
"點我查看秘籍連載" 頁翻譯:快速地址轉換 雖然操作系統通過頁表也能將虛擬頁翻譯成記憶體中對應的頁幀,但是它仍然很慢。另一方面,如果訪問每個頁都需要操作系統來參與幫忙翻譯,這會頻繁陷入內核,效率是非常低的。所以,這裡再次將任務交給硬體CPU去做。 提示:操作系統將底層任務交給硬體提高效率 前文介紹段的 ...
頁翻譯:快速地址轉換
雖然操作系統通過頁表也能將虛擬頁翻譯成記憶體中對應的頁幀,但是它仍然很慢。另一方面,如果訪問每個頁都需要操作系統來參與幫忙翻譯,這會頻繁陷入內核,效率是非常低的。所以,這裡再次將任務交給硬體CPU去做。
提示:操作系統將底層任務交給硬體提高效率
前文介紹段的虛擬地址翻譯,以及這裡介紹的頁翻譯,本都可以由操作系統完成,但是操作系統參與太多效率會非常低,這時候都將任務交給操作系統的好伙伴——硬體(CPU)來完成,這會減少大量的上下文切換,因為不用再陷入內核了。
不僅如此,磁碟IO本也是可以由操作系統參與完成的,但速度會更慢,所以也將IO任務交給了硬體(硬碟)去完成。此外,還有網卡、顯卡等等。
所以可以做個總結,只要頻繁進行底層操作的任務,一般都會交給硬體而繞過操作系統內核(因為繞過內核,這類任務也常稱為內核旁路操作),它們的原理都一樣。而要交給硬體,硬體肯定要支持這類操作。
CPU對頁做快速地址轉換,其全稱為translation-lookaside buffer(TLB),即地址轉換旁路緩衝。快速地址轉換之所以稱為TLB,這是歷史原因造成的。但是否註意到旁路緩衝這幾個字?即繞過內核的緩衝,也就是硬體中的緩衝。
所以,CPU對頁做快速地址轉換是藉助CPU的高速緩衝區完成的,而且使用的L1級緩存(離CPU核心最近的緩存)和L2級緩存(比L1緩存稍慢),翻譯速度可想而知有多快。
這裡以最簡單的方式描述下快速地址轉換涉及到的一些過程。

雖然CPU的高速緩存速度非常快,但與之對應的是緩存空間非常小,所以只能保存有限數量的翻譯信息。如果高速緩衝區緩存的翻譯信息數量已滿,當訪問緩存中不存在翻譯信息的頁,就只能從記憶體的多級頁表中讀取翻譯信息,因為這條翻譯信息也要緩存到高速緩衝區,所以只能從高速緩衝區中踢掉之前的一條翻譯信息。那麼踢掉哪一項呢?於是緩存替換策略演算法就派上用場了,例如隨機踢掉一項的隨機替換演算法,踢掉最近最少訪問的那項的LRU演算法,等等。
這裡給一個訪問數組的示例,來幫助理解TLB帶來的好處。如下圖是數組a中10個元素的存放方式,總共存放在3個虛擬頁中。
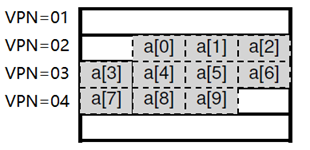
如果依次去訪問這10個數組元素,首先訪問a[0]時高速緩衝區中沒有緩存相關的翻譯信息,所以需要從記憶體中去讀取VPN 02頁的翻譯信息並緩存在高速緩衝區中,然後到對應的物理記憶體中去取得該元素的值。但是當訪問a[1]和a[2]的時候就能夠從高速緩衝區中受益,因為這兩個元素都在VPN 02頁中,而該頁的翻譯信息已經緩存了。
同理,訪問新頁中a[03]和a[7]的時候,需要先從記憶體中讀取頁VPN 03和VPN 04的翻譯信息並緩存下來,之後再訪問頁中其它元素的時候就可以直接從緩存中取得翻譯信息,直接找到物理記憶體中的值。
這裡可以做個假設,假如每頁的大小足夠大,數組a中的元素可以全部存放在同一個頁中,那麼緩存的效果顯然更好。但頁過大,容易造成大量的頁空間浪費,因為記憶體的操作單元是頁,如果一個100K的頁只存放了1K的數據,也只能讀取這100K,並且剩餘99K空間被浪費,這種浪費稱為內部碎片。
提示:空間的外部碎片和內部碎片
這是空間管理的兩個經常出現概念。
內部碎片是給空間按固定大小劃分成塊或頁後,塊內或頁內的空間沒有完全利用導致有一部分空間浪費,這種稱為內部碎片,即頁內或塊內的空間碎片。一般使用填充因數或頁密度來描述頁的空間使用率是高還是低。內部碎片有好處也有壞處,壞處是浪費了一點空間,但這是無法避免的,好處是每頁都留下了空閑空間,如果程式支持的話(例如資料庫),以後該頁可以繼續存入新數據。
外部碎片是因為給空間劃分了不同大小的區段(即分段或分區)後,隨著空間的分配和釋放,導致空間的不連續(即出現了空間孔洞)。例如3段連續空間大小分別為10K、20K、10K,如果中間的20K已被使用而左右兩個10K是空閑的(這是可能的,空間可以在使用後釋放),即使現在總共有20K空閑空間,但如果想要申請15K空間,結果要麼失敗,要麼通過鏈表將不連續的空間鏈起來,不同程式處理方式不一樣。所以,外部碎片過多的負面影響非常大,要麼因無法分配空間導致程式異常終止,要麼因為訪問空間時要通過鏈表跳轉的重定位而嚴重影響性能。

