
背景 By 魯迅 By 高爾基 說明: 1. Kernel版本:4.14 2. ARM64處理器,Contex A53,雙核 3. 使用工具:Source Insight 3.5, Visio 1. 概述 在之前的系列文章中,分析到了 的頁框分配, 的小塊記憶體對象分配,這些分配的地址都是物理記憶體連續 ...
背景
Read the fucking source code!--By 魯迅A picture is worth a thousand words.--By 高爾基
說明:
- Kernel版本:4.14
- ARM64處理器,Contex-A53,雙核
- 使用工具:Source Insight 3.5, Visio
1. 概述
在之前的系列文章中,分析到了Buddy System的頁框分配,Slub分配器的小塊記憶體對象分配,這些分配的地址都是物理記憶體連續的。當記憶體碎片後,連續物理記憶體的分配就會變得困難,可以使用vmap機制,將不連續的物理記憶體頁框映射到連續的虛擬地址空間中。vmalloc的分配就是基於這個機制來實現的。
還記得下邊這張圖嗎?
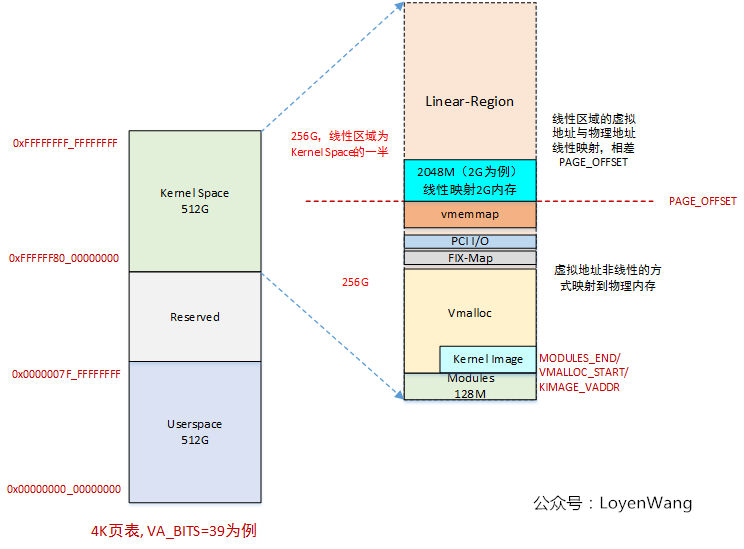
vmap/vmalloc的區域就是在VMALLOC_START ~ VMALLOC_END之間。
開啟探索之旅吧。
2. 數據結構
2.1 vmap_area/vm_struct
這兩個數據結構比較簡單,直接上代碼:
struct vm_struct {
struct vm_struct *next;
void *addr;
unsigned long size;
unsigned long flags;
struct page **pages;
unsigned int nr_pages;
phys_addr_t phys_addr;
const void *caller;
};
struct vmap_area {
unsigned long va_start;
unsigned long va_end;
unsigned long flags;
struct rb_node rb_node; /* address sorted rbtree */
struct list_head list; /* address sorted list */
struct llist_node purge_list; /* "lazy purge" list */
struct vm_struct *vm;
struct rcu_head rcu_head;
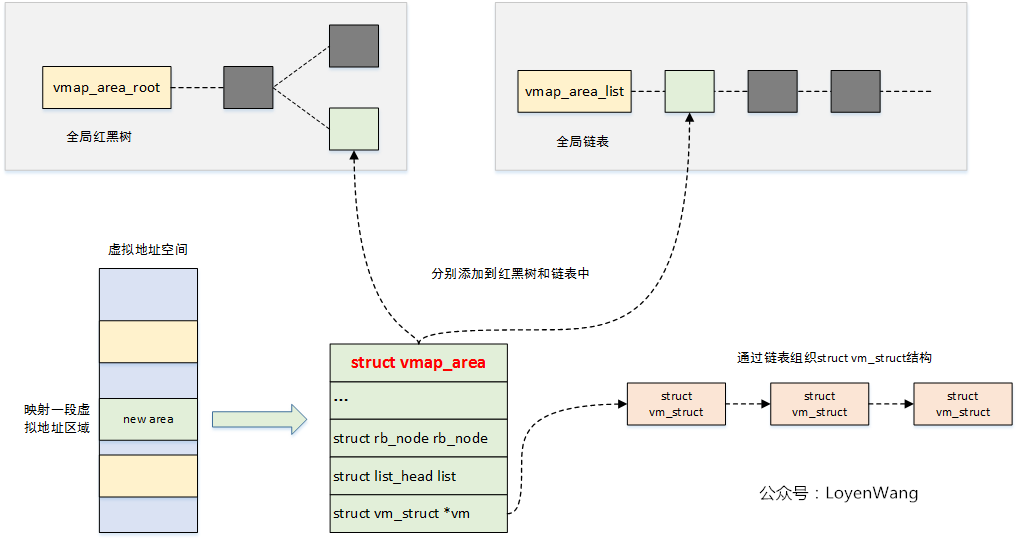
};struct vmap_area用於描述一段虛擬地址的區域,從結構體中va_start/va_end也能看出來。同時該結構體會通過rb_node掛在紅黑樹上,通過list掛在鏈表上。
