
2019年11月08日 數磚的 Xingbo Jiang 大佬給社區發了一封郵件,宣佈 Apache Spark 3.0 預覽版正式發佈,這個版本主要是為了對即將發佈的 Apache Spark 3.0 版本進行大規模社區測試。無論是從 API 還是從功能上來說,這個預覽版都不是一個穩定的版本,它的 ...
2019年11月08日 數磚的 Xingbo Jiang 大佬給社區發了一封郵件,宣佈 Apache Spark 3.0 預覽版正式發佈,這個版本主要是為了對即將發佈的 Apache Spark 3.0 版本進行大規模社區測試。無論是從 API 還是從功能上來說,這個預覽版都不是一個穩定的版本,它的主要目的是為了讓社區提前嘗試 Apache Spark 3.0 的新特性。如果大家想測試這個版本,可以到 這裡 下載。
Apache Spark 3.0 增加了很多令人興奮的新特性,包括動態分區修剪(Dynamic Partition Pruning)、自適應查詢執行(Adaptive Query Execution)、加速器感知調度(Accelerator-aware Scheduling)、支持 Catalog 的數據源API(Data Source API with Catalog Supports)、SparkR 中的向量化(Vectorization in SparkR)、支持 Hadoop 3/JDK 11/Scala 2.12 等等。Spark 3.0.0-preview 中主要特性和變化的完整列表請參閱這裡。下麵我將帶領大家解析一些比較重要的新特性。
PS:仔細觀察的同學可以看出,Spark 3.0 好像沒多少 Streaming/Structed Streaming 相關的 ISSUE,這可能有幾個原因:
- 目前基於 Batch 模式的 Spark Streaming/Structed Streaming 能夠滿足企業大部分的需求,真正需要非常實時計算的應用還是很少的,所以 Continuous Processing 模塊還處於試驗階段,還不急著畢業;
- 數磚應該在大量投人開發 Delta Lake 相關的東西,這個能夠企業帶來收入,目前這個才是他們的重點,所以自然開發 Streaming 的投入少了。 好了,廢話不扯了,我們來看看 Spark 3.0 的新特性吧。
動態分區修剪(Dynamic Partition Pruning)
所謂的動態分區裁剪就是基於運行時(run time)推斷出來的信息來進一步進行分區裁剪。舉個例子,我們有如下的查詢:
SELECT * FROM dim_iteblog
JOIN fact_iteblog
ON (dim_iteblog.partcol = fact_iteblog.partcol)
WHERE dim_iteblog.othercol > 10
假設 dim_iteblog 表的 dim_iteblog.othercol > 10 過濾出來的數據比較少,但是由於之前版本的 Spark 無法進行動態計算代價,所以可能會導致 fact_iteblog 表掃描出大量無效的數據。有了動態分區裁減,可以在運行的時候過濾掉 fact_iteblog 表無用的數據。經過這個優化,查詢掃描的數據大大減少,性能提升了 33 倍。
這個特性對應的 ISSUE 可以參見 SPARK-11150 和 SPARK-28888。過往記憶大數據公眾號也在前幾天對這個特性進行了詳細介紹,具體請參見 Apache Spark 3.0 動態分區裁剪(Dynamic Partition Pruning)介紹 和 Apache Spark 3.0 動態分區裁剪(Dynamic Partition Pruning)使用。
自適應查詢執行(Adaptive Query Execution)
自適應查詢執行(又稱 Adaptive Query Optimisation 或者 Adaptive Optimisation)是對查詢執行計劃的優化,允許 Spark Planner 在運行時執行可選的執行計劃,這些計劃將基於運行時統計數據進行優化。
