一、Tensor 1.1 什麼是Tensor?Tensor的數據類型 Tensor是張量的意思,在TensorFlow中張量可以是標量(scalar)、向量(vector)、矩陣(matrix)、高維度張量(rank>2),像Numpy里的數組就不屬於Tensor。TensorFlow里的常用的數據 ...
一、Tensor
1.1 什麼是Tensor?Tensor的數據類型
Tensor是張量的意思,在TensorFlow中張量可以是標量(scalar)、向量(vector)、矩陣(matrix)、高維度張量(rank>2),像Numpy里的數組就不屬於Tensor。TensorFlow里的常用的數據類型有tf.int32、tf.float32、tf.double、tf.bool、tf.Variable。下麵展示了用tf.constant創建的一些Tensor:
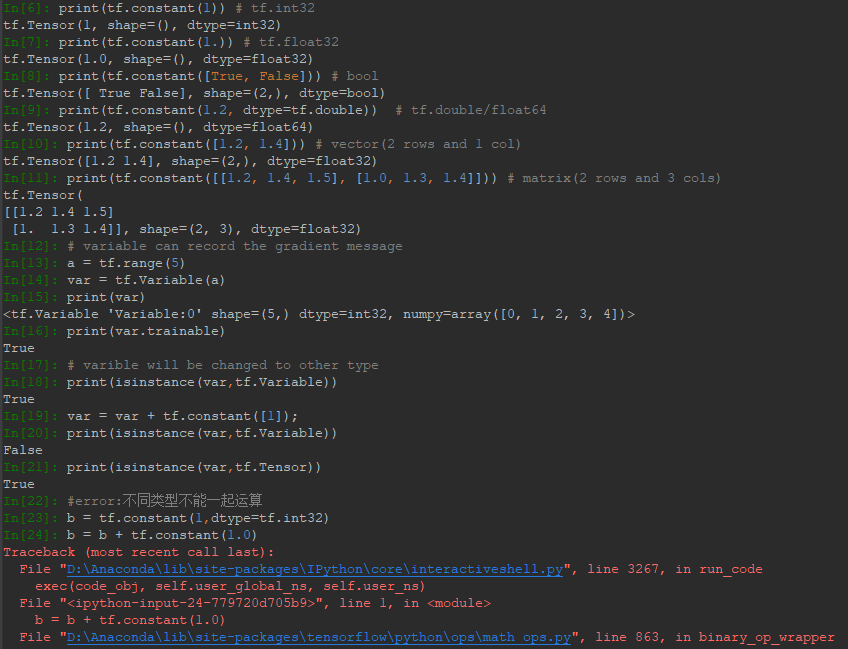
需要特別註意代碼IN[18]-IN[21]行,由於TensorFlow有自動求導功能,而被求導參數類型必須為Variable類型,這樣才可以被記錄下梯度信息。但是Variable類型在於int、float運算過程中,假如被更新了,其類型會自動轉為int、float類型,導致求導出錯。第二個需要註意的是代碼第34-36行,Tensor不同類型數據間不能混合運算(除了Variable),否則會出錯,而在深度學習中,運算通常採用浮點形式,這種錯誤較少出現。為瞭解決Variable更新自動被轉成其他類型,可以採用原地更新,即數據類型不變,如下例所示,使用assign方法可以實現任意賦值而不改變類型:
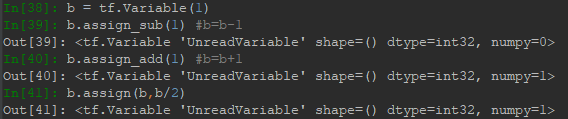
1.2 Tensor的shape
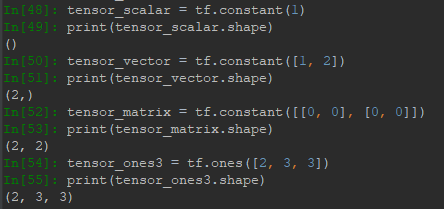
Tensor最常用的屬性就是shape,即維度信息,以下代碼展示了標量、向量、矩陣、高維度張量的shape信息。對於標量,其維度為0,則Python顯示shape為(),對於矩陣,shape第一個元素表示行數,第二個表示列數。:
