
1. Apache Hadoop 1.1 Hadoop介紹 Hadoop是Apache旗下的一個用java語言實現的開源軟體框架, 是一個開發和運行處理大規模數據的軟體平臺. 允許使用簡單的編程模型在大量電腦集群上對大型數據集進行分散式處理. Hadoop不會跟某種具體的行業或者某個具體的業務掛鉤 ...
1. Apache Hadoop
1.1 Hadoop介紹
Hadoop是Apache旗下的一個用java語言實現的開源軟體框架, 是一個開發和運行處理大規模數據的軟體平臺. 允許使用簡單的編程模型在大量電腦集群上對大型數據集進行分散式處理. Hadoop不會跟某種具體的行業或者某個具體的業務掛鉤, 他只是一種用來做海量數據分析處理的工具.

狹義上說, Hadoop指Apache這款開源框架, 其核心組件有:
HDFS (分散式文件系統) : 解決海量數據存儲
YARN (作業調度和集群資源管理的框架) : 解決資源任務調度
MAPREDUCE (分散式運算編程框架) : 解決海量數據計算
廣義上說, Hadoop通常是指一個更廣泛的概念 -- Hadoop生態圈.
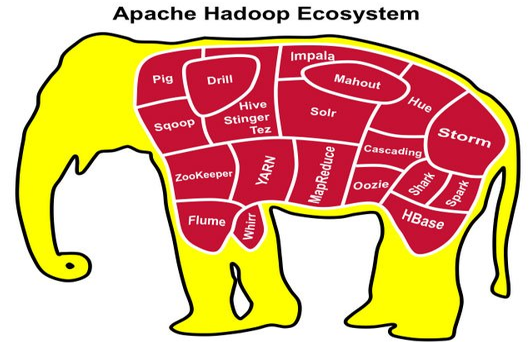
當下的Hadoop已經成長為一個龐大的體系.
HDFS: 分散式文件系統
MAPREDUCE: 分散式運算程式開發框架
HIVE: 基於Hadoop的分散式數據倉庫, 提供基於SQL的查詢數據操作
HBASE: 基於Hadoop的分散式海量數據資料庫
ZOOKEEPER: 分散式協調服務基礎組件
Mahout: 基於MR / Spark / Flink等分散式運算框架的機器學習演算法庫
OOZIE: 工作流調度框架
SQOOP: 數據導入導出工具 (比如用於mysql和HDFS之間)
FLUME: 日誌數據採集框架
IMPALA: 基於Hive的實時sql查詢分析
1.2 Hadoop發展簡史
三篇Google論文:
1) 2003年Google發表的第一篇論文: GFS (Google分散式文件系統)
2) 2004年Google發表的第二篇論文: Google的MapReduce解決海量數據計算
同一時期,Doug Cutting基於Google的兩篇論文開發出: HDFS (Hadoop的分散式文件系統) , MapReduce (基於Hadoop的分散式計算平臺) 成為Apache的頂級項目.
3) 2006年Google發表的第三篇論文: BigTable, 開源界根據論文開發了HBase (基於Hadoop的分散式資料庫) .
1.3 Hadoop特性優點
1) 擴容能力: Hadoop是在可用的電腦集群間分配數據並完成計算任務的, 這些集群可用方便的擴展到數以千計的節點中.
2) 成本低: Hadoop通過廉價的機器組成伺服器集群來分發以及處理數據, 以至於成本很低.
3) 高效率: 通過併發數據,Hadoop可以在節點之間動態並行的移動數據, 使得速度非常快.
4) 可靠性: 能自動維護數據的多份複製, 並且在任務失敗後自動的重新部署計算任務. 所以Hadoop的按位存儲和處理數據的能力值得信賴.
2. Hadoop集群
2.1 發行版本
分為開源社區版和商業版
社區版: 由Apache軟體基金會維護的版本, 是官方維護的版本體系.
優點: 功能最新, 免費.
缺點: 穩定性差, 相容性差.
商業版: 由第三方商業公司在社區版基礎上進行一些修改, 整合以及各個服務組件相容性測試而發行的版本, 比如著名的cloudera的CDH, mapR, hortonWorks等.
優點: 穩定性好, 軟體相容性好.
缺點: 收費, 暫時不能使用最新的Hadoop版本.
Hadoop版本特殊, 是由多條分支並行的發展, 大的來看分為3個大的系列版本: 1.x, 2.x, 3.x.
Hadoop1.x由一個分散式文件系統HDFS和一個離線計算框架MR組成.