早在2015年,Spark 社區就提出了自適應執行的基本想法,在 Spark 的 DAGScheduler 中增加了提交單個 map stage 的介面,並且在實現運行時調整 shuffle partition 數量上做了嘗試。但目前該實現有一定的局限性,在某些場景下會引入更多的 shuffle,即更多的 stage,對於三表在同一個 stage 中做 join 等情況也無法很好的處理;而且使用當前框架很難靈活地在自適應執行中實現其他功能,例如更改執行計劃或在運行時處理傾斜的 join。所以該功能一直處於實驗階段,配置參數也沒有在官方文檔中提及。這個想法主要來自英特爾以及百度的大牛,具體參見 SPARK-9850,對應的文章可以參見 Apache Spark SQL自適應執行實踐。
而 Apache Spark 3.0 的 Adaptive Query Execution 是基於 SPARK-9850 的思想而實現的,具體參見 SPARK-23128。SPARK-23128 的目標是實現一個靈活的框架以在 Spark SQL 中執行自適應執行,並支持在運行時更改 reducer 的數量。新的實現解決了前面討論的所有限制,其他功能(如更改 join 策略和處理傾斜 join)將作為單獨的功能實現,並作為插件在後面版本提供。
加速器感知調度(Accelerator-aware Scheduling)
如今大數據和機器學習已經有了很大的結合,在機器學習裡面,因為計算迭代的時間可能會很長,開發人員一般會選擇使用 GPU、FPGA 或 TPU 來加速計算。在 Apache Hadoop 3.1 版本裡面已經開始內置原生支持 GPU 和 FPGA 了。作為通用計算引擎的 Spark 肯定也不甘落後,來自 Databricks、NVIDIA、Google 以及阿裡巴巴的工程師們正在為 Apache Spark 添加原生的 GPU 調度支持,該方案填補了 Spark 在 GPU 資源的任務調度方面的空白,有機地融合了大數據處理和 AI 應用,擴展了 Spark 在深度學習、信號處理和各大數據應用的應用場景。這項工作的 issue 可以在 SPARK-24615 裡面查看,相關的 SPIP(Spark Project Improvement Proposals) 文檔可以參見 SPIP: Accelerator-aware scheduling
Apache Spark 3.0 將內置支持 GPU 調度
 目前 Apache Spark 支持的資源管理器 YARN 和 Kubernetes 已經支持了 GPU。為了讓 Spark 也支持 GPUs,在技術層面上需要做出兩個主要改變:
目前 Apache Spark 支持的資源管理器 YARN 和 Kubernetes 已經支持了 GPU。為了讓 Spark 也支持 GPUs,在技術層面上需要做出兩個主要改變:
在 cluster manager 層面上,需要升級 cluster managers 來支持 GPU。並且給用戶提供相關 API,使得用戶可以控制 GPU 資源的使用和分配。 在 Spark 內部,需要在 scheduler 層面做出修改,使得 scheduler 可以在用戶 task 請求中識別 GPU 的需求,然後根據 executor 上的 GPU 供給來完成分配。 因為讓 Apache Spark 支持 GPU 是一個比較大的特性,所以項目分為了幾個階段。在 Apache Spark 3.0 版本,將支持在 standalone、 YARN 以及 Kubernetes 資源管理器下支持 GPU,並且對現有正常的作業基本沒影響。對於 TPU 的支持、Mesos 資源管理器中 GPU 的支持、以及 Windows 平臺的 GPU 支持將不是這個版本的目標。而且對於一張 GPU 卡內的細粒度調度也不會在這個版本支持;Apache Spark 3.0 版本將把一張 GPU 卡和其記憶體作為不可分割的單元。詳情請參見 過往記憶大數據公眾號的《Apache Spark 3.0 將內置支持 GPU 調度》文章。