1.3 Tensor的驗證
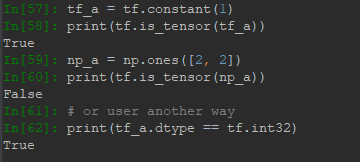
可以用tf.is_tensor()方法判斷是否屬於Tensor類型,也可以用dtype屬性進行判斷,這裡拿Numpy做對比:
1.4 Tensor轉換
在實際編寫中,由於需要導入數據集,所以經常會用到數據轉換方法,將數據集轉為Tensor或Tensor轉為其他形式,如Numpy:
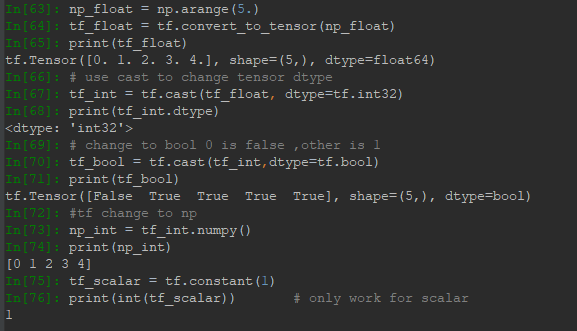
tf.cast可以用來轉換Tensor的數據類型。
1.5 Tensor創建
前面使用過constant以及Variable創建過Tensorm下麵介紹更實用的創建方法。
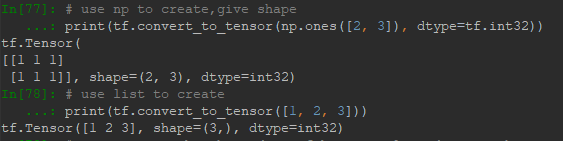
首先是間接創建,即通過Numpy,List創建然後轉化為Tensor:
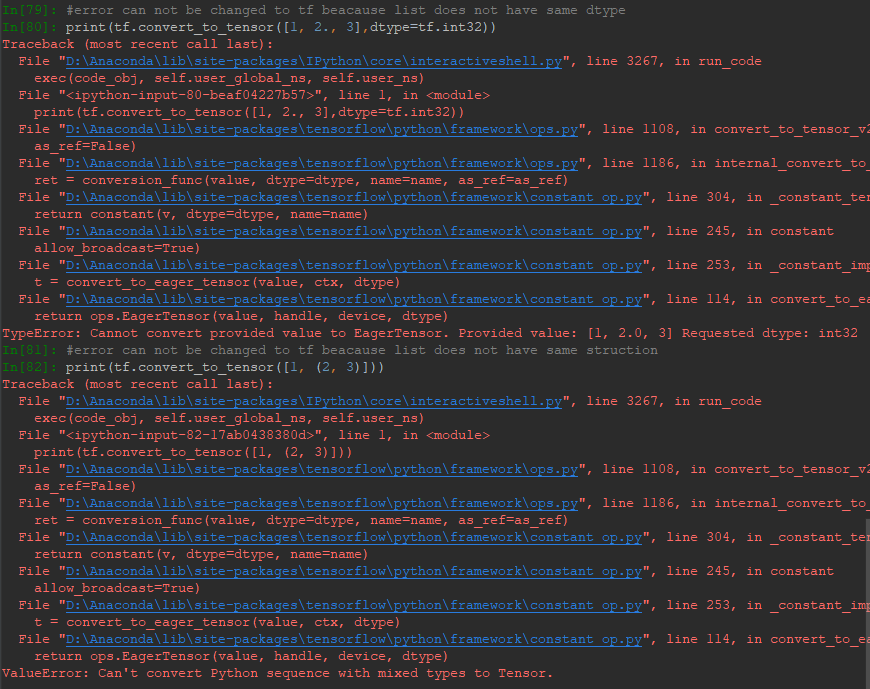
但是需要註意不能轉換的情況,一種是數據類型不統一,第二種是結構不統一,如下:
另外就是直接通過tf的方法直接創建一些矩陣、特殊分佈等數據形式:
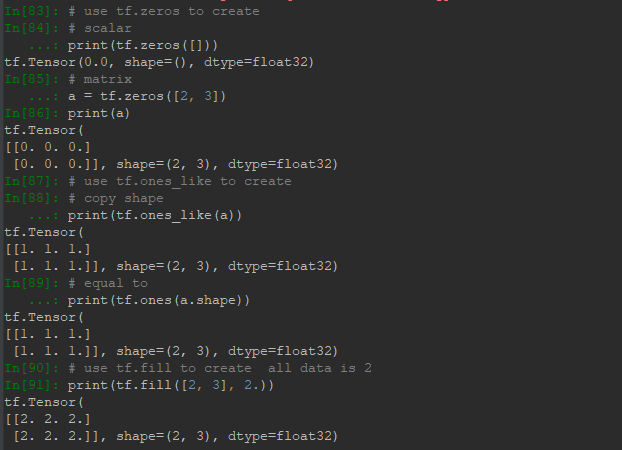
在構建網路權重的時候,常會用到正態分佈或者均勻分佈來初始化,其中截斷型的正態分佈應用更多。
二、索引與切片
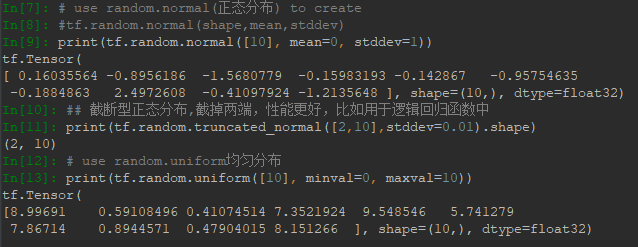
2.1 多維度索引
Tensor索引常採用列表形式,而不是像a[0][1][2]的形式。比如:

可以看到多次索引後,結果變為了標量。 這就如同註冊賬戶時選擇地址一樣。
索引可以是負值,正索引0表示第一個元素,而負索引-1表示最後一個元素。
2.2 使用索引列表進行切片
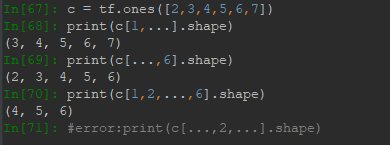
