等局限。如今相較建立 ETL 通道更為先進的一種理念,就是數據虛擬化。所謂數據虛擬化,顧名思義就是不論數據以具體何種格式存放何處,都能以統一的抽象進行管理和訪問。技術上來說,以資料庫為核心的數據虛擬化體系主要以聲明式的外部表來指向和定義底層數據。
在 SQL Server 2019 版本中,微軟將數據虛擬化作為產品核心概念和主要建設目標提出,併在功能層面通過內置的 PolyBase 技術進行了關鍵支撐和加強。PolyBase 其實並非一個新面孔,它最早出現於 SQL Server 2012 Parallel Data Warehouse 中,服務於這個軟硬一體化的分散式 MPP 資料庫版本。PolyBase 組件在功能上賦予了資料庫層面定義指向 Hadoop/HDFS 數據的外部表的能力,成為幫助打通關係資料庫與 Hadoop 大數據生態系統的重要橋梁。在 SQL Server 2016 中 PolyBase 則真正變得成熟並且廣為人知,正式出現在了標準 SQL Server 中,大大地拓展了受眾。
Polybase 的外聯能力在 SQL Server 2019 版本中進一步得到了強化,除原先支持的 Hadoop 和 Azure Blob Storage 外,新版本額外添加了 SQL Server、Oracle、Teradata、MongoDB 和 ODBC 的支持。如果說 PolyBase 之前只是不起眼的附屬功能,在強調數據虛擬化的 SQL Server 2019 中已是位居聚光燈下的核心能力。
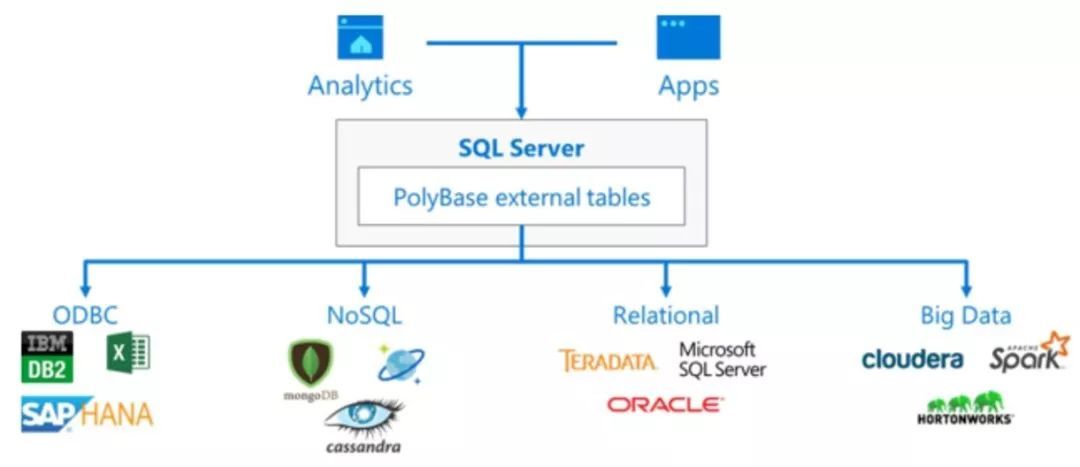
不妨來看一個在 SQL Server 2019 中使用 PolyBase 配置遠端 MongoDB 數據源的簡單例子,以此來理解數據虛擬化的落地形態。
CREATE DATABASE SCOPED CREDENTIAL MongoCredential WITH IDENTITY = 'username', SECRET = 'password'; CREATE EXTERNAL DATA SOURCE MongoDBSource WITH ( LOCATION = 'mongodb://<server>[:<port>]', PUSHDOWN = ON, CREDENTIAL = MongoCredential ); CREATE EXTERNAL TABLE MyMongoCollection( [_id] NVARCHAR(24) NOT NULL, [column1] NVARCHAR(MAX) NOT NULL, [column2] INT NOT NULL -- ..., other columns to be mapped ) WITH ( LOCATION='dbname.collectionname', DATA_SOURCE= MongoDBSource );