Apache Spark DataSource V2
Data Source API 定義如何從存儲系統進行讀寫的相關 API 介面,比如 Hadoop 的 InputFormat/OutputFormat,Hive 的 Serde 等。這些 API 非常適合用戶在 Spark 中使用 RDD 編程的時候使用。使用這些 API 進行編程雖然能夠解決我們的問題,但是對用戶來說使用成本還是挺高的,而且 Spark 也不能對其進行優化。為瞭解決這些問題,Spark 1.3 版本開始引入了 Data Source API V1,通過這個 API 我們可以很方便的讀取各種來源的數據,而且 Spark 使用 SQL 組件的一些優化引擎對數據源的讀取進行優化,比如列裁剪、過濾下推等等。
Data Source API V1 為我們抽象了一系列的介面,使用這些介面可以實現大部分的場景。但是隨著使用的用戶增多,逐漸顯現出一些問題:
- 部分介面依賴 SQLContext 和 DataFrame
- 擴展能力有限,難以下推其他運算元
- 缺乏對列式存儲讀取的支持
- 缺乏分區和排序信息
- 寫操作不支持事務
- 不支持流處理
為瞭解決 Data Source V1 的一些問題,從 Apache Spark 2.3.0 版本開始,社區引入了 Data Source API V2,在保留原有的功能之外,還解決了 Data Source API V1 存在的一些問題,比如不再依賴上層 API,擴展能力增強。Data Source API V2 對應的 ISSUE 可以參見 SPARK-15689。雖然這個功能在 Apache Spark 2.x 版本就出現了,但是不是很穩定,所以社區對 Spark DataSource API V2 的穩定性工作以及新功能分別開了兩個 ISSUE:SPARK-25186 以及 SPARK-22386。Spark DataSource API V2 最終穩定版以及新功能將會隨著年底和 Apache Spark 3.0.0 版本一起發佈,其也算是 Apache Spark 3.0.0 版本的一大新功能。
更多關於 Apache Spark DataSource V2 的詳細介紹請參見過往記憶大數據公眾號的 Apache Spark DataSource V2 介紹及入門編程指南(上) 和 Apache Spark DataSource V2 介紹及入門編程指南(下) 兩篇文章的介紹。
更好的 ANSI SQL 相容
PostgreSQL 是最先進的開源資料庫之一,其支持 SQL:2011 的大部分主要特性,完全符合 SQL:2011 要求的 179 個功能中,PostgreSQL 至少符合 160 個。Spark 社區目前專門開了一個 ISSUE SPARK-27764 來解決 Spark SQL 和 PostgreSQL 之間的差異,包括功能特性補齊、Bug 修改等。功能補齊包括了支持 ANSI SQL 的一些函數、區分 SQL 保留關鍵字以及內置函數等。這個 ISSUE 下麵對應了 231 個子 ISSUE,如果這部分的 ISSUE 都解決了,那麼 Spark SQL 和 PostgreSQL 或者 ANSI SQL:2011 之間的差異更小了。
SparkR 向量化讀寫
Spark 是從 1.4 版本開始支持 R 語言的,但是那時候 Spark 和 R 進行交互的架構圖如下:
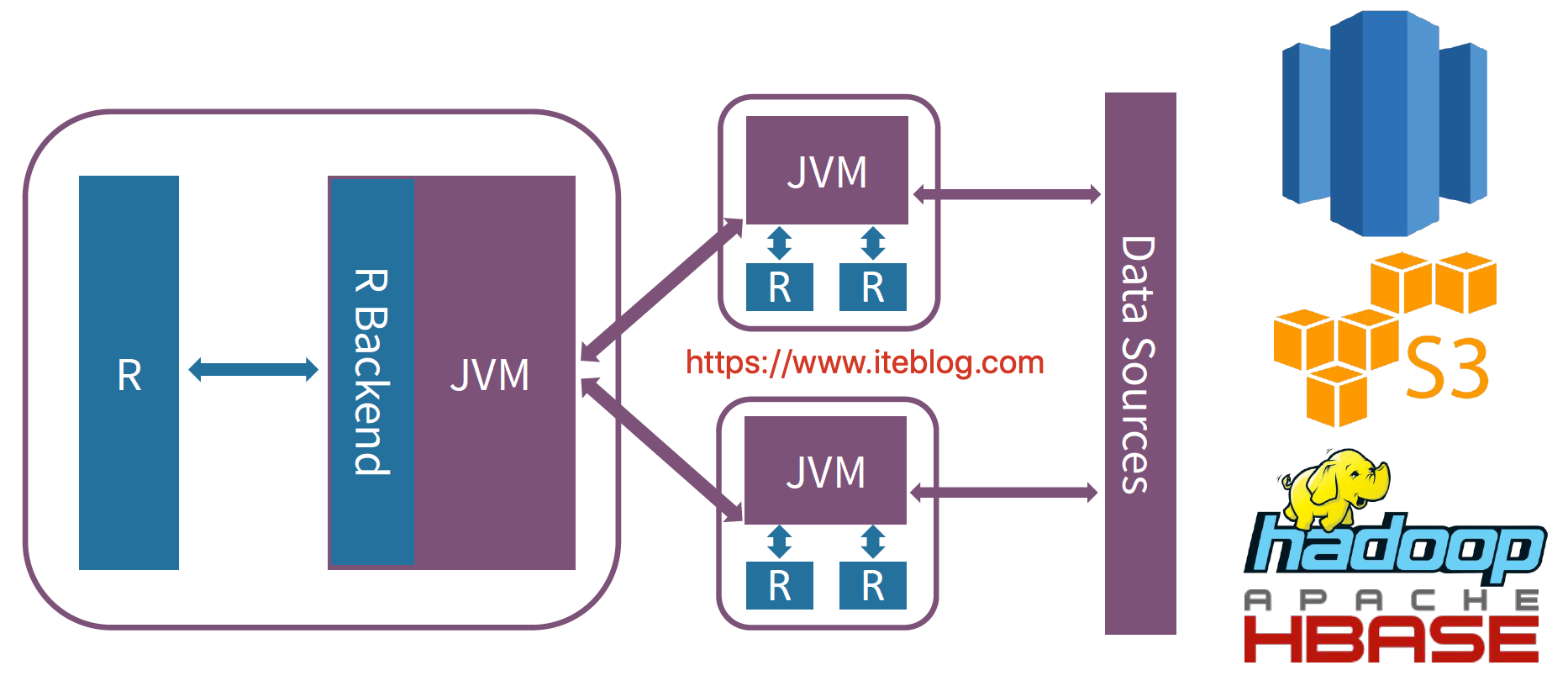 每當我們使用 R 語言和 Spark 集群進行交互,需要經過 JVM ,這也就無法避免數據的序列化和反序列化操作,這在數據量很大的情況下性能是十分低下的!
