
前言:之前有寫過一篇關於LRU的文章鏈接https://www.cnblogs.com/wyq178/p/9976815.html LRU全稱:Least Recently Used:最近最少使用策略,判斷最近被使用的時間,距離目前最遠的數據優先被淘汰,作為一種根據訪問時間來更改鏈表順序從而實現緩存 ...
前言:之前有寫過一篇關於LRU的文章鏈接https://www.cnblogs.com/wyq178/p/9976815.html LRU全稱:Least Recently Used:最近最少使用策略,判斷最近被使用的時間,距離目前最遠的數據優先被淘汰,作為一種根據訪問時間來更改鏈表順序從而實現緩存淘汰的演算法,它是redis採用的淘汰演算法之一。redis還有一個緩存策略叫做LFU, 那麼LFU是什麼呢?我們本期博客來分下一下LFU:
本篇博客的目錄:
一: LRU是什麼
二:LRU的實現
三:測試
五:總結
正文
一:LRU是什麼
LFU,全稱是:Least Frequently Used,最不經常使用策略,在一段時間內,數據被使用頻次最少的,優先被淘汰。最少使用(LFU)是一種用於管理電腦記憶體的緩存演算法。主要是記錄和追蹤記憶體塊的使用次數,當緩存已滿並且需要更多空間時,系統將以最低記憶體塊使用頻率清除記憶體.採用LFU演算法的最簡單方法是為每個載入到緩存的塊分配一個計數器。每次引用該塊時,計數器將增加一。當緩存達到容量並有一個新的記憶體塊等待插入時,系統將搜索計數器最低的塊並將其從緩存中刪除(本段摘自維基百科)

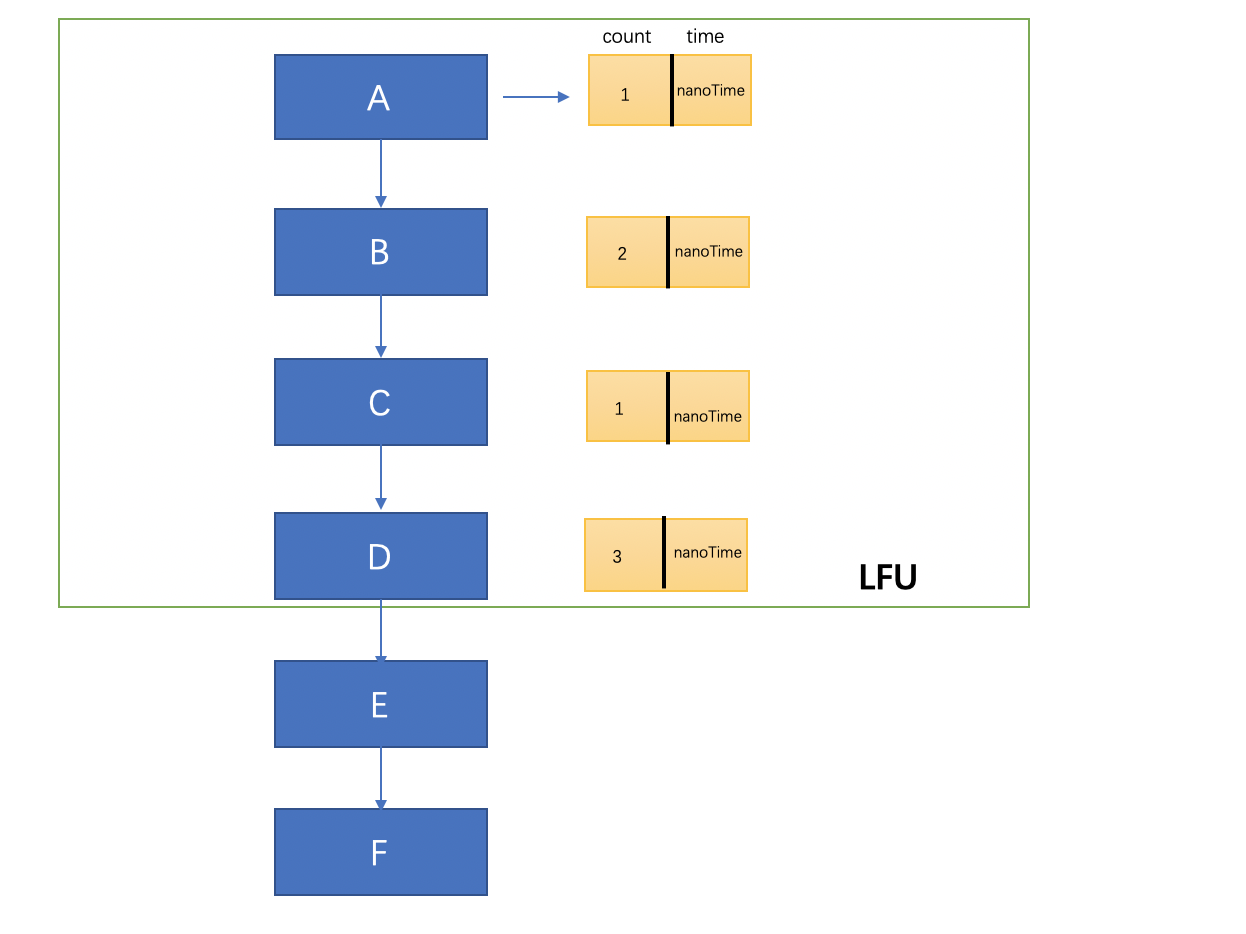
解釋:上面這個圖就是一個LRU的簡單實現思路,在鏈表的開始插入元素,然後每插入一次計數一次,接著按照次數重新排序鏈表,如果次數相同的話,按照插入時間排序,然後從鏈表尾部選擇淘汰的數據~
二:LRU實現
2.1 定義Node節點
Node主要包含了key和value,因為LFU的主要實現思想是比較訪問的次數,如果在次數相同的情況下需要比較節點的時間,越早放入的越快 被淘汰,因此我們需要在Node節點上加入time和count的屬性,分別用來記錄節點的訪問的時間和訪問次數。其他的版本實現方式里有新加個內部類來記錄 key的count和time,但是我覺得不夠方便,還得單獨維護一個map,成本有點大。還有一點註意的是這裡實現了comparable介面,覆寫了compare方法,這裡 的主要作用就是在排序的時候需要用到,在compare方法裡面我們首先比較節點的訪問次數,在訪問次數相同的情況下比較節點的訪問時間,這裡是為了 在排序方法裡面通過比較key來選擇淘汰的key
/** * 節點 */ public static class Node implements Comparable<Node>{ //鍵 Object key; //值 Object value; /** * 訪問時間 */ long time; /** * 訪問次數 */ int count; public Node(Object key, Object value, long time, int count) { this.key = key; this.value = value; this.time = time; this.count = count; } public Object getKey() { return key; } public void setKey(Object key) { this.key = key; } public Object getValue() { return value; } public void setValue(Object value) { this.value = value; } public long getTime() { return time; } public void setTime(long time) { this.time = time; } public int getCount() { return count; } public void setCount(int count) { this.count = count; } @Override public int compareTo(Node o) { int compare = Integer.compare(this.count, o.count); //在數目相同的情況下 比較時間 if (compare==0){ return Long.compare(this.time,o.time); } return compare; } }