可以看到,通過 T-SQL 對憑證 (credential)、數據源 (data source)、外部表 (external table) 這三個核心配置進行定義,就可以輕鬆地將 MongoDB 中的集合與欄位映射到 SQL Server 中來,後續即可對虛擬的外部表進行查詢。PolyBase 甚至還支持 MongoDB 中的對象、數組等嵌套結構,允許在外部表定義時將複雜欄位打平。另外,雖然此處所舉的例子是針對 MongoDB,若需連接其他類型數據源,配置的步驟也大致類似,只是相關參數的含義和形式有所不同。
值得註意的是,PolyBase 加持下的外部表使用起來與一般數據表無異,能夠與其他表進行 join 等操作,這大大方便了異構數據源之間的集成,許多情況下能夠免除數據搬運的麻煩。當然,對於一些出於性能原因不便直接查詢的場景,也可用簡單的 SQL 語句將外部表數據方便地同步到 SQL Server 內部。
在技術實現層面,PolyBase 由於脫胎於 MPP 架構場景,所以其實具備很好的並行擴展能力——當遠端數據體量巨大時這一特性殊為重要,能夠極大地加速查詢的執行。用戶可以設立多個 SQL Server 實例(分為頭節點和計算節點)並編組為 PolyBase Scale-out Group 來協同工作,對外部大數據進行並行讀取和處理。從這個層面來看,PolyBase 模塊已使 SQL Server 具備了分散式分析型資料庫的一些典型特征。
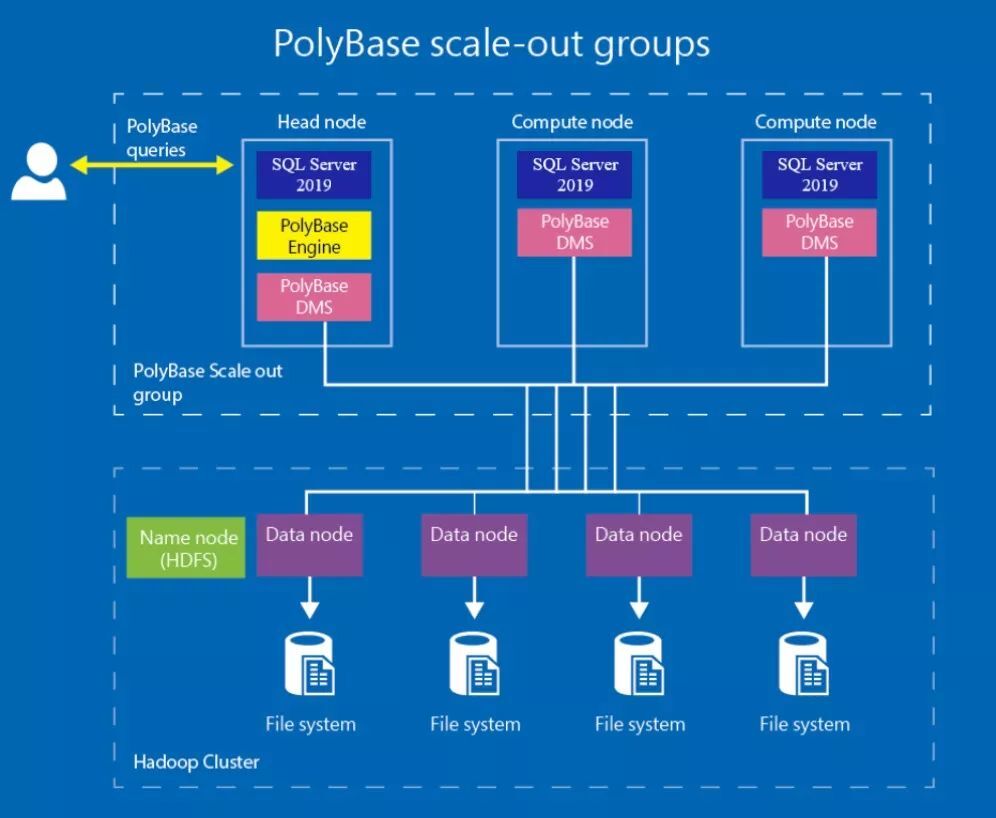
PolyBase 的另一個特點,是具備一定的查詢下推 (pushdown) 能力,在遠端能夠支持的情況下,查詢處理器會將符合條件的謂詞發送到數據源端進行就近處理,既提高查詢性能同時也減輕網路 IO 的負擔。例如,在面向 Hadoop 的讀取場景下,有時 PolyBase 會根據統計信息選擇使用 MapReduce 來讀取過濾原始文件,最終只需傳回部分結果數據而非全量數據。
綜上所述,數據虛擬化的理念和 PolyBase 技術的增強,有望幫助新一代 SQL Server 成為數據架構的中心。通過捏合和集成多種異構數據源,SQL Server 2019 可有效降低企業架構複雜性,還能在數據冷熱分層、統一數據湖構建等應用場景中大顯身手。
SQL Server 大數據集群
SQL Server 2019 最值得一提的重磅特性,恐怕就要數 SQL Server 大數據集群了(SQL Serve Big Data Cluster)。憑藉創造性地將 Hadoop 和 Spark 等開源大數據技術組件直接納入 SQL Server 併在 Kubernetes 體系下無縫集成的大膽設計,SQL Server 大數據集群在去年一經宣佈並開始有限預覽後,即引起了廣泛關註。因為大家都非常好奇:大數據、Hadoop、Spark、容器化、雲原生這些炙手可熱的技術熱詞將如何與一個傳統商業資料庫發生化學反應呢?