struct vmap_area中vm欄位是struct vm_struct結構,用於管理虛擬地址和物理頁之間的映射關係,可以將struct vm_struct構成一個鏈表,維護多段映射。
關係如下圖:
2.2 紅黑樹
紅黑樹,本質上是一種二叉查找樹,它在二叉查找樹的基礎上增加了著色相關的性質,提升了紅黑樹在查找,插入,刪除時的效率。在紅黑樹中,節點已經進行排序,對於每個節點,左側的的元素都在節點之前,右側的元素都在節點之後。
紅黑樹必須滿足以下四條規則:
- 每個節點不是紅就是黑;
- 紅黑樹的根必須是黑;
- 紅節點的子節點必須為黑;
- 從節點到子節點的每個路徑都包含相同數量的黑節點,統計黑節點個數時,空指針也算黑節點;
定義如下:
struct rb_node {
unsigned long __rb_parent_color;
struct rb_node *rb_right;
struct rb_node *rb_left;
} __attribute__((aligned(sizeof(long))));
/* The alignment might seem pointless, but allegedly CRIS needs it */
由於內核會頻繁的進行vmap_area的查找,紅黑樹的引入就是為瞭解決當查找數量非常多時效率低下的問題,在紅黑樹中,搜索元素,插入,刪除等操作,都會變得非常高效。至於紅黑樹的演算法操作,本文就不再深入分析,知道它的用途即可。
3. vmap/vunmap分析
3.1 vmap
vmap函數,完成的工作是,在vmalloc虛擬地址空間中找到一個空閑區域,然後將page頁面數組對應的物理記憶體映射到該區域,最終返回映射的虛擬起始地址。
整體流程如下:
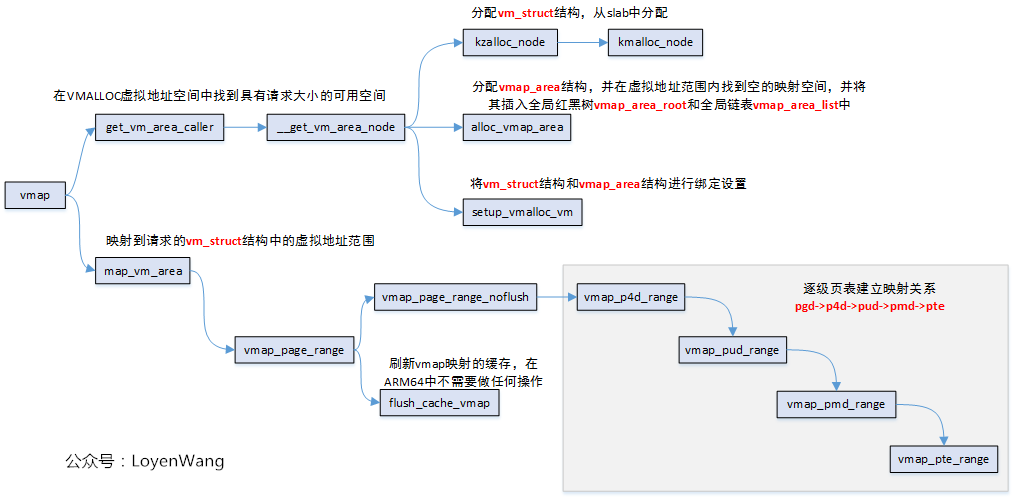
操作流程比較簡單,來一個樣例分析,就清晰明瞭了:

vmap調用中,關鍵函數為alloc_vmap_area,它先通過vmap_area_root二叉樹來查找第一個區域first vm_area,然後根據這個first vm_area去查找vmap_area_list鏈表中滿足大小的空間區域。
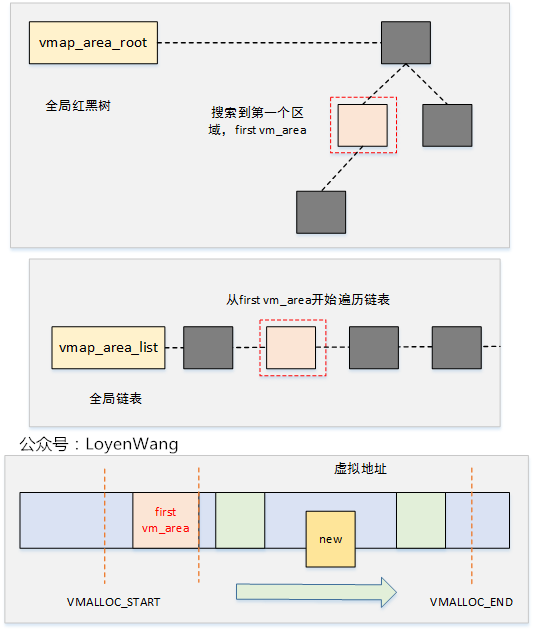
在alloc_vmap_area函數中,有幾個全局的變數:
static struct rb_node *free_vmap_cache;
static unsigned long cached_hole_size;
static unsigned long cached_vstart;
