
官網關於 "LanguageManual Sampling" 的教程,部分截圖如下,這裡主要分享對TABLESAMPLE(BUCKET 3 OUT OF 16 ON id)子句的理解 官網中假設創建表時設置了 即分成了32個文件(雖然這裡用的是bucket,為了避免混淆和方便理解下麵的解釋,個人 ...
官網關於LanguageManual Sampling的教程,部分截圖如下,這裡主要分享對TABLESAMPLE(BUCKET 3 OUT OF 16 ON id)子句的理解
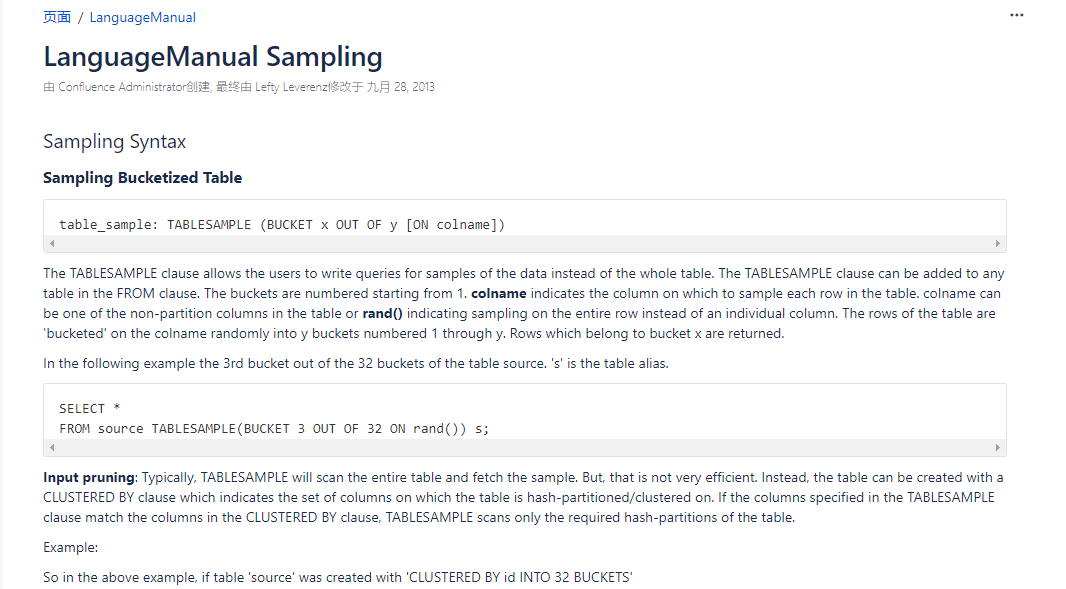
官網中假設創建表時設置了 CLUSTERED BY(id) INTO 32 BUCKETS 即分成了32個文件(雖然這裡用的是bucket,為了避免混淆和方便理解下麵的解釋,個人傾向於用cluster或者叫簇來代替),那麼下麵這個子句
TABLESAMPLE(BUCKET 3 OUT OF 16 ON id)在查詢中的意思是將cluster分成16個桶,然後取出第三個桶中的數據。32個文件分進16個桶,那就是每個桶有(32/16=)2 個cluster,怎麼分呢?第1個cluster分進第1個桶,第2個cluster分進第2個桶......第16個cluster分進第16個桶,第17個cluster分進第1個桶,以此類推。所以當取出第三個桶中的數據時,就會取出第3個簇(cluster)和第19簇(cluster)的數據。官網原話:
would pick out the 3rd and 19th clusters as each bucket would be composed of (32/16)=2 clusters.
那下麵這個怎麼理解呢?
TABLESAMPLE(BUCKET 3 OUT OF 64 ON id) 32個cluster分進64個桶,然後再抽出第三個桶中的數據。32/64=1/2,每個桶由1/2個cluster組成,同樣地,第1個cluster的前一半數據分進第1個桶,後一半數據分進第33個桶,第2個cluster的前一半數據分進第2個桶,後一半數據分進第34個桶,.....第32個cluster的前一半數據分進第32個桶,後一半數據分進第64個桶。所以這個子句會取出第3個桶中的數據,也就是第3個cluster中的前一半數據。官網原話:
would pick out half of the 3rd cluster as each bucket would be composed of (32/64)=1/2 of a cluster.
補充官網關於分桶表的DDL操作
LanguageManual DDL BucketedTables


