
一、何為“記憶體模型” 記憶體模型描述了程式中各個變數(實例域、靜態域和數組元素)之間的關係,以及在實際電腦系統中將變數存儲到記憶體和從記憶體中取出變數這樣的底層細節,對象最終是存儲在記憶體裡面的,但是編譯器、運行庫、處理器或者系統緩存可以有特權在變數指定記憶體位置存儲或者取出變數的值。 二、JMM(Java ...
一、何為“記憶體模型”
記憶體模型描述了程式中各個變數(實例域、靜態域和數組元素)之間的關係,以及在實際電腦系統中將變數存儲到記憶體和從記憶體中取出變數這樣的底層細節,對象最終是存儲在記憶體裡面的,但是編譯器、運行庫、處理器或者系統緩存可以有特權在變數指定記憶體位置存儲或者取出變數的值。
二、JMM(Java Memory Model)即Java記憶體模型的作用
- JMM的最初目的是為了能夠支持多線程程式。JMM使得每一個線程就像運行在不同的機器、不同的CPU或者本身就不同的線程上一樣;
- JMM定義了Java語言針對記憶體的一系列相關規則。對於CPU本身而言,一個CPU不能直接訪問其它CPU的寄存器,因此JMM必須通過某種定義規則來使得線程和線程在工作記憶體中進行相互調用,從而實現一個CPU對其它CPU、或者說一個線程對其它線程的記憶體中資源的訪問;
- 雖然JMM設計之初是為了能夠更好地支持多線程,但是JMM的應用和實現並不局限於多處理器,對於單CPU的系統而言,在JVM編譯器編譯Java程式的時候,以及運行時執行該程式的時候,這種規則也是有效的;
- JMM定義了線程與主存之間的抽象關係:每個線程可以被抽象為一塊工作記憶體,程式中所有的共用變數都在主存中定義並存儲,工作記憶體不能直接使用主存中的共用變數,如果要使用,工作記憶體必須對主存中的共用變數進行讀取和拷貝,然後對拷貝過來的變數副本進行操作,最後將操作後的變數結果回寫到主存中。大多數JMM規則在實現的時候,必須保證主存和工作記憶體之間進行通信,而且不能違反記憶體模型本身的結構。這是在設計語言的時候必須考慮到的針對記憶體的一種設計方法。
作為Java程式員,我們需要知道的是,Java對記憶體的管理不需要人為操作,因為Java本身就擁有了一套自動的記憶體管理策略,這是Java相對與其它一些語言在進行記憶體管理上具備的一種優勢。
三、線程間通信機制
在命令式編程中,線程之間的通信機制有兩種:共用記憶體和消息傳遞。
- 共用記憶體。線程之間共用程式的公共狀態,線程之間通過寫-讀記憶體中的公共狀態來隱式進行通信;
- 消息傳遞。線程之間沒有公共狀態,線程之間必須通過明確的發送消息來顯式進行通信。
Java在實現線程間通信時採用的是共用記憶體的方式,因而Java線程之間的通信總是隱式的,整個通信過程對程式員完全透明。如果我們在編寫多線程程式的時候不理解這種隱式的通信機制,很可能會遇到各種奇怪的併發問題。
四、主存與工作記憶體
上面我們將每個單獨的線程抽象為一塊工作記憶體,主存與線程之間的關係也就被抽象成了主存與工作記憶體的關係,這種關係用圖可表示為:
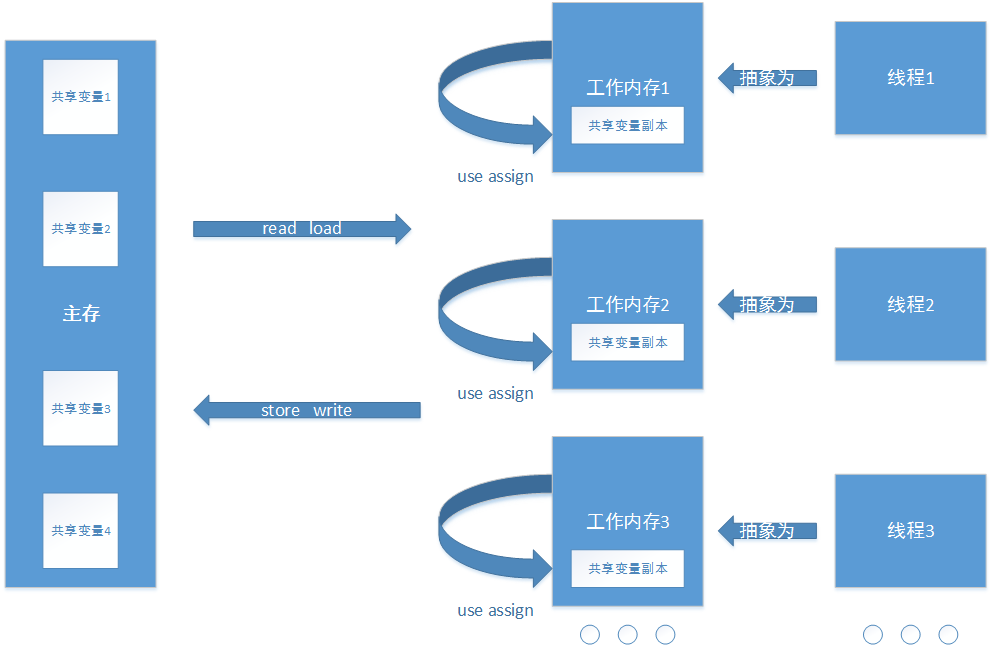
JMM定義了8中主存與工作記憶體之間的操作:
- lock(鎖定):作用於主記憶體的變數,把一個變數標識為一條線程獨占狀態;