static unsigned long cached_align;用於緩存上一次分配成功的vmap_area,其中cached_hole_size用於記錄緩存vmap_area對應區域之前的空洞的大小。緩存機制當然也是為了提高分配的效率。
3.2 vunmap
vunmap執行的是跟vmap相反的過程:從vmap_area_root/vmap_area_list中查找vmap_area區域,取消頁表映射,再從vmap_area_root/vmap_area_list中刪除掉vmap_area,頁面返還給伙伴系統等。由於映射關係有改動,因此還需要進行TLB的刷新,頻繁的TLB刷新會降低性能,因此將其延遲進行處理,因此稱為lazy tlb。
來看看逆過程的流程:

4. vmalloc/vfree分析
4.1 vmalloc
vmalloc用於分配一個大的連續虛擬地址空間,該空間在物理上不連續的,因此也就不能用作DMA緩衝區。vmalloc分配的線性地址區域,在文章開頭的圖片中也描述了:VMALLOC_START ~ VMALLOC_END。
直接分析調用流程:
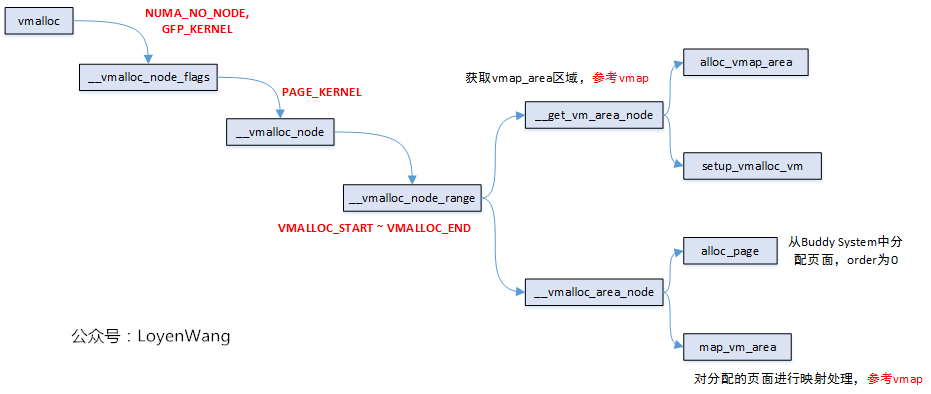
從過程中可以看出,vmalloc和vmap的操作,大部分的邏輯操作是一樣的,比如從VMALLOC_START ~ VMALLOC_END區域之間查找並分配vmap_area, 比如對虛擬地址和物理頁框進行映射關係的建立。不同之處,在於vmap建立映射時,page是函數傳入進來的,而vmalloc是通過調用alloc_page介面向Buddy System申請分配的。
vmalloc VS kmalloc
到現在,我們應該能清楚vmalloc和kmalloc的差異了吧,kmalloc會根據申請的大小來選擇基於slub分配器或者基於Buddy System來申請連續的物理記憶體。而vmalloc則是通過alloc_page申請order = 0的頁面,再映射到連續的虛擬空間中,物理地址不連續,此外vmalloc可以休眠,不應在中斷處理程式中使用。
與vmalloc相比,kmalloc使用ZONE_DMA和ZONE_NORMAL空間,性能更快,缺點是連續物理記憶體空間的分配容易帶來碎片問題,讓碎片的管理變得困難。
4.2 vfree
直接上代碼:
void vfree(const void *addr)
{
BUG_ON(in_nmi());
kmemleak_free(addr);
if (!addr)
return;
if (unlikely(in_interrupt()))
__vfree_deferred(addr);
else
__vunmap(addr, 1);
}如果在中斷上下文中,則推遲釋放,否則直接調用__vunmap,所以它的邏輯基本和vunmap一致,不再贅述了。



