
1 背景 像我們去面試一些大公司的時候,就會遇到一些關於緩存的問題。可能很多同學都是接觸過,多多少少瞭解一些,但是如果沒有好好記錄這些內容,不熟練精通的話,在真正面試的時候,就很難答出來了。 在我們的平常的項目中多多少少都會使用到緩存,因為一些數據我們沒有必要每次查詢的時候都去查詢到資料庫。 特別是 ...
1 背景
像我們去面試一些大公司的時候,就會遇到一些關於緩存的問題。可能很多同學都是接觸過,多多少少瞭解一些,但是如果沒有好好記錄這些內容,不熟練精通的話,在真正面試的時候,就很難答出來了。在我們的平常的項目中多多少少都會使用到緩存,因為一些數據我們沒有必要每次查詢的時候都去查詢到資料庫。
特別是高 QPS 的系統,每次都去查詢資料庫,對於你的資料庫來說將是災難。
今天我們不牽涉多級緩存的知識,就把系統使用到的緩存方案,不管是一級還是多級的都統稱為緩存,主要是為了講述使用緩存的時候可能會遇到的一些問題以及一些解決辦法。
我們使用緩存時,我們的業務系統大概的調用流程如下圖:
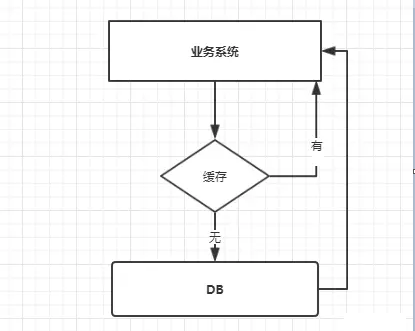
當我們查詢一條數據時,先去查詢緩存,如果緩存有就直接返回,如果沒有就去查詢資料庫,然後返回。這種情況下就可能會出現一些現象。
2 緩存穿透
2.1 什麼是緩存穿透
正常情況下,我們去查詢數據都是存在。
那麼請求去查詢一條壓根兒資料庫中根本就不存在的數據,也就是緩存和資料庫都查詢不到這條數據,但是請求每次都會打到資料庫上面去。
這種查詢不存在數據的現象我們稱為緩存穿透。
2.2 穿透帶來的問題
試想一下,如果有黑客會對你的系統進行攻擊,拿一個不存在的id 去查詢數據,會產生大量的請求到資料庫去查詢。可能會導致你的資料庫由於壓力過大而宕掉。
2.3 解決辦法
2.3.1 緩存空值
之所以會發生穿透,就是因為緩存中沒有存儲這些空數據的key。從而導致每次查詢都到資料庫去了。
那麼我們就可以為這些key對應的值設置為null 丟到緩存裡面去。後面再出現查詢這個key 的請求的時候,直接返回null 。
這樣,就不用在到資料庫中去走一圈了,但是別忘了設置過期時間。
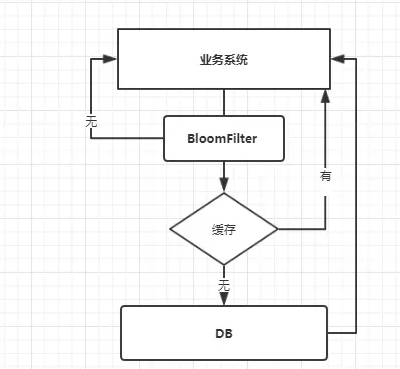
2.3.2 BloomFilter
BloomFilter 類似於一個hbase set 用來判斷某個元素(key)是否存在於某個集合中。
這種方式在大數據場景應用比較多,比如 Hbase 中使用它去判斷數據是否在磁碟上。還有在爬蟲場景判斷url 是否已經被爬取過。
這種方案可以加在第一種方案中,在緩存之前在加一層 BloomFilter ,在查詢的時候先去 BloomFilter 去查詢 key 是否存在,如果不存在就直接返回,存在再走查緩存 -> 查 DB。
流程圖如下:
2.4 如何選擇
針對於一些惡意攻擊,攻擊帶過來的大量key 是不存在的,那麼我們採用第一種方案就會緩存大量不存在key的數據。
此時我們採用第一種方案就不合適了,我們完全可以先對使用第二種方案進行過濾掉這些key。
