
爬取51Job和獵聘網的信息,想處理字元集問題(51job為gbk,獵聘為utf-8), 找到兩個網站字元集信息都在同一標簽下 就想先把網頁保存成String,解析一遍獲取字元集,然後將網頁轉換成對應的正確的字元集,最後再轉換成統一的字元集utf-8 1.0實現,2次調用Entity.Utils.t ...
爬取51Job和獵聘網的信息,想處理字元集問題(51job為gbk,獵聘為utf-8),
找到兩個網站字元集信息都在同一標簽下
就想先把網頁保存成String,解析一遍獲取字元集,然後將網頁轉換成對應的正確的字元集,最後再轉換成統一的字元集utf-8
1.0實現,2次調用Entity.Utils.toString方法
CloseableHttpResponse httpResponse = httpClient.execute(httpGet); if(httpResponse.getStatusLine().getStatusCode() == 200) { //網站轉為String String get_Charset_Entity2String = EntityUtils.toString(httpResponse.getEntity()); //解析 Document get_Charset_Document = Jsoup.parse(get_Charset_Entity2String); //字元集信息提取,51job和獵聘 String charset = get_Charset_Document.select("meta[http-equiv=Content-Type]") .attr("content").split("=")[1]; System.out.println(charset); //根據字元集重新編碼成正確的 String Ori_Entity = EntityUtils.toString(httpResponse.getEntity(),charset); //轉換為統一的utf-8 String entity = new String(Ori_Entity.getBytes(),"utf-8"); System.out.println(entity);
{
報錯
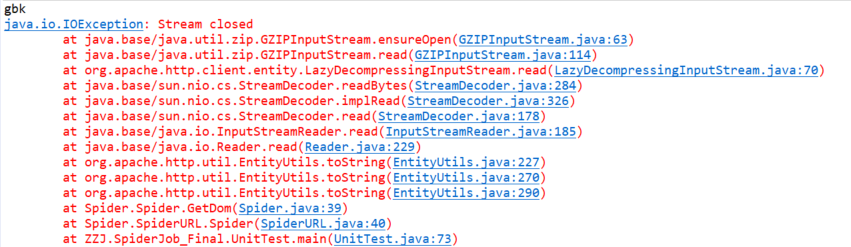
參考 https://blog.csdn.net/qq_23145857/article/details/70213277
發現EntityUtils流只存在一次,但是有不想一個網頁要連接兩次,
這難不倒我,直接轉換原來保留的String
2.0實現,第二次不使用EntityUtils
CloseableHttpResponse httpResponse = httpClient.execute(httpGet); if(httpResponse.getStatusLine().getStatusCode() == 200) { //網站轉為String String get_Charset_Entity2String = EntityUtils.toString(httpResponse.getEntity()); //解析 Document get_Charset_Document = Jsoup.parse(get_Charset_Entity2String); //字元集信息提取,51job和獵聘 String charset = get_Charset_Document.select("meta[http-equiv=Content-Type]") .attr("content").split("=")[1]; System.out.println(charset); //根據字元集重新編碼成正確的,不用EntityUtils,直接轉get_Charset_Entity2String String Ori_Entity = new String(get_Charset_Entity2String.getBytes(), charset); //轉換為統一的utf-8 String entity = new String(Ori_Entity.getBytes(),"utf-8"); System.out.println(entity);
{
輸出:

字元集依舊有問題,發現不指定字元集,EntityUtils.toString()就用"ISO-8859-1"字元集,可我就是不知道字元集
看到參考鏈接下麵的解決辦法,眼前一亮,把流直接以位數組保存,都能靈活變換
3.0實現,不使用EntityUtils.toString,改用EntityUtils.toByteArray()
CloseableHttpResponse httpResponse = httpClient.execute(httpGet); if(httpResponse.getStatusLine().getStatusCode() == 200) {
//網站轉換為byte[] byte[] bytes = EntityUtils.toByteArray(httpResponse.getEntity()); //byte列表轉為預設字元集 String get_Charset_Entity2String = new String(bytes); //解析 Document get_Charset_Document = Jsoup.parse(get_Charset_Entity2String); //字元集信息提取,51job和獵聘 String charset = get_Charset_Document.select("meta[http-equiv=Content-Type]") .attr("content").split("=")[1]; System.out.println(charset); //根據字元集重新編碼成正確的 String Ori_Entity = new String(bytes, charset); //轉換為統一的utf-8 String entity = new String(Ori_Entity.getBytes(), "utf-8"); System.out.println(entity);
}
對於裡面的預設字元集
參考:https://blog.csdn.net/wangxin1949/article/details/78974037
- 1、如果使用了eclipse,由java文件的編碼決定
- 2、如果沒有使用eclipse,則有本地電腦語言環境決定,中國的都是預設GBK編碼,
輸出正常

換成獵聘的url再嘗試

完美,爬蟲的字元集真神奇