Hadoop2.x包含一個支持NameNode橫向擴展的HDFS, 一個資源管理系統YARN和一個運行在YARN上的離線計算框架MR. 相比於Hadoop1.x, Hadoop2.x功能更加強大, 且具有更好的擴展性, 性能, 並支持多種計算框架. 現在是企業主流版本.
Hadoop3.x相比之前的Hadoop2.x有一系列的功能增強. 目前已經趨於穩定, 但是整個生態圈體系升級整合還未完畢, 所以商用還值得商榷.
2.2 集群簡介
Hadoop集群具體來說包含兩個集群: HDFS集群, YARN集群, 兩者邏輯上分離, 但物理上常在一起.
1) HDFS集群負責海量數據的存儲, 集群中的角色主要有: NameNode, DataNode, SecondaryNameNode.
2) YARN集群負責海量數據運算時的資源調度, 集群中的角色主要有: ResourceManager, NodeManager.
其中MR其實是一個分散式運算編程框架, 是應用程式開發包, 由用戶按照編程規範進行程式開發, 後打包運行在HDFS集群上, 並且受到YARN集群的資源調度管理.
Hadoop部署方式分四種: Standalone mode (獨立模式) , Pseudo-Distributed mode (偽分散式模式) , Cluster mode (集群模式) , HA high availability (高可用集群模式) 其中前兩種都是在單機部署.
1) 獨立模式又稱為單機模式, 僅1個機器運行1個Java進程, 主要用於調試.
2) 偽分佈模式也是在1個機器運行HDFS的NameNode和DataNode, YARN的ResourceManager和NodeManager, 但分別啟動單獨的Java進程, 主要用於調試.
3) 集群模式主要用於生產環境部署. 會使用N台主機組成一個集群, 這種部署模式下, 主節點和從節點會分開部署在不同的機器上.
4) 高可用集群模式主要解決單點故障, 保證集群的高可用, 提高可靠性
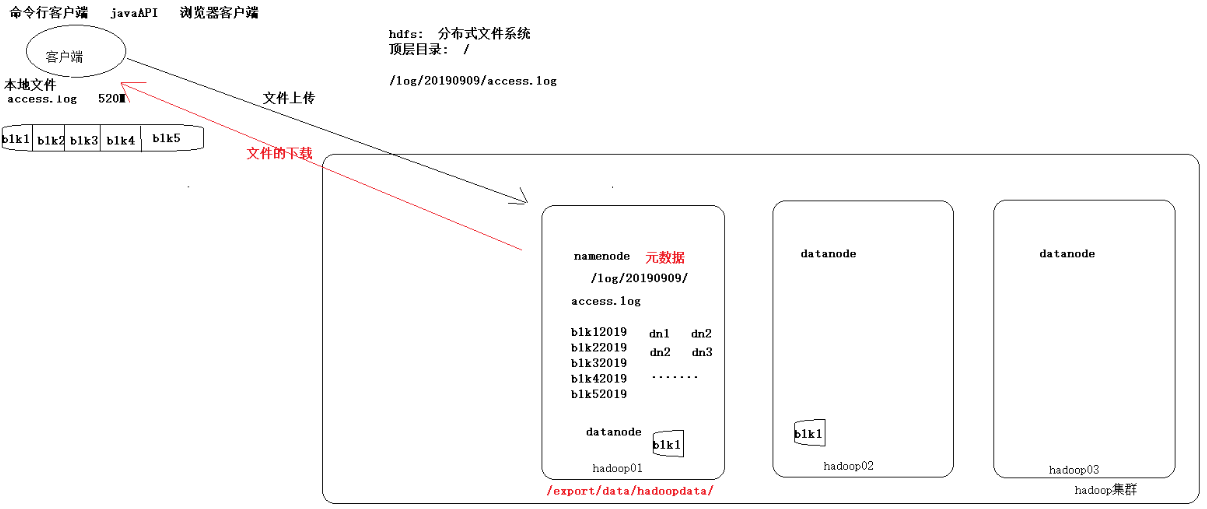
HDFS集群 (主從架構) :
主角色: NameNode (nn)
從角色: DataNode (dn)
主角色的輔助角色: SecondaryNameNode (snn)
YARN集群 (主從架構) :
主角色: ResourceManager (rm)
從角色: NodeManager (nm)
MR需要開發的程式組件:
Map組件
Reduce組件
Hadoop角色分佈圖:

HDFS原理圖簡單分析:
2.3 為什麼CDH版本Hadoop要重新編譯?