SQL Server 大數據集群本質上既是 SQL Server 2019 的一個新特性,也是一種新的產品形態和部署方式。它具有以下幾個重要特點:(1) 將 SQL Server 以多實例形態進行部署和聯動,實現數據的分散式存儲、處理和計算 (2) 將 SQL Server 完全容器化並以 Kubernetes 為基礎架構實現底層計算資源的編排和管理 (3) 在自有分散式存儲基礎上額外內置提供了標準 HDFS 分散式文件系統 (4) 在計算層面額外提供了標準 Spark 作為分散式計算引擎。其架構概覽圖如下所示:
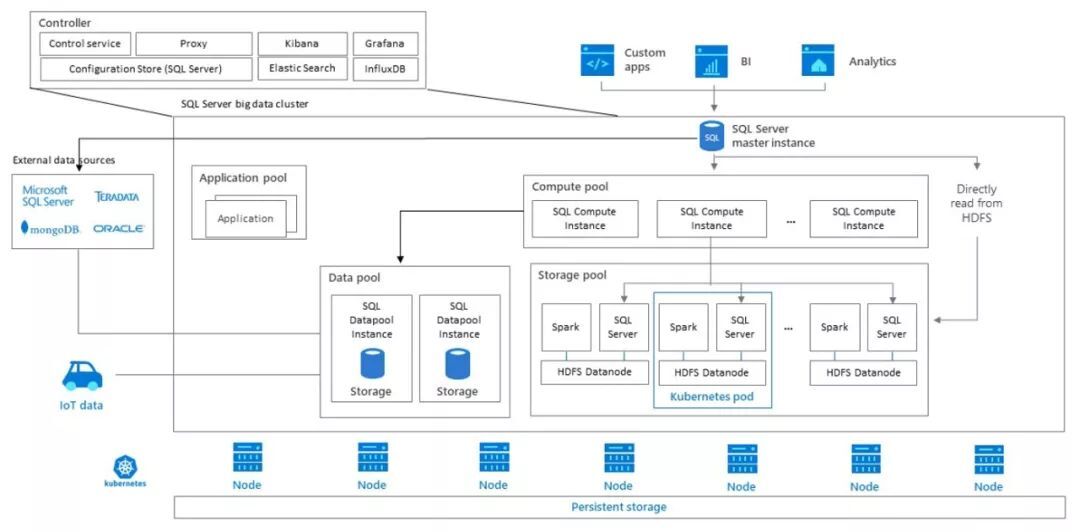
可以看到,SQL Server 大數據集群代表了微軟數據平臺最新的架構思想,從單純的與外部互聯互通,走向了與開源平臺技術的全面融合;從技術對接與相容,走向了你中有我、我中有你。這不能不說是一個大膽的嘗試,也是一個令人拍案叫絕的產品思路。它的好處顯而易見:從企業客戶角度來說 all-in-one 的設計大幅簡化了架構,用戶可基於此建設自己的一站式大數據平臺,開源與商業技術兩者兼得;從微軟角度而言,確保了開源工作負載在 SQL Server 集群和體系內順利運行,類似一個商業 Hadoop 發行版本,無疑有利於其在開源時代繼續獲得商業上的成功。
如果想體驗 SQL Server 2019,最簡便的方法是先建立一個 Azure Kubernetes Service(AKS) 集群(當然也支持其他雲或本地 K8s 集群),然後藉助 azdata 命令行工具即可一鍵將 SQL Server 大數據集群部署至 Kubernetes。筆者進行了相關的動手實驗和架構觀察,發現 SQL Server 大數據集群在技術實現上可謂頗具看點,列舉部分如下:
- 控制、計算、存儲等各節點實現了完全容器化,部署時可自動從微軟容器註冊表 (Microsoft Container Registry) 下載相應鏡像並運行。
- 大數據集群的 master 實例支持多節點部署和高可用,通過結合 K8s 提供的底層故障檢測轉移能力和 SQL Server 中的可用性組 (Availability Group) 共同實現。
- 分散式存儲底層由 VM 集群掛載的磁碟組合構成,向上提供了兩種不同選擇 Data Pool 和 Storage Pool,分別對應私有和開源技術。使用時通過定義外部表指向 sqldatapool 或 sqlhdfs 協議下的地址進行掛載和訪問。兩種不同的存儲可以結合使用,互相配合。
- Data Pool 提供了 SQL Server 自有的分散式存儲能力,一般配合 ROUND-ROBIN 數據分佈策略,可提供較高的數據載入性能。實際場景中可作為外部數據接入時的落地選擇,也可作為大查詢結果集的持久化存儲。