針對這種key異常多、請求重覆率比較低的數據,我們就沒有必要進行緩存,使用第二種方案直接過濾掉。
而對於空數據的key有限的,重覆率比較高的,我們則可以採用第一種方式進行緩存。
3 緩存擊穿
3.1 什麼是擊穿
緩存擊穿是我們可能遇到的第二個使用緩存方案可能遇到的問題。
在平常高併發的系統中,大量的請求同時查詢一個 key 時,此時這個key正好失效了,就會導致大量的請求都打到資料庫上面去。這種現象我們稱為緩存擊穿。
3.2 會帶來什麼問題
會造成某一時刻資料庫請求量過大,壓力劇增。
3.3 如何解決
上面的現象是多個線程同時去查詢資料庫的這條數據,那麼我們可以在第一個查詢數據的請求上使用一個 互斥鎖來鎖住它。
其他的線程走到這一步拿不到鎖就等著,等第一個線程查詢到了數據,然後做緩存。後面的線程進來發現已經有緩存了,就直接走緩存。
4、緩存雪崩
4.1 什麼是緩存雪崩
緩存雪崩的情況是說,當某一時刻發生大規模的緩存失效的情況,比如你的緩存服務宕機了,會有大量的請求進來直接打到DB上面。結果就是DB 稱不住,掛掉。
4.2 解決辦法
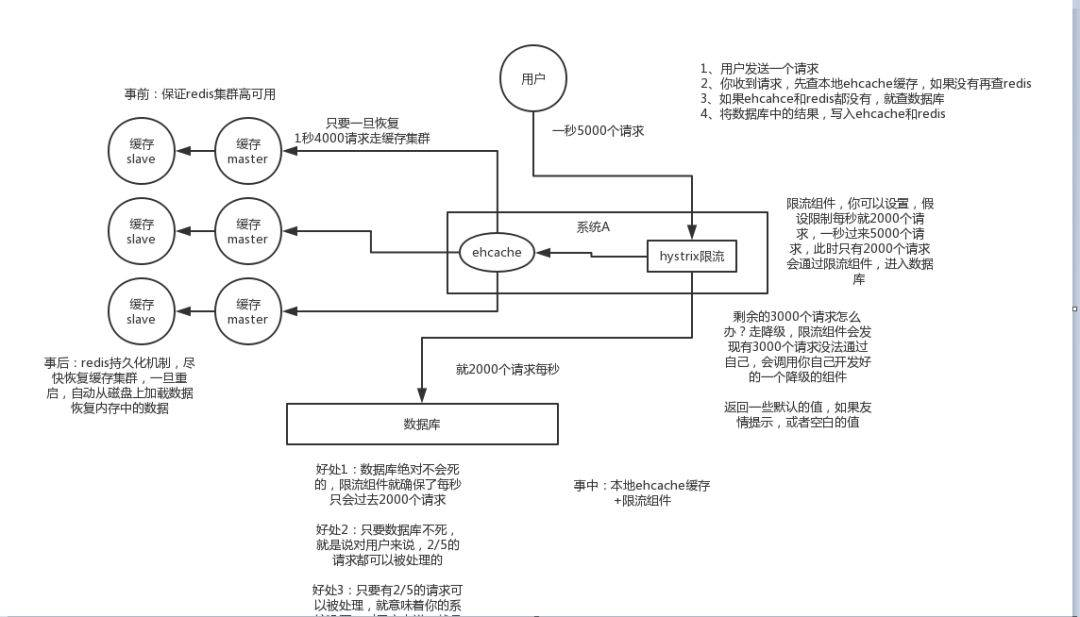
4.2.1 事前:
- 使用集群緩存,保證緩存服務的高可用
這種方案就是在發生雪崩前對緩存集群實現高可用,如果是使用 Redis,可以使用 主從+哨兵 ,Redis Cluster 來避免 Redis 全盤崩潰的情況。
4.2.2 事中:
- ehcache本地緩存 + Hystrix限流&降級,避免MySQL被打死
使用 ehcache 本地緩存的目的也是考慮在 Redis Cluster 完全不可用的時候,ehcache 本地緩存還能夠支撐一陣。
使用 Hystrix進行限流 & 降級 ,比如一秒來了5000個請求,我們可以設置假設只能有一秒 2000個請求能通過這個組件,那麼其他剩餘的 3000 請求就會走限流邏輯。
然後去調用我們自己開發的降級組件(降級),比如設置的一些預設值呀之類的。以此來保護最後的 MySQL 不會被大量的請求給打死。
4.2.3 事後:
- 開啟Redis持久化機制,儘快恢復緩存集群
一旦重啟,就能從磁碟上自動載入數據恢復記憶體中的數據。
防止雪崩方案如下圖所示:
5 解決熱點數據集中失效問題
我們在設置緩存的時候,一般會給緩存設置一個失效時間,過了這個時間,緩存就失效了。
對於一些熱點的數據來說,當緩存失效以後會存在大量的請求過來,然後打到資料庫去,從而可能導致資料庫崩潰的情況。
5.1 解決辦法
5.1.1 設置不同的失效時間
為了避免這些熱點的數據集中失效,那麼我們在設置緩存過期時間的時候,我們讓他們失效的時間錯開。
比如在一個基礎的時間上加上或者減去一個範圍內的隨機值。
5.1.2 互斥鎖
結合上面的擊穿的情況,在第一個請求去查詢資料庫的時候對他加一個互斥鎖,其餘的查詢請求都會被阻塞住,直到鎖被釋放,從而保護資料庫。
但是也是由於它會阻塞其他的線程,此時系統吞吐量會下降。需要結合實際的業務去考慮是否要這麼做。

