
什麼是布隆過濾器?它實際上是一個很長的二進位向量和一系列隨機映射函數。把一個目標元素通過多個hash函數的計算,將多個隨機計算出的結果映射到二進位向量的位中,依次來間接標記一個元素是否存在於一個集合中。布隆過濾器可以做什麼?布隆過濾器可以用於檢索一個元素是否在一個集合中。它的優點是空間效率和查詢時間 ...
什麼是布隆過濾器?
它實際上是一個很長的二進位向量和一系列隨機映射函數。把一個目標元素通過多個hash函數的計算,將多個隨機計算出的結果映射到二進位向量的位中,依次來間接標記一個元素是否存在於一個集合中。
布隆過濾器可以做什麼?
布隆過濾器可以用於檢索一個元素是否在一個集合中。它的優點是空間效率和查詢時間都比一般的演算法要好的多,缺點是有一定的誤識別率和刪除困難。
布隆過濾器特點
如果布隆過濾器顯示一個元素不存在於集合中,那麼這個元素100%不存在與集合當中
如果布隆過濾器顯示一個元素存在於集合中,那麼很有可能存在,可能性取決於對布隆過濾器的定義(BF.RESERVE {key} {error_rate} {capacity})
布隆過濾器的原理圖,這個就很容易理解了。
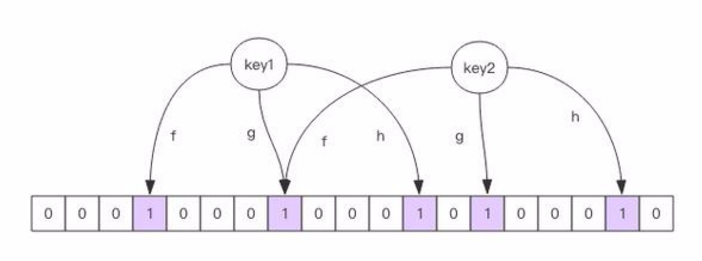
Redis中的布隆過濾器實現(rebloom模塊擴展)
下載並編譯
git clone git://github.com/RedisLabsModules/rebloom
cd rebloom
make
配置文件中載入rebloom
loadmodule /your_path/rebloom.so
重啟Redis伺服器即可
./bin/redis-cli -h 127.0.0.1 -p 6379 -a ****** shutdown
./bin/redis-server redis.conf
rebloom在Redis中的使用
bloom filter定義
BF.RESERVE {key} {error_rate} {capacity}
使用給定的期望錯誤率和初始容量創建空的Bloom過濾器(如果不存在的話)。如果打算向Bloom過濾器中添加許多項,則此命令非常有用,否則只能使用BF.ADD 添加項。
初始容量和錯誤率將決定過濾器的性能和記憶體使用情況。一般來說,錯誤率越小(即對誤差的容忍度越低),每個過濾器條目的空間消耗就越大。
bloom filter基本操作
1,BF.ADD {key} {item}
單條添加元素
向Bloom filter添加一個元素,如果該key不存在,則創建該key(過濾器)。
如果項是新插入的,則為“1”;如果項以前可能存在,則為“0”。
2,BF.MADD {key} {item} [item...]
批量添加元素
布爾數(整數)的數組。返回值為0或1的範圍的數據,這取決於是否將相應的輸入元素新添加到過濾器中,或者是否已經存在。
3,BF.EXISTS {key} {item}
判斷單個元素是否存在
如果存在,返回1,否則返回0
4,BF.MEXISTS {key} {item} [item...]