- Storage Pool 對應的 Pod 高度集成了 Spark、HDFS DataNode 和 SQL Server 實例,對外提供了一個完整的 HDFS 文件系統,可完美相容使用 Parquet 等開源體系的列存儲格式,還能通過 HDFS tiering 功能掛載使用 Amazon S3、Azure Data Lake Storage Gen2 等雲端存儲服務;查詢時 SQL Server 能夠通過 NameNode 提供的信息進行尊重 data locality 的本地高速讀取,還能夠在許多情況下支持謂詞下推 (predicate pushdown)。
- 大數據集群全面集成 Spark 運行環境意義重大,意味著可使用標準 Spark 技術棧讀寫 Storage Pool,與 SQL Server 就地共用同一份數據。經驗證此次發佈集成的 Spark 版本為 2.4,是最新的大版本。
- 大數據集群自動安裝包含了 Elasticsearch 和 Kibana 組件,幫助監控系統各環節的關鍵指標與健康狀態。
- 工具支持方面可使用跨平臺的 Azure Data Studio 連接 SQL Server 大數據集群,SQL Server 2019 專用插件大大方便了自助查詢、集群管理、外部表創建等工作。還可在 Azure Data Studio 中使用廣受歡迎的 Jupyter Notebook 連接到集群,通過 SQL、Python/PySpark 或 Scala/Spark 腳本進行探索式數據分析和機器學習模型訓練。
限於篇幅,更多內容此處不再展開。若大家對其中一些關鍵細節和動手實操感興趣,可關註筆者微信公眾號“雲間拾遺”的後續文章瞭解更多信息。
在定價方面,雖然 SQL Server 大數據集群仍屬商用資料庫範疇,且占用 CPU 核心數較多,但用戶不必過於擔心在授權費用方面的高額支出。SQL Server 團隊貼心地設計了成本友好的定價策略,主要體現為除 master 實例需要 Enterprise 或 Standard 版本授權外,其他占大多數的 computer/data/storage 節點只需要按照專門設計且便宜許多的“Big Data Node”的方式進行計費,這會大大減輕用戶在選用 SQL Server 大數據集群後的成本負擔。
回過頭來看,SQL Server 大數據集群雖然是全新的能力,但也許微軟其實早早就開始了相關佈局。因為容易發現 SQL Server 之前版本的一些成果,恰恰是此次大數據集群得以橫空出世的技術前提。比如前面提到的歷經多年積累的 PolyBase 技術,正是 SQL Server 得以和大數據技術棧無縫交互的關鍵;又如 SQL Server 2017 開始引入的 Linux 版本,則是容器化封裝得以順利達成的重要基礎條件。
微軟近年來全面擁抱開源之後,正在逐漸獲得回報。擁抱開源既能夠拉近與社區和用戶的距離,也為最新的技術產品發展贏得了更大的設計靈活度。此次徹底容器化、使用 Kubernetes 進行編排並集成 Spark、HDFS 等開源組件的 SQL Server 大數據集群,無疑也是這種“改革開放”和“拿來主義”策略的成功典範。