由於CDH的所有安裝包版本都給出了對應的軟體版本, 一般情況下是不需要自己進行編譯的, 但是由於CDH給出的Hadoop的安裝包沒有提供帶C程式訪問的藉口, 所有我們在使用本地庫的時候就會出現問題. (本地庫: 可以用來做壓縮, 以及支持C程式等等)
1) Hadoop是使用Java語言開發的, 但是有一些需求和操作並不適合使用java, 所以就引入了本地庫 (Native Libraries) 的概念. 說白了, 就是Hadoop的某些功能, 必須通過JNT來協調Java類文件和Native代碼生成的庫文件一起才能工作.
2) linux系統要運行Native代碼, 首先要將Native編譯成目標CPU架構的 [.so] 文件. 而不同的處理器架構, 需要編譯出相應平臺的動態庫 [.so] 文件, 才能被正確的執行, 所以最好重新編譯一次hadoop源碼, 讓 [.so] 文件與自己處理器相對應. 註意: windows平臺是動態庫 [.dll] 文件
總結: 主要是要重新編譯本地庫 (Native Libraries) 代碼 (Linux下對應 [.so] 文件,window下對應 [.dlI] 文件) , 也就是編譯生成linux下的 [.so] 文件.
源碼編譯後壓縮包路徑:

源碼編譯後結果:
2.4 Hadoop安裝包目錄結構
目錄結構如下:
bin: Hadoop最基本的管理腳本和使用腳本的目錄.
etc: Hadoop配置文件所在的目錄.
include: 對外提供的編程庫頭文件 (具體動態庫和靜態庫在lib目錄中) .
lib: 包含了Hadoop對外提供的編程動態庫和靜態庫, 與include目錄中的頭文件結合使用.
libexec: 各個服務對用的shell配置文件所在的目錄, 可用於配置日誌輸出, 啟動參數等基本信息.
sbin: Hadoop管理腳本所在的目錄, 主要包括HDFS和YARN中各類服務的啟動 / 關閉腳本.
share: Hadoop各個模塊編譯後的jar包所在的目錄, 官方自帶實例.
2.5 集群規劃
集群規劃: 在我們準備的三台伺服器上如何搭建hadoop集群
原則:
1) 優先滿足軟體需要的硬體資源
2) 儘量避免有衝突的軟體不要在一起
3) 有依賴的軟體儘量部署在一起
規劃安排:
hadoop01: NameNode DataNode | ResourceManager NodeManager
hadoop02: DataNode SecondaryNameNode | NodeManager
hadoop03: DataNode | NodeManager
未來擴展:
hadoop04: DataNode NodeManager
hadoop05: DataNode NodeManager
hadoop06: DataNode NodeManager
......
2.6 啟動, Web-UI
要啟動Hadoop集群, 需要啟動HDFS和YARN兩個集群, 首次啟動HDFS時, 必須對其進行格式化操作. 本質上是一些清理和準備工作, 因此此時的HDFS在物理上還是不存在的.
Hadoop集群啟動並允許, 可以通過web-ui進行查看
NameNode: http://nn_host:port/ 預設50070.
ResourceManager: http://rm_host:port/ 預設8088.
2.7 MapReduce JobHistory
JobHistory用來記錄已經finished的MR運行日誌, 日誌信息存放於HDFS目錄中, 預設情況下沒有開啟此功能, 需要在mapred-site.xml中配置並手動啟動.
可以通過web-ui進行查看
http://nn_host:port/ 預設19888.
3. HDFS的垃圾桶機制
3.1 垃圾桶機制解析
每一個文件系統都會有垃圾桶機制, 便於將刪除的數據回收到垃圾桶里, 避免某些誤操作刪除一些重要文件. 回收到垃圾桶里的資料數據, 都可以進行恢復.
3.2 垃圾桶機制配置
HDFS的垃圾回收的預設配置屬性為0, 也就是說, 如果不小心誤刪了, 那麼這個操作是不可恢復的. 修改core-site.xml , 那麼可以按照生產上的需求設置回收站的保存時間, 這個時間以分鐘為單位, 例如1440 = 24h = 1天.
3.3 垃圾桶機制驗證
如果啟用垃圾桶配置, dfs命令刪除的文件不會立即從HDFS中刪除. 相反, HDFS將其移動到垃圾目錄 (每個用戶在 /user/<username>/.Trash 下都有自己的垃圾目錄). 只要文件保留在垃圾箱中, 文件可以快速回覆.
使用skipTrash選項刪除文件, 該選項不會將文件發送到垃圾桶, 它將從HDFS中完全刪除.