對於索引列表的每個維度索引,都可以用start:end:step獲取切片,其切片範圍為[start,end),註意end是取不到的,step指定了步長,類似於隔幾行採樣一次。索引可以有省略形式,start省略預設為最開始的地方,end省略預設為結束的地方,step省略表示1。如:表示範圍為全部,step=1。::2表示範圍為全部,但step=2。2::表示範圍≥2,step=1。其他情況類似。
· 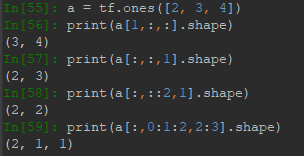
採用負索引進行切片,範圍仍舊是start取得到,end取不到,切片方向仍然是從左向右,因此步長需為正。正索引與負索引可以混合使用:
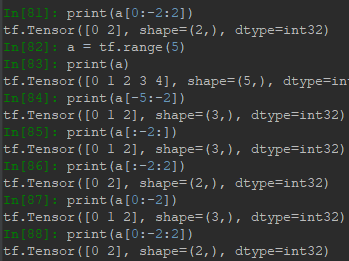
另外,通過切片可以實現逆序功能,即每個維度中的數據都倒過來排列。

當維度較多,不想打冒號,可以用...。前提是切片的範圍是整個,並且,省略號不能同時出現在兩邊,這樣是無法判斷結構的。
2.3 gather抽樣切片
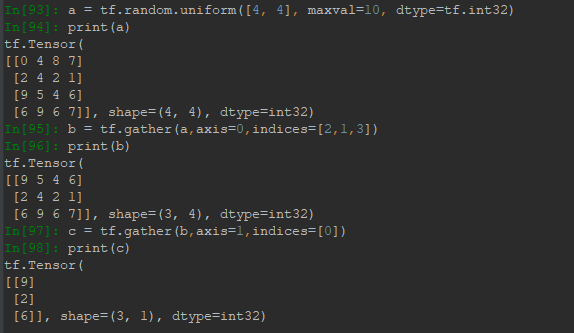
索引列表進行切片還是有很多限制,只能按一定步長等間距取樣,取樣是有序的。而gather可以一次對某個維度(給定axis)進行任意位置任意數量任意順序的取樣(給定indices),這裡的indices不是索引坐標,而是該維度下數據位置索引的有序集合,不能用冒號形式。
2.4 gather_nd抽樣與自定義結構
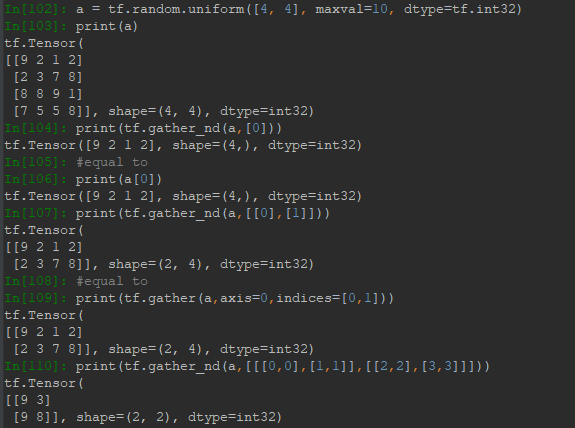
gather_nd參數中給出一個結構,輸出結果會將結構中的索引用數據替代,例如下麵In[104],用a[0]替代了結構[0],所以結果是一個向量;又比如In[107],用a[0]替代[0],用a[1]替代[1]因為結構包裹了一層方括弧,因此,結果是一個矩陣。註意這裡的[0,1]可以理解為索引列表,但是不支持冒號。所以有個問題就是gather與gather_nd在截取比較複雜的數據時,會比較麻煩。
三、維度變換