當然,任何事物都有其兩面性。對於 SQL Server 大數據集群這樣的一體化架構模式,也有個別業界人士持有不同觀點,認為過度整合封裝未必是雲時代的架構演化方向,他們更傾向於計算存儲分離的架構,讓每個數據組件專註做好一件事情。這就是一個仁者見仁智者見智的問題了。也許 SQL Server 大數據集群的設計初衷更側重基於本地部署的大型客戶,同時吸引對可遷移性和跨雲適配十分敏感的企業解決方案提供商——對這些場景而言,SQL Server 大數據集群不失為極具競爭力的選擇。相信市場會給予我們最終的答案。
總結
世界即將跨入新的十年。在 2019 年末發佈的 SQL Server 2019,展現了微軟在新時代對下一個十年的展望和雄心。尤其是 SQL Server 大數據集群的推出,相信將促成一批全新大數據平臺的落地,也會啟發業界思考未來大數據的架構模式,以及商業技術與開源世界和諧並存之道。
值得一提的是,SQL Server 2019 與 SQL Server 2017 一樣,擁有面向 Linux 的版本,並與 Linux 廠商一起提供官方的支持服務。事實上 SQL Server 對 Linux 的特性覆蓋也一直在默默地持續改進,2019 版本為 Linux 帶來了數據複製、Active Directory 集成、PolyBase on Linux 等重要特性。如果大家對於兩年前的首個 Linux 版本還持觀望態度的話,SQL Server 2019 對於 Linux 的相容性和功能集合已經完善了許多,是一個更好的 SQL Server for Linux,或許是時候可以“上車”了。
以雲為先的微軟,除了雲原生化 SQL Server 2019 本身外,也必然會考慮將新一代版本的新能力逐漸同步到 Azure 雲的 PaaS 服務上。其實 Azure SQL Database 已經開始支持 SQL Server 2019 中如 APPROX_COUNT_DISTINCT 等部分新特性了,只需手動設置資料庫的相容性等級 (compatibility level) 為對應 2019 版本的 150 即可。再者如 PolyBase,之前在 Azure 上僅有 SQL Data Warehouse 提供了支持(主要用於訪問 Blob Storage),後續該特性很可能會在雲端得到相應的更新增強,也期待它拓展到 SQL Databases 或 SQL Managed Instance 等更多數據服務中。
最後,我們簡要地總結 SQL Server 2019 的發展策略如下:首先繼續夯實了原生支持多種數據架構範式的多模內核,其次是不斷改進數據虛擬化技術 PolyBase 以強化外部聯接,最後通過擁抱和納入開源大數據技術體系實現整體融合。這是一個穩步發展、層層遞進的產品進化思路。不知作為用戶的你,是否已經心動?讓我們祝 SQL Server 2019 好運。
“雲間拾遺”專註於從用戶視角介紹雲計算產品與技術,堅持以實操體驗為核心輸出內容,同時結合產品邏輯對應用場景進行深度解讀。歡迎掃描下方二維碼關註“雲間拾遺”微信公眾號。