判斷多個元素是否存在
布爾數(整數)的數組。返回值為0或1的範圍的數據,這取決於是否將相應的元是否已經存在於key中。
127.0.0.1:8001> bf.reserve bloom_filter_test 0.0000001 1000000 OK 127.0.0.1:8001> bf.reserve bloom_filter_test 0.0000001 1000000 (error) ERR item exists 127.0.0.1:8001> 127.0.0.1:8001> 127.0.0.1:8001> bf.add bloom_filter_test key1 (integer) 1 127.0.0.1:8001> bf.add bloom_filter_test key2 (integer) 1 127.0.0.1:8001> 127.0.0.1:8001> bf.madd bloom_filter_test key2 key3 key4 key5 1) (integer) 0 2) (integer) 1 3) (integer) 1 4) (integer) 1 127.0.0.1:8001> bf.exists bloom_filter_test key2 (integer) 1 127.0.0.1:8001> bf.exists bloom_filter_test key3 (integer) 1 127.0.0.1:8001> bf.mexists bloom_filter_test key3 key4 key5 1) (integer) 1 2) (integer) 1 3) (integer) 1 127.0.0.1:8001>
5,bf.insert
bf.insert{key} [CAPACITY {cap}] [ERROR {ERROR}] [NOCREATE] ITEMS {item…}
該命令將向bloom過濾器添加一個或多個項,如果它還不存在,則預設情況下創建它。有幾個參數可用於修改此行為。
key:過濾器的名稱
capacity:如果指定了,應該在後面加上要創建的過濾器的所需容量。如果過濾器已經存在,則忽略此參數。如果自動創建了過濾器,並且沒有此參數,則使用預設容量(在模塊級指定)。見bf.reserve。
error:如果指定了,後面應該跟隨著新創建的過濾器的錯誤率(如果它還不存在)。如果自動創建過濾器而沒有指定錯誤,則使用預設的模塊級錯誤率。見bf.reserve。
nocreate:如果指定,表示如果過濾器不存在,就不應該創建它。如果過濾器還不存在,則返回一個錯誤,而不是自動創建它。如果需要在創建過濾器和添加過濾器之間進行嚴格的分離,可以使用這種方法。將NOCREATE與容量或錯誤一起指定是一個錯誤。
item:指示要添加到篩選器的項的開頭。必須指定此參數。
127.0.0.1:8001> bf.insert bloom_filter_test2 items key1 key2 key3 1) (integer) 1 2) (integer) 1 3) (integer) 1 127.0.0.1:8001> bf.insert bloom_filter_test2 items key1 key2 key3 1) (integer) 0 2) (integer) 0 3) (integer) 0 127.0.0.1:8001> bf.insert bloom_filter_test2 capacity 10000 error 0.00001 nocreate items key1 key2 key3 1) (integer) 0 2) (integer) 0 3) (integer) 0 127.0.0.1:8001> 127.0.0.1:8001> bf.insert bloom_filter_test2 capacity 10000 error 0.00001 nocreate items key4 key5 key6 1) (integer) 1 2) (integer) 1 3) (integer) 1 127.0.0.1:8001>
bf持久化操作
BF.SCANDUMP {key} {iter}對bloom過濾器進行增量保存。這對於不能適應常規save和restore模型的大型bloom filter非常有用。
第一次調用這個命令時,iter的值應該是0。這個命令將返回連續的(iter, data)對,直到(0,NULL),以表示完成
python偽代碼演示:
chunks = []
iter = 0
while True:
iter, data = BF.SCANDUMP(key, iter)
if iter == 0:
break
else:
chunks.append([iter, data])
# Load it back
for chunk in chunks:
iter, data = chunk
BF.LOADCHUNK(key, iter, data)
bf.scandump示例
127.0.0.1:8001> bf.scandump bloom_filter_test2 0 1) (integer) 1 2) "\x06\x00\x00\x00\x00\x00\x00\x00\x01\x00\x00\x00\x04\x00\x00\x00\x80\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x06\x00\x00\x00\x00\x00\x00\x00{\x14\xaeG\xe1z\x84?\x88\x16\x8a\xc5\x8c+#@\a\x00\x00\x00j\x00\x00\x00\n" 127.0.0.1:8001> bf.scandump bloom_filter_test2 1 1) (integer) 129 2) "\x00\x00\x00\x00\xa2\x00\x00\x00\x00\x00\x00B\x01\x00\x00\x00\x00\x00\x00\x00\x80\x00\x00 \x00\x00\b\x00\x00\x00\x00\b\x00\x00@\x00\x01\x04\x18\x02\x00\x00\x00\x82\x00\x00\x80@\x00\b\x00\x00\x00\x00 \x00\x00@\x00\x00\x00\x00\x18\b\x00\b\x00\b\x00\x80B\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x80\x00\x00\x00\x00 (\x00\x00\x00\x00@\x00\x00\x00\x00@\x00\x00\x04\x00\x00\x00\x00\x00\x00\x00\x80\x00\x00\x00\x80\x00\x00@\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\b" 127.0.0.1:8001> bf.scandump bloom_filter_test2 129 1) (integer) 0 2) "" 127.0.0.1:8001>