- unlock(解鎖):作用於主記憶體變數,把一個處於鎖定狀態的變數釋放出來,釋放後的變數才可以被其他線程鎖定;
- read(讀取):作用於主記憶體變數,把一個變數值從主記憶體傳輸到線程的工作記憶體中,以便隨後的load動作使用;
- load(載入):作用於工作記憶體的變數,它把read操作從主記憶體中得到的變數值放入工作記憶體的變數副本中;
- use(使用):作用於工作記憶體的變數,把工作記憶體中的一個變數值傳遞給執行引擎,每當虛擬機遇到一個需要使用變數的值的位元組碼指令時將會執行這個操作;
- assign(賦值):作用於工作記憶體的變數,它把一個從執行引擎接收到的值賦值給工作記憶體的變數,每當虛擬機遇到一個給變數賦值的位元組碼指令時執行這個操作;
- store(存儲):作用於工作記憶體的變數,把工作記憶體中的一個變數的值傳送到主記憶體中,以便隨後的write的操作;
- write(寫入):作用於主記憶體的變數,它把store操作從工作記憶體中一個變數的值傳送到主記憶體的變數中。
Java記憶體模型只要求上述操作必須按順序執行,而沒有保證必須是連續執行。也就是read和load之間,store和write之間是可以插入其他指令的,如對主記憶體中的變數a、b進行訪問時,可能的順序是read a,read b,load b, load a。
JMM還規定了在執行上述八種基本操作時,必須滿足如下規則:
- 不允許read和load、store和write操作之一單獨出現;
- 不允許一個線程丟棄它的最近assign的操作,即變數在工作記憶體中改變了之後必須同步到主記憶體中;
- 不允許一個線程無原因地(沒有發生過任何assign操作)把數據從工作記憶體同步回主記憶體中;
- 一個新的變數只能在主記憶體中誕生,不允許在工作記憶體中直接使用一個未被初始化(load或assign)的變數。即就是對一個變數實施use和store操作之前,必須先執行過了assign和load操作;
- 一個變數在同一時刻只允許一條線程對其進行lock操作,lock和unlock必須成對出現;
- 如果對一個變數執行lock操作,將會清空工作記憶體中此變數的值,在執行引擎使用這個變數前需要重新執行load或assign操作初始化變數的值;
- 如果一個變數事先沒有被lock操作鎖定,則不允許對它執行unlock操作;也不允許去unlock一個被其他線程鎖定的變數;
- 對一個變數執行unlock操作之前,必須先把此變數同步到主記憶體中(執行store和write操作)。
五、關於重排序
在Java程式的執行過程中,編譯器和處理器會通過對指令進行重排序來優化程式的執行效率。重排序分為三種:
1.編譯器優化的重排序。編譯器在不改變單線程程式語義的前提下,可以重新安排語句的執行順序;
2.指令級並行的重排序。現代處理器採用了指令級並行技術(Instruction-Level Parallelism, ILP)來將多條指令重疊執行。如果不存在數據依賴性,處理器可以改變語句對應機器指令的執行順序;
3.記憶體系統的重排序。由於處理器使用緩存和讀/寫緩衝區,這使得載入和存儲操作看上去可能是在亂序執行。
從java源代碼到最終實際執行的指令序列,會分別經歷上面三種重排序。


