
最左匹配原則 1、先定位該sql的查詢條件,有哪些,那些是等值的,那些是範圍的條件。 2、等值的條件去命中索引最左邊的一個欄位,然後依次從左往右命中,範圍的放在最後。 分析講解 1、mysql的索引分為聚簇索引和非聚簇索引,mysql的表是聚集索引組織表。 聚集規則是:有主鍵則定義主鍵索引為聚集索引 ...
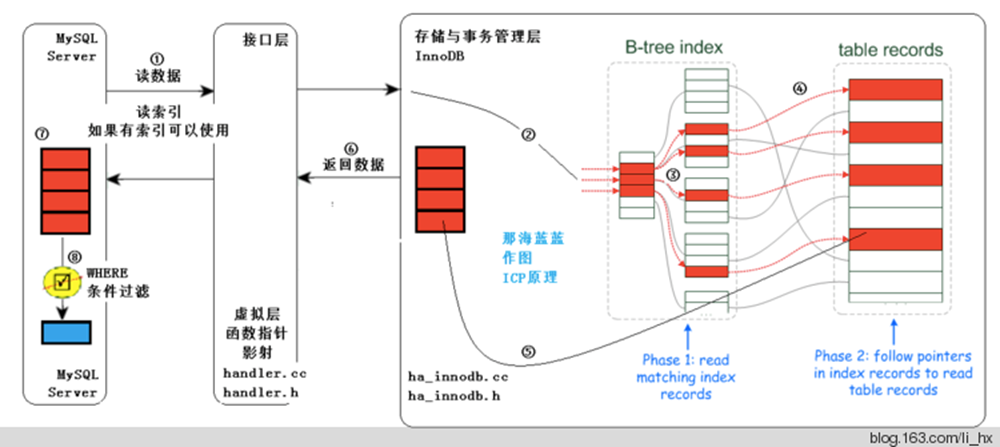
最左匹配原則 1、先定位該sql的查詢條件,有哪些,那些是等值的,那些是範圍的條件。 2、等值的條件去命中索引最左邊的一個欄位,然後依次從左往右命中,範圍的放在最後。 分析講解 1、mysql的索引分為聚簇索引和非聚簇索引,mysql的表是聚集索引組織表。 聚集規則是:有主鍵則定義主鍵索引為聚集索引;沒有主鍵則選第一個不允許為NULL的唯一索引;還沒有就使用innodb的內置rowid為聚集索引。 非聚集索引也稱為二級索引,或者輔助索引。 2、mysql的索引無論是聚集索引還是非聚集索引,都是B+樹結構。聚集索引的葉子節點存放的是數據,非聚集索引的葉子節點存放的是非聚集索引的key和主鍵值。B+樹的高度為索引的高度。 3、索引的高度 聚集索引的高度決定了根據主鍵取數據的理論IO次數。根據非聚集索引讀取數據的理論IO次數還要加上訪問聚集索引的IO次數總和。實際上可能要不了這麼多IO。因為索引的分支節點所在的Page因為多次讀取會在mysql記憶體里cache住。 mysql的一個block大小預設是16K,可以根據索引列的長度粗略估算索引的高度。 sql優化依據 SQL語句中的where條件,使用以上的提取規則,最終都會被提取到Index Key (First Key & Last Key),Index Filter與Table Filter之中。 Index First Key,只是用來定位索引的起始範圍,因此只在索引第一次Search Path(沿著索引B+樹的根節點一直遍歷,到索引正確的葉節點位置)時使用,一次判斷即可; Index Last Key,用來定位索引的終止範圍,因此對於起始範圍之後讀到的每一條索引記錄,均需要判斷是否已經超過了Index Last Key的範圍,若超過,則當前查詢結束; Index Filter,用於過濾索引查詢範圍中不滿足查詢條件的記錄,因此對於索引範圍中的每一條記錄,均需要與Index Filter進行對比,若不滿足Index Filter則直接丟棄,繼續讀取索引下一條記錄; Table Filter,則是最後一道where條件的防線,用於過濾通過前面索引的層層考驗的記錄,此時的記錄已經滿足了Index First Key與Index Last Key構成的範圍,並且滿足Index Filter的條件,回表讀取了完整的記錄,判斷完整記錄是否滿足Table Filter中的查詢條件,同樣的,若不滿足,跳過當前記錄,繼續讀取索引的下一條記錄,若滿足,則返回記錄,此記錄滿足了where的所有條件,可以返回給前端用戶 分析 一條sql語句要執行完成需要經歷什麼樣的過程 當一條sql語句提交給mysql資料庫進行查詢的時候需要經歷以下幾步 1、先在where解析這一步把當前的查詢語句中的查詢條件分解成每一個獨立的條件單元 2、mysql會自動將sql拆分重組 3、然後where條件會在B-tree index這部分進行索引匹配,如果命中索引,就會定位到指定的table records位置。如果沒有命中,則只能採用全部掃描的方式 4、根據當前查詢欄位返回對應的數據值
 Mysql - 什麼情況下索引不會被命中
Mysql - 什麼情況下索引不會被命中1、如果條件中有 or ,即使其中有條件帶索引也不會使用(這也是為什麼儘量少用or的原因)
註意:要想使用or,又想讓索引生效,只能將or條件中的每個列都加上索引
如果出現OR的一個條件沒有索引時,建議使用 union ,拼接多個查詢語句
2.、like查詢是以%開頭,索引不會命中
只有一種情況下,只查詢索引列,才會用到索引,但是這種情況下跟是否使用%沒有關係的,因為查詢索引列的時候本身就用到了索引
3. 如果列類型是字元串,那一定要在條件中將數據使用引號引用起來,否則不使用索引
4. 沒有查詢條件,或者查詢條件沒有建立索引
5. 查詢條件中,在索引列上使用函數(+, - ,*,/), 這種情況下需建立函數索引
6. 採用 not in, not exist
7. B-tree 索引 is null 不會走, is not null 會走