3.1 reshape分解與合併維度
reshape改變維度,並不會影響數據存儲的順序與內容,只是會丟失維度的信息,改變視圖結構,進行了數據重新的組合。在改變維度的過程中,應該小心,保證更改後總大小不變,例如:

3.2 transpose轉置與維度交換
transpose可以對多維Tensor進行轉置,註意它並不局限於矩陣,其轉置相當於將shape倒過來排列,例如[1,2,3]轉置為[3,2,1]。此外,它還可以進行任意的維度交換,實際上轉置也可以看做維度的交換,例如[1,2,3]現在可以將第二維和第三維交換,結果是[1,3,2]。詳細情況如下,transpose指定perm時,預設功能為倒置。

3.3 expand_dims擴維與squeeze降維
在矩陣計算中經常碰到維度不一致的情況,例如一個3*3的矩陣和一個長度為3的向量做加法,需要將向量在橫向上複製成3*3的矩陣。這裡就可以用expand_dims+tile實現。expand_dims需要制定插入的位置,即制定axis,如果設定的axis非負,則會在axis前面擴展,否則在axis後擴展。例如對shape為(a,b)的Tensor進行擴展,指定axis=0,那麼就在維度a前擴展,擴展後shape為(1,a,b);如果指定axis=-1,那麼就是在維度b的後面進行擴展,擴展後shape為(a,b,1)。到此為止,expand_dims做的事類似於reshape,實際上也可以用reshape來做擴展,效果是一樣的。例如:
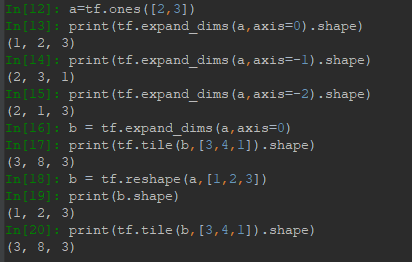
tile的作用在於將對應的維度值以倍數擴展,數據以複製形式進行填充。上例中,1->1*3;2->2*4;3->3*1。
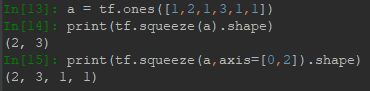
squeeze則用於降維,可以刪去值等於1的維度,例如[1,2,3,1]降維後為[2,3]。squeeze用法如下圖:
3.4 broadcast廣播
