
前提 所有服務均有獨立的事物管理機制,相互間沒有任何關聯. 所有業務介面都有對應的補償方法,用於將已經更新的數據還原到上一次的狀態. 本次實例為同步業務,理想狀態下,只有全部成功或全部失敗兩種情況. 正式開始 正常流程 一切安好. 中途異常 補償成功 雖然發生了失敗,但所有補償都成功了.沒有什麼問題 ...
前提
- 所有服務均有獨立的事物管理機制,相互間沒有任何關聯.
- 所有業務介面都有對應的補償方法,用於將已經更新的數據還原到上一次的狀態.
- 本次實例為同步業務,理想狀態下,只有全部成功或全部失敗兩種情況.
正式開始
正常流程
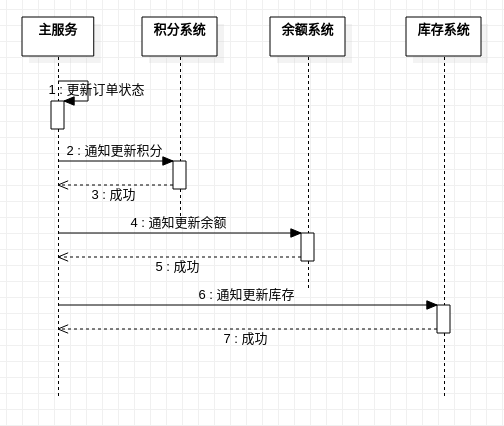
一切安好.
中途異常 - 補償成功
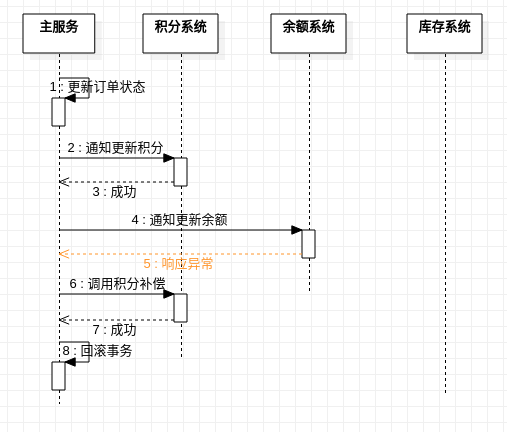
雖然發生了失敗,但所有補償都成功了.沒有什麼問題
中途異常 - 補償失敗

此時,主服務有三種處理方法
- 主服務無限重試補償方法,直到補償成功.
這裡有很麻煩的問題,如果下游的伺服器已經停機,此時主服務的無限重試已經沒有意義.在最壞的情況下,如果主服務訪問量過大,而因為業務相同,主服務的線程池中的全部線程將全部處於阻塞狀態,失去處理新請求的能力.
同時,訪問主服務的客戶端有可能會放棄本次的連接,導致正在重試中的線程被回收,丟失所有狀態 - 主服務儘可能調用補償方法,並回滾自身事物,同時通知備用方案
這裡依靠備用方案對失敗的補償調用進行非同步非同步調用,已達到"最終一致"的效果.備用方案一般需要集成"可靠消息系統" - 主服務直接放棄補償與自身的回滾,並通知備用方案
與2基本相同.在調用鏈比較長的情況下且補償隨機性失敗,從上層看,2方案的調用結果(備用方案未執行時)將成鋸齒狀.而本方案,其對應
的消費者直接以級聯方式進行補償的調用,最終完成全部補償調用與主方法數據回滾,同樣從上層看,方案3的調用結果(備用方案未執行時)將是平整的(只有失敗處斷裂).
方案1直接pass
方案2,3可以使用消息隊列與對應的消費者進行實現.但是會有短暫的數據不一致問題
中途異常(偽) - 觸發補償

這種情況具體描述如下
- 正常遠程調用
- 下游業務接收併進行處理
- 主服務認為網路超時(如等待資料庫鎖釋放)或發生其他意外,從而觸發補償流程
- 下游業務完成請求處理
- 主服務發起並執行補償流程(不包含4涉及的服務)
解決方法
- 記錄全局唯一識別碼,當主服務發起補償時,所有下游業務應該得知,並出發各自的補償方法.
需要註意,在嘗試解決過程中,如果主服務過早推送回滾通知,涉及獨自提交的服務早於對應業務處理完成進行補償,將會導致回滾通知失效.
在這種情況下,上游業務回滾,下游業務獨自完成了業務處理,造成數據問題. 會有短暫的數據不一致問題
同樣的,在這種情況下,調用補償也有可能發生調用失敗的情況.並且會更複雜,因為此時主服務會發出全局的回滾消息,需要處理補償消息與回滾消息的順序問題
主服務斷電 - 正常運行,補償中,補償失敗中
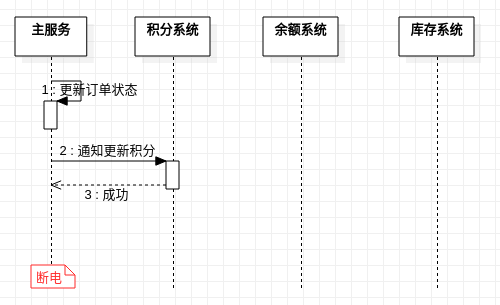

此時主服務狀態全部丟失且下游業務狀態錯亂
只能借用可靠消息對進行中的操作進行記錄,併在再次開啟後進行恢復
總結
- 在必須要使用RPC進行遠程調用且事物複雜的情況下,應使用一個可靠的消息系統保證在各方斷電,斷網,回滾時能夠即使恢復"狀態".
- 同時,應保證嚴格的冪等性,對於非冪等消息,根據實際情況,進行保留會消耗.
- 所有經由消息系統的恢復性調用,均為非同步操作,此時各方數據會出現不同步的問題.
- 對於複雜性,即使是只有2步,也會產生意外,且補償方法並不可靠.必須使用"可靠消息"系統進行保證(就是說,不要想要有"方便"這兩個字).
- 對於調用消息,進行兩步驗證,要做xxx與完成xxx,同時保證複蘇用的業務數據即可.對於全局回滾消息,進行通用,同時保證複蘇消息與回滾消息的冪等
- 主服務自身的業務邏輯也應做成遠程調用的模式,即有常規與補償方法.而主方法本身不包含事物,以此進行統一管理
- 基於上述的內容,已經很靠近TCC模式了,且需要擴展很多框架級代碼與補償代碼.