每當我們使用 R 語言和 Spark 集群進行交互,需要經過 JVM ,這也就無法避免數據的序列化和反序列化操作,這在數據量很大的情況下性能是十分低下的!
而且 Apache Spark 已經在許多操作中進行了向量化優化(vectorization optimization),例如,內部列式格式(columnar format)、Parquet/ORC 向量化讀取、Pandas UDFs 等。向量化可以大大提高性能。SparkR 向量化允許用戶按原樣使用現有代碼,但是當他們執行 R 本地函數或將 Spark DataFrame 與 R DataFrame 互相轉換時,可以將性能提高大約數千倍。這項工作可以看下 SPARK-26759。新的架構如下: 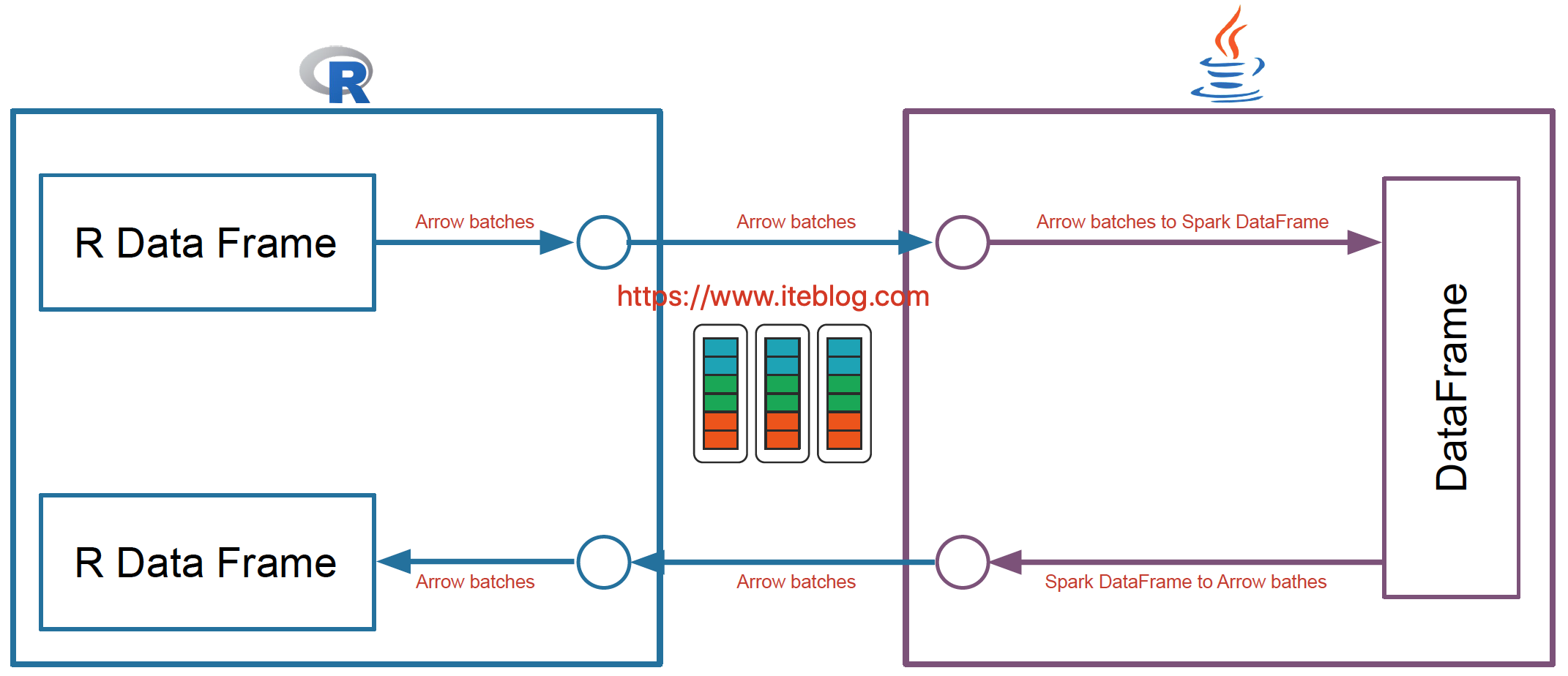 可以看出,SparkR 向量化是利用 Apache Arrow,其使得系統之間數據的交互變得很高效,而且避免了數據的序列化和反序列化的消耗,所以採用了這個之後,SparkR 和 Spark 交互的性能得到極大提升。
可以看出,SparkR 向量化是利用 Apache Arrow,其使得系統之間數據的交互變得很高效,而且避免了數據的序列化和反序列化的消耗,所以採用了這個之後,SparkR 和 Spark 交互的性能得到極大提升。