blool filter數據類型的屬性
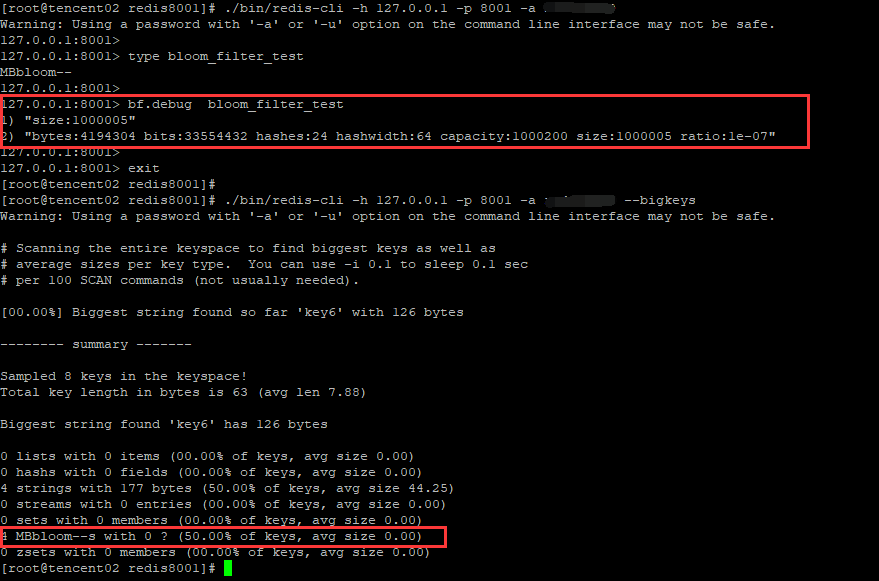
bf.debug
這裡可以看到,隨著bloom filter元素的增加,其空間容量也在不斷地增加
127.0.0.1:8001> bf.debug bloom_filter_test 1) "size:5" 2) "bytes:4194304 bits:33554432 hashes:24 hashwidth:64 capacity:1000200 size:5 ratio:1e-07" 127.0.0.1:8001> 127.0.0.1:8001> 127.0.0.1:8001> bf.debug bloom_filter_test 1) "size:128955" 2) "bytes:4194304 bits:33554432 hashes:24 hashwidth:64 capacity:1000200 size:128955 ratio:1e-07" 127.0.0.1:8001> 127.0.0.1:8001> 127.0.0.1:8001> bf.debug bloom_filter_test 1) "size:380507" 2) "bytes:4194304 bits:33554432 hashes:24 hashwidth:64 capacity:1000200 size:380507 ratio:1e-07" 127.0.0.1:8001> 127.0.0.1:8001> 127.0.0.1:8001> bf.debug bloom_filter_test 1) "size:569166" 2) "bytes:4194304 bits:33554432 hashes:24 hashwidth:64 capacity:1000200 size:569166 ratio:1e-07" 127.0.0.1:8001> 127.0.0.1:8001> 127.0.0.1:8001> bf.debug bloom_filter_test 1) "size:852316" 2) "bytes:4194304 bits:33554432 hashes:24 hashwidth:64 capacity:1000200 size:852316 ratio:1e-07" 127.0.0.1:8001> 127.0.0.1:8001> 127.0.0.1:8001> bf.debug bloom_filter_test 1) "size:1000005" 2) "bytes:4194304 bits:33554432 hashes:24 hashwidth:64 capacity:1000200 size:1000005 ratio:1e-07" 127.0.0.1:8001>
關於布隆過濾器數據類型的空間分析
redis的bigkeys選項可以分析整個實例中的big keys信息,但是無法分析出MBbloom--類型的key值得大小
這裡基於Redis的debug object功能,實現對MBbloom--類型的key的統計(沒有找到怎麼用Python執行bf.debug原生命令的執行方式)。
import redis import sys import time import random def get_bf_bigkeys(): try: redis_conn = redis.StrictRedis(host='127.0.0.1', port=8001, db=0, password='******') except: print("connect redis error") sys.exit(1) dict_key = {} cursor = 1 while cursor != 0: if cursor == 1: key = redis_conn.scan(cursor=0, match='*', count=5000) else: key = redis_conn.scan(cursor=cursor,match='*', count=5000) cursor = key[0] if len(key[1]) > 0: for var in key[1]: if str(redis_conn.type(var), encoding = "utf-8") == 'MBbloom--': info = redis_conn.debug_object(var) dict_key[var] = float(info['serializedlength']) / 1024 / 1024 # byte ---> mb res = sorted(dict_key.items(), key=lambda dict_key: dict_key[1], reverse=True) for i in range(10 if len(res) > 10 else len(res)): print(res[i]) if __name__ == "__main__": get_bf_bigkeys()
統計結果示例如下
[root@tencent02 redis8001]# python3 static_big_bf_keys.py (b'bloom_filter_test', 4.000059127807617) (b'my_bf2', 0.04577445983886719) (b'bloom_filter_test2', 0.00014019012451171875) (b'my_bf1', 0.0001220703125) [root@tencent02 redis8001]#
參考:
https://redislabs.com/blog/rebloom-bloom-filter-datatype-redis/
https://oss.redislabs.com/redisbloom/Bloom_Commands/