2.2:定義LFU類
定義LFU類,這裡採用了泛型,聲明瞭K和V,還有總容量和一個Map(caches)用來維護所有的節點。在構造方法里將size傳遞進去,並且創建了一個LinkedHashMap,採用linkedHashMap的主要原因是維護key的順序
public class LFU<K,V> { /** * 總容量 */ private int capacity; /** * 所有的node節點 */ private Map<K, Node> caches; /** * 構造方法 * @param size */ public LFU(int size) { this.capacity = size; caches = new LinkedHashMap<K,Node>(size); } }
2.3: 添加元素
添加元素的邏輯主要是先從緩存中根據key獲取節點,如果獲取不到,證明是新添加的元素,然後和容量比較,大於預定容量的話,需要找出count計數最小(計數相同的情況下,選擇時間最久)的節點,然後移除掉那個。如果在預定的大小之內,就新創建節點,註意這裡不能使用 System.currentTimeMillis()方法,因為毫秒級別的粒度無法對插入的時間進行區分,在運行比較快的情況下,只有System.nanoTime()才可以將key的插入時間區分,預設設置count計數為1.如果能獲取到,表示是舊的元素,那麼就用新值覆蓋舊值,計數+1,設置key的time為當前納秒時間。最後還需要進行排序,這裡可以看出插入元素的邏輯主要是添加進入緩存,更新元素的時間和計數~
/** * 添加元素 * @param key * @param value */ public void put(K key, V value) { Node node = caches.get(key); //如果新元素 if (node == null) { //如果超過元素容納量 if (caches.size() >= capacity) { //移除count計數最小的那個key K leastKey = removeLeastCount(); caches.remove(leastKey); } //創建新節點 node = new Node(key,value,System.nanoTime(),1); caches.put(key, node); }else { //已經存在的元素覆蓋舊值 node.value = value; node.setCount(node.getCount()+1); node.setTime(System.nanoTime()); } sort(); }
每次put或者get元素都需要進行排序,排序的主要意義在於按照key的cout和time進行一個key順序的重組,這裡的邏輯是首先將緩存map創建成一個list,然後按照Node的value進行,重組整個map。然後將原來的緩存清空,遍歷這個map, 把key和value的值放進去原來的緩存中的順序就進行了重組~這裡區分於LRU的不同點在於使用了java的集合API,LRU的排序是進行節點移動。而在LFU中實現比較複雜,因為put的時候不光得比較基數還有時間。如果不藉助java的API的話,可以新維護一個節點頻率鏈表,每次將key保存在這個節點頻率鏈表中移動指針,從而也間接可以實現排序~
/** * 排序 */ private void sort() { List<Map.Entry<K, Node>> list = new ArrayList<>(caches.entrySet()); Collections.sort(list, new Comparator<Map.Entry<K, Node>>() { @Override public int compare(Map.Entry<K, Node> o1, Map.Entry<K, Node> o2) { return o2.getValue().compareTo(o1.getValue()); } }); caches.clear(); for (Map.Entry<K, Node> kNodeEntry : list) { caches.put(kNodeEntry.getKey(),kNodeEntry.getValue()); } }
移除最小的元素
淘汰最小的元素這裡調用了Collections.min方法,然後通過比較key的compare方法,找到計數最小和時間最長的元素,直接從緩存中移除~
/** * 移除統計數或者時間比較最小的那個 * @return */ private K removeLeastCount() { Collection<Node> values = caches.values(); Node min = Collections.min(values); return (K)min.getKey(); }
2.4:獲取元素
獲取元素首先是從緩存map中獲取,否則返回null,在獲取到元素之後需要進行節點的更新,計數+1和刷新節點的時間,根據LFU的原則,在當前時間獲取到這個節點以後,這個節點就暫時變成了熱點節點,但是它的cout計數也有可能是小於某個節點的count的,所以
此時不能將它直接移動到鏈表頂,還需要進行一次排序,重組它的位置~
/** * 獲取元素 * @param key * @return */ public V get(K key){ Node node = caches.get(key); if (node!=null){ node.setCount(node.getCount()+1); node.setTime(System.nanoTime()); sort(); return (V)node.value; } return null; }
首先聲明一個LRU,然後預設的最大的大小為5,依次put進入A、B、C、D、E、F6個元素,此時將會找到計數最小和時間最短的元素,那麼將會淘汰A(因為count值都是1)。記著get兩次B元素,那麼B元素的count=3,時間更新為最新。此時B將會移動到頂,接著在getC元素,C元素的count=2,時間會最新,那麼此時因為它的count值依然小於B,所以它依然在B後面,再getF元素,F元素的count=2,又因為它的時間會最新,所以在與C相同的計數下,F元素更新(時間距離現在最近),所以鏈表將會移動,F會在C的前面,再次put一次C,此時C的count=3,同時時間為最新,那麼此刻C的count和B保持一致,則他們比較時間,C明顯更新,所以C將會排在B的前面,最終的順序應該是:C->B->F->E->D
public static void main(String[] args) { LFU<Integer, String> lruCache = new LFU<>(5); lruCache.put(1, "A"); lruCache.put(2, "B"); lruCache.put(3, "C"); lruCache.put(4, "D"); lruCache.put(5, "E"); lruCache.put(6, "F"); lruCache.get(2); lruCache.get(2); lruCache.get(3); lruCache.get(6);
//重新put節點3
lruCache.put(3,"C");
final Map<Integer, Node> caches = (Map<Integer, Node>) lruCache.caches; for (Map.Entry<Integer, Node> nodeEntry : caches.entrySet()) { System.out.println(nodeEntry.getValue().value); } }
運行結果:

四:LRU和LFU的區別以及LFU的缺點
LRU和LFU側重點不同,LRU主要體現在對元素的使用時間上,而LFU主要體現在對元素的使用頻次上。LFU的缺陷是:在短期的時間內,對某些緩存的訪問頻次很高,這些緩存會立刻晉升為熱點數據,而保證不會淘汰,這樣會駐留在系統記憶體裡面。而實際上,這部分數據只是短暫的高頻率訪問,之後將會長期不訪問,瞬時的高頻訪問將會造成這部分數據的引用頻率加快,而一些新加入的緩存很容易被快速刪除,因為它們的引用頻率很低。
五:總結
本篇博客針對LFU做了一個簡單的介紹,並詳細介紹瞭如何用java來實現LFU,並且和LRU做了一個簡單的比較。針對一種緩存策略。LFU有自己的獨特使用場景,如何實現LFU和利用LFU的特性來實現開發過程部分功能是我們需要思考的。實際在使用中LRU的使用頻率要高於LFU,不過瞭解這種演算法也算是程式員的必備技能。
最後: 如果對學習java有興趣可以加入群:618626589,本群旨在打造無培訓廣告、無閑聊扯皮、無註水斗圖的純技術交流群,群里每天會分享有價值的問題和學習資料,歡迎各位隨時加入~