前面展示了通過expand+tile的方法進行擴展使不同維度的Tensor變為相同維度進行運算,實際中,像加減乘除一些運算支持隱式Broadcast自動擴展,Broadcast性能比expand來得好,占用記憶體小。正是有這種自動擴展,在Tensorflow里一些不同維度的Tensor可以直接進行運算,如下圖:
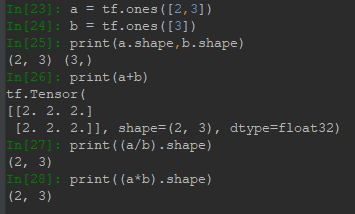
可以看到,一個矩陣與向量作四則運算並未出錯。原因在於運算前,向量自動擴展為(2,3)。但不是任何情況都不會出錯,擴展的過程為,遵循最後一維對齊原則,缺失的維度自動擴展,且值為1,對值為1的維度進行擴展,值不為1的維度不能擴展。對比下列情況:
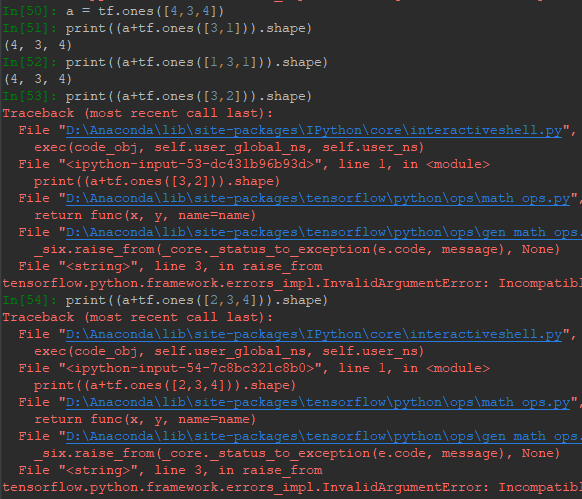
[3,1]可以擴展,根據右對齊原則,[3,1]缺少對應2的維度,自動擴展為(1,3,1)。左1對應於2,可以擴成2。3對應於3,不用擴展。右3對應於4,擴為4。[3,2]根據右對齊原則,2對應於4,兩者不相等且不為1,所以不能擴展。
有些時候可能出現不支持隱式擴展,這時候可以顯式擴展:

四、Tensor運算
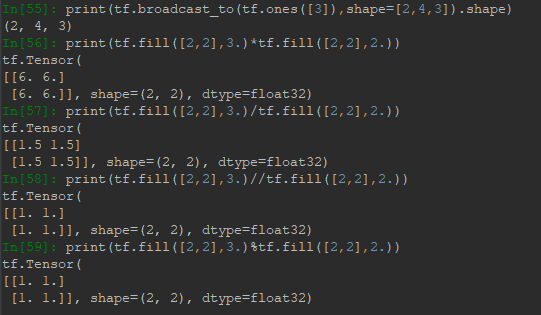
4.1 加減乘除餘
加減乘除餘都是對應位置元素作運算,符號為:+、-、*、/、//、%,示例如下:
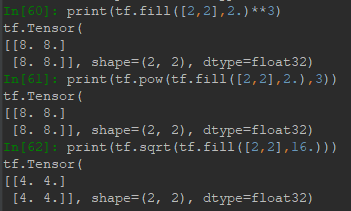
4.2 冪與平方根
Tensor的冪和平方根就是各元素的冪與平方根,符號為:**(pow)、sqrt。示例如下:
4.3 指數與對數
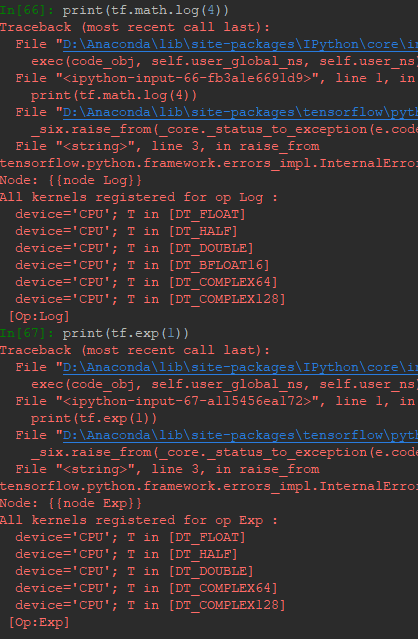
Tensor的指數和對數就是各元素的指數與對數。TensorFlow里只有以e為底的對數,要實現其他對數底,可以利用數學公式轉換底到e:

另外,需要註意的是指數和對數的參數必須為浮點數,用整數會報錯:
4.4 叉乘
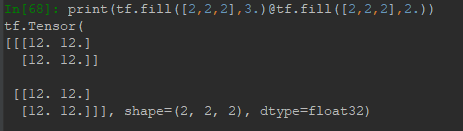
符號為@: